使用OpenTelementry来监控英伟达的GPU
本文介绍了轻量级GPU监控工具gpu-observe,它基于NVML库开发,通过OpenTelemetry协议发送GPU指标数据。相比DCGM Exporter,该工具兼容性更好,支持Windows WSL2等环境。文章详细说明了部署方法:1)使用Docker快速搭建OpenTelemetry后端(Grafana LGTM);2)运行单文件agent.py采集GPU使用率、温度、功耗等指标;3)提
1. 介绍gpu-observe
如果要使用OpenTelementry来监控英伟达的GPU,我们一般会采用DCGM Exporter。但是DCGM Exporter的兼容性似乎有一些问题,对设备和软件驱动的版本要求似乎太高了一些。在Windows WSL2之类的平台上也跑不起来。
相反,像nvitop这类的小工具一直能很好的运行。nvitop本身也是依赖 NVML(NVIDIA Management Library)。 那么我按照nvitop提供的支持,写了一个叫做gpu-observe的小应用,把metrics发给OpenTelementry即可。 这个工具应用非常小和轻便, 目前只有一个源程序文件(agent.py),直接运行即可。
在运行应用之前,按照依赖的python包。
pip install -r requirements.txt我们可以通过设置环境变量, 把监控数据通过OTLP/grpc协议发给支持OpenTelemetry的后端服务器, 或者一个OpenTelementry Collector。
默认是发给本机监听4317端口的应用。直接运行agent.py即可。
python agent.py或者指定后端服务器(或者OpenTelementry Collector)的地址再运行:
export OTEL_EXPORTER_OTLP_ENDPOINT="http://<OTel Backend>:4317"
python agent.py我还准备的一个Grafana Dashboard的配置(参见dashboard.json),包括以下图表:
- GPU Usage %
- GPU Memory Usage
- GPU Temperature
- GPU Power Consumption
- Per Process GPU Memory Usage
对于没有OpenTelemetry后端的用户,也可以通过我提供的一个Docker Compose脚本来启动一个本地的OpenTelemetry Collector容器、一个OpenTelemetry Prometheus容器和一个Grafana容器来使用。
2. 用最简单的办法在本地运行GPU监控(第一步):先启动一个最简单的OpenTelemetry的后端工具
OpenTelemetry的后端工具,就是支持OpenTelemetry metrics/traces/logs/profiles的数据库和UI的工具集。最常见的做法还是使用OpenTelemetry Collector来连接不同的后端工具。假如您是初学者,或者系统很小,可以直接使用基于Docker的Grafana LGTM,几乎是一键安装完成,非常简单易行。前提是需要您有个支持Docker的环境。
假设您想把LGTM安装到/opt/lgtm目录 (任何目录均可),下面是命令(假设在Linux系统):
docker pull grafana/otel-lgtm
mkdir /opt/lgtm
cd /opt/lgtm
wget https://raw.githubusercontent.com/grafana/docker-otel-lgtm/main/run-lgtm.sh
chmod +x run-lgtm.sh
sed -i 's/3000:3000/3100:3000/' run-lgtm.sh注意最后一行命令,因为LGTM的Grafana的默认对外端口是3000,这个端口经常和一些应用程序冲突,我就改成了3100.
下面是启动LGTM的方法,就一个命令:
cd /opt/lgtm
./run-lgtm.shLGTM要监听以下的端口:
- 4317/4318 是OTLP端口,用来接受metrics/traces/logs数据
- 3100 是Grafana UI的端口
- 9090 是Prometheus的端口,用于调试
- 4040 是Pyroscope接受Profiles的端口,将来会整合进入4317/4318
3. 用最简单的办法在本地运行GPU监控(第二步):运行gpu-observe的agent.py
1) 克隆Github 项目到你的有GPU卡的机器(拷贝也可以)
git clone https://github.com/liurui-software/gpu-observe.git当然直接把项目里的agent.py下载下来也可以。
2) 在你的Python环境安装依赖包
pip install -r requirements.txt3) 运行 agent
如果你的OpenTelemetry在本机,那就运行以下命令:
python agent.py如果你的OpenTelemetry在远端,假如IP(主机名也可以)是1.2.3.4,那就运行以下命令:
export OTEL_EXPORTER_OTLP_ENDPOINT="http://<OTel Backend>:4317"
python agent.py4. 介绍一下Dashboard
以下是dashboard的示例(为了一些非中文用户,我就采用了英文):
这个dashboard支持多台主机的情况,现在在左上角选择要监控的主机。每个面板显示了GPU号,标注它支持每个主机多张GPU卡。
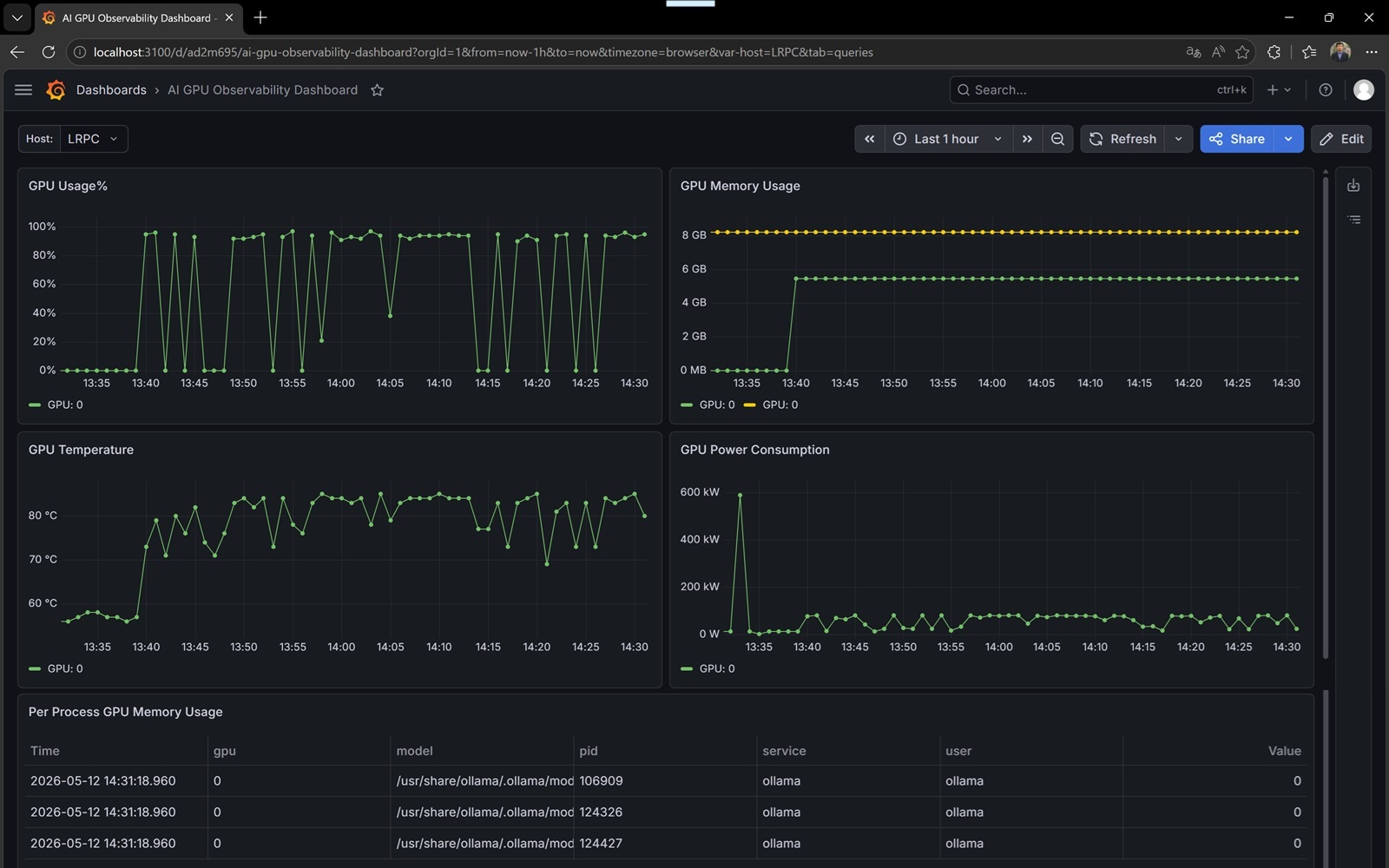
第一行左边是GPU使用率。主要的PMQL是:
sum by(gpu) (gpu_utilization_percent{host_name="$host"})第一行右边是GPU内存使用量。上面的直线是内存总量。主要的PMQL是:
sum by(gpu) (gpu_memory_used_mb{host_name="$host"})第二行左边是GPU温度。主要的PMQL是:
gpu_temperature_celsius{host_name="$host"}第二行右边是GPU功耗。主要的PMQL是:
gpu_power_watts{host_name="$host"}第三行是按照每个进程来统计的GPU内存使用量。主要的PMQL是:
process_gpu_memory_mb{host_name="$host"}从Github的dashboard.json中可以得到完整的Dashboard配置代码。
5. 总结
本文介绍了轻量级GPU监控工具gpu-observe,它基于NVML库开发,通过OpenTelemetry协议发送GPU指标数据。相比DCGM Exporter,该工具兼容性更好,支持Windows WSL2等环境。文章详细说明了部署方法:1)使用Docker快速搭建OpenTelemetry后端(Grafana LGTM);2)运行单文件agent.py采集GPU使用率、温度、功耗等指标;3)提供了预置的Grafana仪表板配置,支持多主机多GPU监控。该方案部署简单,适合中小规模环境,用户可通过Docker Compose快速搭建完整监控栈。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)