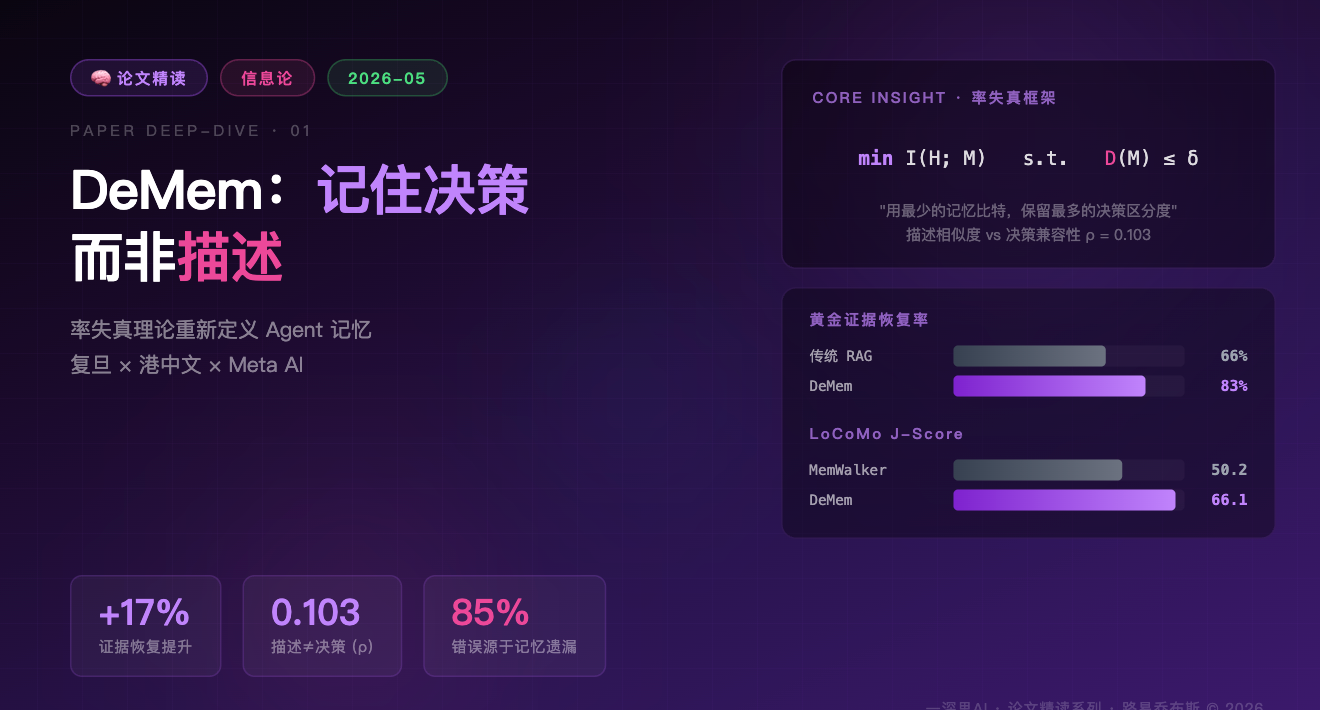
DeMem 深度解读:当 Agent 记忆遇上信息论——“记住决策,而非描述“
普通方法可能因为噪声数据就乱分裂,DeMem 要求统计证据足够强构造下界证书d‾txx′dtxx′,仅当d‾txx′ϵdtxx′ϵ时(即以高概率确认两个上下文不能共享最优动作)才添加 cannot-link 边。实测数据:在 LoCoMo 上,认证分裂仅在4.6%的路由事件上触发,但对黄金标注精度达85%。翻译成白话:DeMem 很少分裂记忆(克制),但一旦分裂就很准(精确)。这比激进分裂
论文: Remember the Decision, Not the Description: A Rate-Distortion Framework for Agent Memory
来源: arXiv:2605.10870 [cs.AI] · 2026-05-11
机构: 复旦大学 × 港中文 × Meta AI × 松鼠AI × Monash × 上海AI for Science研究院
一句话: 用率失真理论重新定义 Agent 记忆——记忆的价值不在于描述过去,而在于保留影响决策的历史区分度。
0. 为什么你应该读这篇论文
如果你做过 Agent 开发,你一定遇到过这个问题:对话越长,Agent 越傻。
不是模型变差了,是记忆系统崩了。Token 窗口就那么大,你要么截断(丢信息),要么摘要(丢细节),要么 RAG 检索(靠相似度赌运气)。这三种方式有一个共同的致命缺陷——它们都在用"描述性标准"决定什么该记、什么该忘。
DeMem 说:你们全错了。记忆系统应该问的不是"这段信息描述了什么",而是"这段信息会不会影响接下来的决策"。
这不是直觉,这是定理。
1. 核心洞察:描述性相似度是骗人的
论文上来就甩了一组数据,在 LoCoMo 长对话基准上:
| 指标 | 数值 | 含义 |
|---|---|---|
| 描述相似度 vs 证据兼容性 Spearman ρ | 0.103 | 几乎无关 |
| 描述相似度 AUC | 0.548 | 比随机猜好不了多少 |
| 描述性检索恢复黄金证据比例 | 66% | 三分之一的关键证据丢了 |
| DeMem 恢复黄金证据比例 | 83% | +17 个百分点 |
| 描述性失败案例中证据遗漏占比 | 85% | 错误的根因就是记错了 |
什么意思? 两段对话看起来很像(描述相似度高),但它们需要的决策可能完全不同。反过来,两段对话看起来毫无关联(描述相似度低),但它们可能需要同一个动作。
传统 RAG 按语义相似度检索记忆 → 高相似但决策无关的信息挤进来 → 真正需要的证据被挤出去 → Agent 做出错误决策。
这就是 DeMem 要解决的根本问题。
2. 理论框架:把记忆问题变成率失真优化
2.1 问题建模:上下文赌博机 + 记忆瓶颈
DeMem 把 Agent 记忆问题形式化为一个记忆受限的上下文赌博机(Contextual Bandit):
- 上下文 x = ( h , q ) x = (h, q) x=(h,q):历史 h h h + 当前查询 q q q
- 动作 a ∈ A a \in \mathcal{A} a∈A:Agent 的响应
- 奖励 μ ( x , a ) \mu(x, a) μ(x,a):做对了得 1 分,做错了得 0 分
- 约束:Agent 不能看到完整历史 h h h,只能通过 K K K 个记忆槽的编码 m = g ( h , q ) ∈ [ K ] m = g(h, q) \in [K] m=g(h,q)∈[K] 来间接访问
这意味着 Agent 的策略链变成:
完整历史 h → 编码器 g(h,q) → 记忆状态 m ∈ {1,...,K} → 决策规则 π(m,q) → 动作 a
记忆编码器就是一个有损压缩器,问题是:怎么压缩才能让决策损失最小?
2.2 决策失真 vs 描述失真
传统压缩关心重构误差(压缩后能不能还原原文)。DeMem 定义了一个全新的失真度量——决策失真:
d q ( h , m ; π q ) = μ q ⋆ ( h ) − μ q ( h , π q ( m ) ) d_q(h, m; \pi_q) = \mu_q^{\star}(h) - \mu_q(h, \pi_q(m)) dq(h,m;πq)=μq⋆(h)−μq(h,πq(m))
翻译成白话:因为你把历史 h h h 压缩成了记忆状态 m m m,Agent 做出的决策比最优决策差了多少。
这个定义的美妙之处在于——它完全不关心你是怎么压缩的、压缩后长什么样、能不能还原原文。它只关心一件事:你的压缩有没有导致 Agent 做出更差的决策。
2.3 精确遗忘边界(Theorem 1)
定理 1: 一组历史 C C C 可以共享同一个记忆槽(即"可以安全遗忘它们之间的差异"),当且仅当存在一个动作 a a a 对所有 h ∈ C h \in C h∈C 都是 ϵ \epsilon ϵ-最优的。
直觉解释:
- 张三和李四去年分别买了苹果和华为手机(描述完全不同)
- 但如果你推荐"小米"对两个人都是不错的选择(共同近似最优动作存在)
- 那么在这个推荐场景下,"张三 vs 李四"的区分可以安全遗忘
反过来:
- 王五和赵六都是程序员(描述很像)
- 但王五需要推荐 MacBook 而赵六需要推荐 ThinkPad(不存在共同近似最优动作)
- 那么即使他们描述再像,也不能合并记忆
关键区别:传统方法按"描述距离"决定能否合并,DeMem 按"决策距离"决定。这就是论文标题的精髓——Remember the Decision, Not the Description。
2.4 记忆-失真前沿(Memory-Distortion Frontier)
类比经典率失真理论的 R(D) 曲线,DeMem 定义了:
ϵ ∞ ⋆ ( K ; q ) = inf g q , π q sup h d q ( h , g q ( h ) ; π q ) \epsilon^{\star}_{\infty}(K; q) = \inf_{g_q, \pi_q} \sup_{h} d_q(h, g_q(h); \pi_q) ϵ∞⋆(K;q)=gq,πqinfhsupdq(h,gq(h);πq)
意思是:在 K 个记忆槽的预算下,最坏情况决策失真最小能到多少?
这条曲线就是理论极限。任何记忆系统在 K 槽下都不可能做得比这更好。DeMem 的目标是逼近这条线。
2.5 计算困难性(Theorem 3)
定理 3: 判定 K 个记忆槽是否能达到失真 ≤ ϵ \leq \epsilon ≤ϵ 是 NP 完全问题。
证明思路很巧妙:从 Set Cover(集合覆盖)规约。把上下文集映射为全集 U \mathcal{U} U,动作映射为子集。一个记忆集群有失真 ≤ ϵ \leq \epsilon ≤ϵ 当且仅当该集群的所有上下文被某个动作(子集)覆盖。
含义:精确最优解算不出来,必须走在线近似路线。这为 DeMem 的贪婪算法提供了理论合理性。
3. DeMem 算法:只在必要时分裂记忆
3.1 核心思想:认证分裂(Certified Split)
DeMem 不是预先规划记忆分区,而是在线学习——边交互边优化。核心操作是认证分裂:
- 开始时把所有历史扔进同一个记忆槽
- 交互过程中收集数据
- 只有当数据证明两个上下文共享记忆槽会导致决策冲突时,才分裂
- 分裂使用统计证书(confidence bound),不是拍脑袋
Algorithm 1: DeMem in one loop
for each epoch e:
# 1. 行动:用当前分区 P_e 路由记忆,UCB 选动作
for each round in epoch:
m_t ← g_{P_e}(x_t) # 编码到记忆槽
a_t ← UCB(m_t, x_t) # 探索或利用
observe reward, update stats
# 2. 认证:构建"不能合并"图
E_e ← {(x,x'): 统计证据表明 d_dec(x,x') > ε}
# 3. 刷新:贪婪着色得到新分区
P_{e+1} ← GreedyColor_K(E_e)
3.2 为什么是"认证"分裂?
普通方法可能因为噪声数据就乱分裂,DeMem 要求统计证据足够强:
构造下界证书 d ‾ t ( x , x ′ ) \underline{d}_t(x, x') dt(x,x′),仅当 d ‾ t ( x , x ′ ) > ϵ \underline{d}_t(x, x') > \epsilon dt(x,x′)>ϵ 时(即以高概率确认两个上下文不能共享最优动作)才添加 cannot-link 边。
实测数据:在 LoCoMo 上,认证分裂仅在 4.6% 的路由事件上触发,但对黄金标注精度达 85%。
翻译成白话:DeMem 很少分裂记忆(克制),但一旦分裂就很准(精确)。这比激进分裂 + 高错误率好得多。
3.3 遗憾保证
定理 4 (上界):
R e g ( T ) ≤ T ⋅ O ( ϵ ˉ T c e r t ) + O ~ ( A K T ) + O ( A N T B T ( γ ) ) \mathrm{Reg}(T) \leq T \cdot O(\bar{\epsilon}^{\mathrm{cert}}_T) + \tilde{O}(\sqrt{AKT}) + O(AN_T B_T(\gamma)) Reg(T)≤T⋅O(ϵˉTcert)+O~(AKT)+O(ANTBT(γ))
三项的含义:
| 项 | 是什么 | 能不能消除 |
|---|---|---|
| T ⋅ O ( ϵ ˉ T c e r t ) T \cdot O(\bar{\epsilon}^{\mathrm{cert}}_T) T⋅O(ϵˉTcert) | 已实现的压缩误差 | 受限于 K 槽预算,是结构性损失 |
| O ~ ( A K T ) \tilde{O}(\sqrt{AKT}) O~(AKT) | K 个记忆状态上的统计学习开销 | 标准赌博机学习率,不可避免 |
| O ( A N T B T ( γ ) ) O(AN_T B_T(\gamma)) O(ANTBT(γ)) | 认证探索开销 | 随 T 增长亚线性 |
定理 5 (下界):
inf a l g sup μ , D E [ R e g ( T ) ] ≥ c ⋅ T ⋅ ϵ ∞ ⋆ ( K ) + c A K T \inf_{\mathrm{alg}} \sup_{\mu, \mathcal{D}} \mathbb{E}[\mathrm{Reg}(T)] \geq c \cdot T \cdot \epsilon^{\star}_{\infty}(K) + c\sqrt{AKT} alginfμ,DsupE[Reg(T)]≥c⋅T⋅ϵ∞⋆(K)+cAKT
结论:DeMem 在统计学习项 A K T \sqrt{AKT} AKT 上匹配极小极大下界(对数因子内)。剩余差距仅来自认证过程的有限样本精度——理论上可以随 T 增长渐近消失。
4. 实验:不是小幅提升,是范式级的碾压
4.1 LoCoMo 长对话基准
DeMem 对比了 8 个基线方法,在 GPT-4o-mini 和 GPT-4.1-mini 两个骨干上:
| 方法 | Temporal | Open Domain | Multi-Hop | Single-Hop | Overall |
|---|---|---|---|---|---|
| RAG | 0.572 | 0.590 | 0.543 | 0.698 | 0.637 |
| Mem0 | 0.453 | 0.365 | 0.552 | 0.644 | 0.570 |
| MemGPT(Zep) | 0.545 | 0.336 | 0.457 | 0.592 | 0.541 |
| Mnemis (SOTA) | 0.878 | 0.793 | 0.798 | 0.938 | 0.888 |
| DeMem | 0.919 | 0.868 | 0.847 | 0.932 | 0.911 |
亮点:
- 比 RAG +27.4 个百分点(0.637 → 0.911)
- 比 Mem0 +34.1 个百分点
- 比前 SOTA(Mnemis) +2.3 个百分点
- Temporal 和 Open Domain 优势最大——这正是需要跨远距离交互保留决策区分的场景
4.2 合成实验:当描述与决策不匹配时
论文设计了一个精妙的合成实验(Decoupled Bandit):故意让描述性表示与潜在决策身份不对齐。
结论:不匹配程度越大,DeMem 对描述性方法的优势越大。
这验证了核心论点——当"看起来像"和"该怎么做"脱钩时,基于描述的记忆系统就会系统性地犯错。
4.3 消融实验:每个组件都不可或缺
| 消融 | 影响 |
|---|---|
| 移除认证分裂 → 激进分裂 | 性能显著下降(过度细分浪费记忆槽) |
| 移除认证分裂 → 随机分裂 | 更差 |
| 改为描述性路由(embedding相似度) | 下降 |
| 改为仅摘要记忆 | 下降 |
5. 工程启示:对 Agent 开发者意味着什么
5.1 记忆系统设计原则
| 旧范式 | DeMem 范式 |
|---|---|
| 按语义相似度检索 | 按决策区分度组织 |
| “这段记忆跟当前问题像不像?” | “这段记忆会不会改变我接下来该做什么?” |
| 遗忘 = 删除最旧/最不相关的 | 遗忘 = 合并不影响决策的历史 |
| 记忆质量 = 重构精度 | 记忆质量 = 决策保真度 |
5.2 落地建议
1. 任务型 Agent(客服/工单/迁移助手)
这类 Agent 的记忆系统可以直接借鉴 DeMem 的"遗忘边界":如果两个客户的历史对话虽然内容不同,但最终都需要"升级工单"这个动作,那它们的记忆可以合并。
2. 长对话 Agent(数字分身/个人助理)
对话超过 50 轮时,传统摘要策略会丢失关键决策信息。DeMem 的"决策失真"度量可以替代"信息量"度量来指导摘要——只保留会改变未来推荐/建议的细节。
3. 多 Agent 协作系统
当多个 Agent 共享记忆池时,DeMem 的 K-槽分区天然适合做记忆分片——不同 Agent 关注不同决策维度,各自维护自己的决策相关分区。
5.3 跟现有系统的关系
DeMem 不是要替代 RAG 或 MemGPT,而是在它们之上加一层决策感知的组织逻辑:
传统: 原始记忆 → Embedding → 向量检索 → LLM
DeMem: 原始记忆 → 决策区分分析 → K-槽分区 → 分区内检索 → LLM
↑ 这一层是 DeMem 的贡献
论文原文也明确说了:“DeMem 最好被视为补充更丰富描述性记忆存储的有预算决策层。”
6. 与其他记忆框架的对比
| 框架 | 核心范式 | 压缩策略 | 理论保证 | 决策感知 |
|---|---|---|---|---|
| RAG | 相似度检索 | Top-K | 无 | ❌ |
| MemGPT | 分层存储 | LRU 换入/换出 | 无 | ❌ |
| Mem0 | 图结构 | 实体合并 | 无 | ❌ |
| A-Mem | 自组织 | 灵感模式 | 无 | ❌ |
| Memory-T1 | 学习式 | 元学习 | 部分 | 部分 |
| DeMem | 率失真 | 认证分裂 | 近极小极大 | ✅ 核心 |
DeMem 是目前唯一一个有信息论最优性保证的 Agent 记忆框架。
7. 局限性与思考
论文自身的局限
- 上下文赌博机假设:论文用上下文无关的赌博机建模,真实 Agent 交互是有状态的 MDP。作者在结论中也提到了这个扩展方向。
- 有限上下文集:论文假设 ∣ H ∣ |\mathcal{H}| ∣H∣ 有限。连续/高维历史空间需要额外的离散化步骤。
- 计算开销:虽然认证分裂只触发 4.6% 的事件,但构建 cannot-link 图仍需 O ( N 2 ) O(N^2) O(N2) 成对比较。
我的思考
这篇论文最大的价值不在于 DeMem 算法本身(实现并不复杂),而在于它改变了思考记忆系统的方式:
- 以前我们问:“什么信息应该放进记忆?”——这是描述性问题
- 现在我们应该问:“什么信息的缺失会导致错误的决策?”——这是决策性问题
这个视角转换适用于所有 Agent 记忆系统的设计,无论你用的是 RAG、图数据库、还是向量存储。
8. 总结
DeMem 用一句话概括:在有限记忆预算下,保留那些对决策有区分度的历史信息,合并那些对决策无差异的历史信息。
它的贡献不是"又一个记忆系统",而是给 Agent 记忆提供了信息论意义上的最优性框架——什么该记、什么该忘、什么时候分裂、什么时候合并,全部有数学上的最优解和可证明的近似保证。
对于正在构建 Agent 系统的工程师,最直接的启示是:下次设计记忆模块时,先问"这个记忆是否影响决策",再问"这个记忆是否相关"。
原文: arXiv:2605.10870
作者: Mingxi Zou (复旦) et al.
关键词: Agent Memory, Rate-Distortion Theory, Decision-Centric, Forgetting Boundary, Online Learning

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)