什么是极大似然估计/Likelihood、AICc 与 BIC,这是我听过最好的回答【可靠性应用干货】
当你的样本量(数据行数)相对较小,或者模型参数较多时,普通的 AIC 容易误导你选择过于复杂的模型。仍以阿超的冰淇淋为例,假设阿花对阿超有好感的概率为p,则无感的概率为1-p(假设每次都是独立同分布),则根据阿超得到0个冰淇淋其概率为P(0个冰淇淋 | Model), 将第一次结果记为P1,第二次为P2,。与 AICc 的区别(惩罚力度更大): BIC 在计算“惩罚项”时,不仅考虑了参数的数量,还
目录:
-
一个小故事
-
概率 VS 似然
-
极大似然估计
-
-2Loglikelihood
-
AICc
-
BIC
一、一个小故事
有两个人:阿超和阿花;阿超老大不小,需要成家:某天遇见同事阿花,想着自己英俊潇洒、风流倜傥、才华横溢又谦虚非常;所以阿超认为阿花对自己有好感。
但是怎么判断阿花对自己是否有好感呢?
阿超了解到阿花每天都会拿1个冰淇淋,如果给阿超了,那就表明有好感;于是连续10天,阿超共得到了0个冰淇淋,问:阿花对阿超是否有好感?

二、概率 VS 似然
由上,有:
数据(既定事实):连续 10 天,阿超得到了 0 个冰淇淋。
模型/参数(隐藏的规则):阿花对阿超的好感度(即每天愿意把冰淇淋给阿超的概率)。
概率 (Probability) 是在问:“如果规则(好感度)是确定的,发生这件事的可能性有多大?”
阿超的幻想(算概率):
假设阿超开了上帝视角,确切知道“阿花极其暗恋我”(规则确定,每天给冰淇淋的概率是 90%)。那么,阿花连续 10 天都不给我冰淇淋的可能性有多大?
算一下概率:0.1^{10},这是一个极小极小的概率,几乎不可能发生。
似然 (Likelihood) 是在问:“既然这件事已经发生了,那么某个规则(好感度假设)显得有多么顺理成章?”
残酷的现实(算似然): 现实是,连续 10 天拿 0 个冰淇淋这件事已经发生了。
这时,阿超依然摸着自己英俊潇洒的脸庞说:“阿花肯定对我有好感!” 但作为旁观者,我们这个假设“合理”吗?,“顺理成章”吗?( 非常不顺理成章(简直是自作多情!)。“阿花喜欢阿超”这个假设的似然值极低。)
所以,说人话:
似然 (Likelihood) 就是顺理成章的程度;其本质就是当有既定事实时,倒推原因(规则/模型),并评估哪个原因听起来最靠谱。
三、极大似然估计 (Maximum Likelihood Estimation, MLE)
既然“似然”是“顺理成章的程度”,那么“极大似然”就是最顺理成章:在所有可能的解释中,挑出那个最能完美解释眼前事实的解释。 也就是找那个让事情看起来最不像是巧合的解释。
英文 Maximum Likelihood: 直译就是“最大的可能性(尤指基于证据的合理性)”。
正式理解:利用已知的样本结果信息,反推最大可能(概率)导致这些样本结果出现的模型参数值!即其提供一种给定观察数据来评估模型参数的方法(模型已定,参数未知)。
原理:在随机试验中,许多事件都有可能发生,概率大的事件发生的概率也大。若只进行一次试验,事件 A 发生,则我们有理由认为 事件A 比其他事件发生的概率大。
计算:
仍以阿超的冰淇淋为例,假设阿花对阿超有好感的概率为p,则无感的概率为1-p(假设每次都是独立同分布),则根据阿超得到0个冰淇淋其概率为P(0个冰淇淋 | Model), 将第一次结果记为P1,第二次为P2,。。。
有:
P(0个冰淇淋 | Model) = P(P1 | M ) * P(P2 | M ) *… * P(P10| M ) = p^0 * (1-p)^10
所以已经有了概率表达式,需要求模型参数,使得P(0个冰淇淋 | Model) 最大。显而易见,p=0;(😊😊😊)
比较正式的和公式推导可以参考:https://www.cnblogs.com/haohai9309/p/16867285.html
再举个例子看看似然值怎么得到:
假设我们有一组数据,表示某个零件的寿命(单位:小时)。假设我们只有 3 个数据点:
x_1 = 10
x_2 = 15
x_3 = 20
现在,我们要评估一个正态分布模型(假设均值μ=15,标准差σ=5)适不适合这批数据。
对于这 3 个数据点中的每一个,我们都可以把它代入正态分布的概率密度函数 (PDF,Probability Density Function) 中,算出一个值。这个值表示在这个假设的模型下,出现这个具体数值的可能性大小。
对于x_1 = 10,代入公式算出概率密度,假设是P_1 = 0.048
对于x_2 = 15,(正好是均值,可能性最大),代入公式算出概率密度,假设是P_2 = 0.080
对于x_3 = 20,代入公式算出概率密度,假设是P_3 = 0.048
(注:这里的 P 严格来说叫概率密度,而不是概率,但在计算似然时,我们直接用它。)
然后计算总的 Likelihood (似然)
现在我们有了每个单独数据点在这个模型下出现的“可能性”。那么这 3 个数据点同时出现的可能性有多大呢?
在统计学中,我们通常假设数据点之间是相互独立的。所以,总的 Likelihood (L) 就是所有单个数据点概率密度的乘积:
L=0.048×0.080×0.048=0.00018432
这个0.00018432 就是在这个特定的正态分布模型(μ=15,σ=5)下,这组数据的似然值 (Likelihood)。
四、-2Loglikelihood
稍等,在JMP中未看到likelihood,看到的是-2Loglikelihood, why?
对于L来说,其值越大,说明拟合得越好。但L通常是一个极小的数字,计算机在处理这种极小数字时很容易出现“下溢出”错误,而且也不直观。于是数学家就给它取了自然对数 (ln),然后再乘上 -2; 经过这么一转换,原本“越大越好”的 L,变成了“越小越好”的 -2Loglikelihood。
因为乘积的对数 = 对数的和。
ln(A×B)=ln(A)+ln(B);所以:
ln(L) = ln(P_1 * P_2 * ... * P_n) 这样把连乘变成了连加。
即对于MLE值越大越好,而对于-2Loglikelihood, 其值越小越好!那其前后的AICc和BIC又都是啥玩意?
五、AICc (Corrected Akaike Information Criterion/校正赤池信息量准则)
AIC 是一种评估模型拟合优度的标准。它会奖励拟合度高的模型,但同时会对模型中增加的变量/参数进行“惩罚”。AICc 是 AIC 的改进版,那个“c”代表 corrected(校正)。
当你的样本量(数据行数)相对较小,或者模型参数较多时,普通的 AIC 容易误导你选择过于复杂的模型。AICc 专门针对小样本进行了数学上的惩罚校正。当样本量非常大时,AICc 的值会和普通的 AIC 几乎完全一样。即AICc = AIC + 加上“复杂度惩罚” (适合中小样本)
AIC 公式: AIC = -2Loglikelihood + 2k
k 是模型里参数的个数。Weibull 和 Lognormal 都有 2 个参数(比如 Weibull 的形状和尺度),所以k=2。(2k 为惩罚。参数越多,惩罚分越高。)
AICc 公式: AICc = AIC + [ 2k(k+1) / (n-k-1) ],n 是样本量(数据行数)。
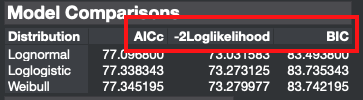
已知:-2LogL = 73.031583,参数k=2,样本量n=187。
AIC = 73.031583 + 2*2 = 77.031583
校正项 = (2 * 2 * 3) / (187 - 2 - 1) = 12 / 184 = 0.065217
AICc = 77.031583 + 0.065217 = 77.096800
六. BIC (Bayesian Information Criterion/贝叶斯信息量准则)
其设计初衷和 AICc 类似,也是为了平衡拟合度和复杂度。
与 AICc 的区别(惩罚力度更大): BIC 在计算“惩罚项”时,不仅考虑了参数的数量,还把样本量的对数计算在内。这意味着随着样本量的增加,BIC 对模型增加新变量的“惩罚力度”远远大于 AICc。
结果倾向: 因为惩罚更严厉,BIC 通常倾向于选择比 AICc 更简单、参数更少的模型。
BIC 公式: BIC = -2Loglikelihood + k * ln(n)
这里的惩罚项变成了 k * ln(n)。当样本量n > 8 时,ln(n) 就会大于 2,所以 BIC 的惩罚通常比 AIC 狠得多。
已知:-2LogL = 73.031583,参数k=2,样本量n=187。
惩罚项 = 2 *ln(187) = 2 * 5.2311 = 10.4622
BIC = 73.031583 + 10.4622 = 83.4938
模型拟合数据的准确度”和“模型的复杂度(参数数量)”之间找到最佳平衡,从而防止过拟合(Overfitting)。在对比多个模型时,无论是 AICc 还是 BIC,数值越小,代表模型越好。
对于单独一个分布函数来说,AICc 和 BIC 没有任何实际意义,他们是比分,只有在和其他模型比较时才有意义,而且分数越低越好。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)