工业智能体不是ChatGPT:从“模数共振“到智能工厂,数字孪生与大模型的融合架构解析
2026年,工业AI正在经历一次认知纠偏。
4月底,工信部与国家数据局联合启动**"模数共振"行动**,提出一个核心目标:让人工智能模型与工业数据资源协同互促、同频共振,到年底形成"数据—模型—场景应用"的良性循环。
紧接着,5月初中国石化发布"烽火"工业智能体,宣称实现了工艺优化、设备预测性维护等核心场景的智能决策。
再加上工信部此前明确的**"智能工厂梯度培育行动"**——到2027年建成不少于200家卓越级智能工厂——制造业正在进入一个明确的倒计时。
但这里有一个关键问题被很多人忽略了:
工业智能体,真的不是给工厂装一个ChatGPT那么简单。
它需要的不是"会聊天"的AI,而是能看懂产线、调度设备、预测故障、自主优化的"数字员工"。而要让这样的员工真正上岗,背后必须有一套能持续产出高质量工业训练数据的数字孪生底座。
这篇文章,就从技术架构的视角,拆解"模数共振"背景下,数字孪生与大模型的融合路径。
一、先纠偏:工业智能体≠聊天机器人,它是"产线Agent"
很多人听到"智能体",第一反应是类似ChatGPT那样能对话的AI。但在工业场景里,这个概念被严重窄化了。
真正的工业智能体(Industrial Agent),应该具备三个核心能力:
| 能力维度 | 传统AI应用 | 工业智能体(Agent) |
|---|---|---|
| 感知 | 读取单一传感器数据 | 融合多源异构数据(设备日志、工艺参数、视觉检测、环境数据) |
| 决策 | 基于规则判断(if-then) | 基于大模型推理 + 领域知识库,生成可执行方案 |
| 执行 | 输出报警或报表 | 直接下发指令给PLC/SCADA/MES,闭环控制产线 |
简单说:
工业智能体不是"帮你查资料",而是"替你盯产线、做决策、下指令"。
以中国石化"烽火"智能体为例,它要做的不是回答"催化裂化原理是什么",而是——根据实时进料成分、反应器温度场分布、历史最优工况,自动调节操作参数,把能耗压到最低。
这种能力的背后,不是一个大模型单打独斗,而是**"领域大模型 + 实时数据流 + 数字孪生仿真"**的三位一体。
二、数字孪生:为什么它是大模型落地工业的"数据轴承"?
"模数共振"的核心逻辑是**"数据飞轮"**:
工业数据 → 训练行业模型 → 模型优化作业场景 → 场景产生新数据 → 数据再反哺模型
这个飞轮要转起来,有一个关键瓶颈:高质量、结构化、带物理约束的工业训练数据,极度稀缺。
为什么稀缺?
第一,工业数据是"经验型"的。
很多关键工艺知识存在于老师傅的手感和经验里,而不是数据库里。焊接时的电流微调、注塑机的压力补偿、轧机的辊缝控制——这些隐性知识难以被大模型直接学习。
第二,工业数据是"场景型"的。
你想训练一个"焊缝质检AI",只喂它几张焊缝照片远远不够。AI需要理解的是:焊接过程中的温度场演变、熔池流动动力学、材料相变规律。 这些数据无法通过简单的传感器采集获得,必须通过物理仿真来生成。
第三,工业数据是"高风险型"的。
你不能在真实产线上反复做破坏性试验来收集数据。故障数据、极限工况数据、安全事故数据——这些"长尾场景"的数据,往往只能在数字孪生里"安全地"生成和迭代。
这时候,数字孪生的价值就凸显出来了:
它不只是"把设备画成3D模型摆在屏幕上看",而是构建一个跟物理实体同步呼吸、能跑仿真、能出数据的"虚拟工厂"。
在这个虚拟工厂里,你可以:
-
零成本试错:反复模拟极端工况,生成大量"现实中很难遇到"的训练样本;
-
物理保真:基于CAE仿真确保生成的数据符合真实物理规律,而不是让AI学一堆"假数据";
-
全链路闭环:从设计仿真 → 工艺验证 → 产线调试 → 运维优化,数据在一个统一的数字镜像里流动。
所以我说,数字孪生是这个飞轮的"轴承"——没有它,数据和模型之间就缺了一个能把物理世界"翻译"成数字语料的转换器。
三、仿真软件:被低估的"数据生产工具"
如果说数字孪生是"轴承",那**仿真软件(CAE)**就是轴承里的"滚珠"——真正让数据流动起来的核心部件。
这也是我想重点聊的一个被低估的环节。
很多人把仿真理解为"设计阶段的验证工具":做个结构强度分析、算个流场分布,验证通过了就完事。
但在"模数共振"的语境下,仿真的角色正在发生根本性转变——
从"验证工具"变成"数据工厂"。
什么意思?
当大模型需要海量的、带物理约束的、多工况覆盖的训练数据时,真实产线给不了的数据,仿真可以"造"出来。
举个例子:
你在做轨道交通装备的轴承故障预测。真实轴承从正常运行到失效,可能要跑几个月甚至几年,而且你不可能故意把轴承跑到报废来收集故障数据。
但在仿真环境里,你可以:
-
构建轴承的多体动力学模型 + 材料疲劳模型;
-
在几小时内模拟数百万转的运行工况;
-
生成涵盖正常、轻微磨损、裂纹扩展、最终失效全阶段的多维数据(振动、温度、声发射、油液颗粒);
-
把这些高保真数据喂给故障预测大模型,训练出一个能在真实产线上提前数周预警失效的AI。

这就是仿真驱动的人工智能(Simulation-based AI),也是我们在自研仿真软件Pongo上持续投入的核心逻辑——
打通"仿真验证 → 数据沉淀 → 模型训练"的链路,让数字孪生从一个"可视化项目"变成真正的"智能工厂基础设施"。
四、融合架构:数字孪生 + 大模型的三层闭环
理解了各个部件的角色,我们可以画出一个更清晰的技术架构图(文字版)
┌─────────────────────────────────────────────┐│ 物理层(Physical Layer) ││ 产线设备 · 传感器网络 · PLC/SCADA/MES │└──────────────┬────────────────────────────────┘│ 实时数据流▼┌─────────────────────────────────────────────┐│ 数字孪生层(Digital Twin Layer) ││ 三维可视化 · 物理仿真(CAE)· 实时同步引擎 ││ ├─ 几何孪生:设备/产线的1:1三维镜像 ││ ├─ 物理孪生:基于仿真生成高保真训练数据 ││ └─ 数据孪生:多源异构数据的统一语义层 │└──────────────┬────────────────────────────────┘│ 高质量结构化数据▼┌─────────────────────────────────────────────┐│ 模型层(Model Layer) ││ 行业大模型 · 专用小模型 · 工业智能体 ││ ├─ 行业通识模型:跨企业的通用工业知识 ││ ├─ 场景专识模型:针对具体工艺/设备的微调 ││ └─ 工业智能体:感知→推理→决策→执行的闭环 │└──────────────┬────────────────────────────────┘│ 优化指令/策略▼┌─────────────────────────────────────────────┐│ 应用层(Application Layer) ││ 智能排产 · 预测性维护 · 工艺优化 · 质检AI │└─────────────────────────────────────────────┘这个架构里,最关键的设计原则是:
1. 数字孪生不是"展示层",而是"数据层"
它向上给大模型供数据,向下从物理设备接数据,中间通过仿真"补全"那些现实中采集不到的工况。
2. 大模型不是"问答层",而是"推理层"
它接收来自数字孪生的结构化数据 + 领域知识库,输出的是可执行的操作策略,而不是一段文本回复。
3. 智能体不是"应用层",而是"闭环层"
它把大模型的推理结果翻译成具体的控制指令(比如调整PID参数、切换工艺配方),并实时监测执行效果,再反馈给数字孪生,完成循环。
五、行业实践:谁已经在跑通这个架构?
回到"200家卓越级智能工厂"的目标,看看哪些行业正在率先落地这套"数字孪生 + 大模型"的融合架构。
轨道交通装备
中国中车主导的"AI+轨道交通"技术路线已经明确:以数字孪生构建列车全生命周期的数据底座,叠加故障预测大模型,实现从"定期修"到"状态修"的转型。轨博会上展示的新一代智能动车组,已经在试用基于数字孪生的实时健康管理系统。
石油化工
中国石化"烽火"智能体的发布是个标志性事件。它背后的逻辑就是:以工艺装置的数字孪生为底座,把历史工况数据 + 实时DCS数据 + 机理仿真数据融合,训练出能自主优化工艺参数的工业Agent。
海洋工程与船舶
工信部近期报道的**"浪花平台"**(船舶CAE工业软件)首次亮相,国际首创集船舶性能仿真、合同设计、数字化送退审于一体。这意味着船舶领域的数字孪生正在从"展示级"走向"工程级",为未来船舶智能体的训练提供了国产化的数据生产工具。
智能装备与家电
这两个领域的数据基础设施相对更成熟(设备联网率高、数据标准化程度好),是"模数共振"行动中最容易先跑出闭环的行业。不少头部企业已经在试点"数字孪生 + 视觉质检大模型"的产线级应用。
六、写在最后:2026年,制造业的技术栈正在重组
"模数共振"四个字,本质上是在说一件事:
大模型和数据,不是谁服务谁的关系,而是谁也离不开谁的共生关系。
但让它们"共振"起来,需要一个物理世界和数字世界之间的转换器——这就是数字孪生 + 工业仿真的价值。
2026年的制造业技术栈,正在从原来的"单点数字化"(上个MES、装套IoT、做个大屏),重组为"三层闭环":
-
数据层:数字孪生 + 仿真 → 持续生产高质量训练数据
-
模型层:行业大模型 + 专用Agent → 从"能回答"进化到"能决策"
-
应用层:智能排产、预测维护、工艺自治 → 真正的"无人化"不是没有人,而是有"数字员工"
对于技术从业者来说,这意味着:
只会做三维可视化不够了,要懂仿真;只会做仿真也不够,要懂数据怎么喂给模型;只懂模型也不够,要懂产线怎么闭环控制。
制造业的"技术融合"时代,真的来了。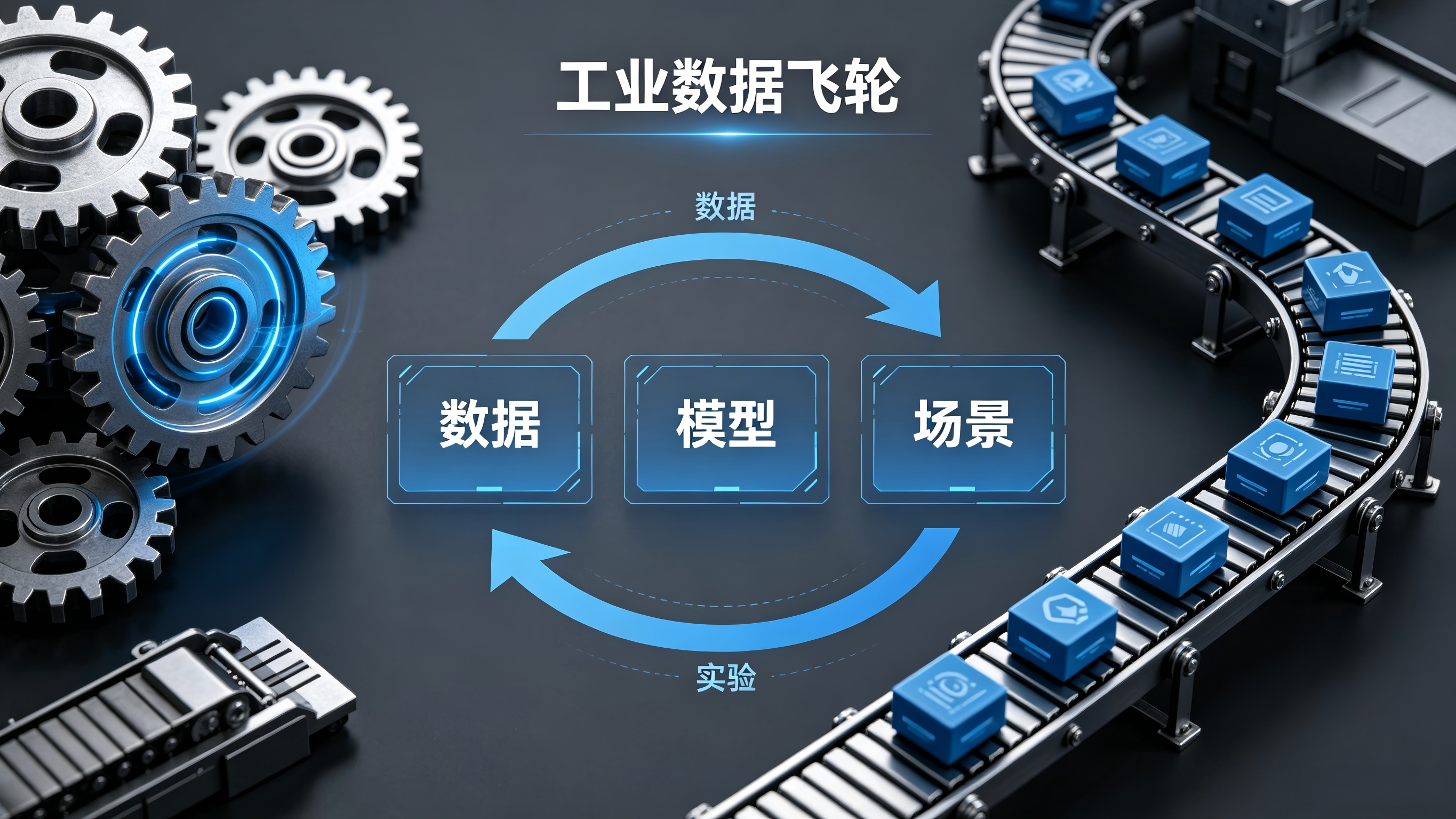
你怎么看工业智能体的落地难度?你们在做数字孪生项目时,最大的数据瓶颈是什么?
欢迎在评论区交流,点赞过100,我下一篇写《从零搭建工业数字孪生的数据 pipeline:仿真数据如何清洗、标注、入库》的实战分享。
本文部分信息参考《工业和信息化部办公厅 国家数据局综合司关于联合实施2026年"模数共振"行动的通知》、中国石化"烽火"工业智能体公开报道、工信部船舶CAE工业软件"浪花平台"相关新闻。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)