Day1:大模型介绍和ollama基本使用
Ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。中文名:羊驼Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等
目标:无代码方式构建一个智能聊天机器人
需求:构建一个基于大模型的智能聊天机器人,利用其强大的自然语言处理和生成能力,为用户提供高效、精准、个性化的对话服务。
功能:可以进行自然语言处理;实时对话交互;页面简洁明了;
项目架构:
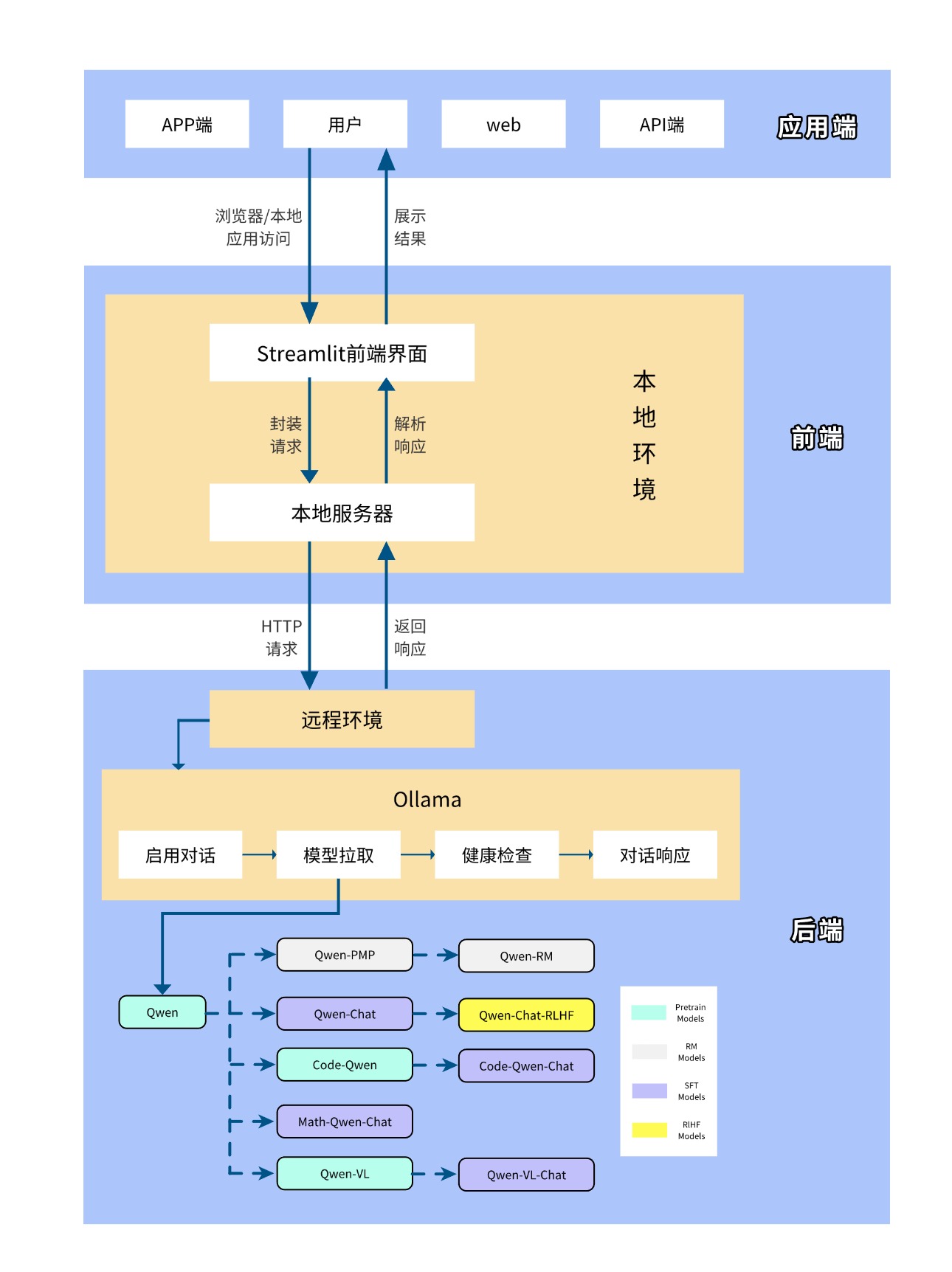
项目完整架构:
-
后端模型:利用 Ollama 平台的 Qwen 模型,该模型具备出色的自然语言处理能力,能够理解和生成自然语言文本,为聊天机器人提供核心的对话处理功能。
-
前端界面:采用 Streamlit 框架搭建用户界面,Streamlit 是一个简单易用的 Python 库,能够快速创建美观、交互式的 Web 应用,使用户能够通过网页与聊天机器人进行实时对话。
-
对话交互:用户可以通过 Streamlit 界面输入文本,聊天机器人基于 Qwen 模型对输入内容进行理解和处理,生成相应的回复并展示在界面上,实现流畅的对话交互。
-
模型调用:后端服务负责将用户输入传递给 Qwen 模型,并获取模型生成的回复,然后将回复内容返回给前端界面进行展示,确保对话的实时性和准确性。
-
界面展示:Streamlit 界面提供简洁明了的布局,包括输入框、发送按钮和对话展示区域,用户可以方便地输入问题并查看机器人的回答,提升用户体验。
聊天机器人是一种基于人工智能的自然语言处理技术开发的软件程序,能够通过文本或语音与用户进行交互,模拟人类对话它可以根据用户输入的问题或指令,生成相应的回答或执行特定的操作。
特点
-
自然语言理解(NLP):能够理解用户输入自然语言,包括文字或语音,并从中提取意图和关键信息。
-
对话管理:通过对话引擎维持对话的连贯性,根据上下文生成合适的回答。
-
个性化交互:可以根据用户的历史记录和偏好提供定制化的回答。
-
多功能性:除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等。
应用场景
-
客户服务:在电商、金融等领域,聊天机器人可以自动解答用户问题,提供24*7的客户支持。
-
娱乐:一些聊天机器人可以与用户进行趣味对话,提供娱乐体验。
-
教育:用于语言学习、知识问答等教育场景。
-
智能家居:控制家电设备,如灯光、空调等。
-
医疗健康:提供健康咨询、预约挂号等服务。
常见聊天机器人
deepseek,通义千问,讯飞星火,豆包
大模型核心基础
自然语言处理模型
专注于文本生成、理解、翻译等任务,GPT系列(OpenAI)、BERT(Google)、T5(Google)
计算机视觉(CV)模型
视觉大模型(Large Visual Models)核心是通过大规模数据和复杂模型架构,实现对图像和视频的深度理解和生成。与传统计算机视觉模型相比,视觉大模型具有更强的泛化能力和多任务适应性,能够处理复杂的视觉任务,如图像分类、目标检测、语义分割、图像生成等。
Stable Diffusion、Vision Transformers (ViT)、DALL·E(OpenAI)、CLIP(OpenAI)
语音模型
语音大模型是基于深度学习技术构建的人工智能模型,主要用于处理语音相关的任务,如语音识别(ASR)、语音合成(TTS)、语音翻译等。近年来,随着深度学习和大规模数据训练的发展,语音大模型在性能和功能上取得了显著进展,能够支持多语言、多场景的复杂任务。
举例:Whisper(OpenAI)、WaveNet(DeepMind)、讯飞星火
语音模型是一种将声音信号转换为数字信号的模型。
语音模型的应用场景
-
语音识别:将人类语音转换为文本或其他可理解的形式,广泛应用于智能助手、语音输入和自动化客服系统。
-
语音合成:生成自然、具备韵律且富有情感的语音,适用于多语言、情感丰富的TTS应用。
-
语音增强:提高语音信号的清晰度和质量,常用于噪声环境下的语音处理。
-
声音事件监测:识别环境中的特定声音事件,如警报声、机器故障声等。
-
说话人识别:识别说话人的身份,常用于安全验证和个性化服务。
多模态模型
多模态模型是一种能够同时处理多种数据模态(如文本、图像、音频、视频等)的人工智能模型。与传统的单模态模型(如仅处理文本或图像)相比,多模态模型通过整合不同模态的数据,能够提供更全面、更准确的理解和生成能力。这些模型在多个领域展现出强大的应用潜力,例如医疗诊断、自动驾驶、智能助手等。
多模态模型的核心在于跨模态融合,即将不同模态的数据表示映射到同一空间,以便模型能够理解和生成跨模态的内容。例如,在视觉问答(VQA)任务中,模型需要同时理解图像内容和自然语言问题,以生成准确的答案。
举例:GPT-4(支持多模态)、Flamingo(DeepMind)、BLIP、KOSMOS(微软)
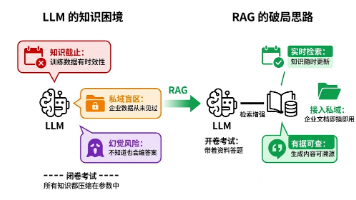
私有部署大模型
原因:(为什么要部署私有大模型)
Ollama安装与使用
什么是Ollama
Ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
中文名:羊驼
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发
Ollama特点
-
一站式管理:
-
Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节。
-
包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。
-
-
热加载模型文件:
-
支持热加载模型文件,无需重新启动即可切换不同的模型,
-
提高了灵活性,还显著增强了用户体验。
-
-
丰富的模型库:提供多种预构建的模型,如Llama 2、Llama 3、通义千问,方便用户快速在本地运行大型语言模型。
-
多平台支持:支持多种操作系统,包括Mac、Windows和Linux,确保了广泛的可用性和灵活性。
-
无复杂依赖:优化推理代码减少不必要的依赖,可以在各种硬件上高效运行。包括纯CPU推理和Apple Silicon架构。
-
资源占用少:Ollama的代码简洁明了,运行时占用资源少,使其能够在本地高效运行,不需要大量的计算资源。
Ollama下载与安装
Ollama下载
Ollama共支持三种平台:
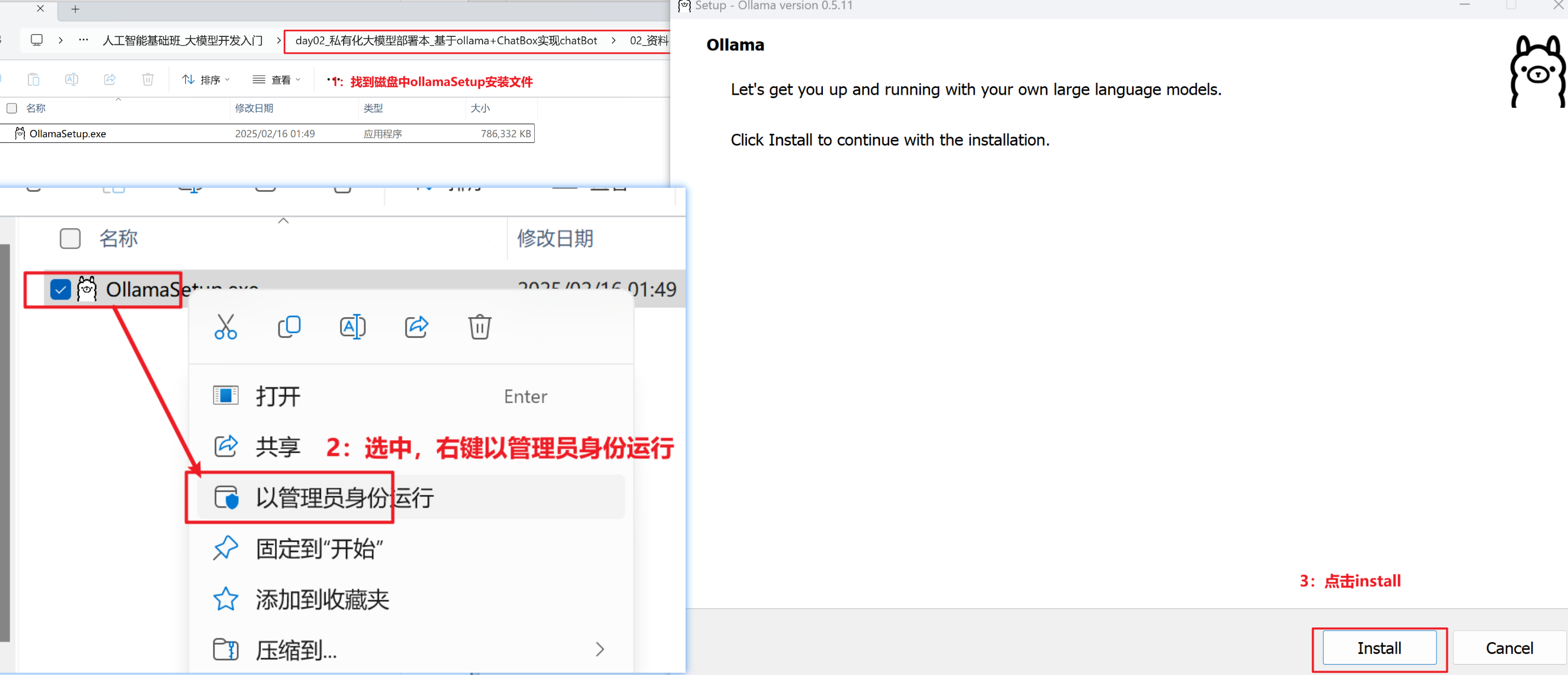
Windows平台安装
安装ollama
windows安装
第一步:OllamaSetup.exe 找到执行程序
第二步:右键以管理员身份运行
第三步:点击install
验证安装成功
第一步:win+R组合键 输入cmd
第二步: 输入命令 ollama -v
第三步:显示ollama版本号 ollama version is 0.5.4
即安装成功!
部署大模型
ollama run deepseek-r1:1.5b
ollama run qwen2:0.5b安装位置
C盘:用户-》.ollama->models
设置环境变量(用户变量和系统变量) 修改 ollama的模型库位置
OLLAMA_MODELS = 自己的目录所在位置
OLLAMA_MODELS=D:\work\java\soft\models
注意: 设置完后需重启计算机生效ollama命令
run命令
run命令主要用于运行一个大模型
ollama run MODEL[:Version] [PROMPT] [flags]
比如,运行通义千问命令:
ollama run qwen2:0.5b
[:Version] 可以理解成版本,而版本信息常常以大模型规模来命名,可以不写,不写则模式成latest
ollama run qwen2
等同
ollama run qwen2:latest
[PROMPT] 参数是用户输入的提示词,如果带有此参数则,run命令会执行了输入提示词之后即退出终端,即只对话一次。
[root@bogon ~]# ollama run qwen2:0.5b 您好
您好!有什么问题我可以帮助您?
[root@bogon ~]#
[flags] 指定运行时的参数
Flags:
--format string 指定运行的模型输出格式 (比如. json)
--insecure 使用非安全模,比如在下载模型时会忽略https的安全证书
--keepalive string 指定模型在内存中的存活时间
--nowordwrap 关闭单词自动换行功能
--verbose 开启统计日志信息
例如,在启动时增加 --verbose参数,则在对话时,自动增加统计token信息:
[root@bogon ~]# ollama run qwen2:0.5b --verbose
>>> 您好 欢迎光临,我可以为您提供帮助。有什么问题或需要帮助的地方?
total duration: 1.229917477s
load duration: 3.027073ms
prompt eval count: 10 token(s)
prompt eval duration: 167.181ms
prompt eval rate: 59.82 tokens/s
eval count: 16 token(s)
eval duration: 928.995ms
eval rate: 17.22 tokens/s
show 命令
[root@bogon ~]# ollama show -h
Show information for a modelUsage:
ollama show MODEL [flags]Flags:
-h, --help 查看使用帮助
--license 查看模型的许可信息
--modelfile 查看模型的制作源文件Modelfile
--parameters 查看模型的内置参数信息
--system 查看模型的内置Sytem信息
--template 查看模型的提示词模版
pull命令
从远程下载一个模型,命令格式是: 拉取
ollama pull MODEL[:Version] [flags]
list/ls 命令
看本地下载的大模型列表,也可以使用简写ls
[root@bogon ~]# ollama list
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago
deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago
qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago
[root@bogon ~]# ollama ls
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 10 minutes ago
deepseek-coder:latest 3ddd2d3fc8d2 776 MB 3 hours ago
qwen2:0.5b 6f48b936a09f 352 MB 8 hours ago
ps 命令
查看当前运行的大模型列表,PS命令没其它参数
[root@bogon ~]# ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-coder:latest 3ddd2d3fc8d2 1.3 GB 100% CPU About a minute from now
rm 命令
删除本地大模型,RM命令没其它参数 remove 删除
[root@localhost system]# ollama ls
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago
deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago
qwen2:0.5b 6f48b936a09f 352 MB 24 hours ago
[root@localhost system]# ollama rm qwen2:0.5b
deleted 'qwen2:0.5b'
[root@localhost system]# ollama ls
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 16 hours ago
deepseek-coder:latest 3ddd2d3fc8d2 776 MB 19 hours ago
[root@localhost system]#
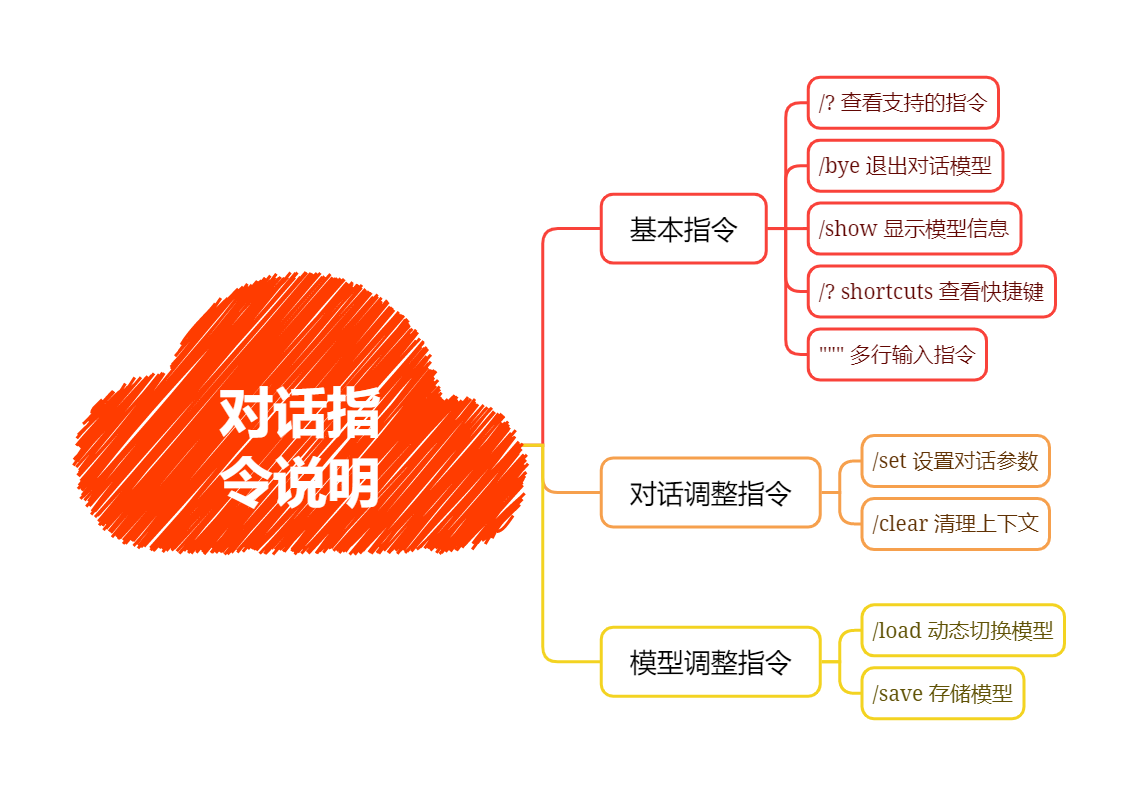
ollama对话指令详解(模型内指令)
/set 指令
set指令主要用来设置当前对话模型的系列参数
>>> /set
Available Commands:
/set parameter ... 设置对话参数
/set system <string> 设置系统角色
/set template <string> 设置推理模版
/set history 开启对话历史
/set nohistory 关闭对话历史
/set wordwrap 开启自动换行
/set nowordwrap 关闭自动换行
/set format json 输出JSON格式
/set noformat 关闭格式输出
/set verbose 开启对话统计日志
/set quiet 关闭对话统计日志
/set parameter ... 设置对话参数
>>> /set parameter
Available Parameters:
/set parameter seed <int> Random number seed
/set parameter num_predict <int> Max number of tokens to predict
/set parameter top_k <int> Pick from top k num of tokens
/set parameter top_p <float> Pick token based on sum of probabilities
/set parameter num_ctx <int> Set the context size
/set parameter temperature <float> Set creativity level
/set parameter repeat_penalty <float> How strongly to penalize repetitions
/set parameter repeat_last_n <int> Set how far back to look for repetitions
/set parameter num_gpu <int> The number of layers to send to the GPU
/set parameter stop <string> <string> ... Set the stop parameters
/clear 指令
在命令行终端中对话是自带上下文记忆功能,如果要清除上下文功能,则使用/clear指令清除上下文内容,例如:
前2个问题都关联的,在输入/clear则把前2个问题的内容给清理掉了,第3次提问时则找不到开始的上下文了。
>>> 请帮我出1道java list的单选题
以下是一些关于Java List的单选题:1. 在Java中,List是哪一种数据结构?
2. Java中的顺序存储方式(例如:使用数组)主要用来做什么?
3. 一个列表对象可以包含哪些类型的元素?>>> 再出1道
以下是一些关于Java List的单选题:4. 在Java中,List接口用于创建和操作集合。
5. Java中的顺序存储方式(如:使用数组)的主要优势有哪些?
6. 一个列表对象可以包含哪些类型?>>> /clear
Cleared session context
>>> 在出1道
很抱歉,我无法理解您的问题。您能否提供更多的背景信息或者问题描述,以便我能更好地帮助您?
/load 指令
对话过程中切换大模型
/save 指令
可以将当前模型存储为一个新的模型
>>> /save test
Created new model 'test'>>> /bye
命令:ollama ls

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)