我用 Tushare + Claude Code,手搓了一套本地股票数据同步系统(已开源)
在交互方式上,我最后选的是 CLI。原因有两个。第一,CLI 足够轻。对于这种本地同步系统来说,很多操作本来就是命令式的,比如初始化、全量同步、增量更新、查看状态、跑测试。CLI 反而是最自然的形态。第二,后续更方便 AI 接管。因为命令行本身就是标准化的输入输出接口。你把能力做成命令,后面不管是 Claude Code、Codex,还是别的 agent,要接入都更容易。也就是说,我一开始就在往"
🔗 开源项目地址:https://github.com/zer0quant/zer0share
欢迎 Star / Issue / PR,后续模块会陆续合并进去。
这几个月,OpenClaw 小龙虾很火,我也看到不少人用它去网上抓行情数据。
但抓别人家的行情数据,其实有几个很现实的问题:
- 不稳定:别人家的服务不是专门给你做数据底座的,接口随时可能变,抓取逻辑也可能随时失效;
- 容易打扰别人的服务器:你抓得越频繁,对方压力越大;
- 可持续性差:很多这类方案前期看起来能用,后面往往就是不断修修补补,代码改了一遍又一遍;token 还会在不知不觉中被消耗掉。
所以,想真正把数据这件事做好,最稳妥的方式还是自己搭一套本地数据系统。
这篇文章,我就以日线行情模块为例,讲讲我是怎么用 Tushare + Claude Code,手搓一套开箱即用的小型数据同步系统的。
一、先别急着写代码,先把数据源想清楚
搭建数据系统,第一件事永远不是写代码,而是先想清楚数据源。
这次我选的是 Tushare。
原因很简单:对个人开发者来说,它的性价比非常高。捐赠 200 元,拿到 2000 积分,就能拥有一套相对稳定、质量也不低的日线行情数据源。拿它来搭一个个人版的小型本地数据库,其实非常合适。
如果只是做个人研究、做因子、做回测、做一些轻量级策略验证,Tushare 已经够用了。
二、我的目标,不是"拉到数据",而是"搭成系统"
很多人做数据,目标其实只是"把数据拉下来"。
但我这次想做的不是一次性脚本,而是一套能长期用的本地数据同步系统。
也就是说,它至少要满足这几个要求:
- 数据源清晰
- 存储结构清晰
- 支持全量同步
- 支持增量更新
- 有统一的交互方式
- 后续方便继续扩展别的数据模块
- 最好还能让 AI 比较容易接管
所以从一开始,我就不是按"写几个脚本"去做的,而是按"搭一个最小可用的数据底座"去设计的。
三、开发方式上,我选择让 AI 参与,但不放弃工程流程
这次我主要用的是 Claude Code,并且装了 superpowers skill。
这个 skill 对我来说最大的帮助,不是"写代码更快",而是让整个开发流程更规范了。它比较适合做这样一类事情:
先头脑风暴,收敛需求 → 再把需求写清楚,形成架构文档 → 然后继续往下拆任务 → 最后一步步实现
也就是说,AI 在这里不是单纯的代码生成器,而更像一个参与工程流程的助手。
这点我觉得很重要。因为如果你只是把一句模糊需求直接扔给 AI,让它开始生成,最后大概率会得到一堆"看起来能跑,但不好维护"的东西。
但如果你先把系统边界、模块分工、存储结构、交互方式都想清楚,再让 AI 进入实现阶段,产出的质量会高很多。
四、先做整体架构,再做存储分区
确定好数据源后,我先做了整体架构设计。

核心思路并不复杂,本质上就是把整个系统拆成几个部分:
- 数据源层:负责和 Tushare API 交互
- 同步层:负责全量拉取、增量更新、调度执行
- 存储层:负责本地数据落盘
- 交互层:负责让人和系统沟通
- 文档与测试层:保证系统后续可维护、可验证
这个技术栈我最后选得比较克制,整体追求的是简洁和通用,不是堆很多花里胡哨的东西。因为对个人数据系统来说,最重要的不是"架构看起来高级",而是"稳定、透明、好维护"。
接着我又设计了存储的分区结构。

这一步也很关键,因为如果你一开始不把数据怎么存想清楚,后面同步逻辑、查询逻辑、更新逻辑全都会乱掉。
我的理解是:一个小型本地数据系统,不需要一上来就搞得特别重,但一定要先把目录结构、表结构或者分区逻辑设计清楚。否则后面每加一个模块,系统都会越来越难维护。
五、交互方式上,我最后选择了 CLI
在交互方式上,我最后选的是 CLI。

原因有两个。
第一,CLI 足够轻。 对于这种本地同步系统来说,很多操作本来就是命令式的,比如初始化、全量同步、增量更新、查看状态、跑测试。CLI 反而是最自然的形态。
第二,后续更方便 AI 接管。 因为命令行本身就是标准化的输入输出接口。你把能力做成命令,后面不管是 Claude Code、Codex,还是别的 agent,要接入都更容易。
也就是说,我一开始就在往"未来能被 AI 自动调度"的方向设计,而不是只考虑手动点几下能不能跑。
六、第一版功能做完后,我发现真正的坑来了
整体功能初版做完之后,我 review 了一遍代码。
从表面上看,这套代码已经比较完整了,结构也比较简洁,测试样例也有。但仔细往下看,我很快发现还是有坑。
于是我换了另外一个工具 Codex 来继续填坑。
然后就发现了一个非常关键的问题:系统里没有保留所有基础信息。

再往下看,我意识到,最核心的缺失其实是——交易日历。
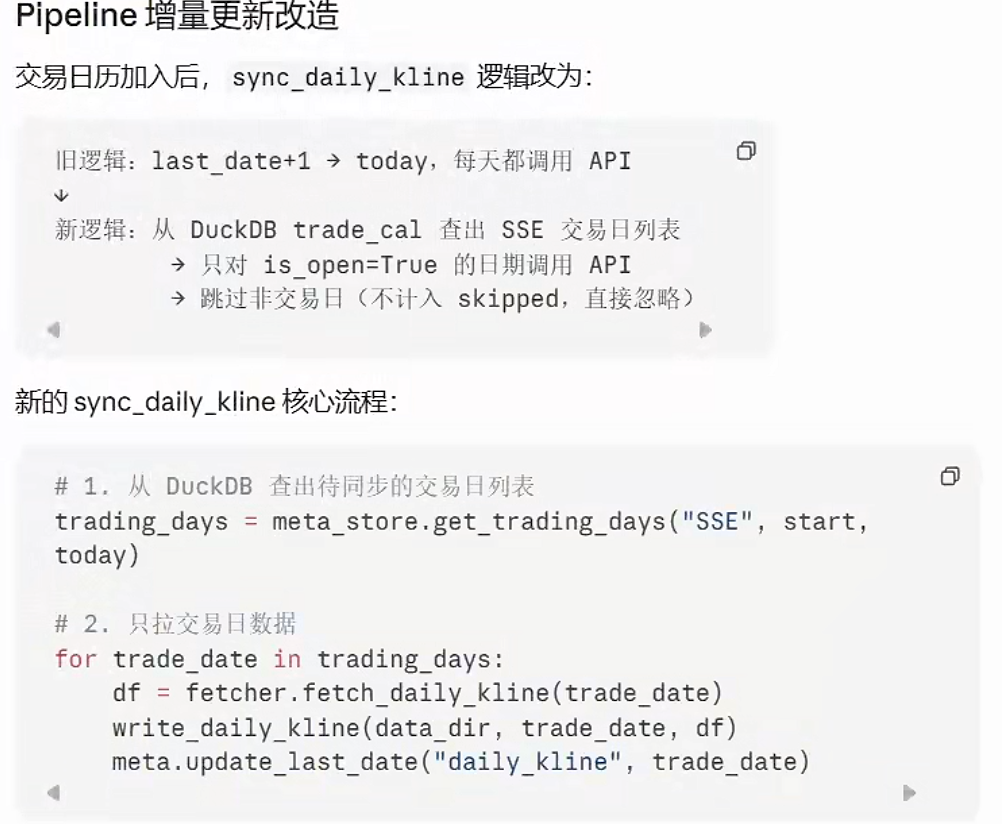
这个问题看起来小,但其实非常关键。
因为不管是历史数据全量同步,还是后续增量更新,本质上都不应该"盲目拉数据",而应该从交易日历开始。
换句话说,交易日历不是一个可有可无的附属功能,而应该是整个数据同步系统的起点。
这是这次开发里我觉得最有价值的一个修正点。
很多人做行情同步,会直接按股票代码、按日期区间、按接口一把拉。但如果没有交易日历这个基础模块,很多事情都会变得不够严谨:
- 你不知道哪些天本来就不开盘
- 你不知道增量更新应该从哪个有效交易日开始
- 你也很难把同步逻辑真正标准化
所以后面我又把交易日历功能补上了。
七、补上交易日历之后,系统才真正像一个"系统"
把交易日历补进去之后,这套系统的逻辑就顺了很多。
因为这时候,全量同步和增量更新终于有了统一起点:
先更新交易日历 → 再基于交易日历判断需要同步哪些交易日 → 然后再去同步对应的日线行情数据
这样整个链路就从"按接口拉数据"变成了"按交易日驱动的数据同步系统"。
这个变化其实非常重要。因为一旦同步逻辑是围绕交易日历组织的,后续你再扩展别的数据模块,比如复权因子、财务数据、指数数据、ETF 数据,整体的思路都会更统一。
八、后面做的事情,其实都是工程化细节的完善
核心链路打通之后,我后面做的工作主要有三块。
第一块,是继续补稳定性。 我根据日线行情文档,把一些细节再完善了一遍,让同步过程更稳一些。

第二块,是补文档。 这个步骤我觉得很多人容易忽视,但实际上非常重要。因为代码只是系统的一部分,文档才是后续自己复盘、扩展、交给 AI 继续接管时的上下文基础。

九、最后测试下来,结果还不错
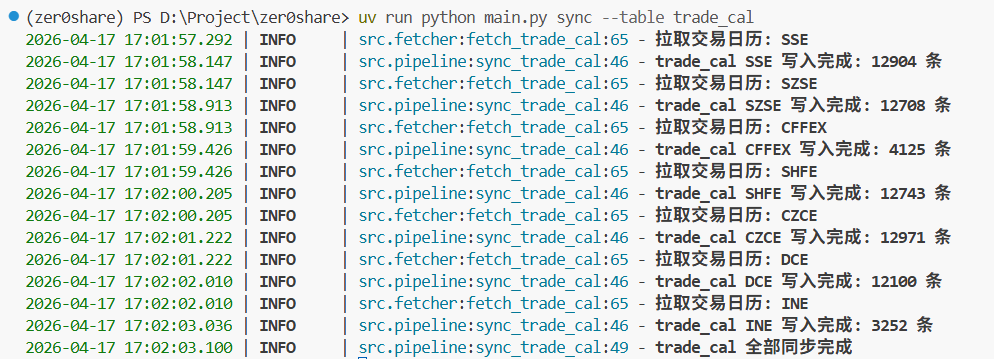
最后实际测试跑了一下,交易日历和日线模块都能正常完成。
先看交易日历同步——8 个交易所的日历几秒钟就拉完了:
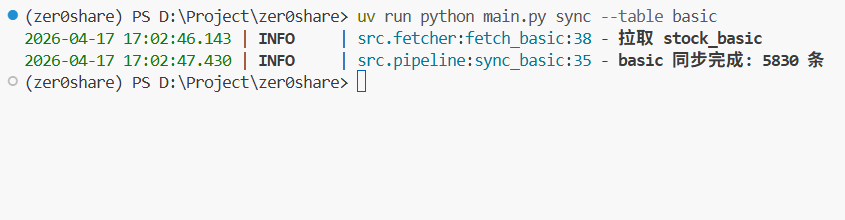
接着是 stock_basic 基础信息:
最后是日线行情。全量同步大概需要 1 个小时左右,跑完之后用 status 命令一看,三张表的更新时间都对得上:
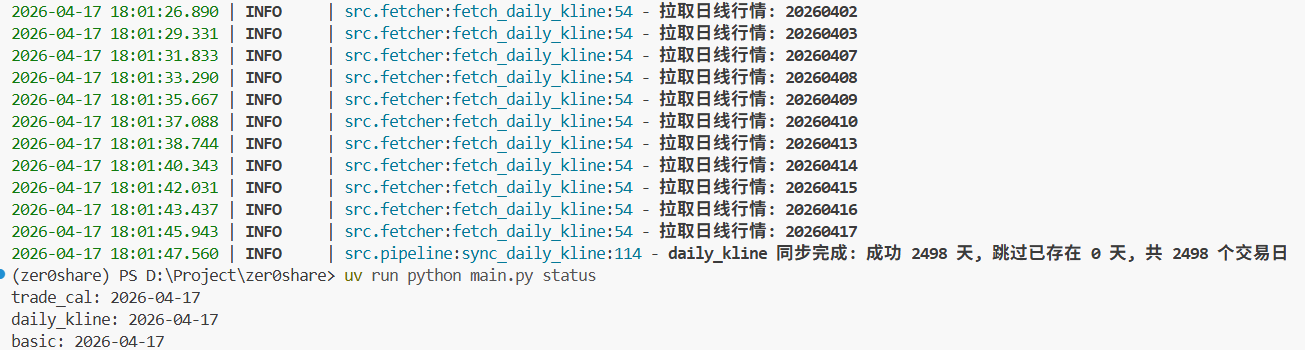
对于一个个人本地数据系统来说,这个速度我是能接受的。因为它至少说明了三件事:
- 这套链路已经能跑通
- 这不是一个只停留在设计图上的系统
- 它已经具备了继续扩展的基础
到这里,这个 Tushare 数据同步系统,算是完成了第一个可用版本。
十、这次最大的收获,不是代码,而是系统思维
回过头看,这次开发我最大的收获,其实不只是"写出了一套同步代码"。
更重要的是,我把自己对"小型本地数据系统"的一些想法,真正落地了一遍。
比如:
- 数据系统一定要先从数据源和边界开始想
- 不要一上来就写脚本,要先做架构和存储设计
- CLI 是一种很适合本地数据系统的交互形态
- AI 可以参与开发,但前提是工程流程不能丢
- 交易日历应该是整个行情同步系统的起点,而不是附属模块
这些东西,单独看都不复杂。但只有你真正把系统从 0 到 1 搭起来,踩过坑,再补回来,才会对这些点有真正的体感。
十一、写在最后
这篇文章讲的,其实只是整个数据系统的第一步。
目前我完成的是:
- 基于 Tushare 的本地数据同步系统雏形
- 包含交易日历和日线行情模块
- 支持从工程化流程出发进行设计、实现、测试和补坑
下一步,我会继续整理一下前后复权数据的合成逻辑。因为只有把复权这部分也补齐,这套数据底座才算更适合后面的因子研究、回测和策略开发。
下篇继续讲,怎么合成前复权和后复权数据。
如果这篇文章对你有帮助
- ⭐ Star 一下项目:https://github.com/zer0quant/zer0share
- 关注公众号,下篇更新第一时间通知
- 有想法、有 bug、有功能建议,欢迎在 GitHub 提 Issue 或直接 PR
我们下篇见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)