大模型压缩训练(知识蒸馏)
剪枝简介剪枝方式。
模型压缩简介
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
①线性或非线性量化:1/2bits, in t8 和 fp 16等;
②结构或非结构剪枝:deep compression, channel pruning 和 network slimming等;
③知识蒸馏与网络结构简化(squeeze-net, mobile-net, shuffle-net)等;
剪枝简介
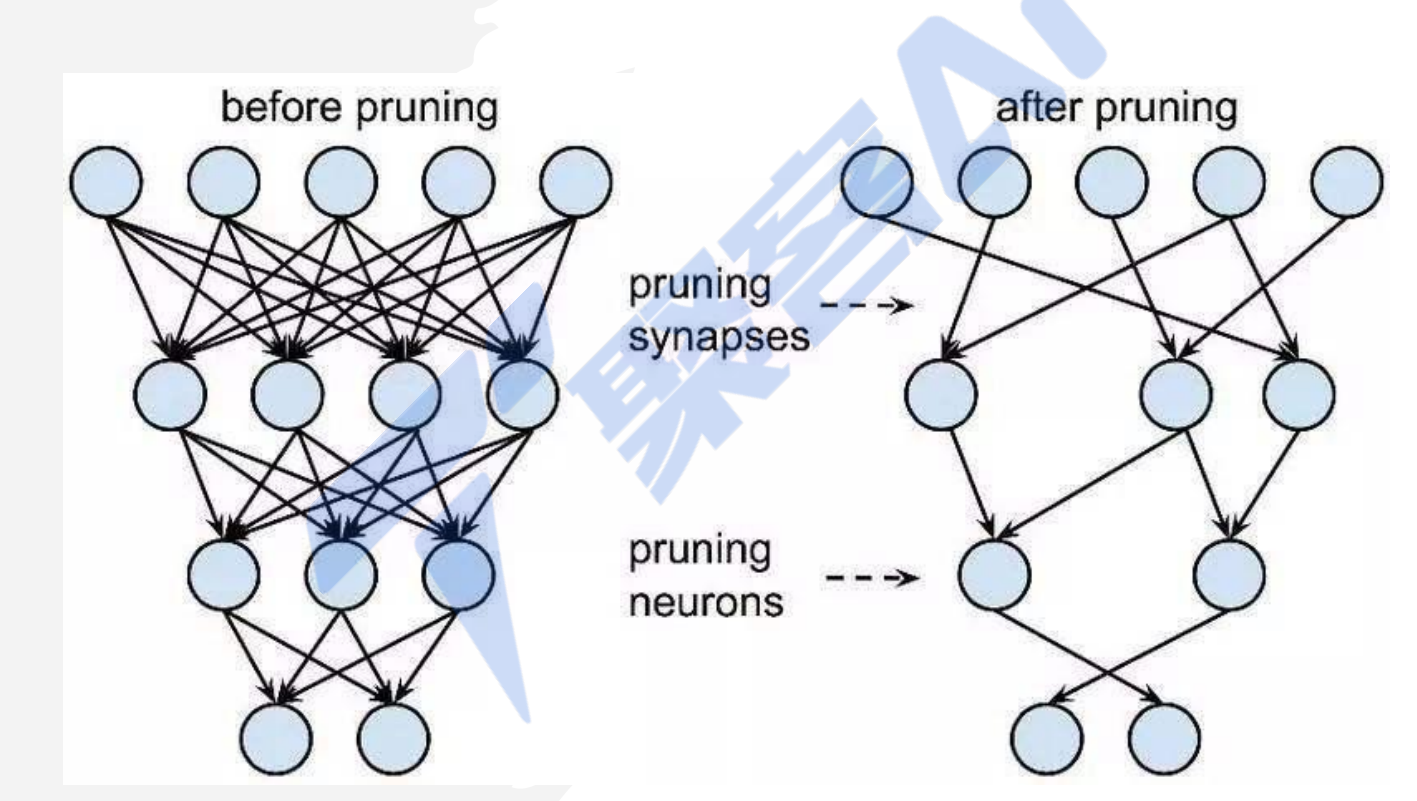
剪枝方式
非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持
结构剪枝:是filter 级或layer 级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行
局部方式的、通过layer by layer 方式的、最小化输出FM重建误差的Channel Pruning, ThiNet Discrimination-aware Channel Pruning;
全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming
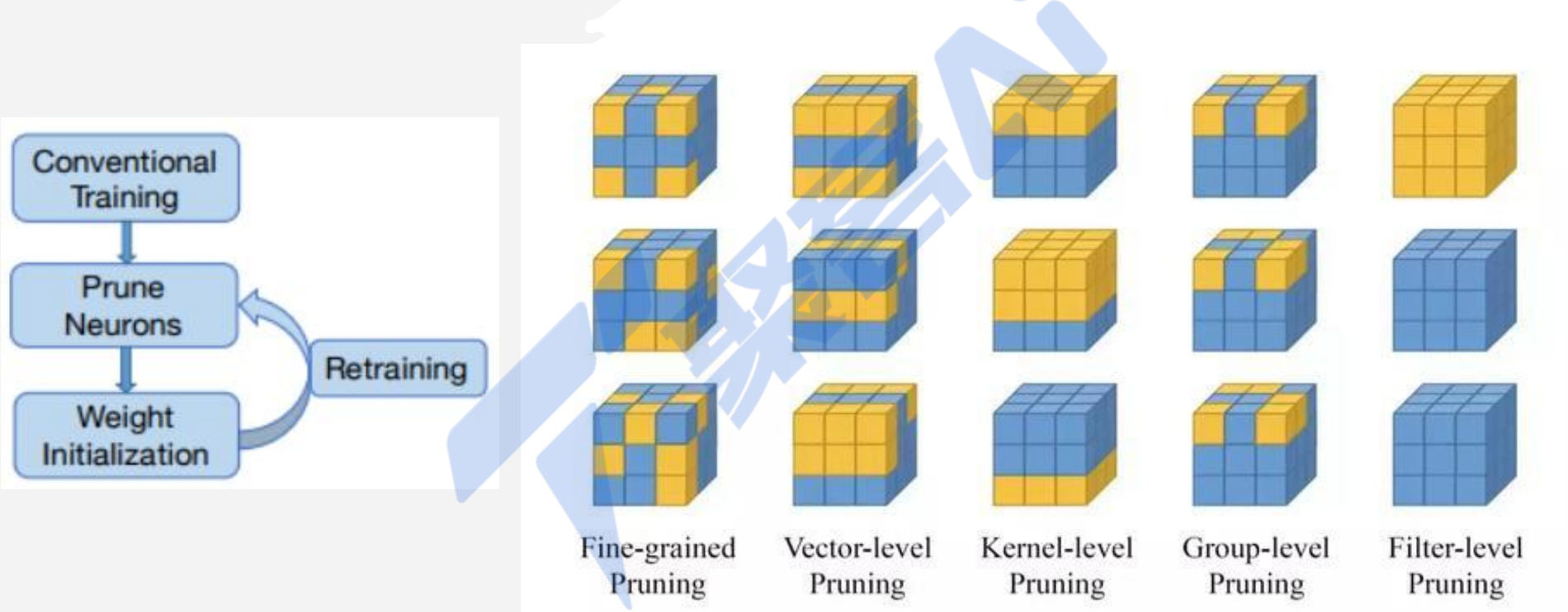
剪枝效果
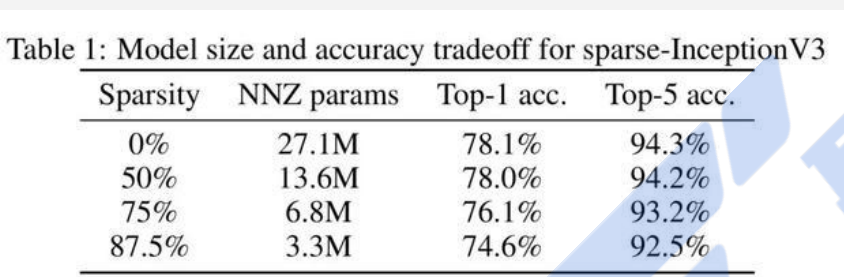
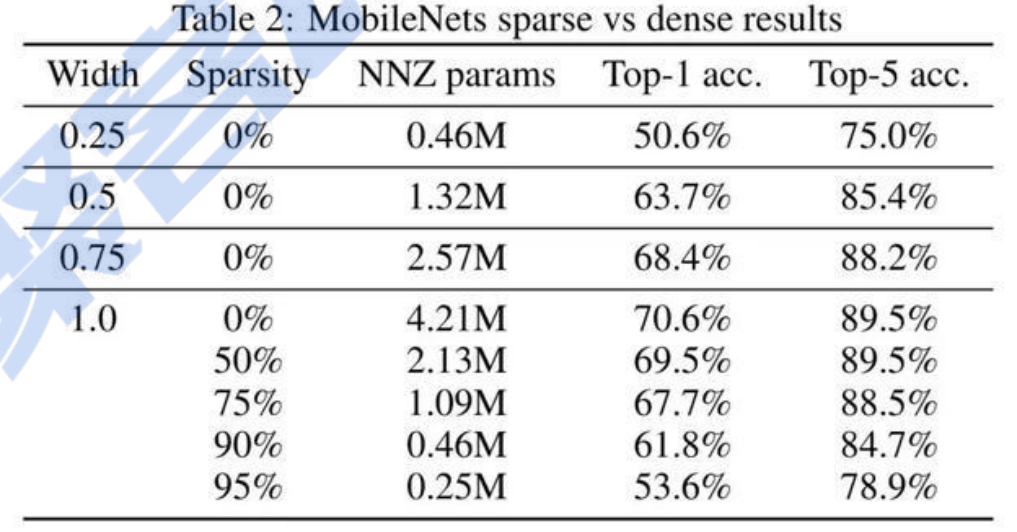
量化(学术界)
低精度(Low precision)可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等数值格式。不过目前低精度往往指代 INT8。
混合精度(Mixed precision)在模型中使用 FP32 和 FP16。 FP16 减少了一半的内存大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度。如果您对该主题感兴趣,请查看 Mixed-Precision Training of Deep Neural Networks。
量化一般指 INT8。
根据存储一个权重元素所需的位数,还可以包括:
①二值神经网络:在运行时权重和激活只取两种值(例如 +1,-1)的神经网络,以及在训练时计算参数的梯度。
②三元权重网络:权重约束为+1,0和-1的神经网络。
③XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近似卷积。
量化(工业界)
理论是一回事,实践是另一回事。如果一种技术方法难以推广到通用场景,则需要进行大量的额外支持。花哨的研究往往是过于棘手或前提假设过强,以至几乎无法引入工业界的软件栈。
工业界最终选择了 INT8 量化—— FP32 在推理(inference)期间被 INT8 取代,而训练(training)仍然是 FP32。TensorRT,TensorFlow,PyTorch,MxNet 和许多其他深度学习软件都已启用(或正在启用)量化。
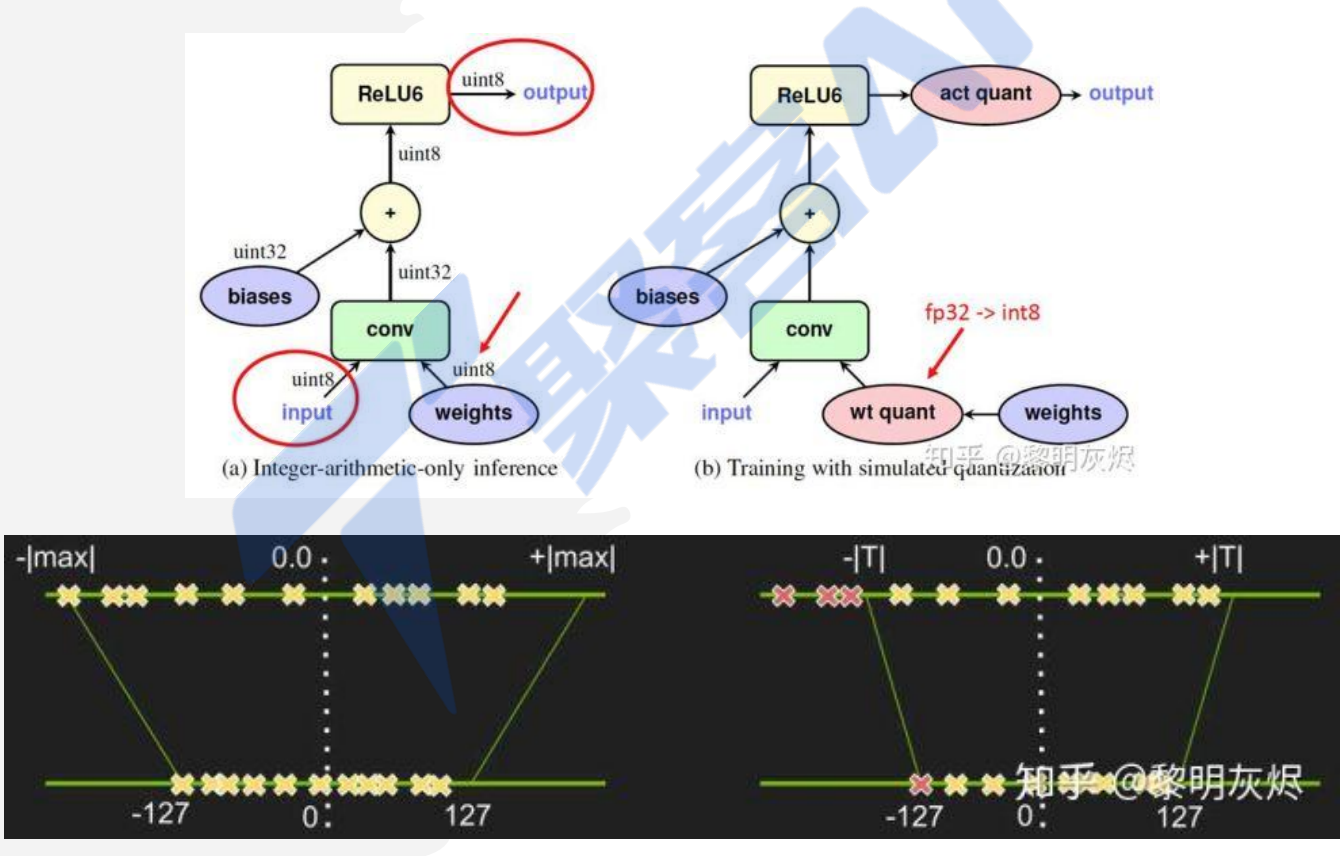
通常,可以根据 FP32 和 INT8 的转换机制对解决方案进行分类。一些框架简单地引入了 Quantize 和 Dequantize 层,当从卷积或全链接层送入或取出时,它将 FP32 转换为 INT8 或相反。在这种情况下,如图四的上半部分所示,模型本身和输入/输出采用 FP32格式。深度学习框架加载模型,重写网络以插入Quantize 和 Dequantize 层,并将权重转换为 INT8 格式。
量化原理
知识蒸馏
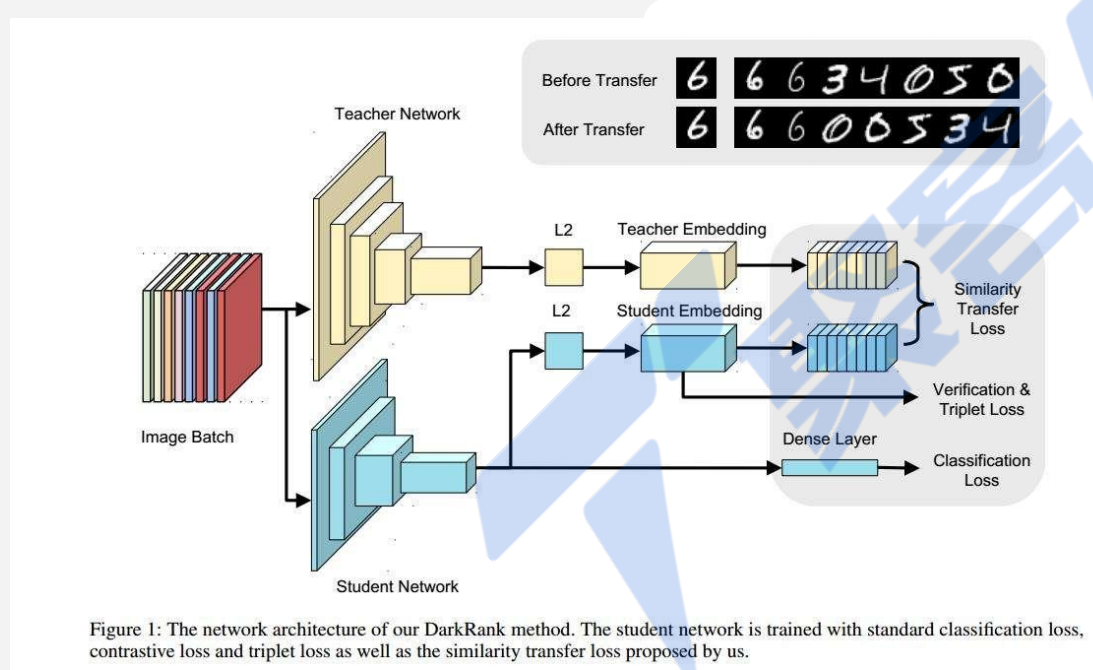
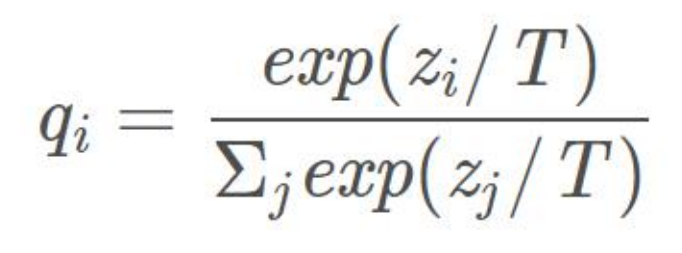
知识蒸馏在大模型中的应用
知识蒸馏在DeepSeek中的核心意义
1 .降低算力与成本
DeepSeek通过蒸馏技术将模型训练成本压缩至OpenAI同类模型的1/20。例如,DeepSeek-V3仅消耗278 .8万GPU小时(成本约557 .6万美元),而OpenAI类似模型的训练成本高达数亿美元49。这种低成本特性使中小企业也能负担高性能AI模型的开发。
2 .加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊断、自动驾驶等场景的低延迟需求。
3 .推动行业应用落地
教育领域:DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策略,降低教育平台运营成本。
工业场景:本地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助力智能制造中的质检、供应链优化等任务。
内容创作:AI写作工具结合蒸馏模型,创作效率提升50%,同时API调用成本仅为OpenAI的1/4,推动新媒体运营与创意产业发展。
掌握重点:
1. 掌握AI模型压缩技术的基本概念
1. 剪枝 (Pruning)
-
基本概念:去除模型中“不重要”的参数(权重)或结构。就像修剪树枝一样,去掉冗余的部分。
-
常见类型:
-
非结构化剪枝:将个别权重值设为0(如权重接近0的连接),粒度细但可能需要专用硬件/软件支持才能提速。
-
结构化剪枝:移除整个神经元、通道(Channel)或滤波器(Filter),能直接减少模型大小和计算量,兼容普通硬件。
-
2. 量化 (Quantization)
-
基本概念:降低模型权重和/或激活值数值的精度。通常将从训练时的32位浮点数(FP32)转换为低比特整数,如INT8、INT4甚至二值化(1-bit)。
-
效果:模型大小直接缩小(如INT8是FP32的1/4),内存带宽需求降低,且整数运算通常比浮点运算更快(尤其在支持INT8的硬件上)。
3. 知识蒸馏 (Knowledge Distillation, KD)
-
基本概念:训练一个小型模型(学生 Student)来模仿一个大型预训练模型(教师 Teacher)的行为。
-
原理:不仅让学生模型学习真实的标签(Hard Targets),还让它学习教师模型输出的概率分布(Soft Targets),从而将大模型的知识“蒸馏”到小模型中,通常能让小模型达到比直接训练更好的效果。
2. 掌握知识蒸馏在大模型中的应用价值。
知识蒸馏(Knowledge Distillation, KD)在大模型(LLM)时代的应用价值主要体现在将庞大、昂贵的计算密集型模型的能力“迁移”到更小、更高效的模型上,是解决大模型落地部署成本高、延迟高问题的关键技术之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)