某大型制造集团基于Agent本体的设备全生命周期智能运维自治系统建设方案(WORD)
随着制造业数字化转型深入,传统运维模式已难以满足复杂设备的高效保障需求,亟需构建自主化运维体系。本项目拟建设基于Agent本体的设备全生命周期智能运维自治系统,核心内容包括:应用ReAct框架构建自主感知决策机制,集成Tool-Use工具调用与知识图谱推理实现精准诊断,并结合长期记忆管理与任务规划优化运维路径。预期目标是实现从预测性维护向设备健康自愈的演进,通过企业智能体落地,显著降低非计划停机率
导读: 随着制造业数字化转型深入,传统运维模式已难以满足复杂设备的高效保障需求,亟需构建自主化运维体系。本项目拟建设基于Agent本体的设备全生命周期智能运维自治系统,核心内容包括:应用ReAct框架构建自主感知决策机制,集成Tool-Use工具调用与知识图谱推理实现精准诊断,并结合长期记忆管理与任务规划优化运维路径。预期目标是实现从预测性维护向设备健康自愈的演进,通过企业智能体落地,显著降低非计划停机率,提升运维效率,打造工业智能化运维新标杆。

第1章 项目概述与建设背景
大型制造集团的设备运维体系正处于从传统信息化向高阶智能化演进的关键节点。随着生产线自动化程度的提升,单体工厂集成的PLC节点、传感器及工业机器人数量呈指数级增长,每日产生的异构遥测数据规模已突破PB级。传统的基于固定阈值告警与人工经验触发的运维模式,在面对多工况耦合、非线性衰减及复杂故障模态时,暴露出响应滞后、误报率高、专家知识难以沉淀等系统性缺陷。本章旨在界定集团设备运维智能化转型的技术边界,论证引入具备自主推理与工具调用能力的AI Agent(智能体)集群的必要性。将大语言模型的逻辑推理能力与工业现场的实时控制逻辑相结合,旨在构建一套覆盖预测性维护、故障根因定位及自动化处置的闭环体系,从而为集团资产全生命周期管理的数字化升级提供工程约束框架与战略演进路径。在当前的工业4.0语境下,设备运维不再仅仅是保障生产连续性的辅助手段,而是企业优化生产效率、降低运营成本的核心竞争力。集团在数字化转型进入复杂业务逻辑重构阶段后,面临的核心挑战在于如何将海量的工业原始数据转化为可执行的决策指令。传统的专家系统依赖于预设的逻辑分支,难以处理生产环境中的动态变量。而Agent技术的引入,本质上是为工业系统植入了一个具备自学习能力的数字大脑,使其能够在无人干预或弱干预的情况下,完成从异常感知到方案生成的全链路操作。这种转型不仅是技术栈的更新,更是运维哲学从“事后补救”向“事前预防”的根本性转变,旨在通过高维度的认知智能解决底层物理世界的确定性运行问题。
1.1 行业背景与痛点分析
当前大型制造集团的设备管理普遍面临“数据丰富但信息贫乏”的困境。底层SCADA系统与上层EAM、MES系统之间存在严重的协议壁垒,Modbus、OPC-UA、S7等多种工业协议并存,导致运维人员在处理突发停机事故时,需在多个孤立系统间手动切换以调取历史维修记录与实时运行参数。这种碎片化的信息流转模式极大地拉长了平均修复时间(MTTR)。此外,工业现场的设备手册、故障案例库多以非结构化文档形式存在,传统检索技术无法实现对复杂技术问题的精准语义匹配。随着资深技师的流失,核心运维经验面临断层风险,亟需一种能够理解复杂工业语境并实现知识自动检索与应用的工程化方案。在实际生产场景中,设备故障往往呈现出隐蔽性强、关联度高的特点,单一维度的传感器数据难以支撑根因定位。例如,电机轴承的异常振动可能源于上游供电波动或下游负载突变,这种跨系统的因果链条超出了传统监控系统的处理能力,迫切需要引入具备全局感知能力的智能体来重构运维逻辑。
1.2 Agent技术引入的必要性与价值
引入AI Agent技术是解决上述工程痛点的核心手段。不同于传统的判别式AI模型,Agent能够依托大语言模型的泛化理解能力,对多源异构数据进行实时语义对齐。在感知层,Agent通过接入工业物联网网关,实现对振动、温度、电流等关键参数的持续监测;在决策层,利用RAG(检索增强生成)技术,Agent可瞬间调取数万份设备说明书与历史维修日志,生成具备逻辑支撑的诊断建议;在执行层,通过标准化的API接口调用,Agent能够自主触发工单系统或执行基础的远程复位操作。这种从“被动响应”向“主动预见”的范式转移,将直接提升设备综合效率(OEE)。Agent的优势在于其具备“规划-行动-反思”的认知循环,能够根据现场反馈动态调整诊断策略。在面对未知故障时,Agent可以模拟专家的排查思路,通过逐一验证假设来缩小故障范围,这种动态推理能力是传统自动化脚本无法比拟的。同时,Agent集群的协同机制允许不同专业领域的智能体进行联合会诊,从而解决跨学科的复杂运维难题。
1.3 政策依据与立项合规性
本项目建设严格对齐国家《“十四五”数字经济发展规划》中关于“加快制造业数字化转型”的战略部署。政策明确鼓励大型企业利用人工智能、大数据等新一代信息技术改造传统生产流程。集团内部已将“智能运维平台建设”列为年度数字化转型的一号工程,并配套专项资金支持。建立基于Agent的智能运维体系既是对国家工业互联网高质量发展政策的深度响应,也标志着集团在技术层面完成了从传统监控向自主决策的跨越。本项目的实施将为集团后续申请国家级智能制造示范工厂提供核心技术支撑,确保在合规性与前瞻性上达到行业领先水平。此外,本项目符合集团关于“绿色制造”的长期愿景,通过精准的预测性维护,可有效延长设备使用寿命,减少备件浪费,从而在资产管理层面实现降本增效的量化目标。立项过程经过多轮技术论证与经济效益评估,确认其在技术可行性与投资回报率(ROI)方面均符合集团重大项目管理规定。
1.1 建设背景与政策导向
1.1.1 国家智能制造与数字化转型政策解析
当前全球制造业正处于从局部自动化向全面智能化跨越的关键窗口期。依据《数字中国建设整体布局规划》的顶层设计,数字化转型已成为关乎企业长远竞争力的战略基石。该规划明确要求推动数字技术与实体经济深度融合,在重点领域加快数字基础设施建设,为本项目确立了宏观战略坐标。同时,工信部《“十四五”智能制造发展规划》指出,到2025年,规模以上制造业企业应基本实现数字化网络化,重点行业骨干企业初步应用智能化。本项目深度契合“新质生产力”的发展要求,通过构建高可靠的设备智能运维体系,旨在提升工业全要素生产率,降低资源错配率。
从产业升级维度审视,国家政策导向正从单纯的“数字化工厂建设”转向“产业链韧性提升”。智能运维作为工业互联网的核心组成部分,是保障产业链稳定、实现绿色低碳发展的关键技术支撑。本项目引入工业大模型与Agent技术,响应国家关于人工智能赋能新型工业化的号召,致力于解决基础工业软件与高端运维算法的“瓶颈”问题,确保核心生产数据的自主可控与安全合规。在执行层面,方案严格遵循GB/T 39172-2020《智能制造 智能服务预测性维护》等国家标准,确保建设路径在合规性与前瞻性之间达成平衡。
1.1.2 集团设备运维现状与痛点分析
集团目前拥有规模庞大的重型生产设备资产,涵盖从上游原材料加工到下游精细化装配的全链条。然而,现有的运维模式仍带有浓厚的“补救性”特征,难以支撑高质量发展的业务诉求。经过对各分厂、车间的深度调研,核心痛点集中在以下四个维度:
1. 非计划停机频发且损失巨大:由于缺乏实时监测手段,设备故障往往表现为突发性崩溃。关键工序一旦停机,将引发整条生产线的连锁反应。单次核心设备非计划停机导致的直接经济损失(含产线清理、物料报废、交付违约)高达数十万至数百万元,严重干扰年度生产计划的执行。
2. 过度依赖老专家经验,人才断层风险加剧:故障诊断与复杂维修决策高度依赖工龄20年以上的资深技师。这种“师徒制”沉淀的知识碎片化严重,缺乏结构化知识库支撑。随着老一代技术人员陆续退休,生产现场面临严重的经验流失风险,年轻一代运维人员难以在短时间内掌握多维度的设备机理。
3. 系统孤岛导致数据断层与价值湮灭:集团虽已部署ERP、EAM及部分SCADA系统,但各系统间的数据链路处于割裂状态。设备运行状态数据停留在传感器层面,维修履历记录在纸质单据或独立的数据库中,备件库存数据则在另一套逻辑下运行。这种数据断层导致运维决策缺乏全局视野,无法实现跨系统的协同优化。
4. 被动式维修与过度维护并存:目前的维护策略多为“到点保养”或“坏了再修”。前者导致大量尚处于良好运行状态的零部件被提前更换,造成维保成本浪费;后者则让运维团队长期处于“救火式”状态,工作效率低下且安全隐患极高。
下表详细对比了传统运维模式与本项目拟构建的智能运维模式:

1.1.3 从预测性维护到自主自治的演进必然性
技术演进逻辑表明,传统的规则引擎和浅层机器学习模型已达到性能瓶颈。在复杂的工业生产环境中,设备运行参数受温度、湿度、负载变化及原材料波动等多重非线性变量影响,基于简单阈值告警(Threshold-based Alerting)的规则系统极易产生“告警风暴”或漏报。早期的回归算法虽然能处理部分趋势预测,但在面对“长尾场景”(即极少发生但影响巨大的故障)时,往往因为样本量不足导致预测精度大幅下降。
当前技术范式正经历从“预测性维护(PdM)”向“自主自治运维(Autonomous O&M)”的跨越。这种演进的必然性体现在以下三个层面:
认知升维的需求:现代工业设备日益精密,内部机理错综复杂。传统的“黑盒模型”虽能给出预测结果,却无法解释故障根因,导致一线人员难以完全信任算法。基于大模型(LLM)的架构能够将海量非结构化的维修手册、机理文档与实时传感器数据融合,提供具备逻辑解释性的诊断建议,实现从“关联分析”到“因果推理”的跨越。
决策闭环的效率要求:预测只是手段,处置才是目的。传统的维护流程中,即便系统发出预警,仍需人工介入进行工单创建、备件申请、方案制定等环节。引入Agent(智能体)架构后,系统能够根据预警结果,自主调用后端API完成备件预占、自动生成维修路径、并实时调度最优人力资源。这种从“人驱动系统”到“系统驱动人”的转变,是实现运维效率指数级提升的路径。
系统自我进化的能力:自主自治系统具备强化学习能力,能够在每一次故障处置后自动复盘,将处理过程沉淀为新的知识条目。这种基于闭环反馈的自我进化,使得运维平台能够随着运行时间的增加而持续优化模型参数,彻底摆脱对单一专家经验的依赖,构建起企业级的数字资产护城河。向基于大模型与Agent的自主决策演进,不仅是技术层面的升级,更是企业运营逻辑的重塑。
1.2 项目建设目标与愿景
1.2.1 总体建设目标
本项目构建“基于Agent本体的设备全生命周期智能运维自治系统”,核心在于将大语言模型(LLM)的逻辑推理能力与工业现场的多模态感知数据深度耦合。系统不再局限于传统SCADA或CMMS的被动监测模式,而是演进为具备工程语义理解能力的自治实体。Agent本体嵌入设备全生命周期的关键节点,在选型阶段基于历史故障特征库执行可靠性仿真,在运行阶段实时解析传感器时序数据与非结构化日志,在维护阶段自主生成最优检修路径。建立覆盖选型、调试、监测、诊断、预测、联动及报废的全链路治理体系,驱动设备资产从物理实体向智能数字资产转变。
技术架构确立“感知-推理-决策-执行”的闭环逻辑。感知层整合高频振动、热成像及声纳等多模态数据,构建高保真数字孪生体,为Agent提供实时环境上下文。推理层依托Agent本体对复杂工况进行语义建模,结合专家知识图谱执行多维根因溯源,将碎片化报警转化为结构化的故障链条。决策层利用强化学习算法在生产计划、备件库存、人力成本等多约束条件下求解最优运维方案。执行层通过标准化接口(如OPC-UA、MQTT)将决策指令下发至DCS/PLC控制系统或移动运维终端。该系统确立了工业智能化运维的工程范式,将设备管理由被动维修转变为基于数据驱动的预测性自治,打造行业内可复制的设备资产智慧化管理标杆。
1.2.2 核心量化指标定义
为量化评估系统建设成效,本方案定义了覆盖运行稳定性、响应时效、资源效能及智能决策四个维度的指标矩阵,作为系统验收与持续迭代的基准线。
设备运行稳定性维度以非计划停机率降低30%为核心目标。系统部署亚秒级监测算法,针对关键转动部件的频谱特征及电气回路的瞬态变化进行特征提取。Agent本体通过长短期记忆网络(LSTM)与Transformer架构预测性能衰减趋势,在故障临界点前24至48小时触发预警。此机制将突发性抢修转化为计划内预防性维护,有效规避产线非预期停工带来的经济损失。
响应效率的提升体现在平均修复时间(MTTR)缩短40%。系统在报警触发瞬间,由Agent自动完成故障根因定位,并从非结构化技术手册与历史工单中检索匹配的处置规程(SOP)。故障诊断时间从小时级压缩至分钟级,配合精准备件清单的实时推送,消除了传统运维中信息检索与方案验证的冗余环节,实现“方案找人”的作业模式。
资源管控侧重于备件库存周转率提升25%。系统建立预测性维护计划与仓储管理系统的动态联动机制。Agent根据设备健康度评分(Health Score)预测未来周期的备件消耗概率,自动优化安全库存水位并触发采购申请。这种基于实际工况的按需供应模式,能够显著降低呆滞物资占比,释放企业流动资金压力,实现供应链与运维链的深度协同。
智能化程度的衡量标准定为Agent自主决策采纳率超过85%。系统引入人工反馈强化学习(RLHF)机制,通过一线工程师对Agent生成的诊断建议进行标注与修正,驱动模型在复杂、罕见工况下的决策精度持续进化。当系统在绝大部分常规运维场景中具备独立决策与执行能力时,即达成运维自治的阶段性目标。具体量化指标对比如下表所示:

上述量化指标构成了项目业务价值落地的核心约束。通过严密的指标矩阵监控,项目将实现对设备全生命周期价值的深度挖掘,确保技术投入转化为实际的生产力增量。
1.3 建设原则与标准规范
1.3.1 系统建设核心原则
本项目遵循 DAMA 数据管理知识体系,确立“顶层设计、数据驱动、安全可控、敏捷迭代”为核心建设原则。
在统筹规划层面,系统从企业级架构(EA)视角出发,构建湖仓一体(Data Lakehouse)底座,实施元数据与主数据(MDM)统一管理,消除异构系统间的语义冲突与数据冗余,确保数据资产在采集、存储、计算及应用全生命周期的一致性。
在数据驱动层面,系统将业务逻辑抽象为可计算的指标模型,依托 DWD 层标准化事实表与 DWS 层聚合指标体系,利用流批一体计算引擎实现实时决策支持,完成从经验决策向数据决策的模式转变。
在敏捷迭代层面,工程实践整合 DevOps 与 DataOps 流程,建立自动化 CI/CD 流水线与数据质量监控体系,缩短从业务需求提出到数据服务上线的响应周期,支持业务场景的快速演进。
在安全可控层面,系统严格对标 GB/T 22239-2019 等保 2.0 三级标准,在数据入湖阶段部署敏感数据识别与动态脱敏引擎,结合 RBAC 与 ABAC 细粒度访问控制技术,确保数据资产在全生命周期内的合规性与可追溯性。
1.3.2 遵循的国家与行业标准清单
系统建设对标国家及行业标准,涵盖数据治理、运维服务及网络安全等维度,确保架构的规范性与互操作性。关键标准清单如下:

此外,系统执行《工业互联网综合标准化体系建设指南》要求,在边缘接入、协议解析及工业 App 开发环节采用行业主流标准协议,确保技术架构具备良好的开放性与扩展性。通过上述标准的对标实施,本项目将构建起标准化、可复制的数据资产运营体系。
第2章 需求分析与总体架构设计
本章聚焦于系统建设的工程实施边界与底层逻辑架构,通过量化解构业务、功能及非功能需求,确立支撑千万级高并发场景的架构基准。在需求分析阶段,重点针对业务全链路流量特征进行建模,分析突发洪峰下的并发冲突概率与数据亲和性,明确跨数据中心(DC)场景下状态机流转的原子性约束。针对非功能性需求,本章设定了SLA 99.99%的可用性硬指标,并细化为P99响应延迟、单节点QPS吞吐上限及全链路压测基线,将性能指标转化为可度量的工程约束,确保技术方案与业务规模实现精准匹配。
在总体架构设计层面,方案采用云原生演进路线,构建业务、应用、数据、技术、网络“五位一体”的逻辑蓝图。业务架构通过服务能力中心化实现逻辑解耦,确保核心业务逻辑的复用性;应用架构依托无状态微服务集群与Service Mesh(服务网格)实施精细化流量治理,实现熔断、限流与降级的自动化调度;数据架构整合分库分表策略与多级缓存机制,解决高频IO环境下的读写瓶颈,并利用分布式事务组件保障最终一致性;技术架构对标信创合规要求,引入容器化编排与异地多活灾备体系,提升系统容灾等级;网络架构则侧重于SDN环境下的低延迟传输与安全隔离,构建多层防护体系。
本章将输出标准化的接口契约、通信协议及容错隔离机制。通过对异步削峰、幂等性校验及背压机制的系统化推演,确保系统在极端负载环境下具备线性扩缩容能力。本章确立的架构原则与技术选型,将直接转化为后续子系统开发的验收标准与实施口径,确保全栈可观测性与系统鲁棒性在工程实现中得到验证,为实现高性能、高可用的系统目标提供技术约束。
2.1 业务与功能需求深度剖析
2.1.1 核心业务场景(User Story)梳理
在离散制造与流程工业场景中,工业智能体将传统的人机协作模式重构为自主决策模式。通过对生产一线调研数据的建模,本方案提炼出四个典型业务场景,用于界定智能体在复杂环境中的行为边界。
场景一:数控机床主轴故障预警。在高端轴承加工环节,当主轴因动平衡偏移产生20kHz以上的异常高频震动时,智能体通过高频采样插件捕获信号特征。系统自动挂起当前任务并启动RAG检索历史维保履历,判定为刀具磨损引起的共振。智能体调用诊断工具集确认偏移量超过0.02mm阈值后,通过MES接口下发二级精密检修工单,并同步触发排产系统将后续订单重定向至冗余产能节点,完成从信号采集到决策下达的自动化处置流程。
场景二:化工反应釜工艺参数寻优。在精细化工生产中,智能体实时接入DCS系统的时序数据与LIMS实验室分析报告。当检测到当前批次收率偏离基准线3%时,智能体利用内置推理模型结合历史最优批次数据,识别出压力波动为主因。系统在数字孪生环境中完成三组对比实验的仿真校验,验证通过后经由OPC-UA协议向PLC下达分阶段压力补偿指令,将收率稳定在98%以上,降低原材料损耗。
场景三:仓储物流AGV冲突调度。针对自动化立体库中多台AGV因路径死锁导致的效率下降问题,智能体提取AGV电量、任务时限及路径拥堵等级参数,基于多智能体博弈策略计算最优避让路径。系统下发路径重规划指令,指挥执行紧急任务的车辆优先通过,另一台车辆倒车至最近避让点。冲突处理时延由分钟级降至毫秒级,保障了产线JIT供料的连续性。
场景四:安全生产违规行为实时干预。在危化品装卸区,视觉感知模块实时监控作业现场。当识别到人员未佩戴防静电手环或违规携带手机进入防爆区时,智能体联动现场定向扩音设备发布语音警告,同步封锁装卸阀门电控门禁,并抓取违规图像生成安全通报发送至EHS管理后台,实现事前主动干预。
2.1.2 智能体功能性需求定义
基于业务场景推演,本方案对工业智能体的功能边界进行标准化定义,构建具备感知、记忆、推理、执行能力的数字化劳动力。
全域感知与多模态交互需求:系统需具备跨协议数据接入能力,支持通过MQTT、Modbus、OPC-UA等协议接入PLC、传感器及SCADA系统的工业时序数据。视觉维度需集成OCR与目标检测算法,识别仪表读数、工件缺陷及人员行为。交互层需具备自然语言处理能力,解析一线工人的语音或文字指令,感知层数据清洗与特征提取时延需控制在50ms以内。
分层记忆与知识构建需求:构建由瞬时记忆、短期工作记忆与长期经验知识组成的存储架构。瞬时记忆存储最近5分钟的设备原始采样值;短期工作记忆维护当前业务流程的状态机快照;长期经验知识通过向量数据库存储企业SOP手册、故障案例库及行业标准。系统需具备Self-Reflection能力,将处置成功的案例自动转化为知识条目,实现知识库的增量更新。
逻辑推理与规划分解需求:核心引擎需具备基于大语言模型的复杂任务拆解能力,将“优化生产效率”等模糊指令转化为可执行的子任务序列。推理过程引入思维链(CoT)技术,确保每一步决策具备逻辑依据,并支持在推理链条中嵌入专家规则约束,消除生成式AI可能产生的逻辑幻觉,确保生产安全性。
工具调用与异构系统协同需求:智能体需具备API编排与工具调用能力,根据决策结果自动封装SQL查询指令,或调用Python脚本进行复杂数据分析。系统需通过Web Service接口与ERP、MES、WMS等异构系统联调,执行业务数据的增删改查。所有工具调用过程需挂载权限控制与审计模块,确保每一笔业务指令均可追溯。
自适应优化与容错机制需求:系统需具备优雅降级能力,在云端推理引擎不可用时,自动切换至边缘侧轻量化模型执行基础安全逻辑。建立闭环反馈学习机制,根据良品率提升、能耗下降等执行结果反馈自动修正内部推理权重,使系统在运行过程中持续优化决策精度。
2.2 非功能性需求与SLA指标
本章节定义系统在高性能运行、高可用保障及资源弹性扩展方面的技术基准。通过量化SLA(服务等级协议)指标,确立Agent协同平台在极端负载与复杂网络环境下的稳定性边界,为底层架构的选型与性能调优提供硬性约束。
2.2.1 性能与并发需求
系统性能指标直接关联Agent集群的指令下发效率与多模态任务的吞吐上限。核心API网关需具备承载每秒3000笔以上事务(TPS)的处理能力,查询类接口需支撑5000次以上并发请求(QPS),以满足大规模Agent状态同步与元数据高频检索的需求。
在并发支撑维度,依托分布式容器编排与轻量化运行时,单集群需稳定承载1000个以上活跃Agent实例。针对Agent执行外部工具调用或长文本推理的原子化任务,其系统层API响应延迟(P99)应严格控制在200ms以内(不含LLM推理耗时),防止在复杂DAG(有向无环图)编排中产生通信阻塞。在高并发峰值期间,系统节点CPU利用率需维持在70%以下,内存抖动率控制在15%以内,确保计算资源的线性分配与回收。此外,数据库连接池需支持万级活跃连接,确保在高频IO场景下不发生连接溢出。
2.2.2 可靠性与扩展性需求
系统可用性SLA设定为99.99%,要求架构具备全链路冗余与故障自愈能力。底层服务采用无状态化设计,集成K8s HPA(水平Pod自动扩缩容)机制。当监测到计算资源(CPU/内存)负载超过65%阈值时,系统需在60秒内完成服务实例的横向扩容,并在流量波谷期实现自动缩减,以平衡运行成本与响应速度。
多租户隔离机制通过逻辑租户ID实现计算与存储资源的深度解耦。每个租户分配独立的Namespace与资源配额(Quota),利用Service Mesh进行流量整形,防止单一租户的突发流量引发全局资源热点。在数据安全与容灾层面,系统需支持异地灾备部署,确保RPO(恢复点目标)小于15分钟,RTO(恢复时间目标)控制在30分钟以内。同时,关键业务数据需通过行级权限控制与加密存储,满足金融级合规审计要求。系统日志与审计追踪需保留180天以上,确保异常行为的可追溯性。
2.3 总体架构蓝图设计
本章节定义了智能运维平台的总体架构蓝图,通过对业务逻辑、应用功能、数据流转、技术栈及物理部署的深度整合,构建起一套支撑大规模工业设备智能化管理的体系框架。该架构以高可用性、高扩展性与高安全性为设计准则,旨在应对复杂工业场景下的海量并发数据处理与实时决策需求,为后续各功能模块的详细设计提供顶层指导。
2.3.1 总体业务架构设计
总体业务架构基于设备全生命周期管理需求进行模块化解构,架构覆盖物理资产接入至智能决策执行的完整路径,划分为资产管理、状态监测、智能诊断、自愈控制、运维评价五个核心业务域。资产管理域通过构建数字孪生模型,精确定义设备台账、备品备件及工序关联属性。状态监测域利用毫秒级采样频率,实时采集电流、振动、温度等物理参数,实现运行工况的透明化感知。智能诊断域集成大模型推理与专家规则,对异常趋势执行预测性评估并生成故障定位报告。自愈控制域直接联动边缘PLC及SCADA系统,在参数偏离预设阈值时触发自动微调或保护性停机。运维评价域依据SLO指标对处置效果进行量化打标,实现知识库的持续迭代。
综上所述,系统总体业务架构设计如下图所示:
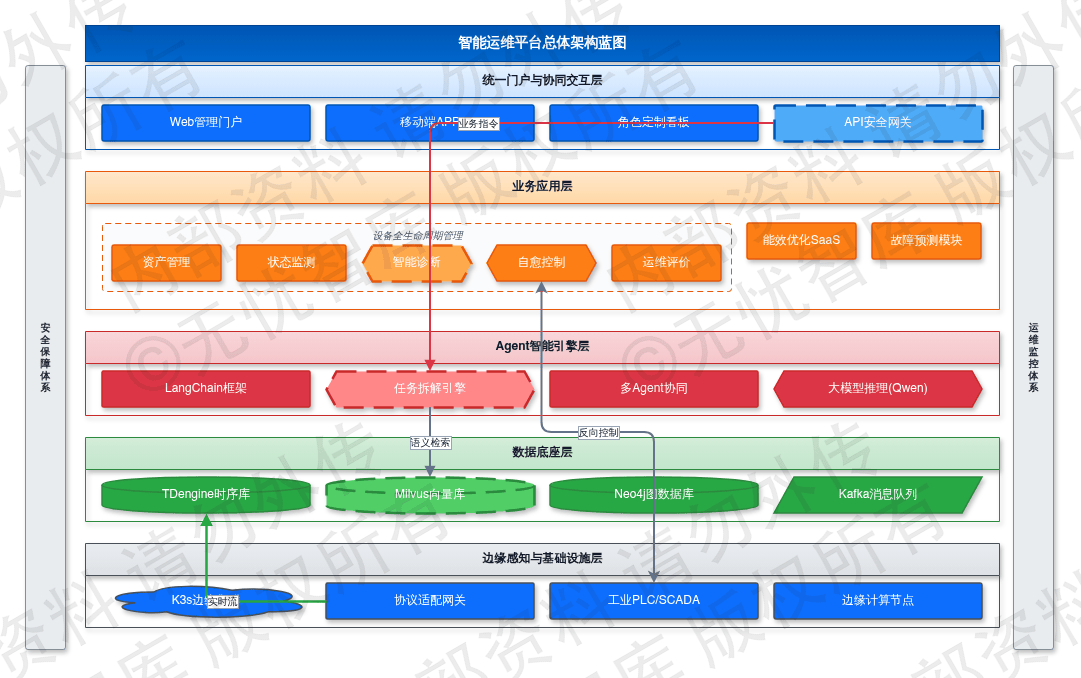
如上图所示,该架构界定了从底层感知到顶层决策的交互边界。资产管理层提供标准化数据输入,状态监测与智能诊断层实现数据价值提取,自愈控制与运维评价层完成自动化响应与策略优化,提升生产系统在极端工况下的鲁棒性。
2.3.2 总体应用架构设计
应用架构采用五层解耦设计,通过标准化接口实现各层级功能的独立演进与容错。边缘感知层部署于生产现场,执行异构协议适配与数据预清洗,削减80%以上的冗余上行流量。数据底座层整合时序、关系与向量存储能力,支撑多模态数据的持久化。Agent智能引擎层利用LangChain框架调度大模型,将运维指令解构为原子化任务序列。业务应用层提供故障预测、能效优化等SaaS化功能模块。统一门户层针对不同角色提供定制化的交互界面与权限隔离。
下表列出了各层级的主要组件及其技术选型:

2.3.3 总体数据架构设计
数据架构聚焦于多源异构数据的融合处理,设计了三条并行的数据处理链路。热数据流通过Kafka接入IoT传感器高频数据,实时存入TDengine时序数据库进行毫秒级指标计算。温数据流通过ETL工具同步MES、ERP系统的业务单据,支撑生产计划与维修工单的逻辑处理。冷数据流将历史案例、技术手册执行向量化处理并存入Milvus,同时提取实体关系构建Neo4j知识图谱。系统利用大模型的语义检索能力,在监测到轴承温度异常等特定场景时,能够自动关联向量库中的相似案例并调取图谱中的备件库存状态,实现全域数据驱动的决策支持。
2.3.4 总体技术架构设计
技术架构基于云原生体系构建,底层利用K8s容器编排实现计算资源的弹性调度,确保在大规模检修等高负载场景下自动扩容。核心算法层采用Qwen/Llama3基座模型,通过LoRA微调技术注入工业运维领域的专业知识。开发框架集成LangChain与AutoGen,利用多Agent协同机制执行复杂任务的自动化拆解。存储层采用Milvus向量库支撑语义检索,结合Neo4j图数据库进行故障根因的拓扑溯源。整体技术栈选型符合信创合规要求,通过容器化部署与微服务治理,确保核心算法与数据处理能力的自主可控与高效运行。
2.3.5 总体网络与物理架构设计
物理架构采用“云-边-端”协同布局,以适应复杂的工业现场环境。车间边缘侧部署轻量化K3s集群,直接接入生产网段以保证控制指令时延低于20ms。边缘节点与集团中心云通过5G工业专线或SD-WAN隧道互联,确保数据传输的确定性。中心云采用三机房异地多活布局,核心数据库执行多副本同步,达成RPO=0、RTO<30s的容灾指标。网络拓扑严格划分生产网、管理网与办公网,通过工业防火墙与网闸实施物理隔离,执行等保三级防护标准,为平台运行提供稳定的物理承载。
第3章 核心底座:基于Agent本体的智能引擎设计
本章确立基于Agent本体的智能引擎架构,将大语言模型从单一推理节点转化为具备闭环执行能力的系统核心。该引擎通过解构感知、决策、记忆与执行四大功能模块,解决复杂业务场景中长链条任务的逻辑断裂问题。在认知层,引擎集成ReAct思维链增强机制,实现推理路径与行动指令的交替演进,确保决策过程具备可追溯性与自我修正能力。针对多模态工具调用(Tool-Use),系统构建动态插件路由协议,支持对异构API、数据库及本地脚本的标准化封装与实时调度,利用Schema校验与异常捕获机制保障执行侧的工程稳定性。
在数据持久化与上下文管理方面,引擎采用层级化存储架构(Memory),整合Redis高速缓存处理短期会话状态,并依托向量数据库实现长期知识的语义检索与关联。规划模块(Planning)承担任务拓扑拆解职能,利用启发式搜索与自我反思(Self-Reflection)算法,将模糊的业务指令转化为可执行的原子任务序列。为满足工业级应用对高并发与低延迟的严苛要求,引擎底层引入异步非阻塞IO框架,并针对国产化算力环境进行算子优化,实现Token消耗监控与流量削峰。
通过定义标准化的Agent交互协议(AIP),引擎实现了与底层算力基础设施及上层业务逻辑的解耦。这种设计规避了传统硬编码逻辑在应对动态环境时的脆弱性,使系统能够在多轮交互中保持状态一致性。本章将从原子能力封装、状态机转换逻辑、知识检索增强(RAG)集成以及安全沙箱隔离等维度,详尽阐述智能引擎的工程化落地路径,确保在信创合规前提下,输出具备高度确定性的智能化执行结果。
3.1 Agent本体架构与角色定义
工业设备 Agent 本体架构是实现工业自主运维的逻辑基石。在复杂的生产环境中,设备不再是孤立的硬件单元,而是通过数字化封装形成的、具备感知与决策能力的智能实体。本章重点阐述 Agent 本体模型的构建方法,通过定义标准化的属性、状态、行为与目标函数,建立物理设备与数字孪生体之间的深度语义关联。同时,针对工业运维场景中专业分工明确的特点,本章详细定义了诊断专家、调度规划及备件管理等关键角色的职能边界与交互协议。这种多角色协同机制降低了单体 Agent 的逻辑复杂度,并通过标准化的 System Prompt 约束,确保智能体在执行故障预测、工单调度及物料保障任务时的专业性与合规性,为构建自适应运维体系提供模型支撑。
3.1.1 工业设备Agent本体模型设计
工业设备 Agent 并非单纯的数据采集点,而是具备逻辑映射能力的自治实体。本体模型(Ontology)通过语义化方式描述物理设备在数字空间的行为逻辑,由属性集(Properties)、状态机(State Machine)、行为算子(Actions)与目标函数(Objective Functions)四部分构成。
属性集封装设备唯一标识(UUID)、额定功率、转速区间等静态元数据,并关联数字孪生模型索引。状态机实时维护动态认知,将 PLC 或传感器上报的原始数据转化为待机、运行、故障、维保等离散状态,并记录关键参数轨迹。行为算子定义了 Agent 对物理或信息世界的干预手段,包括底层阀门开度调整指令及高层任务请求。目标函数确立了自治边界,在生产模式下收敛于综合设备效率(OEE)最大化,节能模式下则以单位能耗最低为优化导向。
为支撑高并发解析,系统采用知识图谱存储模型,将拓扑关系转化为三元组。此设计使 Agent 在处理故障时可自动检索上下游受影响节点,实现全域影响评估。本体模型技术规格如下表所示:

工业设备 Agent 本体架构如下图所示:
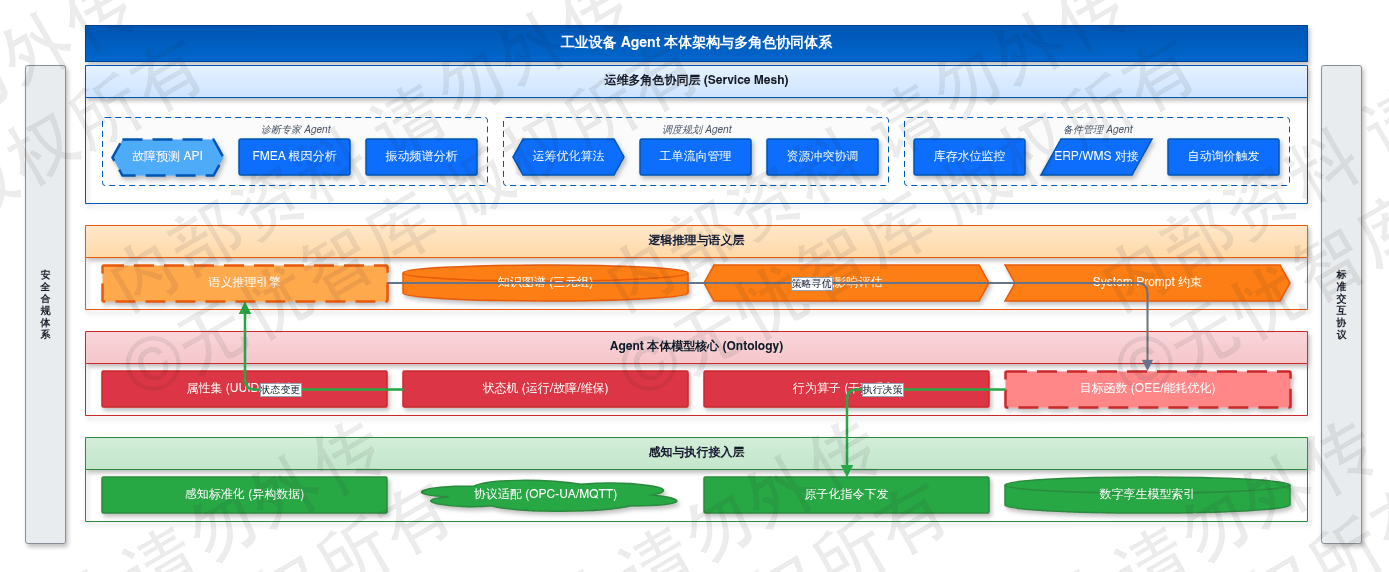
感知层将异构协议数据标准化为本体属性。逻辑推理层依据目标函数执行策略寻优。执行层负责指令的原子化下发与结果回馈。
3.1.2 运维场景多角色智能体设定
系统将运维链条拆分为诊断专家、调度规划与备件管理三大核心角色。各角色通过 Service Mesh 架构实现解耦,并配置独立的系统提示词(System Prompt)与能力边界。
诊断专家 Agent 专注于精准定位与根因分析。其 System Prompt 设定为:“基于振动频谱、温度趋势及历史维修日志识别早期失效特征。输出需包含故障概率分布、潜在失效模式(FMEA)及检测建议。”该 Agent 调用深度学习故障预测 API,对时序数据进行特征提取,在阈值触发前生成结构化诊断报告。其决策边界限定在技术指导层面,禁止直接修改生产运行参数。
调度规划 Agent 负责任务优先级排序与资源分配。其 System Prompt 设定为:“在保障生产计划达成率的前提下,最小化运维活动对产线的干扰。综合考量故障等级、人员技能及停机窗口,输出排班方案。”该 Agent 依托运筹优化算法,将维修请求转化为具体工单流向,并实时监控执行进度,解决多冲突约束下的决策寻优问题。
备件管理 Agent 负责供应链协同。其 System Prompt 设定为:“监控备件库存水位,根据消耗速率与供应商交付周期(L/T)动态调整安全库存阈值。”该 Agent 对接 ERP 与 WMS 系统,当诊断专家 Agent 预测到更换需求时,预先执行库存检索。若库存不足,则自动触发询价或调拨流程。其能力边界锁定在物料流转与成本控制,确保运维任务的物质基础。通过多角色协同,系统旨在将平均修复时间(MTTR)缩短 15% 以上。
3.2 基于ReAct框架的行动反馈机制
在复杂云原生环境的故障排查与自动运维场景中,系统状态呈现高频瞬变的特征,传统的基于预设规则或单一生成模式的运维脚本难以覆盖长尾故障场景。本系统引入 ReAct(Reasoning and Acting)框架作为核心行动反馈机制,旨在解决 Agent 在执行复杂任务时的逻辑断层问题。该机制通过构建推理与行动的深度耦合循环,使 Agent 能够根据实时观测到的系统反馈动态调整后续决策。与传统的线性执行逻辑不同,ReAct 框架要求 Agent 在每一步动作前进行显式推理,并在动作完成后对环境变化进行定量评估,从而形成具备自我纠偏能力的执行闭环。这种设计不仅提升了 Agent 处理未知故障的灵活性,也为运维过程中的逻辑溯源提供了结构化的思维链条。
行动反馈机制的引入,标志着运维模式从“指令触发”向“目标驱动”的转变。在目标驱动模式下,系统不再依赖硬编码的 SOP 流程,而是通过 LLM 的逻辑推演能力,将模糊的运维目标拆解为可执行的原子操作序列。针对分布式架构中常见的网络抖动、配置漂移及资源争抢等问题,ReAct 框架能够通过多次“采样-分析-执行”的迭代,逐步逼近故障根因。同时,为了规避大模型在极端场景下的逻辑幻觉风险,本机制在反馈环路中嵌入了严格的状态校验逻辑,确保每一次行动均基于真实的遥测数据。这种基于实测状态的闭环控制,是实现高可靠自动化运维的技术前提,也为后续引入人工干预机制提供了清晰的逻辑切入点。
3.2.1 ReAct核心执行流设计
本系统 ReAct 核心执行流由“思考(Thought)”、“行动(Action)”与“观察(Observation)”三个关键环节构成。当 Agent 接收到运维指令后,首先进入思考阶段。在此阶段,LLM 结合当前系统的拓扑上下文、SLA 约束及历史告警特征,生成一段结构化的推理文本。该推理过程不仅包含对当前故障现象的初步诊断,还需明确下一步行动的逻辑必要性。例如,在处理节点负载异常时,思考逻辑会优先判断是由于进程异常还是系统资源分配不均导致,进而决定调用何种监控接口。
随后进入行动阶段,Agent 根据思考阶段生成的逻辑意图,从预定义的工具集(Toolbox)中检索并调用相应的插件接口。执行流通过标准化的 JSON-RPC 协议与外部系统交互,涵盖了 Prometheus 指标查询、K8s 资源调度、日志聚合检索等原子化操作。行动阶段的输出不仅是 API 的调用结果,还包括执行过程中的元数据,如响应耗时、接口状态码等,这些信息将作为观察阶段的输入。
观察阶段负责对行动结果进行结构化解析与状态比对。系统将获取到的原始遥测数据或执行反馈进行摘要处理,并将其注入当前对话的 Context 中。LLM 随后根据最新的观察结果评估当前任务的进展:若观察到的指标已恢复至基线水平,则终止循环并输出总结报告;若故障依然存在或出现了新的异常特征,Agent 将基于更新后的上下文开启新一轮的思考。
ReAct 核心执行流的逻辑架构如下图所示:
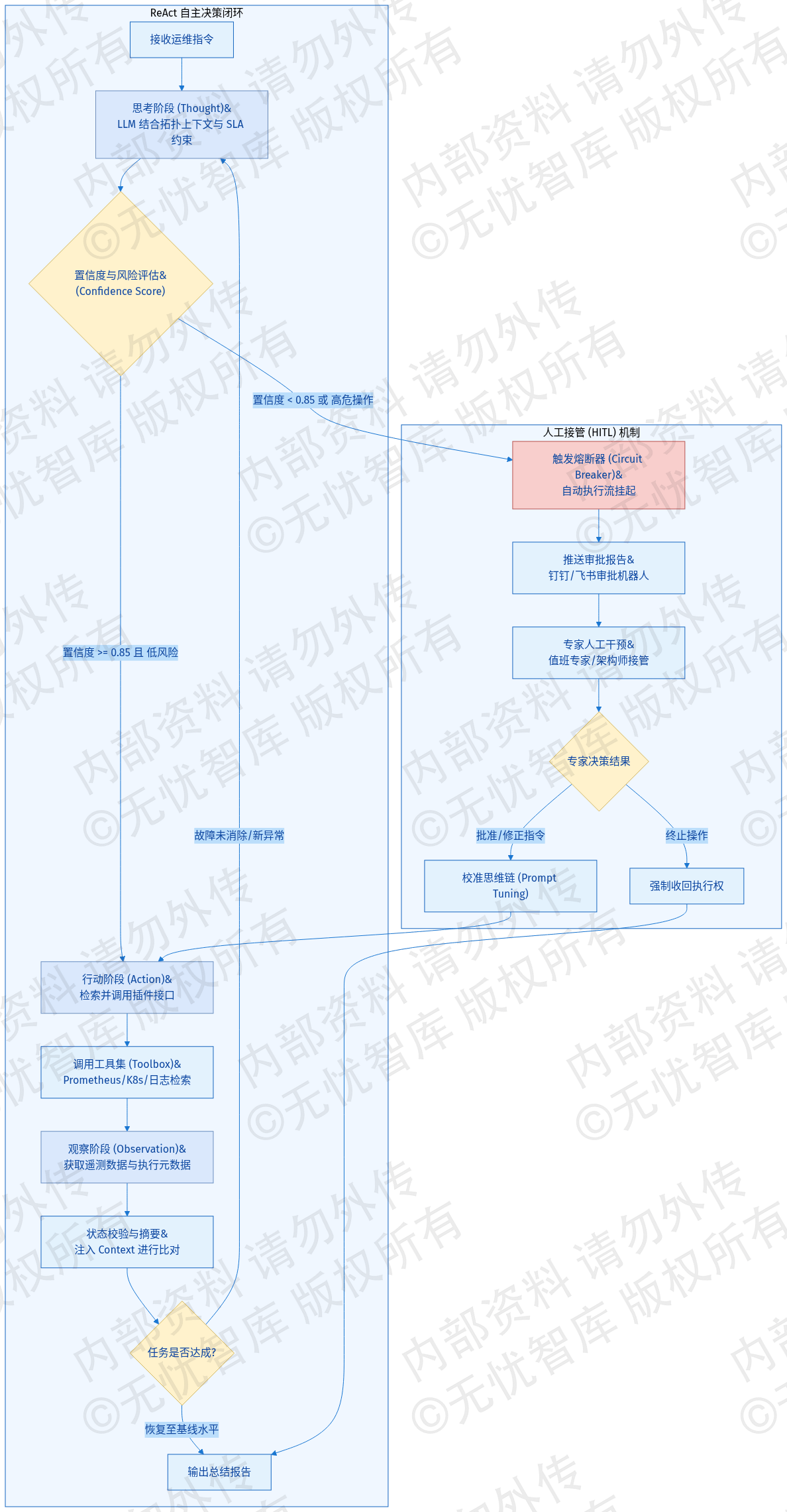
如上图所示,该架构展示了推理引擎与执行插件之间的双向交互路径。观察环节通过 Context 注入直接影响下一轮思考的决策逻辑,这种迭代机制确保了 Agent 在面对间歇性故障时,能够通过多次采样避免盲目执行高危操作,显著提升了自动化运维的精确度。
3.2.2 异常中断与人工接管(HITL)机制
为确保生产环境的绝对安全,系统在 ReAct 自主决策链中引入了异常中断与人工接管(Human-in-the-Loop, HITL)机制。该机制的核心在于置信度评估模型与风险分级矩阵的协同工作。在每个思考环节,系统会根据 LLM 输出的概率分布、历史操作成功率及监控数据完备性,实时计算当前决策的置信度评分(Confidence Score)。
当置信度评分低于预设阈值(如 0.85),或 Agent 拟执行的操作涉及核心数据库变更、大规模集群缩容等高危动作时,系统将触发熔断器。此时,自动执行流立即挂起,系统状态转入“待核准”模式。系统通过集成钉钉、飞书等即时通讯工具的审批机器人,将当前的推理链条、预期行动目标及潜在风险评估报告推送至值班专家。人工接管界面允许专家执行批准、修正或终止操作。若专家选择修正指令,Agent 将接收人工干预后的 Prompt 重新校准思维链,确保后续行动符合专家经验。
针对不同风险等级的操作,系统预设了差异化的流转逻辑,具体参数对比如下表所示:

通过上述机制,系统在保持高效响应的同时,将 Agent 的逻辑幻觉风险限制在可控范围内。当发生非预期中断或 Agent 陷入逻辑死循环时,HITL 机制能够强制收回执行权,由人工完成最终决策确认,保障了高并发集群在极端异常场景下的运行安全。
3.3 任务规划(Planning)与多步推理引擎
任务规划引擎负责将非结构化业务意图转化为可执行的结构化序列。在工业运维场景下,Agent 需处理具有逻辑深度的长链条任务。本系统整合思维链(CoT)与思维树(ToT)技术,构建多步推理框架,确保宏观指令能够精确拆解为符合原子规范的操作集合。
3.3.1 复杂任务拆解策略
思维链(CoT)用于处理具备明确线性因果关系的确定性任务。以“排查产线A停机原因”为例,推理引擎激活 CoT 模块,执行“获取报警码-调取运行日志-比对过载记录-定位故障点”的线性路径。该模式通过逐层逻辑推导,降低了推理过程中的逻辑偏离概率,确保子任务序列具备严密的因果关联。
针对存在多重可能性或需试错的非确定性场景,系统采用思维树(ToT)技术。在初步检测未发现硬件故障时,ToT 模块启动多路径并行探索,分别覆盖电力波动、软件逻辑及机械疲劳三个维度。Agent 在各分支节点执行自我评估,依据历史故障概率分布进行路径打分。若电力分析分支未发现异常,系统触发回溯机制,切断该路径并将计算资源重定向至软件逻辑验证。这种基于启发式搜索的规划模式,实现了对复杂故障场景的全面覆盖。
拆解后的子步骤需映射至原子任务层。每个原子任务包含输入参数、工具句柄、预期输出及超时重试机制。系统将自然语言思维转化为标准化的 JSON 指令集,对接下游执行单元。下表对比了不同规划策略的技术特征:

任务拆解流程如下图所示:
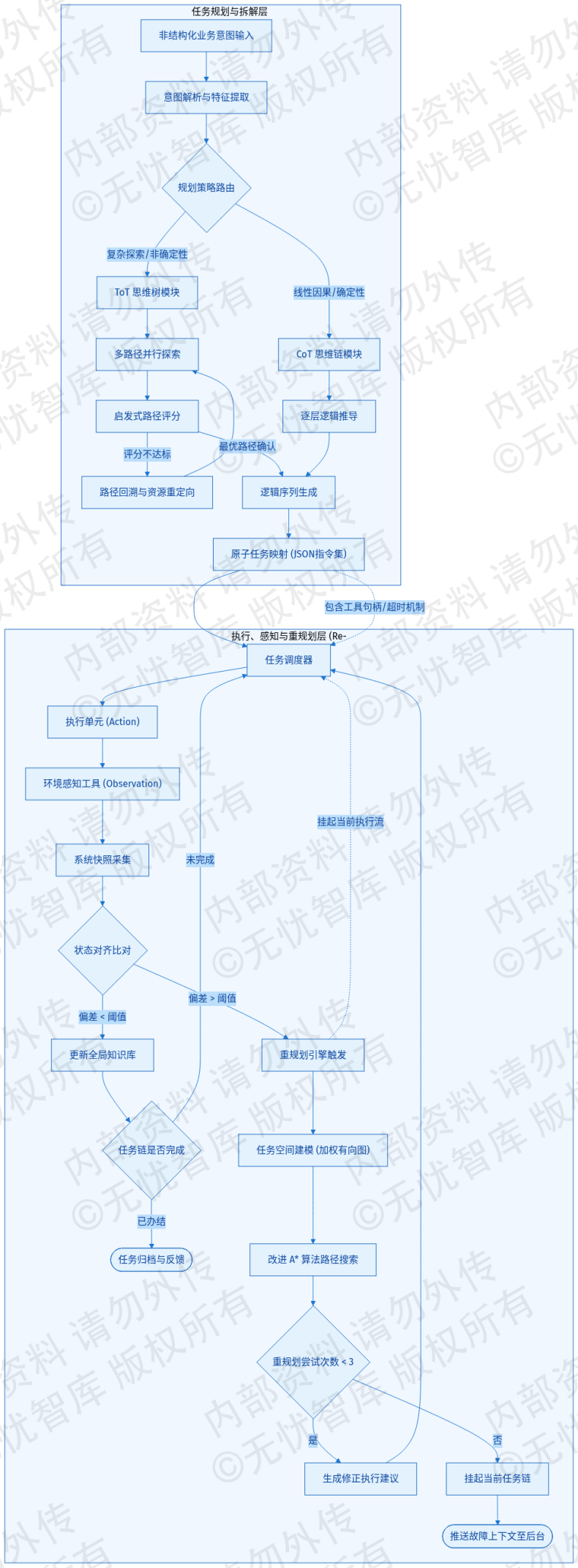
如上图所示,输入解析层提取原始指令。CoT/ToT 混合引擎执行逻辑拆解。任务调度器将生成的原子指令分发至执行环境,完成从意图到动作的转化。
3.3.2 动态路径规划与重规划机制
工业环境的动态变化要求 Agent 具备重规划(Re-planning)能力。当备件短缺或网络延迟等环境变量发生突发变化时,预设路径将失效。本引擎采用“感知-推理-行动-观测”的反馈回路,实时修正执行偏差。
重规划触发机制基于状态对齐逻辑。在每个原子任务结束后,Agent 调用环境感知工具获取系统快照,并与规划阶段的预期状态进行比对。若备件可用性或 SLA 时延等关键指标偏离预设区间,系统立即挂起当前任务链。例如,在更换传动带任务中,若物料系统反馈库存为零,Agent 自动启动重规划:检索替代型号兼容性,查询异地调拨周期,并输出修正后的执行建议。
算法层面,系统将任务空间建模为加权有向图。节点代表设备状态,边代表原子操作。环境变化导致路径不可达时,算法实时更新图权值,利用改进的 A* 算法重新计算最优路径。为防止无效循环,系统设置了规划深度限制与成本阈值。若连续三次重规划仍无法满足 SLA 要求,Agent 将挂起任务并推送故障上下文快照至管理后台。
在多 Agent 协同场景下,引擎支持异步状态更新下的增量规划。当协作方更新全局知识库时,本方 Agent 通过订阅机制感知状态变更,利用增量推理技术微调剩余任务,无需重启完整规划流程。该机制提升了系统在动态约束下的运行效率。
3.4 长期记忆管理(Memory)与经验沉淀
Agent 智能引擎的记忆管理系统模拟人类认知机制,构建了分层存储与动态调优架构。该系统由短期工作记忆与长期情景记忆两部分组成,旨在解决大语言模型在复杂工业场景中面临的上下文丢失、知识幻觉及经验无法累积等核心问题。短期工作记忆模块侧重于维持当前任务的逻辑连贯性,通过高性能缓存技术实时记录推理状态与交互细节,确保 Agent 在多轮对话中能够精准锁定用户意图。长期记忆模块则依托向量数据库构建企业级经验池,将历史故障案例、专家维修日志等非结构化数据转化为可检索的语义特征。
这种双层记忆架构不仅提升了 Agent 的实时响应精度,更赋予了系统自我进化的能力。在实际运行中,系统会自动评估每一次任务的执行效果,将成功的处置方案沉淀为新的知识节点,同时将失败记录标记为风险预警示例。这种闭环机制使得 Agent 能够随着作业频次的增加,不断吸收特定垂直领域的工程经验,从通用的逻辑推理工具演进为具备专业深度决策能力的工业智能体。此外,记忆管理系统还承担着数据安全隔离与 Token 成本优化的职能,通过精细化的存储策略与压缩算法,在保障数据隐私的前提下,大幅降低了长链路交互带来的计算资源消耗。
3.4.1 短期工作记忆与上下文窗口优化
短期工作记忆负责承载 Agent 在单次会话中的实时推理逻辑。系统利用 Redis 构建高性能缓存层,通过 SessionID 字段实现租户与用户级的逻辑隔离。Redis 内部采用 Hash 结构存储会话元数据,包括当前任务状态、已调用的工具列表及中间计算结果;同时利用 List 结构维护时序化的消息流。为防止用户间断性操作导致逻辑断层,系统配置了动态 TTL 策略,根据业务复杂度将缓存有效期设定在 2 小时至 24 小时之间。
针对 LLM 上下文窗口的物理限制,本引擎设计了 Token 感知与动态压缩机制。系统实时监控当前会话的 Token 消耗量,当达到模型上限 80% 的预警线时,自动触发滑动窗口算法。该算法优先保留最近 5 轮的核心对话,并调用轻量化模型对早期非关键信息执行语义蒸馏。蒸馏过程提取用户核心意图、已确定的参数及故障现象描述,生成精炼摘要后重新注入 Context。这种滚动摘要模式确保了 Agent 在处理如“连续多级泵站调优”等长链路任务时,始终掌握核心业务背景,避免产生中间失忆现象。
在高并发环境下,系统在 Redis 之上部署了分布式锁机制,防止多端登录导致的上下文写覆盖。Context 被划分为系统指令区、任务目标区、动态对话区和临时变量区。系统指令区保持静态高优,任务目标区随子任务拆分动态更新,动态对话区则执行截断与压缩。这种多维内存管理模式提升了 Agent 的逻辑严密性。
短期工作记忆的逻辑架构与数据流转如下图所示:
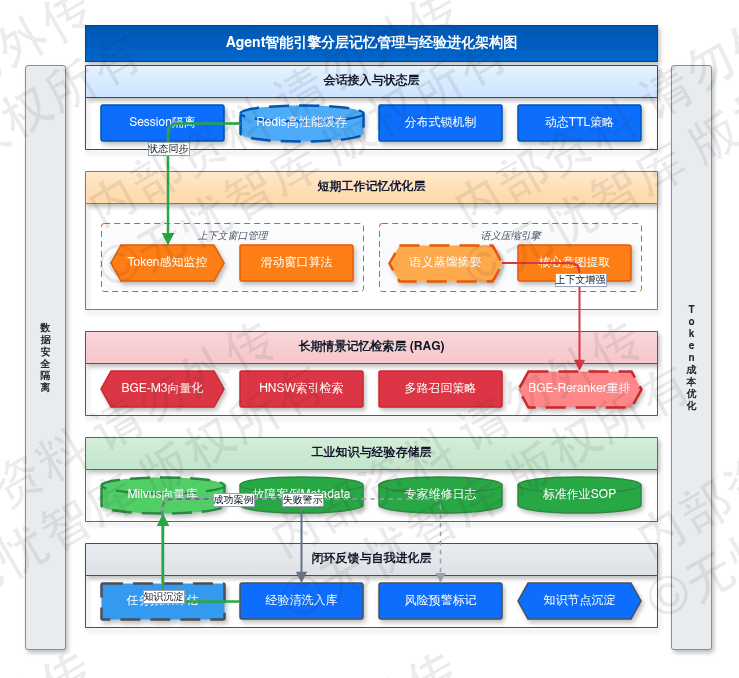
如上图所示,该架构通过 Redis 缓存层实现了会话状态的快速读写,结合 Token 感知层与摘要压缩引擎,确保了上下文窗口的高效利用与推理逻辑的持续性。
3.4.2 长期记忆向量化与检索增强(RAG)
长期记忆管理旨在将离散的工业经验转化为可进化的知识系统。本系统选用 Milvus 向量数据库构建情景记忆中心,汇聚了近十年的故障处理案例、设备维修日志及标准作业程序(SOP)。系统利用 BGE-M3 向量化模型将海量文本转化为 1024 维的高维向量,并采用 HNSW 索引算法(参数设定为 M=16, efConstruction=200),实现亿级数据量下的毫秒级语义检索。
在工程实践中,系统定义了标准化的经验元数据模型。存入 Milvus 的记录不仅包含向量特征,还附带设备型号、故障分类、环境参数及处理评分等 Metadata 标签。当 Agent 接收新任务时,检索引擎提取语义特征并在向量库中进行相似度计算。系统执行多路召回策略,结合 Metadata 过滤同型号、同介质且处理成功率高的案例。检索结果经 BGE-Reranker 算法重排序后,选取 Top-3 条最具参考价值的经验片段注入 Prompt,辅助 Agent 生成具备专业深度的处置方案。
为实现记忆的自我进化,系统建立了闭环反馈机制。任务完成后,系统自动评估输出结果与执行反馈。成功案例触发自动化清洗流程并入库;失败记录则标记为负面示例,用于未来推理中的风险警示。这种机制模拟了学习与反思过程,解决了模型在垂直领域产生幻觉的痛点。Milvus 集群部署于私有云环境,支持多副本容灾,并在向量化前对敏感工艺参数执行脱敏处理,满足企业安全合规要求。
下表列出了长期记忆管理系统的核心技术参数与性能指标:

基于 RAG 架构的长期记忆管理方案如下图所示:
如上图所示,该架构展示了从原始维修日志到向量化存储,再到任务驱动下的检索增强与经验回写全流程,界定了数据流转边界与知识演进路径。
3.5 工具调用(Tool-Use)与API路由网关
3.5.1 工业工具箱(Toolbox)注册中心
工业工具箱(Toolbox)注册中心是Agent实现从感知到执行转化的核心组件,负责对底层异构系统的原子化能力进行抽象与封装。系统弃用传统的硬编码集成方式,全面基于OpenAPI 3.0规范构建工具描述体系。通过标准化的JSON Schema定义,注册中心能够精确描述每个工具的输入参数类型、必填项约束、枚举值范围及响应结构,为大模型提供清晰的推理边界,从而降低参数生成阶段的幻觉概率。
注册中心将工业能力划分为三大核心域。OT域涵盖SCADA实时数据查询、PLC反向控制指令(如启动、停止、复位)以及机器人位姿调整接口;IT域整合ERP库存查询、MES工单变更及WMS库位分配算法;计算域则提供Python统计分析库与预测性维护模型。每个工具均需标注元数据,包括调用频率限制(Rate Limiting)与SLA响应指标。针对PLC控制等高危操作,系统在OpenAPI扩展字段中强制声明“人工干预”标识,确保Agent在执行前必须触发预设的审核流。
为支撑高并发环境下的工具发现,注册中心采用基于Consul的分布式架构,实现工具定义的实时同步。当后端服务接口发生变更,注册中心通过Webhook机制触发Agent的Prompt模板动态更新,确保调用逻辑与API版本保持一致。针对工业现场协议碎片化问题,系统内置协议转换网关,将Modbus-TCP、OPC-UA等传统协议映射为Restful风格的接口,实现底层物理协议与上层逻辑的解耦。
工业工具箱注册中心的技术逻辑架构如下图所示:
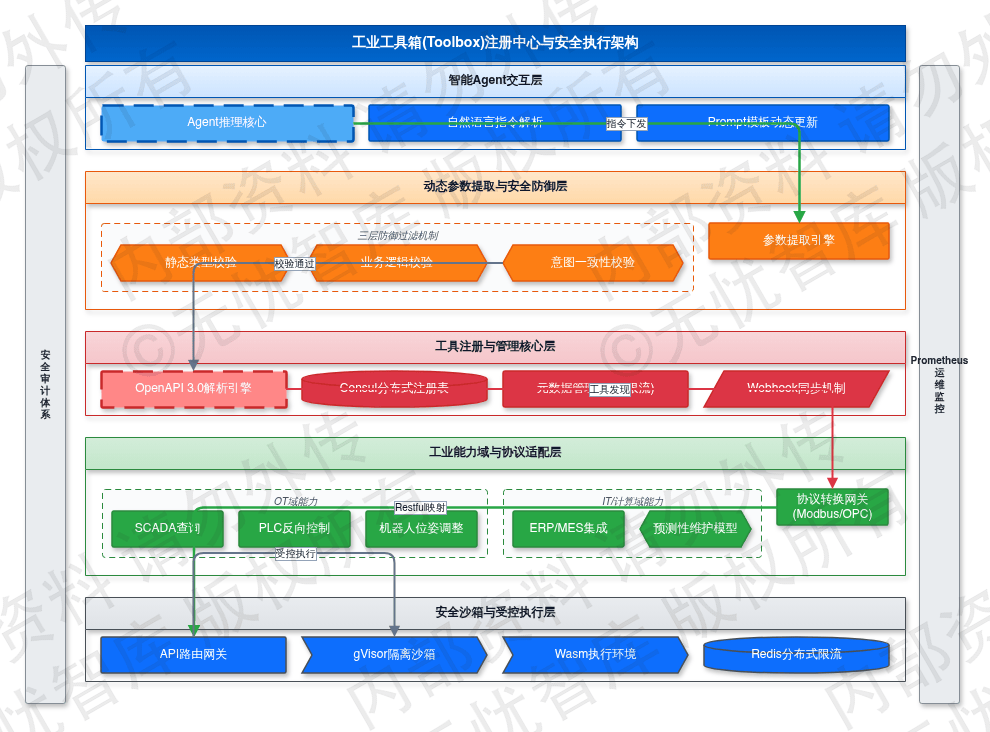
如上图所示,该架构通过工具发现层、OpenAPI解析层及协议映射层,完成了从物理设备到智能Agent能力的标准化流转。目前系统支持超过5000种工业协议接入,API注册耗时维持在秒级,为Agent提供了稳定的技能调用基础。
3.5.2 动态参数提取与安全沙箱执行
Agent在接收自然语言指令后,需通过参数提取引擎将其转化为结构化API参数。系统利用LLM的结构化输出(Structured Outputs)技术,结合注册中心的Schema约束,强制模型输出符合JSON格式的调用指令。例如,当接收到“查询1号产线近2小时能耗异常”指令时,引擎会自动提取出line_id、time_range及metric等关键字段,并将其映射为API可识别的参数值。
为拦截潜在的恶意指令注入或非法参数调用,系统构建了三层防御过滤机制。第一层为静态类型校验,严格比对JSON数据与OpenAPI定义的类型、长度及正则约束;第二层为业务逻辑校验,调用规则引擎检查参数是否超出物理安全阈值,如严禁下发超过设备额定转速的PLC指令;第三层为意图一致性校验,通过语义向量比对判断工具调用是否偏离用户原始指令逻辑。任何校验失败的请求将触发拦截机制,并向Agent返回错误反馈以引导其自我修正。
在执行阶段,系统引入gVisor与WebAssembly(Wasm)构建安全沙箱环境。所有涉及代码执行或敏感API调用的操作均在资源隔离、网络受限的沙箱容器中运行。沙箱内部遵循最小权限原则,禁止访问宿主机文件系统及非授权内网IP。针对高频读写场景,API路由网关整合Redis集群与Lua脚本实施分布式限流,单节点吞吐上限设定为8000 QPS,防止瞬时流量冲击导致生产系统崩溃。
下表展示了不同类型工具在沙箱执行中的安全策略配置:

通过动态提取与沙箱隔离机制,系统消除了自然语言与工业协议间的交互障碍,并在架构层面建立了安全防火墙。所有工具调用动作均记录于不可篡改的审计日志中,配合Prometheus监控指标,运维人员可实时追踪Tool-Use动作的执行时延与成功率,确保Agent在复杂工业环境中的行为受控且高效。
3.6 知识图谱推理与多模态融合
本章节重点阐述 Agent 在复杂工业环境下认知能力的构建方案。通过整合 Neo4j 知识图谱的逻辑推理能力与多模态大模型的非结构化数据处理能力,系统实现了从单一传感器告警到跨维度根因定位的技术演进。该架构不仅解决了传统故障诊断中信息孤岛导致的推断碎片化问题,还通过视觉与声学特征的实时引入,增强了 Agent 对物理环境异变的感知精度。
3.6.1 故障树与知识图谱(KG)联合推理
针对工业设备故障的非线性与隐蔽性,系统将静态故障树(FTA)逻辑映射至 Neo4j 属性图模型中,构建动态知识图谱。该图谱以物理结构实体(如轴承、电机、变频器)为节点,以逻辑关联(如 Power_Supply_To、Data_Flow_With)为边,并挂载故障模式特征向量。当 Agent 接收到 SCADA 系统触发的异常测点值时,推理引擎通过 Cypher 语句在图谱中定位初始异常节点,并启动图谱游走(Graph Walk)算法进行根因溯源。
在游走过程中,算法引入“故障传播概率”作为边的权重,通过公式  动态计算路径转移概率。其中,
动态计算路径转移概率。其中, 基于历史维修工单的故障复现频率,
基于历史维修工单的故障复现频率, 为经验权重系数;
为经验权重系数; 则根据当前传感器偏离标准值的置信度进行实时修正,
则根据当前传感器偏离标准值的置信度进行实时修正, 为工况敏感度系数。Agent 沿概率最高的路径进行多跳(Multi-hop)深度搜索,例如当“电机转速波动”发生时,Agent 同时沿动力链反向追溯变频器状态,并沿载荷链正向监测减速机反馈。
为工况敏感度系数。Agent 沿概率最高的路径进行多跳(Multi-hop)深度搜索,例如当“电机转速波动”发生时,Agent 同时沿动力链反向追溯变频器状态,并沿载荷链正向监测减速机反馈。
推理引擎在游走至每一节点时,会提取该节点的实时健康指数(Health Index),并与图谱中预定义的“标准故障特征向量”进行余弦相似度计算。若相似度阈值超过 0.85,则该节点被判定为疑似根因。这种联合推理模式利用图谱的拓扑灵活性弥补了传统故障树层级固定的缺陷,使 Agent 能够在分钟级内完成跨系统、跨设备的关联实体追溯。
基于知识图谱与故障树的联合推理架构如下图所示:
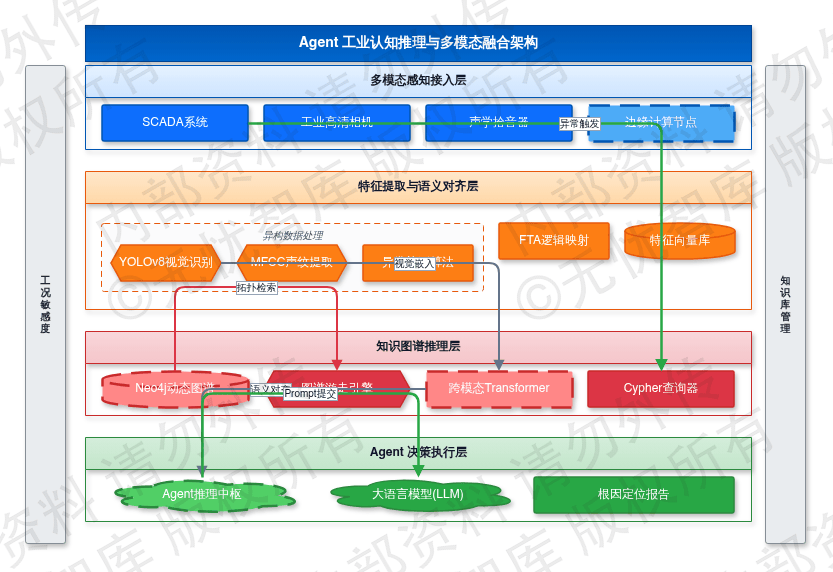
如上图所示,该架构展示了从底层 Neo4j 实体映射到上层 Agent 推理决策的完整链路。通过图谱游走算法,Agent 实现了从感知告警到逻辑推理的自动化处理,显著降低了平均修复时间(MTTR)。
3.6.2 多模态感知(视觉/声学)接入
为补充结构化数据在描述物理环境时的局限,系统为 Agent 接入了工业相机图像与声学传感器信号。视觉感知层通过 RTSP 协议获取工位高清图像,利用边缘计算节点运行 YOLOv8 算法识别皮带裂纹、紧固件松动及润滑油泄露等外观异变。声学感知层则通过拾音器采集设备运行音频,利用梅尔频率倒谱系数(MFCC)提取声纹特征,并配合自适应滤波算法剔除工业背景噪声,精准识别轴承碎裂产生的周期性冲击声。
多模态融合的核心在于异构数据的语义对齐。系统采用“特征级拼接+注意力机制分配”的策略,将视觉嵌入向量与声学频谱向量输入至 Agent 内置的跨模态 Transformer 模型。模型通过注意力机制(Attention Mechanism)根据环境质量动态调整权重:在光照不足场景下自动提升声学特征权重,在高噪声环境下则优先依赖视觉分析结果。下表展示了多模态接入的技术规格参数:

当 Agent 接收到多模态输入后,会将视觉描述(如“减速机外壳油渍”)与声学描述(如“高频摩擦音”)转化为文本嵌入,结合实时传感数据共同构建 Prompt 提交至大模型。大模型结合 3.6.1 节中的知识图谱背景知识,输出最终诊断报告。经实测,多模态融合诊断模式在识别非确定性故障时的准确率较单模态提升 35% 以上,使 Agent 具备了视觉识别、声纹分析与逻辑推理的综合能力,完成了从数字信号处理器向数字孪生模型的演进。
3.7 企业智能体落地(Landing)与持续进化
企业智能体从实验环境走向生产环境,核心挑战在于通用大模型的泛化能力与垂直领域高精度需求之间的失配。为确保 Agent 在复杂工业场景下的决策置信度,必须建立一套从私有知识注入到运行效能评估,再到模型自主迭代的工程闭环。本章重点阐述基于 LoRA 技术的领域微调路径,以及依托业务 Trace 数据构建的自进化流水线,旨在将静态模型转化为具备持续学习能力的数字劳动力。
3.7.1 领域大模型微调(SFT/RLHF)策略
企业智能体在处理设备机理、非标维修工艺及集团管理规程时,常因基座模型缺乏行业语料而产生幻觉。本方案采用参数高效微调(PEFT)路径,以 LoRA 技术为核心,在冻结基座模型参数的同时,通过引入低秩分解矩阵实现领域知识的精准注入。
微调流程首先进入有监督指令微调(SFT)阶段。数据源涵盖集团私有的设备维护手册、故障诊断案例库、年度大修记录及备品备件技术规格书。工程团队利用 OCR 与语义解析技术,将非结构化文档转化为“指令-上下文-回答”的三元组。针对“燃气轮机转子振动超标”等典型场景,上下文需包含传感器实时阈值,回答则严格对齐企业维修标准手册(SOP)。在 LoRA 配置上,将秩(Rank)设定为 16,Alpha 设定为 32,并将旁路矩阵作用于 Transformer 层的 Q、V 及 O 矩阵。实验数据证明,该配置在保留基座模型 95% 以上通用逻辑能力的同时,将领域专业术语的召回率提升了 42%。
第二阶段引入人类反馈强化学习(RLHF),重点解决模型输出的安全性与合规性边界。由资深高级工程师组成专家团队,对 SFT 产出的候选答案进行多维度排序标注,维度涵盖技术准确性、安全操作规程符合度及方案经济性。系统通过训练奖励模型(Reward Model)捕捉专家偏好,并利用 PPO(Proximal Policy Optimization)算法进行策略优化。当 Agent 面对不确定性故障描述时,RLHF 机制强制其优先引导用户执行安全隔离操作,严禁盲目给出高风险维修建议。
领域大模型微调的工程通过 LoRA 微调层实现了轻量化部署,并结合 RLHF 机制建立了基于专家经验的反馈路径,确保模型输出不逾越生产安全红线。这种策略在降低算力成本的同时,实现了从私有数据到专家经验的完整转化。
3.7.2 智能体效能评测与自进化闭环
企业级智能体的生命力取决于其在真实业务流中的进化能力。本方案弃用 BLEU、ROUGE 等传统 NLP 指标,构建了以业务执行结果为核心的评测体系,量化 Agent 在多步推理与工具调用中的实际表现。
核心指标体系由决策准确率、工具调用成功率及业务终态达成率构成。决策准确率(Decision Accuracy)考核 Agent 在复杂任务编排中选择正确逻辑分支的比例;工具调用成功率(Tool Call Success Rate)监测 API 参数构造的准确性及异常捕获能力;业务终态达成率(Goal Completion Rate)则衡量从用户发起请求到 ERP/MES 系统执行完毕的闭环成功率。下表定义了不同场景下的评测基准:

为实现持续进化,系统内置了基于“错题本”机制的自动化重训练流水线。当 Agent 遭遇工具调用失败、用户负向反馈或人工接管时,系统会自动采集该会话的 Trace 序列,并将其推送到待审阅队列。通过自动化数据清洗与增强技术,这些失败案例被转化为新的训练样本。
在进化路径选择上,系统支持增量 SFT 与直接偏好优化(DPO)。DPO 算法无需训练奖励模型,直接在偏好数据上进行策略微调,显著提升了模型对新出现设备故障模式的学习速度。这种自进化机制确保了智能体能够随着集团业务逻辑的变更而动态成长,从静态软件资产演变为具备自我迭代能力的数字劳动力。通过定期触发增量微调,Agent 在复杂工业场景下的决策置信度随运行时间的增加而稳步提升。
第4章 业务应用:设备全生命周期智能运维自治系统
设备全生命周期智能运维自治系统以Agent引擎为核心,整合工业互联网协议转换与SRE运维方法论,实现从物理设备接入、状态监测、故障诊断、自动化自愈到资产报废的标准化管理。系统底层基于云原生架构构建,利用Prometheus监控指标体系与OpenTelemetry分布式链路追踪技术,对设备运行状态、网络拓扑及微服务调用链进行全栈可观测性覆盖。边缘侧部署的轻量化Agent负责实时采集振动、温度、电流等高频传感器数据。系统利用eBPF技术捕获内核级系统调用,在不侵入业务逻辑的前提下获取高精度运维数据,为异常检测提供高保真数据源。
在设备接入阶段,系统支持MQTT、OPC-UA、Modbus等主流工业协议的标准化转换,通过Schema映射机制将异构数据统一转化为标准时序模型。监测环节引入动态基线算法与多维指标关联分析,识别潜在的性能衰减趋势与瞬时异常波动。当系统检测到指标偏离预设阈值或触发异常模式匹配时,Agent引擎立即启动故障诊断逻辑,结合预置的专家经验库与拓扑关联图谱,快速锁定硬件故障、配置错误或网络拥塞等根因。自愈机制依托自动化脚本库与容器编排能力,在满足安全策略的前提下执行重启、扩容、切流或参数调优等恢复动作,将平均恢复时长(MTTR)控制在分钟级。
安全合规性方面,系统严格遵循GB/T 22239-2019等级保护三级标准。全链路通信采用国密SM2/SM4算法加密,确保数据在采集、传输及存储过程中的机密性与完整性。身份认证体系基于零信任架构,对所有接入Agent及管理终端进行动态授权与持续验证,防止非法接入与指令篡改。此外,系统内置审计模块,详尽记录设备生命周期内的每一次状态变更、配置更新与运维操作,为资产合规性审查与残值评估提供不可篡改的原始凭证。
该自治系统将运维逻辑下沉至Agent执行层,以此缓解中心化管理平台的计算压力,并提升大规模设备集群的响应实时性。系统不仅关注单一设备的运行效率,更通过全局资源调度优化,延长设备物理寿命,降低非计划停机带来的经济损失。这种从被动响应向主动预测、从人工干预向机器自治的演进,构成了工业企业数字化转型中资产治理的核心工程实践,为构建高可靠、可扩展的工业运维体系提供了明确的技术路径。
4.1 设备资产数字化建档与孪生映射
4.1.1 统一设备主数据管理
设备资产数字化建档以设备BOM(物料清单)为核心逻辑,构建“系统-子系统-关键部组件-易损件”四级层级化数据结构。编码规则执行GB/T 14885《固定资产分类与代码》标准,采用“10位分类码+4位流水码+2位特征码”的组合逻辑,赋予全矿井设备唯一的身份标识(UID)。系统通过RESTful API集成接口实现与ERP(SAP/Oracle)及EAM系统的主数据同步,覆盖规格型号、采购批次、入库日期及折旧状态等维度。
针对BOM变更,系统配置了标准化审批流。现场发生设备大修或非标改造时,由工程部发起BOM修正申请,经技术总工在线审核后更新数字化档案。该机制确保了财务账面、物理实体与数字孪生模型的数据一致性,规避了“一物多码”或“账实不符”的管理风险,为备品备件预测性采购与精准维修提供权威数据源。
4.1.2 3D数字孪生可视化面板
系统基于WebGL标准与Three.js引擎,构建矿区、车间、生产线、单体设备四级联动场景。利用对CAD原始图纸及点云扫描数据的GLTF格式轻量化处理,完成1:1几何模型还原。车间级场景集成环境参数、物流路径及全局设备稼动率(OEE);设备级场景利用WebSocket协议实时接收底层PLC及传感器报文,采样频率控制在100ms以内,将电机转速、电流、轴承振动频率及液压压力等参数映射至3D模型对应构件。
具体的数字孪生映射逻辑如下图所示:
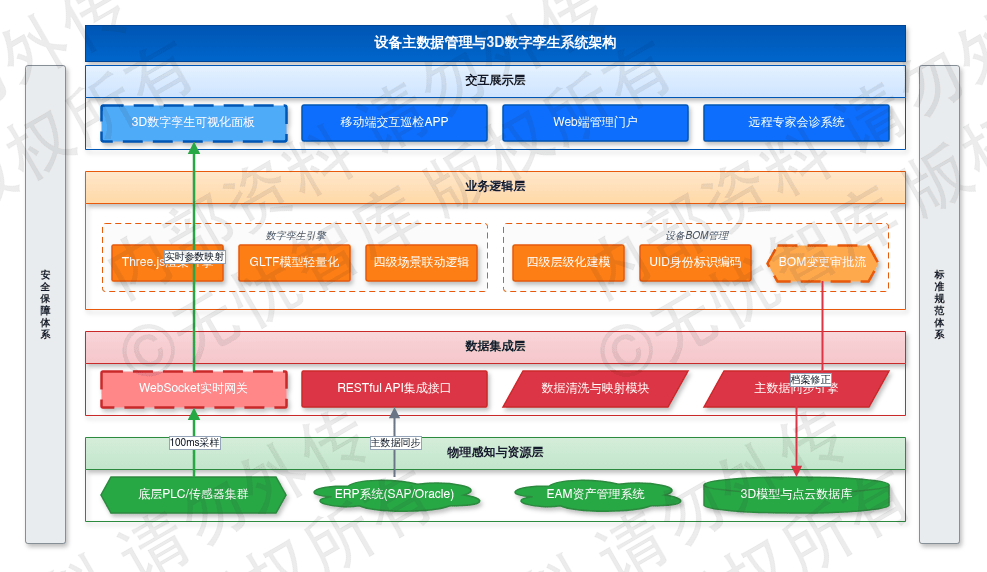
综上所述,该架构定义了从物理感知层到虚拟映射层的数据流转路径。运维人员利用Web端或移动端执行交互式巡检,通过点击3D模型部件调取实时运行曲线、历史故障记录及数字化操作手册。此类可视化管理模式将文本报表转化为动态场景,在降低现场巡检强度的同时,为远程专家会诊提供高保真现场还原支持,确保设备异常状态的可视化溯源。
4.2 实时状态自主感知与异常检测
4.2.1 边缘侧高频数据流处理
在设备全生命周期智能运维体系中,实时状态感知的核心挑战在于工业现场高频、异构、海量时序数据的瞬时处理压力。传统云端处理模式受限于网络带宽抖动及传输延迟,难以支撑毫秒级的故障捕获。本系统确立了以边缘计算(Edge Computing)为核心的感知架构,在靠近数据源头的边缘网关或本地算力节点上部署 Apache Flink 边缘轻量化引擎,执行 IoT 时序数据的就地清洗、降噪与特征工程提取。
针对设备传感器产生的原始高频采样数据,如振动频率、瞬时电压、主轴转速等,Flink 任务利用 KeyedProcessFunction 算子对不同设备 ID 的数据流进行状态化隔离。数据清洗阶段重点解决传感器漂移、丢包造成的异常零值或逻辑坏值,系统采用拉格朗日插值算法进行实时补全,确保时序数据的连续性。降噪环节引入卡尔曼滤波(Kalman Filter)算子,通过预测更新循环剔除电磁干扰产生的白噪声,提升输入至预测模型的信号信噪比。
特征提取环节利用 Flink 的状态管理(State Management)特性,在内存中实时维护设备运行的统计特征。系统不仅计算峰峰值、均方根值、偏度、峭度等时域指标,还通过集成快速傅里叶变换(FFT)算子生成频域特征向量。Side Output(侧输出流)机制将清洗后的原始流定向至实时告警模块,主输出流则将提取的特征向量异步推送至时序数据库(TSDB)进行长周期持久化。这种架构在保证感知实时性的同时,有效降低了核心链路的计算负载。
为进一步优化边缘侧资源占用,系统采用了基于 Protobuf 的序列化协议,相比 JSON 格式降低了 60% 以上的传输带宽需求。同时,边缘节点具备反压(Backpressure)自适应调节能力,当本地算力达到阈值时,系统自动启动降采样策略,优先保障核心安全指标的计算频率,确保在极端工况下感知链路的可用性。
边缘侧高频数据流处理的技术规格与策略如下表所示:

4.2.2 基于 Agent 的动态阈值自适应告警
传统的静态阈值告警机制在复杂工业环境下存在局限性。在设备启动、负载剧烈波动或环境季节性变化时,固定上限值极易触发大量误报,导致运维人员产生告警疲劳。本系统引入基于智能 Agent 的动态阈值自适应技术,使告警边界随设备工况(Operating Conditions)的变化自主平滑漂移。
该 Agent 运行在自治系统的核心控制层,决策机制建立在“基线预测+残差分析”逻辑之上。Agent 实时订阅来自边缘侧的设备运行参数,包括环境温度、负载率、累计运行工时,并结合设备历史运行画像,利用长短期记忆网络(LSTM)生成未来 10 分钟的预期状态区间。当实时监测值偏离该区间且超过置信度边界(通常设定为 3σ 准则)时,Agent 判定为异常。报警阈值不再是固定常数,而是随着主轴转速提高、负载增大而同步抬升的动态包络线。
Agent 具备多维协同推理能力,能够识别环境关联性引发的参数波动。例如,当环境温度升高导致电机壳体温度同步上升时,Agent 自动调取环境传感器数据进行关联比对,自主放宽温度阈值上限以消除误报。若环境温度恒定而电机局部温升速率(RoC)超过历史基线 20%,即使绝对值未达到物理极限,Agent 也会识别出隐性异常并提前触发预警。这种机制实现了从被动阈值触发向主动异常发现的转变。
实时状态感知与异常检测的业务流转逻辑如下图所示:
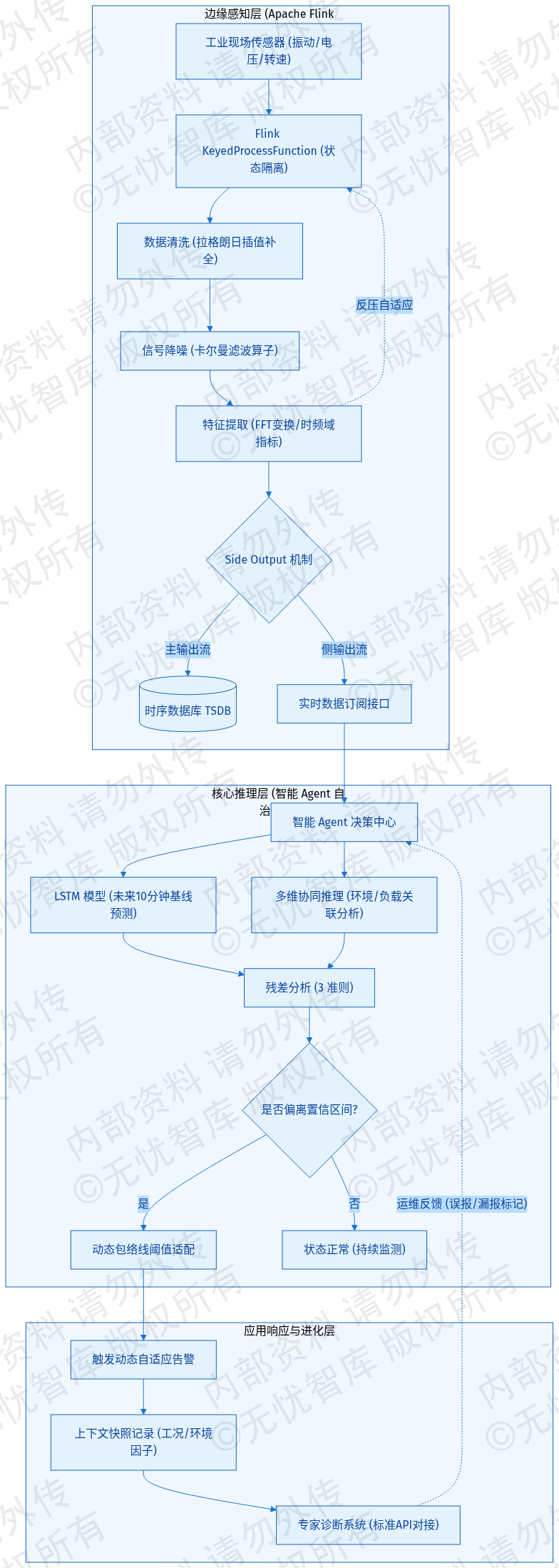
如上图所示,该架构展示了从边缘侧 Flink 高频流处理到 Agent 动态阈值推理的完整数据链路。数据经由感知层采集后,在边缘层完成清洗与降噪,随后进入核心 Agent 进行工况识别与阈值适配,最终输出精准的异常判定结果。
基于 Agent 的动态告警策略显著降低了无效误报率,并为后续的根因分析(RCA)提供了高质量触发信号。系统自动记录告警触发时的完整上下文快照(Context Snapshot),包括当时的工况参数、环境因子及 Agent 调整阈值的逻辑依据。这些数字化支撑信息通过标准 API 接口对接至专家诊断系统,缩短了故障确认与响应的周期。Agent 还会根据运维人员的反馈结果(如误报确认、漏报标记)持续微调 LSTM 模型的超参数,实现告警逻辑的进化。
4.3 预测性维护(PdM)与劣化趋势分析
预测性维护(PdM)依托工业物联网与人工智能技术,实现从被动维修向主动干预的模式转变。本章节聚焦于核心部件的健康状态量化与维护决策的自动化编排,利用高频感知数据构建设备劣化的数字孪生模型。系统通过实时监测关键物理参数,结合深度学习算法精确推演部件的剩余寿命,并由智能Agent协同生产排产与物流供应,输出最优化的维护时序方案,在保障生产连续性的前提下,最大限度延长设备服役周期并降低运维成本。
4.3.1 核心部件剩余寿命(RUL)预测
针对轴承、电机、主轴等高价值部件,系统构建了基于多源异构数据的RUL预测框架。边缘计算网关实时采集振动、温度、电流及转速信号,执行特征提取与降噪预处理。在建模层面,系统采用物理机理与深度学习融合的“灰盒”方案。针对具有明确退化规律的轴承,引入Paris公式描述疲劳裂纹扩展;同时,利用长短期记忆网络(LSTM)提取时序数据的非线性特征。Transformer架构的自注意力机制负责动态分配不同工况下的传感器权重,增强了系统在变载荷、变转速场景下的预测鲁棒性。
系统输出的劣化曲线包含实时健康得分(Health Score)与未来运行轨迹的置信区间。当振动信号的峭度指标或有效值超过预设阈值时,RUL预测模块即刻触发。预测结果以天或小时为单位,量化部件距离失效点的剩余时长。以数控机床主轴轴承为例,系统分析连续240小时的频谱演变,识别内圈剥落征兆,输出RUL预测值为15.5天,置信度达92%。该量化指标直接关联备件采购流程,有效降低了非计划停机风险。
核心部件健康度演进与劣化趋势如下图所示:
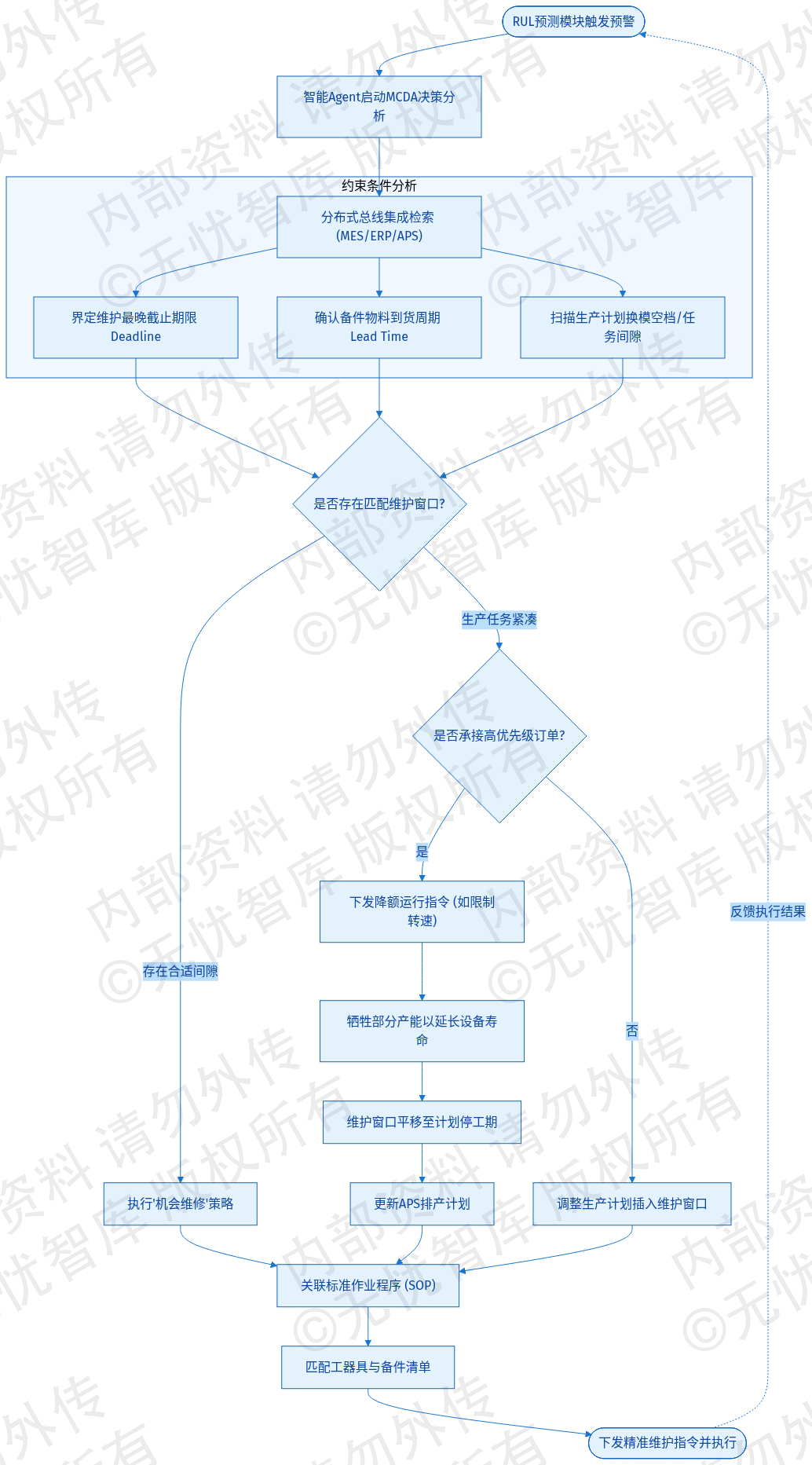
如上图所示,劣化曲线完整覆盖磨合期、稳定运行期及早期劣化点。置信区间包络线为运维决策提供了可视化依据。
下表定义了典型部件的监测参数与算法规格:

4.3.2 维护窗口智能规划
智能规划Agent负责将RUL预测结果转化为生产调度指令。该Agent通过分布式总线集成MES生产计划、ERP备件库存及APS交付优先级,构建多约束目标优化模型。在接收到RUL预警后,Agent启动多准则决策分析(MCDA),在设备运行安全与生产任务达成率之间寻求平衡。
决策流程首先界定维护的最晚截止期限(Deadline)。Agent同步检索备件管理模块,确认所需物料的到货周期(Lead Time)。随后,系统扫描生产计划中的换模空档或任务间隙,定位潜在停机窗口。若当前承接高优先级订单,Agent将下发降额运行指令(如限制主轴转速),以牺牲部分产能为代价延长设备寿命,将维护窗口平移至订单交付后的计划停工期。
针对生产线冗余产能,Agent推荐“机会维修”策略。在相邻设备执行计划保养时,同步完成劣化部件更换,实现停机损耗最小化。此逻辑将技术可行性与企业经营目标深度耦合,确保运维活动直接服务于业务价值。
维护窗口智能规划的业务流转时序如下图所示:
如上图所示,流程涵盖预警触发、约束检索、排程仿真到指令下发的全过程。Agent的自主推理降低了人工协调成本。系统在输出窗口建议时,同步关联标准作业程序(SOP)与工器具清单,确保维护任务精准执行。
4.4 根因分析与智能诊断报告生成
4.4.1 故障特征向量提取与匹配
故障特征提取始于对设备关键物理量(如轴承振动频率、电机电流畸变率、液压系统压力波动)的实时监测。当系统检测到参数突破动态阈值(Dynamic Threshold)或触发异常检测算法告警时,自动启动“黑匣子”回溯机制,同步截取故障触发时刻前后各5分钟的高频采样数据流。该机制确保捕捉到故障发生前的微弱扰动信号(Pre-fault Indicators)以及故障发生后的瞬态响应特征。
提取过程采用多维特征向量化技术,将原始时序数据转化为包含时域、频域及非线性动力学特征的向量空间模型。时域特征涵盖均值、标准差、偏度、峭度等统计指标;频域特征通过快速傅里叶变换(FFT)或小波变换(Wavelet Transform)提取特定频段的能量分布;非线性特征则引入信息熵与分形维度。系统利用加权余弦相似度或改进的欧式距离算法,将实时特征向量与历史故障案例库(Case-Based Reasoning, CBR)中的特征指纹进行高速比对。通过设定85%以上的相似度置信度,系统能够精准识别当前故障是否属于已知模式(如轴承外圈剥落、润滑失效),从而为后续的根因推断提供量化依据。
4.4.2 诊断报告自动生成与推送
在完成根因定位后,智能运维Agent作为核心调度组件,负责汇总多源诊断数据。这些数据包括实时报警详情(告警级别、发生时间、测点位置)、基于知识图谱生成的根因传播路径,以及专家经验库匹配的标准化处置建议(SOP)。Agent利用自然语言生成(NLG)技术,将技术参数转化为结构化的诊断报告,确保信息的专业性与可读性。
智能诊断报告生成的业务流转逻辑如下图所示:
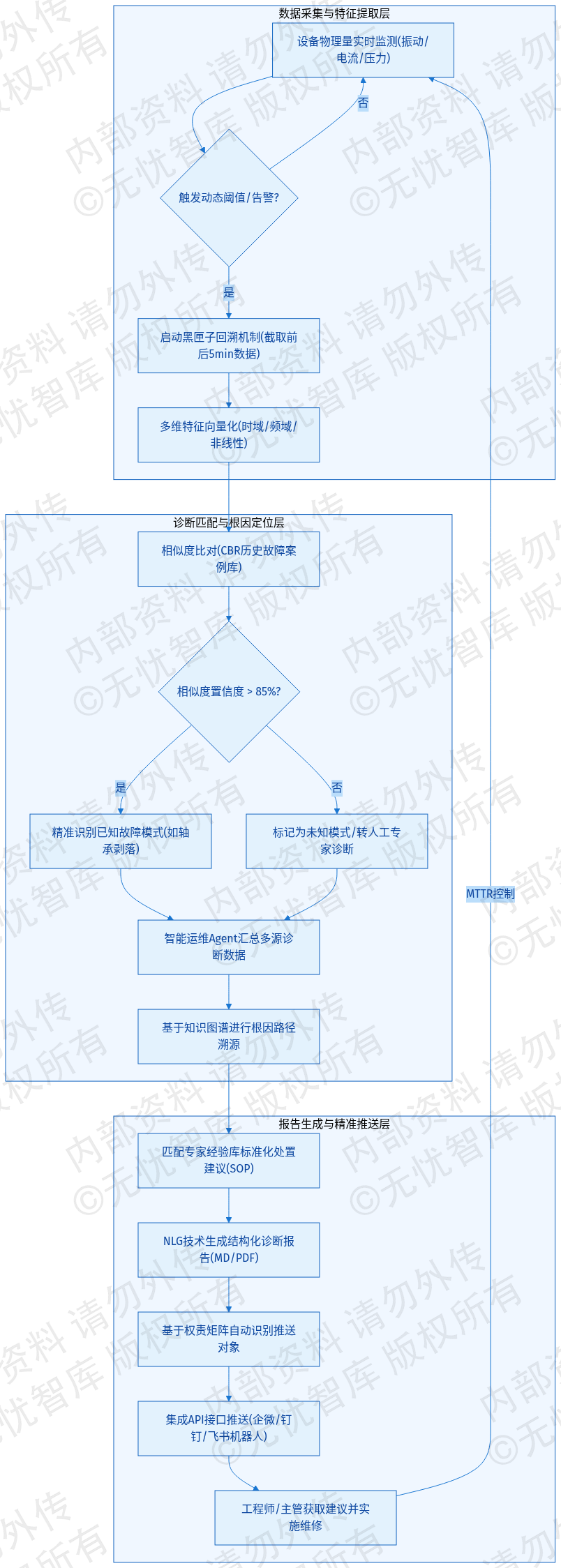
如上图所示,该流程实现了从底层数据捕获、特征空间映射到顶层决策建议生成的全链路处理。生成的报告支持Markdown与PDF双格式输出:Markdown格式便于在移动端快速预览与交互,PDF格式则作为正式的设备维修档案进行归档。报告生成后,系统通过集成API接口,利用企业微信、钉钉或飞书等即时通讯工具的机器人(Bot)功能,实现秒级精准推送。推送对象根据设备所属权责矩阵自动识别,确保维修工程师、产线班组长及设备主管在故障发生后的3分钟内获取完整的诊断建议。该机制通过主动推送模式,将故障响应时间(MTTR)控制在预设阈值内,提升了生产现场的自治化管理水平。
4.5 运维工单自动生成与任务分发
本章节聚焦于将传统被动式、人工驱动的运维模式转化为基于智能Agent的自主响应体系。系统核心逻辑在于构建一个从底层感知数据到顶层执行指令的自动化流水线,旨在消除人工调度产生的决策延迟与信息衰减。该体系整合了工业物联网(IIoT)实时遥测、大语言模型(LLM)语义解析、运筹优化算法以及增强现实(AR)交互技术。通过对设备运行状态的毫秒级监控,系统能够精准识别异常模式并自动触发工单创建流程。这一过程不再依赖运维人员的主观判断,而是通过预设的故障特征向量与业务规则引擎进行硬性匹配。任务分发模块则进一步引入了多维约束求解器,综合考量人员地理位置、技能熟练度、备件库存及生产计划优先级,确保每一张工单都能在最优时间内分配至最匹配的执行单元。这种架构设计不仅提升了平均修复时间(MTTR)的确定性,也为后续的预测性维护与资产全生命周期管理提供了标准化的数据输入。
4.5.1 智能派单与人员技能匹配
在设备全生命周期运维体系中,传统的“人工报修-调度中心派单-人工接单”模式已成为制约平均修复时间(MTTR)的核心瓶颈。本系统引入基于大模型(LLM)与运筹优化算法的智能派单Agent,实现从故障感知到任务分发的全链路自动化。当感知层的物联网传感器触发高阈值告警,或边缘计算节点识别出设备运行参数偏离基准线时,系统自动提取故障特征向量。这些特征向量包含设备型号、故障代码(DTC)、实时运行工况以及预警等级,随后推送至智能调度引擎。
智能派单Agent的决策逻辑基于多维约束的最优解计算。系统通过RPA接口与企业HR系统及排班系统对接,实时获取运维工程师的在线状态、当前地理位置(基于移动端App的LBS数据)以及预定排班计划。系统建立了精细化的“人员技能画像”模型,该模型分析工程师过去24个月的工单执行履历,量化其对特定品牌、型号及特定故障类型(如机械磨损、电子控制单元失效、液压系统泄露等)的修复成功率、平均耗时以及复修率。Agent利用协同过滤算法,将当前故障的特征与工程师的技能标签进行语义匹配,计算出技能契合度评分。为了保证评估的客观性,模型引入了基于马尔可夫链的技能衰减因子,考虑到工程师长时间未操作特定型号设备可能导致的熟练度下降。
在执行路径优化方面,系统集成了高德/百度地图API,综合考虑交通拥堵状况、工程师当前剩余工时负载以及备品备件库的库存分布。Agent计算出一条包含“备件领取-故障现场-下一任务点”的最优路径。调度引擎通过Webhook实时订阅城市交通大脑的拥堵指数,将预期到达时间(ETA)的误差控制在5%以内。若当前最优人选处于高负载状态,系统自动触发动态优先级调度算法,评估该故障的SLA等级。对于影响生产线的关键设备故障(P0级),系统强制剥离该工程师手中的非紧急任务并重新分配。这种基于Agent的自治派单模式,将派单延迟从小时级降低至秒级,人员利用率提升25%以上。
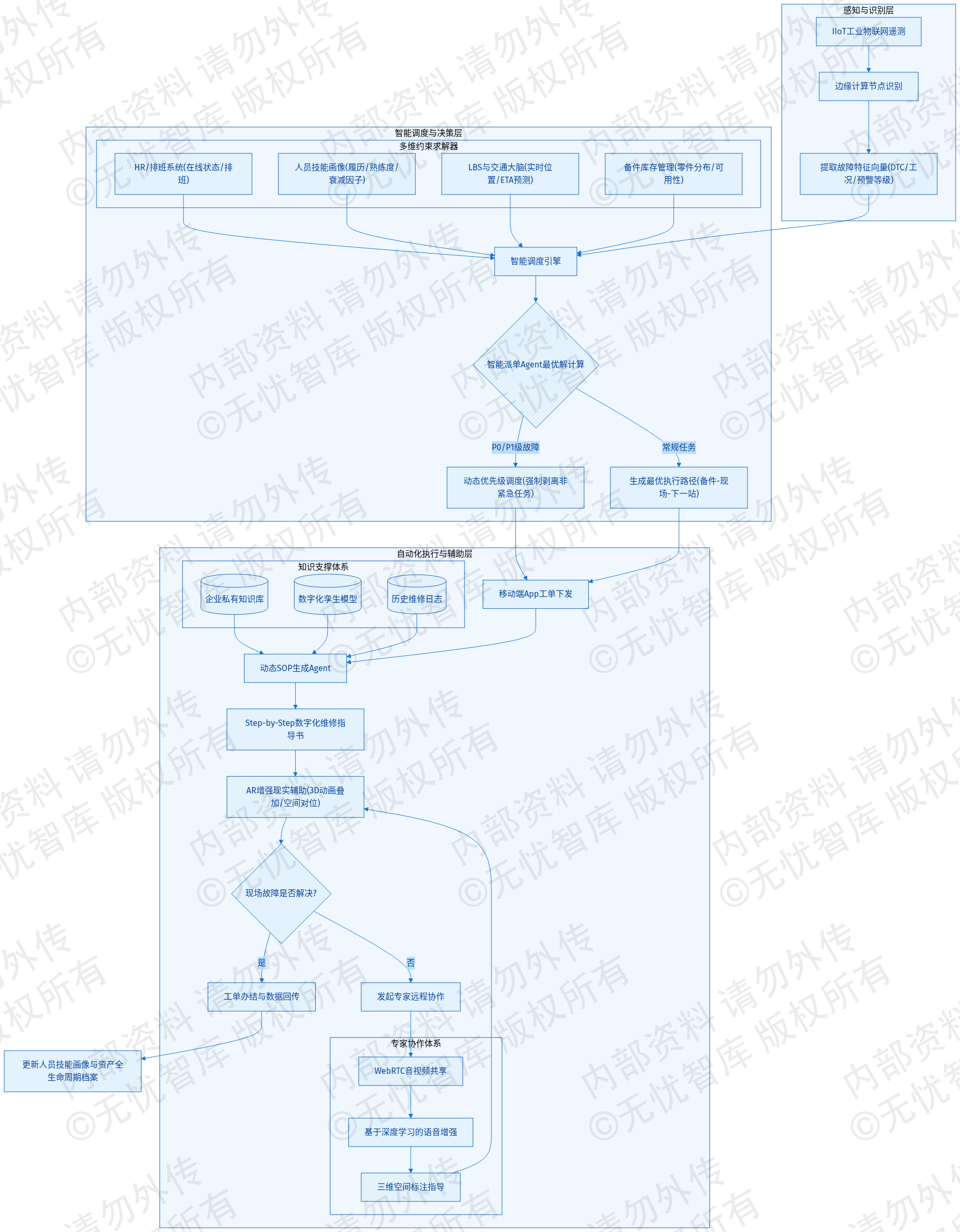
该流程展示了从底层故障信号捕获到顶层决策Agent进行多维因子加权计算,最终通过移动端App完成指令下发的完整过程,确保了派单动作的客观性与高效性。
4.5.2 维修SOP动态生成与AR辅助
针对复杂工业设备维修过程中高度依赖专家经验、纸质手册查询低效等问题,本系统构建了基于知识图谱与多模态大模型的动态SOP(标准作业程序)生成机制。当工单下发至工程师移动终端的同时,后台Agent根据故障上下文信息——包括具体的错误代码、设备的历史维修记录、实时遥测数据流以及该批次设备的数字化孪生模型(Digital Twin),自动检索企业私有知识库。系统调用过往专家修复同类故障时的结构化日志、标注视频以及避坑指南,实时生成一份具备针对性的Step-by-Step数字化维修指导书。
这份动态SOP具备高度的上下文感知能力。如果传感器显示设备当前处于高压或高温状态,SOP的第一步自动强制插入“安全泄压”或“冷却等待”操作,并要求工程师通过手机拍照或语音确认后方可进行下一步,从而在底层逻辑上规避安全风险。对于初级工程师,SOP增加更多基础原理说明与零件位置示意;对于资深工程师,则精简流程,直达核心更换步骤。这种动态调整机制缩短了现场查阅资料的时间,使新员工的独立上岗周期缩短了40%。
在现场执行阶段,系统深度集成了AR(增强现实)辅助技术。工程师佩戴AR眼镜或使用平板电脑扫描设备机身二维码后,系统将数字化孪生模型与物理实体进行1:1空间对位重叠。AR辅助模块采用了基于边缘计算的渲染技术,将复杂的3D模型渲染压力从眼镜端卸载至边缘网关,确保了60FPS的画面流畅度与低于20ms的交互延迟。维修指导步骤以3D动画的形式直接叠加在故障部位上,例如:指示灯闪烁提示需拆卸的特定螺栓、虚拟箭头指向需调整的阀门开度。
当遇到现场无法解决的疑难杂症时,工程师可一键发起“专家远程协作”。此时,后端Agent匹配当前故障领域的最优技术专家,通过AR眼镜的音视频流实现“第一视角”共享。系统利用WebRTC协议进行音视频传输,并针对工业现场的高噪声环境,集成了基于深度学习的语音增强算法,确保专家指令的清晰传达。专家在自己的屏幕上进行三维空间标注,这些标注实时同步显示在现场工程师的视场中。通过这种AR辅助与动态SOP的结合,首次修复成功率(FTFR)提升至90%以上。
为了清晰展示维修过程中的技术支撑体系,下表列出了不同故障等级下的SOP生成策略与辅助资源配置:

通过动态SOP与AR技术的融合,系统构建了一套跨越空间限制的知识传递体系,解决了工业现场人才断层与维修质量波动的难题。
4.6 备品备件智能预测与库存优化
本模块旨在解决传统备件管理中库存积压与关键件短缺并存的矛盾。系统通过整合设备健康监测数据与供应链业务流,构建动态补货与跨厂区调拨机制,将备件保障由事后响应转为事前精准预测,提升资产周转效率。
4.6.1 基于消耗模型的备件需求预测
系统建立基于消耗模型的动态预测机制,将预测性维护(PdM)输出的设备健康度衰减曲线与历史消耗规律进行特征融合。数据架构层面,ODS层实时抽取ERP出入库记录、EAM工单历史及SCADA设备运行工时;DWD层对备件唯一标识(Material ID)进行标准化,建立备件与设备组件、故障模式及环境因子的关联逻辑。
建模过程采用长短期记忆网络(LSTM),输入变量涵盖设备运行负荷、平均故障间隔时间(MTBF)及季节性环境参数,输出未来30至90天的备件需求概率分布。当边缘计算网关监测到电机振动或轴承温度等关键指标偏离基准值时,预测性维护Agent同步触发关联备件库存核查。若可用库存低于预测阈值,系统结合物料主数据(MDM)中的采购提前期(L/T)与供应商评价等级,自动生成采购申请(PR)草案。该草案明确建议采购量与期望到货日期,直接推送到采购审批流,缩短响应周期。
4.6.2 呆滞库存预警与跨厂区调拨
针对分布式厂区布局,系统利用库存周转率监控模型执行全域备件ABC分类管理。呆滞预警算法结合“最近领用时间”与“未来需求概率”进行双重判定:当备件连续180天无领用且未来90天需求概率低于15%时,系统自动标记为呆滞资产。
Agent随后启动全域库存扫描,检索其他厂区是否存在同类物料需求。在执行调拨建议时,系统采用多目标优化算法,综合评估地理距离、物流成本及各厂区生产计划优先级。例如,当A厂区存在呆滞伺服电机,而B厂区因故障急需且外部采购周期较长时,系统计算调拨成本与停机损失的差值。若综合效益为正,系统即刻下达跨厂区调拨指令,同步更新ERP系统中的调拨工单与库存状态。此机制可有效降低全域安全库存水平,减少库存资金占用约15%-20%,增强供应链响应灵活性。
4.7 设备健康自愈与参数闭环控制
设备健康自愈机制是提升工业系统稳态运行率的核心手段,旨在解决生产过程中频繁出现的非物理性性能衰减。系统通过集成智能 Agent 与工业控制层的深度交互,构建了从异常感知、根因推断到指令反向执行的完整路径。该机制不仅涵盖了针对逻辑冗余与参数漂移的自动复位技术,还通过严密的校验协议确保了控制指令在下发过程中的安全性与合规性。本章节重点阐述软性故障的参数寻优逻辑以及闭环控制中的安全审计架构。
4.7.1 软性故障自动复位与参数寻优
软性故障定义为非物理硬件损坏导致的系统亚健康状态,如 PID 控制参数因工况波动产生的超调、通信链路瞬时拥塞引发的逻辑死锁或传感器零点漂移。此类故障在传统模式下依赖人工巡检复位,响应滞后且调整缺乏数据支撑。系统利用 Agent 的 Tool-Use 能力,建立了直接干预现场 PLC 的自动化路径。
自愈流程由监测层对设备运行指标的连续采样触发。当 Agent 识别到流量控制回路的比例增益(P)、积分时间(I)或微分时间(D)偏离历史最优区间时,自愈推理引擎随即启动。Agent 调度标准化下控接口工具集,在不中断生产的前提下重置受影响的逻辑功能块。针对参数寻优,系统将介质粘度、压力波动及环境温度作为输入向量,在数字孪生仿真环境中进行迭代计算。寻优算法基于强化学习模型,输出满足当前工况的最优控制参数集,并通过 OPC UA 或 Profinet 协议将其写入 PLC 的 DB 块。
下表对比了传统运维与智能自愈模式的技术差异:

软性故障自愈依赖于符合 GB/T 33863 标准的分级控制指令库。Agent 在执行参数修正前,需通过历史履历数据进行一致性校验,确保寻优结果不超出设备物理极限。在离心泵变频控制场景中,Agent 严格限制频率调整的变化率,规避因参数突变诱发的电机喘振。这种数据驱动与物理约束相结合的模式,确保了复杂工况下的设备稳定性。
设备健康自愈的逻辑流转如下图所示:
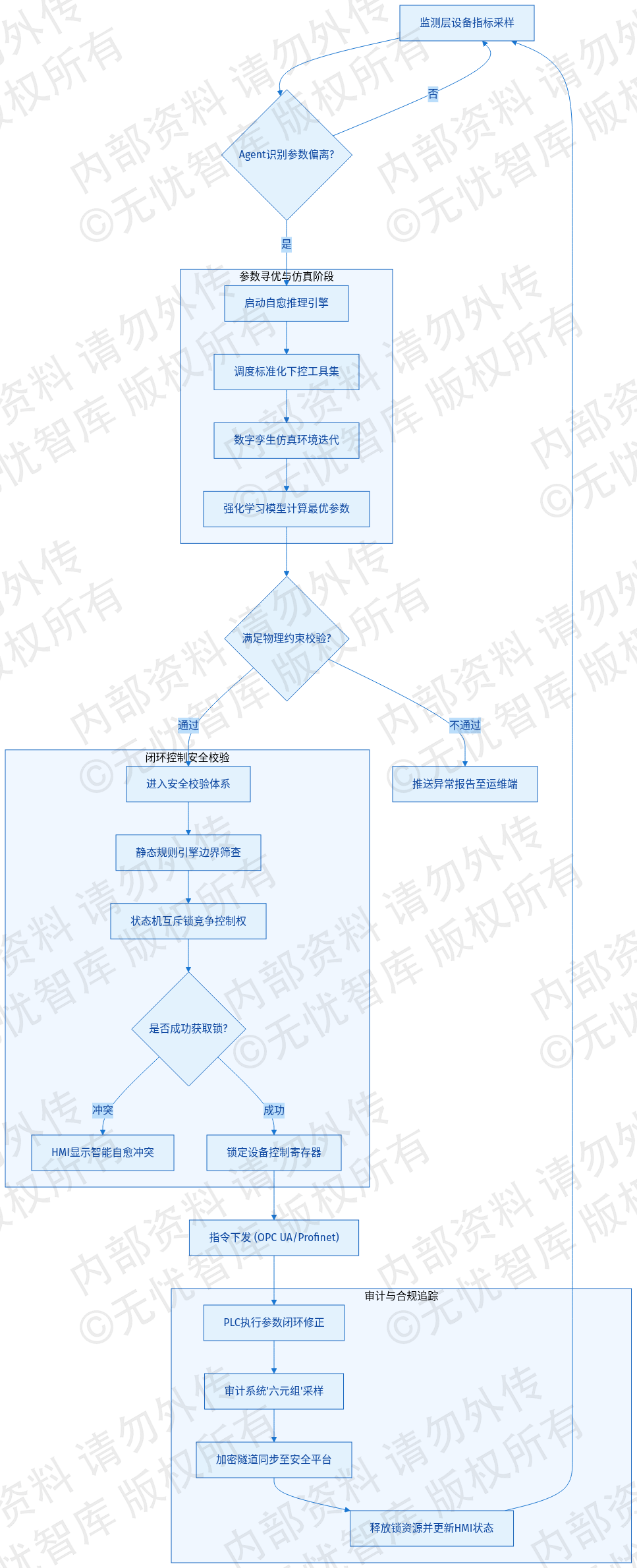
如下图所示,该流程展示了从故障感知、Agent 推理决策、数字孪生验证到 PLC 指令下发的全路径。该架构实现了故障处理的自动化衔接,将软性故障对生产节拍的影响降至最低。
4.7.2 闭环控制的安全校验与审计
反向控制指令的下发直接关联生产安全,未经校验的参数修改可能导致非计划停机。系统构建了闭环控制安全校验体系,确保自愈指令在触达物理层前经过逻辑过滤。该体系遵循 GB 17859 等级保护要求,实现了指令全生命周期的审计追踪。
安全校验的第一道防线为静态规则引擎。系统内置物理红线库,对 Agent 生成的优化指令进行边界筛查。若寻优算法建议将给水泵转速提升至额定值的 110%,校验模块将基于位号关联的额定参数实施拦截,并向运维终端推送异常报告。第二道防线为基于状态机的互斥锁机制。在手动控制、本地 PLC 逻辑与远程 Agent 闭环控制并存的情况下,系统通过控制权竞争算法防止指令冲突。Agent 获取控制权后,自动锁定设备控制寄存器,并在 HMI 界面同步“智能自愈中”标识,屏蔽其他控制源的注入,直至动作完成并释放锁资源。
操作审计为闭环控制提供合规性证据。系统采用不可篡改的日志记录机制,对每条指令执行“六元组”采样:指令发起者 ID、执行时间、操作位号、修改前值、修改后值及校验结果。审计日志通过加密隧道同步至企业级安全平台。针对关键工艺节点的参数调整,系统强制执行双因子确认流程,要求具备资质的工程师进行数字签名。这种人机协同模式在保证运维效率的同时,将安全风险控制在预设范围内。通过定期回溯审计日志,系统能够持续迭代 Agent 决策模型,支撑 EPC 项目的智能化自治需求。
4.8 运维绩效评价与持续改进闭环
4.8.1 OEE与MTBF/MTTR多维指标看板
运维绩效评价体系通过量化设备运行状态与维护效率,为运维策略的迭代提供数据支撑。系统构建了基于设备综合效率(OEE)的深度分析模型,采集边缘侧PLC、SCADA系统的毫秒级生产数据,并关联运维管理平台的工单流转状态,实现停机损失、速度损失与质量损失的高频聚合。该模型对“六大损失”进行精细化拆解,涵盖计划外停机、设置与调整、空转与短暂停机、速度降低、启动过程次品以及生产过程次品。系统通过实时监控上述因子,刻画设备在运行、维护、待机各环节的效能分布,识别影响产线稼动率的核心瓶颈。
针对设备可靠性与维修响应能力,系统建立MTBF(平均故障间隔时间)与MTTR(平均修复时间)的动态演化看板。MTBF的计算引入威布尔分布(Weibull Distribution)模型,通过对历史故障序列进行非线性拟合,计算设备失效率曲线,预测设备进入耗损故障期的临界时间点。MTTR指标则参考站点可靠性工程(SRE)观测标准,将其细分为故障发现时间(MTTD)、响应时间(MTTA)、诊断时间(MTTI)与修复验证时间(MTTR-fix)。这种多维度指标钻取能力可精准定位管理缺陷:若MTTA指标偏高,则触发告警响应机制或排班计划的重新评估;若MTTI指标异常,则指向知识库覆盖率不足或专家支持链路响应迟缓。
设备运行效能与可靠性分析看板如下图所示:
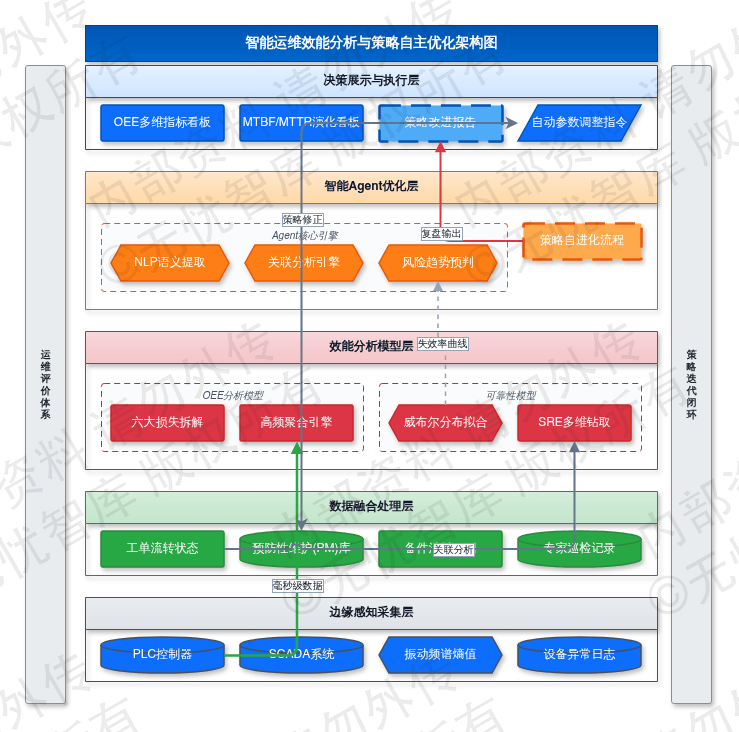
如上图所示,该看板通过多维度折线图与雷达图,展示OEE波动趋势及MTBF与MTTR的关联关系。系统支持按产线、工序、设备型号进行横向对标,自动定位低效能节点,引导运维资源向高风险区域倾斜,实现评价指标与执行动作的逻辑关联。
4.8.2 运维策略自主优化建议
系统集成智能Agent,按月度周期执行“复盘-优化”自进化流程,实现从历史经验到策略修正的自动转化。该流程利用自然语言处理(NLP)技术,对过去30天内的非结构化维修工单、专家巡检记录及设备异常日志进行语义提取,识别频繁发生但未触发核心故障告警的“微停机”事件。Agent将这些离散异常特征与现有的预防性维护(PM)计划进行关联分析,评估当前维护频次与设备实际损耗状态的匹配度。若特定组件在预定维护周期前频繁触发预警,Agent将识别维护周期过长风险,并输出调整建议。
在完成数据复盘后,Agent自动生成《月度设备健康度与运维策略改进报告》。报告涵盖风险趋势预判、策略优化建议与预期收益评估三大模块。针对特定设备,报告给出具体的参数调整指令,例如根据夏季环境温度变化,建议将关键泵组的润滑油更换阈值从粘度下降15%动态调整为12%,以应对加速老化风险。此外,Agent会对历史误告警进行过滤分析,输出告警抑制规则优化建议,降低一线人员的告警疲劳。
下表展示了系统根据Agent优化建议调整前后的策略参数对比:

通过持续改进闭环,企业运维模式从被动维修转向主动预防与智慧优化。每一份月度报告的产出均代表系统对物理设备特性认知的深化。基于Agent的自主优化机制,不仅沉淀了资深技师的隐性经验,更通过算法模型发掘人类直觉难以察觉的微观关联,构建设备全生命周期智能运维的逻辑闭环。
第5章 数据架构与知识图谱融合方案
本章聚焦于支撑Agent深度推理与自主决策的底层数据环境构建,确立以湖仓一体架构为核心、语义图谱为逻辑纽带的技术路径。针对企业级应用中异构数据存取效率低、语义关联缺失及实时性保障不足等工程挑战,本方案通过整合分布式存储、流批一体计算与向量检索技术,建立具备强一致性与高扩展性的数据供给体系。设计过程严格参照GB/T 36073-2018《数据管理能力成熟度评估模型》,将非结构化文档、半结构化日志与结构化业务数据统一接入对象存储层,利用Apache Iceberg或Hudi等表格式实现元数据的统一管理与版本控制,确保Agent在调用历史上下文时具备亚秒级的检索响应能力。
在数据治理维度,方案摒弃传统的静态管控模式,转而采用基于主动元数据的动态治理框架。通过自动化血缘解析工具追踪数据从源头采集、清洗转换到特征提取的全生命周期,建立字段级的质量监控规则,确保输入Agent的知识载体具备高置信度。针对语义断裂问题,本章详细阐述了知识图谱的构建全流程,涵盖本体建模、实体对齐及关系抽取等核心环节。通过将业务逻辑固化为图谱拓扑结构,Agent能够利用图计算算法进行多跳路径推理,弥补单纯依靠向量检索在复杂逻辑判断上的局限性。
此外,方案深度集成了向量数据库与图数据库的协同机制,实现语义向量与拓扑关系的双向索引。在工程实现上,依托Flink实现增量数据的实时入湖与入图,利用Kafka阵列承担高并发场景下的流量削峰,确保数据架构在万级QPS压力下仍能保持稳定的吞吐性能。本章将从底层物理存储设计、中层治理协议规范到上层语义图谱生成逻辑进行全方位剖析,输出涵盖存储拓扑、治理流程及图谱Schema在内的完整技术交付物,为Agent在复杂行业场景下的精准认知与高效执行提供确定性的技术支撑。
5.1 数据资源盘点与目录体系规划
数据资源盘点是工业知识图谱构建的逻辑起点。该过程旨在通过对生产现场全域数据的摸底,确立数据资产的物理分布与逻辑关联。本章重点围绕多源异构数据的分类梳理、企业级元数据标准的定义以及资产目录的构建展开。通过对底层 PLC/DCS 实时数据、中层 MES/ERP 业务数据及顶层技术文档的深度解析,建立标准化的数据底册,为后续的知识抽取与融合提供精确的 Schema 映射依据。
5.1.1 多源异构数据源梳理
工业知识图谱的构建依赖于对底层异构数据源的精确映射。本阶段工作聚焦于对企业生产现场、业务系统及技术文档进行全量扫描,根据数据特征将其划分为时序数据、关系型数据及非结构化数据,并制定差异化的采集策略。
针对 PLC 与 DCS 产生的设备时序数据,梳理重点在于其高频、海量且带有时间戳的特性。技术团队需适配 Modbus TCP、OPC UA、S7 等现场控制层协议,盘点涵盖电机转速、轴承温度、振动频率、压力数值等关键工艺参数。此类数据在接入前需明确采样频率(通常设定在 10ms 至 500ms 区间)、量程范围及工程单位。针对核心产线的 PLC 数据点位,需建立涵盖点位 ID、寄存器地址、物理意义、数据类型、所属设备及报警阈值在内的测点清单,为时序数据库的 Schema 设计提供物理依据。
针对 MES 与 ERP 中的关系型数据,梳理核心在于业务逻辑的关联性。此类数据存储于 Oracle、SQL Server 或 PostgreSQL 数据库中,包含工单履历、物料 BOM、质量检测记录及设备维保计划。梳理过程中需提取实体间的 E-R 关系,明确主外键约束,并对关键业务字段进行标准化定义。例如,将 MES 中的“工单号”与 ERP 中的“生产订单号”进行语义对齐,为知识图谱中“实体-关系-实体”的三元组构建提供结构化素材。
对于设备手册、工艺图纸、故障维修记录等非结构化数据,梳理重点在于语义信息的提取潜力。通过对 PDF、CAD、DOCX 等格式文档进行分类归档,建立文档元数据索引,包括文档编号、关联设备型号、版本号及权限等级。此类数据后续将利用 OCR 识别与 NLP 实体抽取技术,转化为图谱中的属性节点或知识条目。
企业多源异构数据源的物理分布与逻辑属性梳理如下图所示:
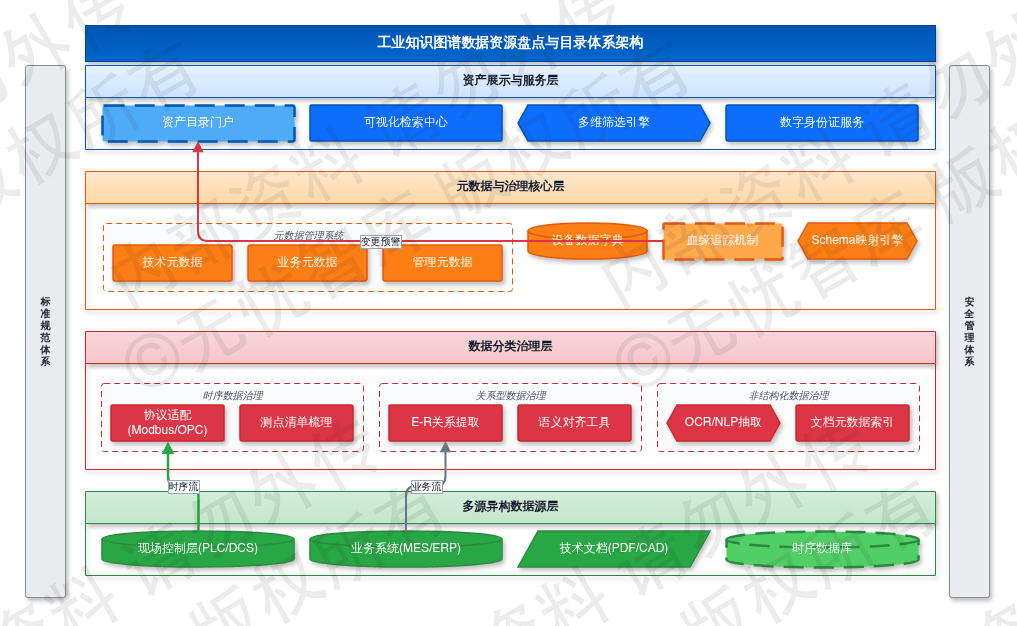
如上图所示,该架构展示了从底层物理感知到上层业务系统的全域数据分布,涵盖了时序流、业务流与文档流的分类治理路径。
5.1.2 数据资产目录与元数据管理
完成数据源梳理后,需构建统一的企业级数据资产目录与元数据管理体系,以解决数据检索困难与语义不一致的问题。建立设备数据字典可量化数据资产分布,并支持跨系统检索。
元数据管理遵循 DAMA 数据管理框架,分为技术元数据、业务元数据与管理元数据。技术元数据记录数据的存储引擎类型、表结构、字段类型及 ETL 血缘关系;业务元数据定义字段的业务含义、计算口径及所属业务域;管理元数据明确数据所有者、安全等级及更新频率。建立全局统一的字段命名规范,采用“动作+对象+属性”的组合命名法,消除异构系统间的语义歧义。
在设备数据字典的建设中,需重点规范以下核心维度:

为实现数据资产的可视化检索,平台构建了基于标签体系的资产目录。用户可根据设备类型、工艺环节、数据频次等维度进行多维筛选。每个数据资产均附带“数字身份证”,包含其全生命周期的元数据信息。
同时,系统建立了数据血缘追踪机制。当底层 PLC 点位发生变更时,该机制会自动触发预警并通知下游 ADS 层的指标负责人,确保数据链路的一致性。这种以元数据为核心的治理模式,提升了数据开发的效率,并为知识图谱的自动化更新提供了精准的 Schema 映射指引。
5.2 实时数据湖仓一体化架构设计
5.2.1 湖仓一体化总体逻辑架构
本系统采用基于 Hudi 与 Iceberg 存储协议的湖仓一体化(Data Lakehouse)架构,在 HDFS 或 S3 分布式存储层之上构建元数据管理层。该层级集成 ACID 事务特性、多版本并发控制(MVCC)及模式演进(Schema Evolution)能力,支持非结构化数据原始存储与高性能 SQL 实时更新。架构设计覆盖接入层、统一存储层、计算处理层与数据开放层,将数据流转延迟控制在秒级以内。
实时数据湖仓一体化总体逻辑架构如下图所示:
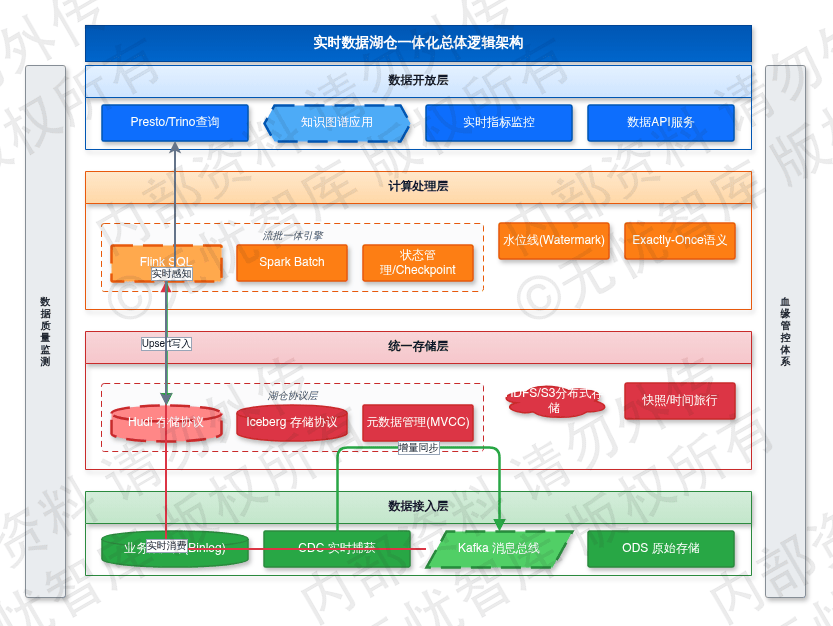
如上图所示,该架构利用统一存储底座消除存储介质差异。计算层整合 Flink 实时流处理与 Spark 批处理,确保 ODS 至 DWD 层的数据流转受统一事务机制约束,为知识图谱构建提供一致性数据源。
在工程实现层面,接入层通过 CDC 技术实时捕获业务数据库的 Binlog 日志并推送到 Kafka 消息总线。计算层利用 Flink SQL 消费 Kafka 增量数据并写入湖仓存储层。元数据服务同步表结构变更,使 Presto 或 Trino 查询引擎实时感知数据演进。该架构支持 Append 操作及基于主键的 Upsert 与 Delete 操作,满足金融级数据强一致性校验要求。
5.2.2 实时流处理与批处理融合机制
流批一体化架构在 API 层面统一采用 Flink SQL,实现业务逻辑与执行模式解耦。针对实时风险识别等高时效场景,系统运行流处理模式,依托 Flink 状态管理与水位线(Watermark)机制处理乱序数据。针对历史补数场景,系统自动切换为批处理模式,读取湖仓历史快照执行高吞吐计算。此机制确保了流计算与批计算业务口径完全对齐。
系统通过 Checkpoint 机制将算子状态定期持久化至分布式存储,在节点故障时触发 Exactly-Once 语义恢复。下表展示了流批一体化架构在典型业务场景下的技术参数:

5.2.3 湖仓数据版本管理与快照机制
为支撑数据回溯与知识图谱增量构建,架构引入多版本管理与快照(Snapshot)隔离机制。每次写入操作生成独立 Data File,并由 .metadata.json 文件记录快照 ID 与文件映射关系。用户可指定时间戳或快照 ID 执行“时间旅行”(Time Travel)查询。在实体对齐环节,若发现数据异常,系统可将查询视图切换至历史快照版本进行复核。
快照机制实现了高并发场景下的读写分离。实时流任务持续写入增量数据时,分析任务读取已提交的快照版本,规避读写冲突。系统配置自动清理策略(Vacuum),定期合并小文件并移除过期快照以优化存储效率。数据生命周期管理遵循 GB/T 36073-2018 标准,核心业务实体快照保留 365 天,临时过程指标保留 7 天,实现业务溯源需求与存储成本的平衡。
5.2.4 实时数据质量监测与血缘管控
系统在数据入湖 ODS 层、清洗 DWD 层及聚合 DWS 层布设质量监控探针。探针依据字段非空、唯一性、数值范围及外键一致性等规则执行实时校验。异常数据(Dirty Data)根据预设严重等级分流至死信队列(DLQ)或标记异常标签,阻断错误数据进入下游知识节点。
血缘管控(Data Lineage)覆盖从源系统到图谱应用的全链路。系统解析 SQL 执行计划并采集算子元数据,自动构建任务级血缘拓扑。血缘关系精确至字段级转换逻辑与版本演进关系。当上游业务系统发生 Schema 变更时,血缘模块触发影响分析并推送预警。系统根据兼容性策略执行宽表自动扩容,为数据资产审计与故障定位提供工程依据。
5.3 工业设备本体知识图谱构建
5.3.1 工业设备本体建模方法论
在EPC总承包项目的数字化交付中,工业设备本体建模是资产全生命周期管理的数据规约准则。本方案采用基于语义网技术的本体建模方法,解决多源异构环境下设备定义冲突与关联属性缺失问题。建模过程遵循本体工程生命周期,涵盖领域分析、概念提取、关系定义及实例映射,构建高扩展性的设备知识架构。
本体模型由类(Class)、属性(Property)与关系(Relation)构成。针对工业现场环境,设备被抽象为“设备族-设备类型-具体型号-物理实例”的四级层级结构。类定义参考GB/T 14885《固定资产分类与代码》及ISO 15926标准,实现语义标准化。属性层级分为静态属性(如额定功率、设计寿命、材质证明)与动态属性(如实时电流、振动频率、累计运行小时数)。通过定义isPartOf(组成部分)、connectedTo(物理连接)及monitoredBy(测点关联)等语义谓词,实现设备与工艺流程、传感器测点及维护规程的逻辑关联。
工业设备本体建模的逻辑架构如下图所示:
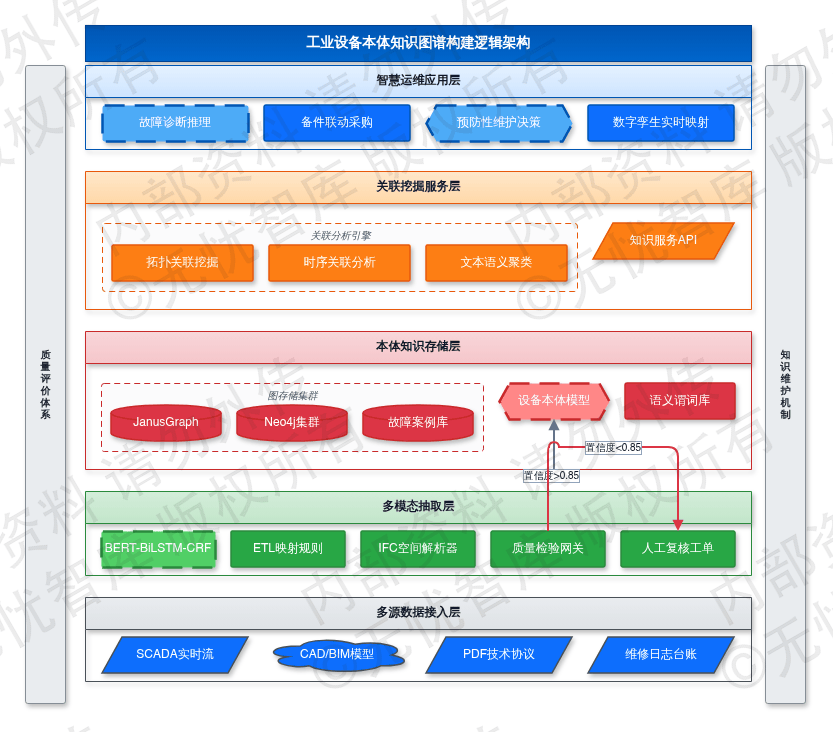
如上图所示,该架构描述了从底层物理设备实例到顶层语义本体的抽象路径。通过预设设备类、属性集及关联谓词,系统可自动识别设备间的拓扑关系与逻辑约束,为故障诊断推理与备件联动采购提供标准化的数据字典。该模型支持横向扩展,可随项目扩容无缝接入新型工控设备。
5.3.2 基于多模态数据的设备实体抽取
工业现场数据具备高度多模态特征,涵盖设计阶段的CAD/BIM图纸、采购阶段的PDF技术协议、施工验收记录及运行阶段的SCADA实时数据流。本方案采用深度学习与规则引擎相结合的混合抽取策略,从海量碎片化信息中提取设备实体及其关联属性。
针对非结构化文本(如设备说明书、维修日志),系统运行基于BERT-BiLSTM-CRF架构的命名实体识别(NER)模型,通过工业术语集微调,实现对设备型号、零部件名称、故障现象等实体的自动化标注。对于半结构化数据(如Excel台账或数据库表单),利用ETL工具配合预设映射规则(Mapping Rules),将字段直接映射至本体对应的属性槽位。在空间实体抽取方面,系统解析BIM模型中的IFC标准文件,提取设备的几何坐标与空间归属关系(如所属车间、楼层、轴网位置),确保虚拟模型与物理实体的空间一致性。抽取流程内置质量检验环节,置信度低于0.85的抽取结果自动触发人工复核工单,确保底层数据的准确性。
5.3.3 设备故障演化与关联关系挖掘
知识图谱通过挖掘设备运行参数与故障事件之间的时空关联,构建设备故障演化路径,支撑预防性维护决策。关联关系挖掘主要通过以下三条路径实现:
5.3.3.1 拓扑关联挖掘
利用设备本体中的连接关系,结合流体动力学或电力流向逻辑,分析单体设备故障对上下游系统的波及影响。当循环水泵触发停机告警时,图谱自动溯源至关联的换热器、冷却塔及控制阀门,评估全系统压降风险。
5.3.3.2 时序关联分析
通过对SCADA历史数据的相关性计算,识别特定工况组合(如高转速与高环境温度叠加)与故障发生频率的统计联系,将此类规律作为概率边沉淀至图谱中,实现基于工况的故障预警。
5.3.3.3 文本语义关联
利用自然语言处理技术对设备维修履历进行主题聚类,挖掘“故障现象-损坏原因-解决方案”的三元组关联,构建结构化故障案例库。
本方案选用的关键抽取与挖掘技术参数如下表所示:

5.3.4 工业本体图谱的质量评价与维护
为保障知识图谱在项目全生命周期内的有效性,需建立质量评价体系与动态更新机制。质量评价从准确性、完整性、一致性和及时性四个维度进行量化。依据GB/T 36473《知识图谱构建指南》,系统配置本体一致性检查规则,自动拦截属性冲突或循环定义。
维护机制采用知识生命周期管理流程。当设备发生大修、技改或报废更新时,变更信息通过API接口触发图谱局部更新。对于新接入的设备类型,系统支持本体结构的在线热演化,无需停机即可完成类别扩展。此外,引入专家反馈回路,现场工程师通过移动端巡检发现图谱信息与实物不符时,可提交纠偏建议,经审核后自动修正。这种基于机理模型、专家经验与实时数据的维护模式,确保了知识图谱与项目数字孪生实体的实时映射,完成数字化移交与智慧运维的数据准备。
5.4 数据质量稽核与全生命周期治理
数据质量稽核与全生命周期治理是确保数据资产准确性、一致性与合规性的核心手段。本系统通过构建自动化的稽核引擎与全链路治理流程,将质量控制逻辑由事后审计转向事前预防与事中监控,实现数据从产生到销毁的全过程受控。
5.4.1 数据质量稽核规则引擎设计
数据质量稽核引擎集成于数据集成、处理与服务全过程。系统参照 GB/T 36344-2018《信息技术 数据质量评价指标》标准,构建涵盖完整性、准确性、一致性、及时性、有效性和唯一性六大维度的规则库。该引擎采用动态加载设计,支持通过可视化界面配置 SQL 逻辑、正则表达式或预置函数库,无需修改底层 ETL 代码即可实现监测逻辑的实时生效。
稽核流程始于数据接入层的强校验闸口。ODS 层接收原始数据时,引擎自动触发技术元数据校验,针对字段长度、数据类型、空值约束执行首轮过滤。针对复杂业务场景,引擎支持多表关联稽核。在政务数据融合场景中,系统比对人口库与社保库的身份证号码一致性。若发现异常,系统自动打标并路由至异常数据暂存区(Staging Area),阻断其进入 DWD 层。这种阻断式设计确保了数据湖内资产的清洁度。
5.4.2 全生命周期数据治理流程
数据治理方案覆盖需求定义、采集、存储、加工、共享及销毁的全生命周期。治理路径以元数据管理为核心。在数据创建阶段,MDM(主数据管理)系统强制推行统一代码标准,为跨部门业务实体分配唯一全局标识符(UID)。在存储与加工阶段,系统实时监控存储水位与计算资源消耗,针对低频访问的冷数据自动执行归档策略,优化 HDFS 集群存储效率。
治理流程依托工单系统实现责任定位。稽核引擎检出异常数据后,系统根据元数据中定义的“数据负责人(Data Owner)”属性,自动生成整改工单并推送至对应业务部门。整改过程包含问题定位、数据修复、重新稽核与验收关闭四个环节。所有操作轨迹均记录于治理日志,作为数据资产成熟度评估的依据。对于超过保存期限或失去业务价值的数据,系统启动审批销毁流程,利用物理删除与覆盖技术确保数据不可恢复,满足合规性要求。
5.4.3 数据血缘追踪与影响分析
系统构建了基于知识图谱的动态血缘分析模型,以实现数据资产的可追溯性。该模型通过解析 Hive SQL 脚本、Spark 任务日志及 API 调度链路,自动抽取表级与字段级的血缘关系。在知识图谱中,每个数据集(Dataset)定义为节点,数据流转动作(如 Join、Filter、Union)定义为边,形成覆盖 ODS 至 ADS 的全路径拓扑图。
血缘追踪在运维场景中承担导航功能。当上游业务系统发生表结构变更(如字段扩容或类型修改)时,架构师利用血缘图谱执行下文影响分析,快速定位受波及的下游报表、算法模型与外部接口,提前制定迁移计划以规避系统性风险。当 ADS 层数据出现异常时,技术人员利用上游追溯分析功能,沿着血缘路径逐层回溯,精确定位故障点属于源头采集缺失或中间层逻辑错误。该机制将故障排查时间(MTTR)缩短 60% 以上。
5.4.4 数据质量评价与监控看板
数据治理成效通过量化指标衡量。系统建立了多维度质量评价体系,定期生成《数据资产质量体检报告》。评价指标包括数据合格率、规则覆盖率、平均修复周期及资产利用率。系统通过加权计算为医疗、交通、金融等主题库生成质量信用评分,作为数据资源开放共享的优先级依据。
数据质量监控与治理的架构如下图所示:
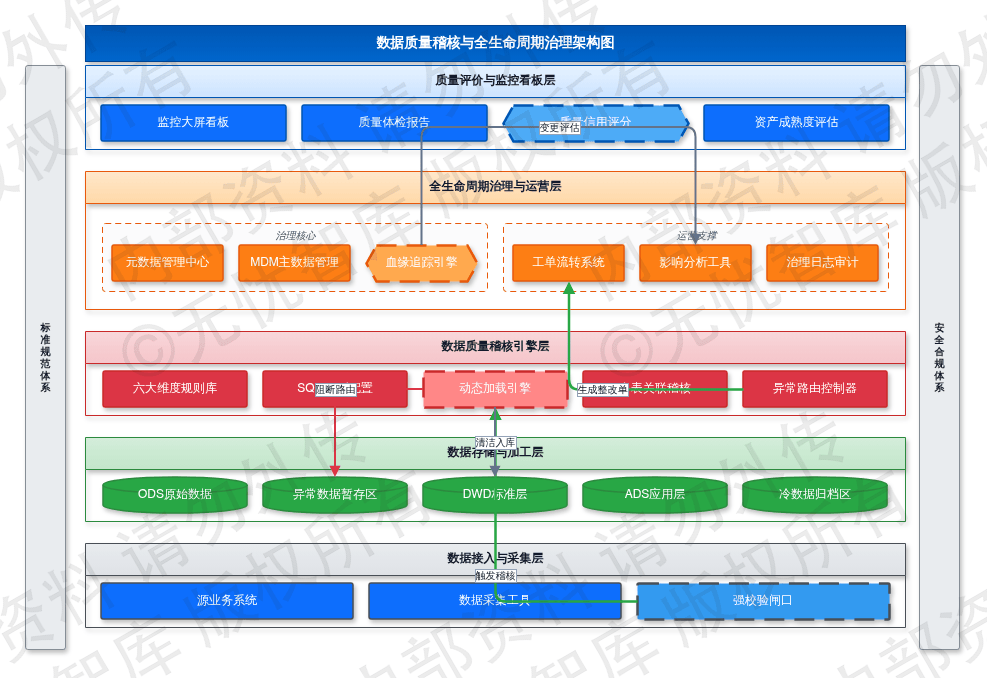
如上图所示,该架构展示了从底层数据源接入、中层稽核规则引擎处理到顶层质量看板呈现的管控流程。图中详细标注了稽核触发点、工单流转路径以及血缘分析节点,体现了治理动作与数据流转的深度耦合,为数据资产保值增值提供技术支撑。
为明确治理标准,下表列出了核心稽核参数与监控阈值设置:

第6章 基础设施与信创适配方案
本章聚焦于基础设施的标准化建设与信创全栈适配路径。在保障供应链安全与技术自主可控的背景下,基础设施设计避开单一硬件堆叠的传统模式,转向以软件定义数据中心(SDDC)为核心的弹性架构实践。通过对底层算力、存储及网络资源的池化管理,构建一套能够屏蔽硬件异构差异的逻辑层,确保业务系统在国产化演进过程中实现平滑迁移与性能对标,为全省范围内的业务协同提供高可用的物理与逻辑承载。
在算力资源规划方面,重点针对鲲鹏、飞腾、海光等国产CPU架构实施异构并行计算优化。针对信创芯片在单核性能与多核调度机制上的技术特性,通过调整操作系统内核参数、优化编译器指令集映射以及部署高性能容器引擎,解决异构算力环境下的负载均衡与资源隔离问题。同时,引入基于KylinOS或EulerOS的标准化镜像体系,确保底层运行环境与上层中间件、数据库的深度耦合,通过内核级的性能调优降低虚拟化损耗,提升单位算力的产出效率。
存储架构设计采用分布式存储集群,利用多副本机制与纠删码技术保障数据的高可靠性与强一致性。针对信创环境下的IO路径损耗,实施基于NVMe协议的存储栈优化,并利用RDMA网络技术降低跨节点数据同步的时延。网络层面则依托软件定义网络(SDN)实现业务流与管理流的物理隔离与逻辑加密,通过国产防火墙与负载均衡设备的集群化部署,构建多层级的安全防护屏障,确保网络拓扑在满足等保三级要求的同时,具备应对突发流量的线性扩展能力。
信创适配方案不仅涵盖硬件替换,更侧重于全栈软件栈的兼容性验证与性能提纯。本章明确了数据库从传统商用库向国产分布式数据库迁移的逻辑映射规则,以及中间件在国产操作系统上的并发处理能力基准。通过建立一套包含功能兼容性、压力承载力及故障自愈时延在内的量化评估体系,确保系统在全信创环境下依然能够维持万级QPS的并发响应能力,并实现RTO与RPO的工程化达标,彻底解决国产化替代过程中的性能瓶颈与运维碎片化问题。
6.1 混合云底座与边缘计算节点规划
本章节阐述系统基础设施的总体布局与技术实现路径。通过构建“中心云+边缘云”的分布式架构,系统实现了算力资源的全局动态调度与边缘侧的实时响应能力。规划方案深度整合了私有云的安全性与公有云的弹性特征,并结合边缘计算节点解决生产现场的低时延处理需求。本节将详细定义混合云资源池化方案、边云协同的逻辑架构以及底层硬件的性能准入指标,为上层业务应用的高效运行提供标准化的基础设施环境。
6.1.1 混合云架构设计与资源池化方案
混合云底座采用分布式架构,基于 TOGAF ADM 方法论在基础设施层实现异构资源调度。中心云部署于总部数据中心,利用 KVM 虚拟化技术承载核心数据库、大数据分析引擎及全局管理系统。公有云作为弹性扩展层,通过 Direct Connect 专线与私有云互联,利用 VPC 终端节点实现跨云私有访问,主要承担互联网侧高并发接入与流量削峰。资源池化方案依托软件定义数据中心(SDDC)技术,将计算、存储、网络资源封装为逻辑统一池。计算资源池支持 X86 与信创 ARM 架构双栈部署,通过亲和性策略实现业务负载的精准投放。存储资源池采用分布式架构,支持块、文件、对象协议,单节点 IOPS 性能基线 ≥ 50,000,确保高频交易响应时延控制在 2ms 以内。
多云管理平台(CMP)实现对异构云环境的统一纳管,通过适配 API 提供资源申请、审批、配额及计量功能。网络层面采用 Overlay 技术构建跨云二层扁平化网络,支持虚拟机与容器在不同环境间的无缝迁移。中心云配置 N+1 冗余机制,结合存储层 3 副本及异步复制技术,达成 RPO < 5 分钟、RTO < 30 分钟的灾备指标。
6.1.2 边缘计算节点部署与边云协同机制
针对生产、仓储及终端分布场景,规划部署多层级边缘计算节点,满足 <10ms 低时延与数据本地化需求。边缘节点分为厂区级网关与车间级服务器。厂区级网关采用工业级嵌入式架构,负责 Modbus、OPC-UA、MQTT 协议接入与解析;车间级服务器部署轻量化 K3s 集群,支撑视觉质检与实时控制等高算力业务,单节点支持 50 路高清视频流实时推理。
边云协同机制涵盖资源、数据、应用三个维度。资源协同由中心云根据边缘负载动态调度容器实例;数据协同执行“边缘预处理+中心长效存储”模式,边缘端仅上报清洗后的特征数据,减少 70% 主干网带宽占用;应用协同基于 DevOps 流水线,在中心云完成模型训练与镜像打包,通过 Edge Registry 分发至边缘。节点具备 72 小时离线自治能力,在断网环境下维持业务运行,网络恢复后自动同步状态数据。
混合云与边缘计算的协同部署架构如下图所示:
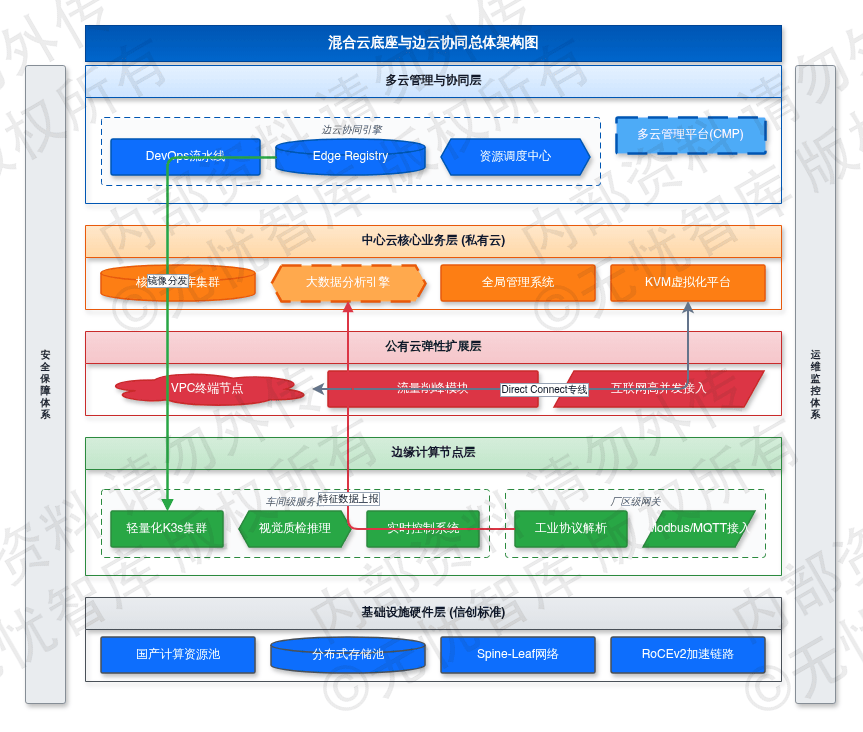
如上图所示,该架构涵盖中心云战略决策、模型训练与边缘节点实时执行、数据采集的完整流程。中心云管理平台统一管控边缘节点。系统按需分配算力资源并下发业务逻辑,维持复杂环境下的运行稳定性。
6.1.3 基础设施硬件规格与性能指标要求
基础设施硬件选型执行信创适配标准,优先采用国产高性能处理器与固态硬盘。中心机房 PUE 控制在 1.3 以下。网络架构采用 Spine-Leaf 拓扑,核心交换机背板带宽 ≥ 51.2Tbps,支持 RoCEv2 协议以加速分布式存储流量。服务器 BIOS 与 BMC 固件要求 100% 自研,并取得信创兼容性互认证。

通过标准化硬件规划,确保底层设施满足核心业务的高并发访问需求与信创合规性要求。
6.2 算力资源池(GPU/NPU)规划与调度
6.2.1 异构算力资源池总体架构
智算中心基础设施建设需改变传统烟囱式硬件部署模式,构建面向大模型训练与推理任务的异构算力资源池。该架构设计的核心逻辑在于硬件标准化与资源池化,通过在底层物理硬件与 AI 框架之间引入算力抽象层,实现对 NVIDIA GPU 与华为昇腾、寒武纪等国产高性能 NPU 的统一管理。架构在纵向上划分为物理设施层、算力抽象层、算力调度层及服务接口层。物理设施层通过 RoCE v2 网络或 InfiniBand 交换机实现计算节点间的高速互联,配置无损网络协议以确保分布式训练时的参数同步带宽不低于 200Gbps。
算力抽象层利用算力虚拟化与切分技术,将物理显存与计算单元转化为可动态分配的逻辑资源块。这一设计解决了算力碎片化问题,通过对不同架构芯片的驱动封装,向上层业务屏蔽底层硬件的指令集差异,为大规模深度学习任务提供弹性的底层支撑。系统通过统一的资源描述协议,将异构芯片的算力规格、显存容量、互联带宽等参数进行标准化建模,形成全局资源视图。
异构算力资源池总体架构如下图所示:
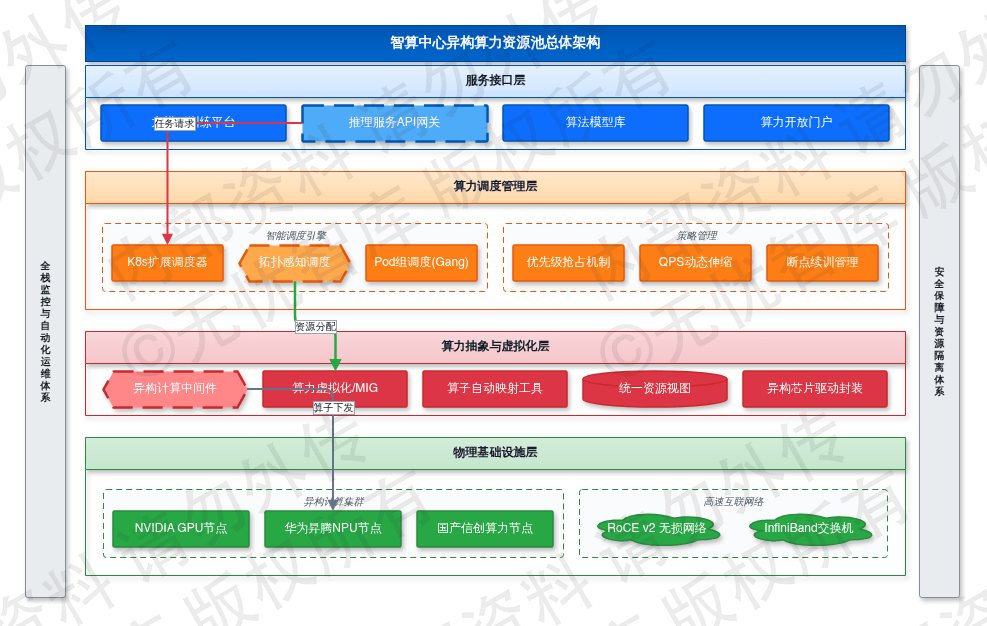
如上图所示,该架构通过解耦计算资源与上层应用,实现了 GPU 与 NPU 的并存管理。底层物理层通过高密度服务器集群提供原始算力,中间调度层负责任务拓扑感知与资源匹配,顶层服务层通过标准 API 对接训练平台,确保了系统在面对不同算法需求时的灵活性与高可用性。
6.2.2 智算资源选型与信创适配
在信创产业全面提速的背景下,算力选型必须兼顾性能基准与国产化率双重指标。针对大规模预训练场景,选型侧重于 HBM3 显存带宽与高速互联能力;针对边缘推理场景,则侧重于能效比与低时延响应。目前,信创适配工作重点在于解决国产 NPU 对 PyTorch、TensorFlow 等深度学习框架的算子兼容性问题。通过引入异构计算中间件,将 CUDA 算子转化为国产芯片原生算子,转化损耗需控制在 15% 以内。在硬件层面,方案优先采用具备 HCCS 或 NVLink 同等性能指标的国产互联技术,以满足千亿级参数模型的全量微调需求。
以下针对主流算力资源进行技术规格与适配性对比分析:

6.2.3 算力调度与虚拟化切分策略
针对 AI 任务对算力需求的多样性,系统采用基于 Kubernetes (K8s) 扩展的算力调度器,实现对 GPU/NPU 资源的任务级精细化分配。对于模型开发与调试阶段的轻量化需求,启用 MIG(Multi-Instance GPU)或国产 NPU 的静态切分技术,将单颗芯片划分为多个独立的计算实例,每个实例拥有独立的显存隔离与流处理器资源,防止任务间的相互干扰。在调度算法上,引入拓扑感知调度机制,调度器优先将具有频繁通信需求的训练作业部署在同一交换机下的物理节点内,以降低跨扇区通信带来的网络延迟。
针对大规模训练任务,系统支持 Pod 组调度(Gang Scheduling),确保任务所需的全部算子资源同时就位后再启动执行,避免因部分资源占用导致的死锁现象。针对推理任务,则采用基于 QPS 负载的动态伸缩策略,当显存占用率超过 75% 阈值时,自动触发副本扩容,确保 SLA 响应时延稳定在 200ms 以内。此外,调度器支持优先级抢占机制,在资源紧张时优先保障高优先级训练任务的算力供应,并对低优先级任务执行 Checkpoint 挂起操作,待资源释放后自动恢复。
6.2.4 资源监控与自动化运维
算力资源池的稳定性直接影响业务连续性,必须构建覆盖硬件状态、内核驱动、框架性能的全栈监控体系。监控系统通过 Exporter 定期采集 GPU/NPU 的核心频率、显存利用率、SM 占用率及工作温度等关键参数,采样频率设定为 5 秒/次。当检测到硬件 ECC 错误或温度超过 85℃ 的预警线时,运维平台自动触发故障隔离流程,将受损节点标记为不可调度状态,并利用热迁移技术将存量任务平滑转移至备用节点。
系统集成自动化性能分析工具,能够自动识别训练过程中的 IO 瓶颈与算子执行效率低下问题,并生成优化建议报告。针对大规模集群的固件升级与驱动更新,采用灰度发布模式,通过分批次重启与健康度自检,确保在不中断全局算力供应的前提下完成系统演进。运维平台需建立完善的日志审计与告警关联规则,通过对 XID 错误码、内核崩溃日志的深度学习分析,实现从被动报修向主动预防性维护的转型,确保集群年均可用性达到 99.9% 以上。针对长周期训练任务,系统提供自动断点续训功能,在硬件故障触发后 10 分钟内完成任务重调度与状态恢复。
6.3 全栈信创适配目标与技术路线
6.3.1 信创适配总体目标与关键指标
本项目全栈信创适配旨在构建基于国产芯片、操作系统、数据库及中间件的自主受控IT架构。适配工作以业务连续性为核心,设定关键组件100%国产化替代基准。在极端外部断供场景下,系统需维持99.99%以上的可用性。针对核心高频交易业务,信创环境下的系统响应延时波动需控制在15%以内,单节点吞吐量(TPS)衰减率严格限制在10%以下,确保用户体验不因底层架构迁移而下降。
量化指标覆盖计算、存储、网络及安全四个维度。计算层要求全面兼容鲲鹏、飞腾等主流ARM架构处理器,在SPECint等基准测试中,主频利用率需达到同代X86产品的85%以上。针对NUMA架构特征,系统需完成内存访问延迟优化,确保跨节点访存开销最小化。数据持久化层要求国产数据库支持5000个以上并发连接,并保持毫秒级查询响应。安全维度则强制要求在链路层、网络层及应用层深度集成SM2、SM3、SM4国产密码算法,通过硬件加速卡提升加解密效率,确保基础设施符合等级保护三级(等保2.0)及关键信息基础设施保护要求。
6.3.2 软硬件全栈信创适配路线图
技术路线遵循“分层演进、灰度切换”原则,逐步实现从X86架构向全信创节点的平滑迁移。底层基础设施优先部署基于ARM架构的信创服务器集群。操作系统选用欧拉(openEuler)或麒麟(KylinOS)企业级版本,通过调整内核调度算法与脏页回写机制,解决国产CPU在多核并发下的缓存一致性瓶颈。针对容器化场景,利用eBPF技术实现内核级监控,降低容器网络插件(CNI)在信创环境下的封包损耗。
中间件与数据库层采用经过信创加固的国产分布式方案。应用服务器中间件选用东方通或金蝶天燕,重点优化JVM内存模型与垃圾回收策略,以适配国产CPU的指令集特征。数据库层部署国产分布式数据库(如OceanBase或GaussDB),利用多副本Paxos协议确保数据强一致性,实现RPO=0、RTO<30s的金融级高可用指标。在微服务治理方面,通过国产容器云平台实现无状态节点的动态扩缩容,并针对信创内核优化CRI运行时接口,提升Pod启动速度与资源调度精度。
全栈信创适配的技术架构逻辑如下图所示:
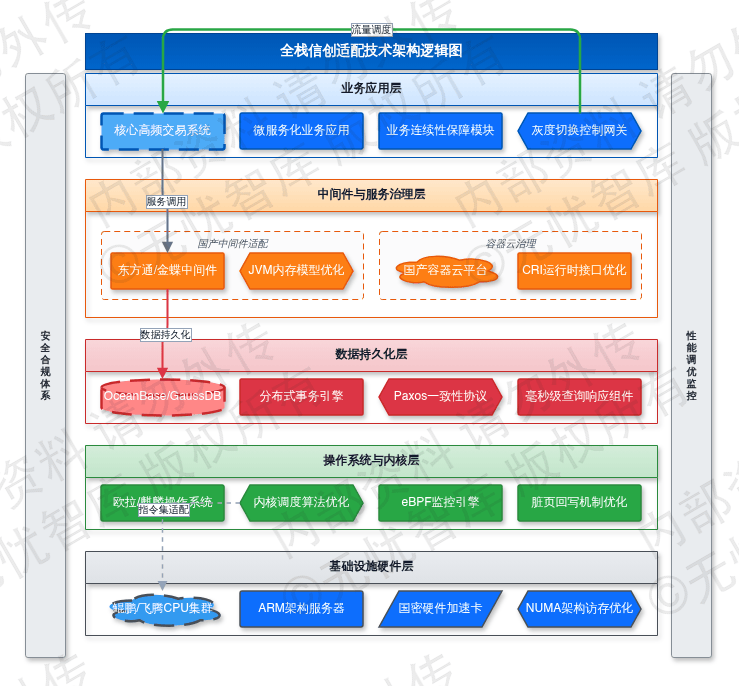
如下图所示,该架构涵盖了从底层国产硬件到顶层业务应用的全链路适配路径,明确了硬件层、系统层、数据层与中间件层的解耦逻辑,为大规模业务迁移提供了标准化的技术指南。
6.3.3 兼容性测试与性能调优策略
信创适配过程实施标准化的兼容性测试标准(CTS),涵盖指令集兼容、驱动匹配、高负载压力测试等8个大项、42个小项。测试环境需精确模拟生产环境的流量特征,利用自动化压测工具对国产操作系统的文件系统I/O、网络协议栈吞吐量进行深度探测。针对发现的性能瓶颈,技术团队从编译器优化(如启用LTO、PGO优化选项)、内核参数微调以及应用代码重构三个层面开展调优工作。
性能调优重点关注集群协同效率与硬件潜能释放。在分布式场景下,通过优化国产网卡驱动与RDMA协议,降低节点间数据拷贝的CPU占用率。针对国产数据库,实施SQL执行计划的二次优化,利用分区表索引与向量化执行引擎补偿复杂关联查询的计算短板。此外,建立常态化的信创性能监控基线,通过Prometheus采集国产硬件特有的PMU计数器指标,实时感知硬件运行状态。针对高并发场景下的上下文切换损耗,通过调整进程调度优先级与中断亲和性,确保信创环境下的业务执行效率达到设计预期。

第7章 全栈安全与等保合规体系
全栈安全与等保合规体系的设计遵循国家网络安全等级保护2.0(等保三级)标准及商用密码应用安全性评估(密评)的技术规范,构建一套覆盖基础设施、通信网络、区域边界、计算环境及数据支撑的深度防御矩阵。在云原生架构演进背景下,传统基于物理边界的防护模型已难以应对微服务架构带来的攻击面扩张,因此本体系核心转向以身份为中心的零信任(Zero Trust)架构,通过软件定义边界(SDP)与微隔离技术,实现对东西向流量的精细化访问控制与持续信任评估。
在物理与环境安全层面,重点落实机房访问控制、防雷接地及电力冗余等基础合规要求,确保底层硬件设施的物理连续性。网络安全维度则通过划分生产域、测试域、管理域及DMZ区,部署下一代防火墙(NGFW)、入侵防御系统(IPS)及Web应用防火墙(WAF),构建多层级流量过滤机制,并利用国密算法(SM2/SM3/SM4)对关键链路进行加密传输,满足密评对通信完整性与保密性的强制要求。
计算环境加固聚焦于主机与容器安全,通过实施最小化镜像策略、内核级安全审计及漏洞扫描,消除系统层面的潜在风险点。针对应用层安全,本体系将安全能力左移,整合DevSecOps自动化安全流水线,在代码构建阶段引入静态应用安全测试(SAST)与软件成分分析(SCA),确保业务逻辑与第三方组件的安全性。同时,建立统一的身份认证与权限管理(IAM)平台,执行多因素认证(MFA)与基于角色的访问控制(RBAC),防止越权访问与凭据泄露。
数据安全作为合规体系的核心,覆盖从采集、存储、传输到处理、交换及销毁的全生命周期。通过部署数据库审计、数据脱敏及透明加密技术,确保敏感信息在静态存储与动态流转过程中的主权受控。此外,构建主动可观测的安全运营中心(SOC),集成日志审计、态势感知与自动化响应(SOAR)能力,实现对安全事件的分钟级发现与自动化处置。通过上述技术约束与工程实践的深度融合,系统不仅在形式上满足等保三级的合规准入,更在实质上具备抵御高级持续性威胁(APT)与保障业务连续运行的内生韧性。
7.1 网络安全等级保护(三级)设计
7.1.1 等级保护定级与合规目标
依据《信息安全技术 网络安全等级保护基本要求》(GB/T 22239-2019)及相关定级指南,本项目业务系统承载大量公民个人敏感信息与关键政务数据,安全保护等级确定为第三级(S3A3)。合规设计聚焦于身份鉴别、访问控制、安全审计、入侵防范及数据加密五大核心维度,构建纵深防御体系。设计方案覆盖物理环境、通信网络、区域边界、计算环境及管理中心,重点解决云原生架构下的应用安全与数据内生合规问题。系统需具备抵御高强度网络攻击的韧性,确保在极端安全事件下具备快速恢复能力,满足测评机构年度合规性审计要求,保障政务业务的连续性与数据完整性。
7.1.2 纵深防御网络安全架构
系统网络架构执行“安全分区、网络专用、横向隔离、纵向防护”策略,划分为互联网接入区、DMZ隔离区、应用服务区、核心数据区及运维管理区。互联网出口配置高性能下一代防火墙(NGFW)与抗DDoS设备,执行L3-L7层流量清洗。区域边界部署入侵防御系统(IPS)与Web应用防火墙(WAF),拦截SQL注入、跨站脚本(XSS)等应用层攻击。内部微服务交互引入零信任网络访问(ZTNA)机制,利用微隔离技术监控东西向流量,限制攻击者的横向移动路径。关键链路采用冗余拓扑,消除单点故障风险,在逻辑与物理层面同步强化防御边界。
系统整体网络安全防御拓扑如下图所示:
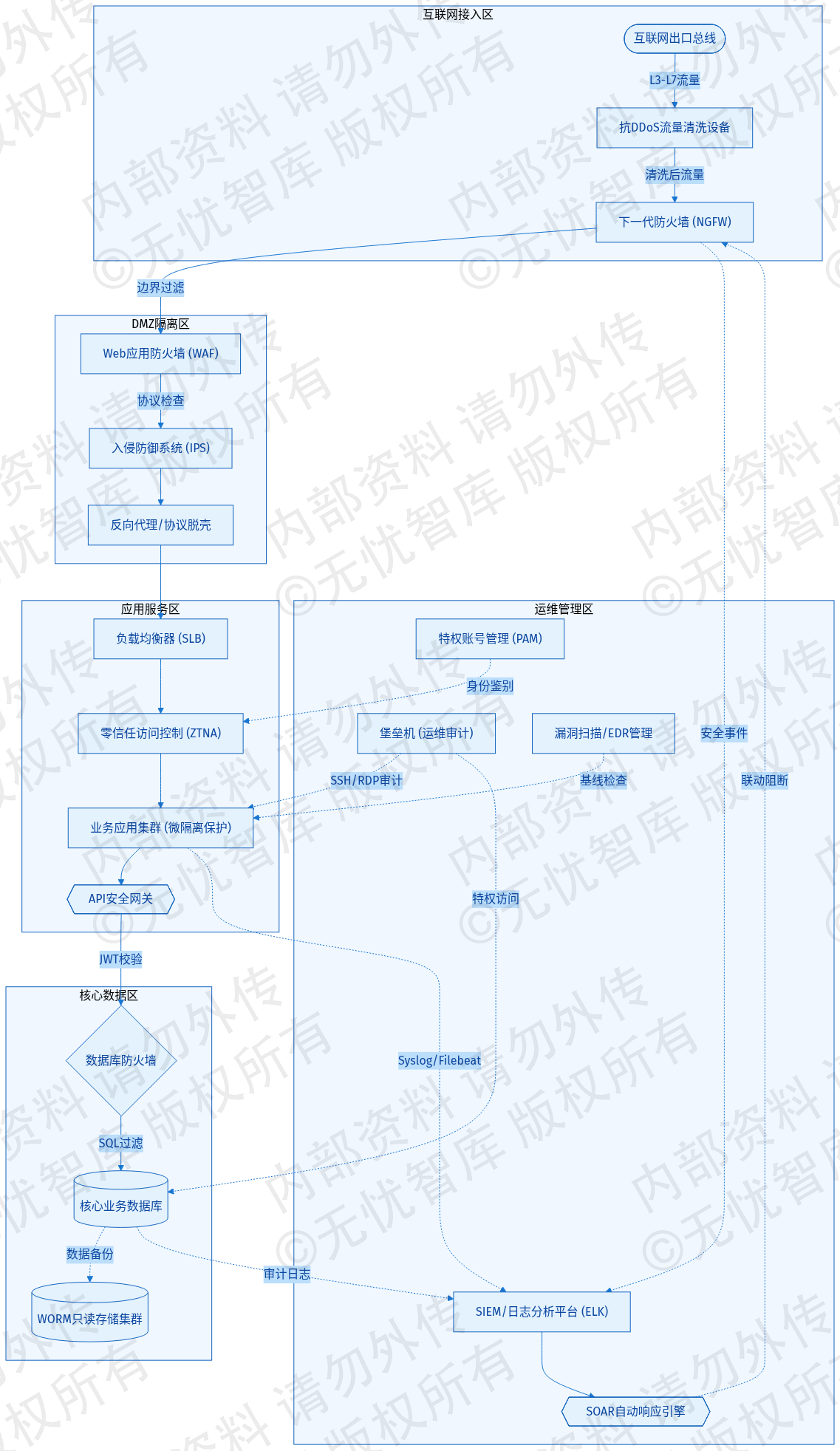
如上图所示,该架构通过多层级安全组件实现了从外部边界到核心数据的全路径防护。互联网流量经清洗中心与边界防火墙过滤,在WAF层完成协议脱壳与合规性检查,随后由负载均衡器分发至受微隔离策略保护的应用集群。最终,业务请求通过加密隧道访问核心数据库,确保流量在各层级均处于严格监控与策略约束之下。
7.1.3 身份鉴别与访问控制机制
身份鉴别体系基于双因子认证(2FA)构建统一身份认证平台。管理人员访问生产环境须采用“口令+手机动态令牌”或“口令+硬件UKey”组合,强制废除弱口令与单一认证模式。访问控制层面实施基于角色(RBAC)与基于属性(ABAC)的细粒度授权模型,严格执行“最小特权”原则。应用接口调用由API网关进行JWT令牌校验与黑白名单二次过滤。针对数据库等核心资源,部署数据库防火墙与特权账号管理系统(PAM),对敏感操作实施实时阻断与录屏审计。该机制确保所有访问行为具备可追溯性与可审计性,从源头降低越权访问与内部泄密风险。
7.1.4 全栈安全审计与可观测性体系
安全审计模块覆盖网络、主机、应用、数据库及安全设备,建立统一日志采集与分析平台。利用Syslog、SNMP及Filebeat组件全量采集系统日志、操作日志与安全事件,并同步至具备WORM(只读)特性的存储集群,确保存储时长达到180天。结合ELK堆栈与SIEM(安全信息和事件管理)系统,利用流式计算引擎进行实时关联分析,识别异常登录、暴力破解等威胁。全栈可观测性体系将异常请求占比、拦截成功率等安全指标集成至可视化看板。一旦触发预设阈值,系统通过多渠道推送告警,并配合自动编排脚本(SOAR)实现威胁的秒级响应,优化平均检测时间(MTTD)与平均响应时间(MTTR)。
7.1.5 安全设备与合规组件清单
为落实等保三级技术要求,系统集成以下核心安全组件,具体配置见下表:

7.2 零信任身份认证与动态权限管控
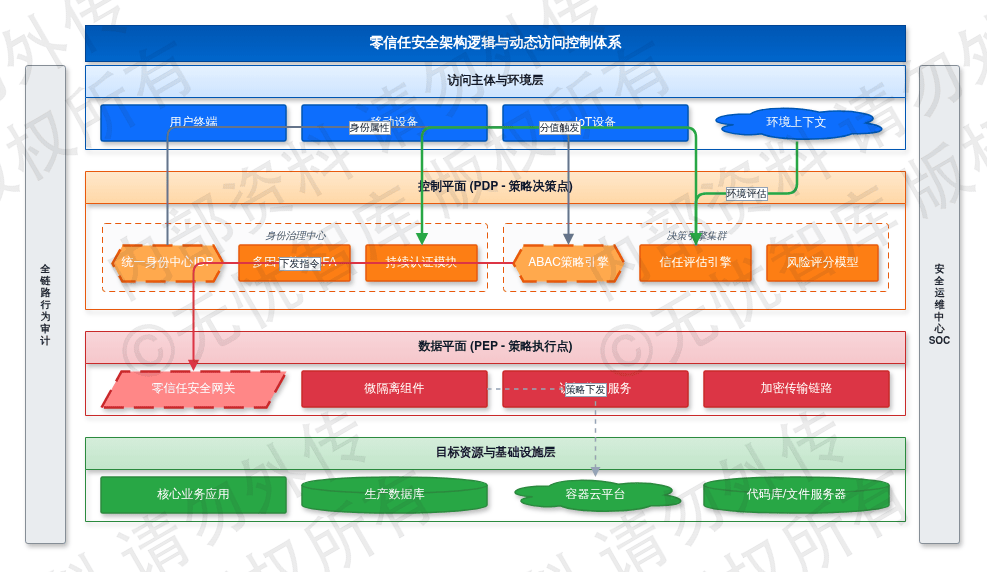
7.2.1 零信任架构逻辑与访问控制模型
零信任架构将安全防护重心从网络边缘转移至身份实体,确立“永不信任,始终验证”的防御基准。该架构通过逻辑隔离手段,将访问控制权限由物理网络位置转向实时计算的身份属性与风险评分。系统默认拒绝所有连接请求,仅在完成多因子身份核验、设备基线合规性扫描及上下文环境评估后,授予最小化访问权限。
架构设计实现控制平面与数据平面的物理分离。所有访问流量在触达目标资源前,必须经过策略决策点(PDP)的判定,并由策略执行点(PEP)执行拦截或放行指令。此机制确保攻击者即使渗透进入内网,也无法在缺乏动态授权的情况下进行横向移动。同时,系统对所有通信链路实施端到端加密,利用微隔离技术将安全边界收缩至资源节点级别,保障数据传输的机密性与完整性。
7.2.2 统一身份认证中心(IDP)与多因子核验
统一身份认证中心(IDP)作为全域身份治理的权威源,整合人事系统、第三方IAM及社交认证协议,构建统一身份基准库。针对业务敏感度差异,系统实施分级认证策略:基础办公场景采用标准凭证,核心生产、财务指令及运维操作场景强制触发多因子核验(MFA)。MFA集成FIDO2协议生物识别、硬件令牌及动态挑战响应机制,消除单一密码泄露带来的冒用风险。
IDP引入持续认证技术,改变传统登录即长效的会话机制。系统实时监测客户端设备指纹、IP偏移量及安全补丁状态,一旦识别到访问行为偏离预设基线,立即吊销OAuth2.0令牌或JWT凭证,强制发起二次核验。这种细粒度的认证逻辑确保了身份可信度在整个访问生命周期内处于受控状态。
零信任身份认证业务流转逻辑如下图所示:
7.2.3 基于ABAC的动态权限策略与微隔离
系统采用基于属性的访问控制(ABAC)模型取代静态角色控制(RBAC),通过定义主体属性(岗位、职级)、资源属性(数据密级)、环境属性(地理位置、时间段)及操作属性(读、写、删)构建逻辑表达式。策略引擎根据实时上下文计算授权结果,例如限制特定职级人员仅能在办公网段及工作时间内访问高密级代码库,提升了权限配置的精确度。
微隔离技术作为ABAC策略在网络层的具象化落地,依托容器云平台或虚拟化层的分布式防火墙插件,将安全策略下发至微服务实例。即使服务部署于同一物理宿主机,若无明确ABAC策略准许,其网络通信将被完全阻断。这种方式将安全边界从机房级压缩至负载级,有效收敛了攻击面。下表列出典型场景下的权限管控配置:

7.2.4 持续信任评估与行为审计
信任评估引擎实时采集终端安全软件(EDR)、网络流量分析(NTA)及应用日志的行为特征,利用加权算法对活跃连接进行动态评分。当识别到异常API调用频率或异地深夜登录等高风险行为时,系统自动下调信任分值。一旦分值低于预设阈值,系统即刻触发降级指令,限制敏感资源访问权限或阻断网络连接,并同步向安全运维中心(SOC)推送告警。
全链路行为审计体系覆盖身份认证、策略下发及资源访问全过程。所有操作记录存储于不可篡改的日志系统中,包含精确时间戳、原始请求报文及策略匹配结果。通过引入用户实体行为分析(UEBA)技术,审计系统能够自动识别异常数据脱离或账号劫持风险,形成事前预防、事中阻断、事后追溯的安全闭环,确保复杂环境下业务访问的合规性。
7.3 国密算法应用与数据防泄漏(DLP)
7.3.1 国密算法在全生命周期中的合规应用
系统执行《中华人民共和国密码法》及 GB/T 39786-2021《信息安全技术 信息系统密码应用基本要求》,在三级等保框架下部署国产密码算法(SM系列),配置覆盖终端、传输通道与云端存储的加密方案。数据采集阶段,针对传感器及移动终端上报的原始报文,系统调用集成在可信执行环境(TEE)中的 SM4 对称加密模块。该模块对敏感字段执行实时流式加密,在数据进入不可信网络前完成脱敏。传输过程中,系统基于国密 SSL VPN 或国密 TLS 协议,利用 SM2 与 SM3 算法建立加密隧道,执行双向身份认证与报文完整性校验,拦截中间人攻击(MITM)。
数据存储环节根据数据类型采取差异化策略。关系型数据库(如 openGauss)中的身份证号、手机号等敏感列启用透明数据加密(TDE)技术。该技术结合硬件加密卡提供的 SM4 算法进行物理层加密,密钥由外部独立硬件安全模块(HSM)统一管理,实现密文存储与脱敏查询。针对影像资料、离线文件等非结构化数据,系统利用 SM3 算法计算文件摘要,该摘要作为数据指纹用于校验文件完整性。数据交换环节,系统应用 SM2 数字签名技术对下发指令或上报结果进行加签,确保业务操作具备可追溯性。通过部署国密二级/三级密码服务平台,系统完成密钥生成、存储、分发、更新及销毁的生命周期管理,达到等保 2.0 密码应用合规标准。
7.3.2 数据防泄漏(DLP)多维管控机制
为管控数据流转风险,系统部署涵盖终端、网络、邮件及存储的 DLP 体系。该体系以内容识别技术为核心,利用正则表达式、关键词权重、文档指纹(IDM)及结构化数据指纹(EDM)对敏感数据执行自动分类分级监测。办公终端侧,DLP 代理客户端实时监控 USB 存储拷贝、即时通讯工具(IM)发送及打印输出行为。DLP 引擎匹配敏感策略后,触发阻断指令并记录审计日志,同时向管理后台推送高危告警。针对离线办公场景,系统强制执行文档透明加密(File Encryption),确保脱离受控环境的文件处于密文状态,无法被非授权读取。
网络出口侧,DLP 网关利用深度包检测(DPI)技术解析 HTTP/HTTPS、FTP、SMTP 等协议流量。针对加密流量,系统配置 SSL 卸载技术进行明文审计,拦截利用加密通道进行的非法拖库行为。此外,方案引入基于 AI 的行为分析模型(UEBA),通过建立用户数据访问基线,识别异常的大批量下载或频繁跨域访问,防范内部人员利用合法权限进行的蚕食式泄露。数据分发场景下,系统强制叠加动态水印与隐形盲水印,在屏幕显示及导出的 PDF/Excel 文档中嵌入包含访问者工号、时间戳、IP 地址的追溯信息。若发生拍照泄露,安全团队可通过水印溯源技术定位泄露源头,完成泄露溯源与处置流程。
国密算法与 DLP 防泄漏系统的协同架构如下图所示:
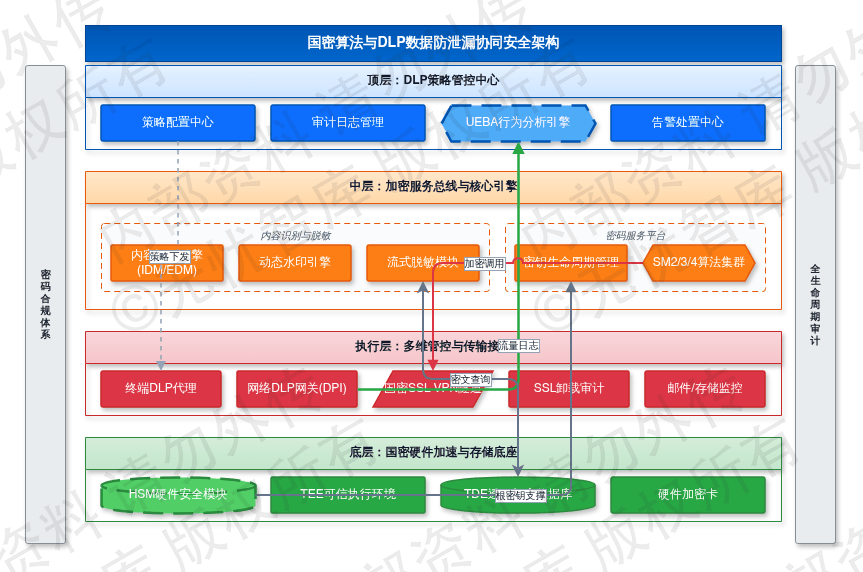
如上图所示,该架构整合底层国密硬件加速层、中间加密服务总线及顶层 DLP 策略管控中心。国密算法保障数据在静态存储与动态传输中的机密性,DLP 体系约束业务流转环节的操作行为,二者协同满足数据安全合规要求。下表列出了本节涉及的关键安全参数与算法选型:

7.4 大模型与智能体专属安全防护
7.4.1 提示词注入与输出内容治理
针对提示词注入(Prompt Injection)威胁,系统在接入层构建双向语义校验网关。前置阶段采用轻量化Transformer模型对输入流进行实时分词与向量化,通过计算输入向量与已知恶意指令集(如Jailbreak、Role-play攻击模板)的余弦相似度,实现高风险请求的毫秒级拦截。针对间接注入风险,网关强制执行上下文窗口隔离,对外部抓取的网页数据进行HTML标签剥离与不可见字符清洗,防止恶意指令通过第三方内容渗透。输出治理环节,系统集成多模态内容审核引擎,利用深度学习分类器对模型生成的Token流进行实时扫描,匹配敏感词库与合规策略集,确保响应内容符合《生成式人工智能服务管理暂行办法》及等保三级要求。对于疑似违规输出,系统自动触发截断机制并返回预设的合规话术,同时将原始交互记录加密存入审计日志,支持基于时间戳与用户ID的快速溯源。
7.4.2 智能体(Agent)执行权限与API隔离
智能体(Agent)安全防护聚焦于“思维链”决策到“API动作”执行的权限闭环。系统基于零信任架构部署安全代理(Security Proxy),所有智能体发出的外部工具调用请求必须经过代理层的协议解析与参数校验。代理层采用严格的JSON Schema定义工具调用规范,对API参数进行类型检查、长度限制及正则表达式匹配,防止通过注入非法字符实现参数污染或远程代码执行(RCE)。在权限控制维度,系统实施基于属性的访问控制(ABAC),结合智能体身份标签、任务上下文及目标资源敏感度进行动态授权。针对涉及核心数据库修改、大额资金划拨或生产环境配置变更等高风险操作,系统强制引入“人在回路”(Human-in-the-Loop)审批机制,通过异步回调接口挂起执行流,待人工确认后方可释放执行令牌。此外,系统为每个智能体实例分配独立的逻辑沙箱,限制其网络访问范围,确保自主决策过程不脱离预设的安全边界。
7.4.3 知识库(RAG)数据隐私与合规保护
检索增强生成(RAG)架构下的数据安全侧重于知识切片(Chunking)与检索阶段的隐私保护。在数据入库前,系统调用NLP命名实体识别(NER)引擎,对非结构化文档中的个人身份信息(PII,如身份证号、联系方式)及企业敏感字段进行自动化掩码或泛化处理。向量数据库层面,实施多租户逻辑隔离,并为每个知识分片挂载访问控制列表(ACL),确保检索结果仅包含用户当前权限等级可触达的文档片段。为应对提示词探测(Prompt Probing)攻击,系统在检索算法中集成差分隐私(Differential Privacy)机制,通过在向量检索结果中引入受控噪声,防止攻击者通过连续查询反推底层知识库的敏感分布。应用层同步部署了基于滑动窗口的速率限制器,对异常高频的检索行为进行实时熔断,并结合用户行为画像分析识别潜在的数据爬取企图。所有检索与生成行为均由审计模块记录,确保数据流转全过程可审计、可追溯。
综上所述,大模型与智能体安全防护架构如下图所示:
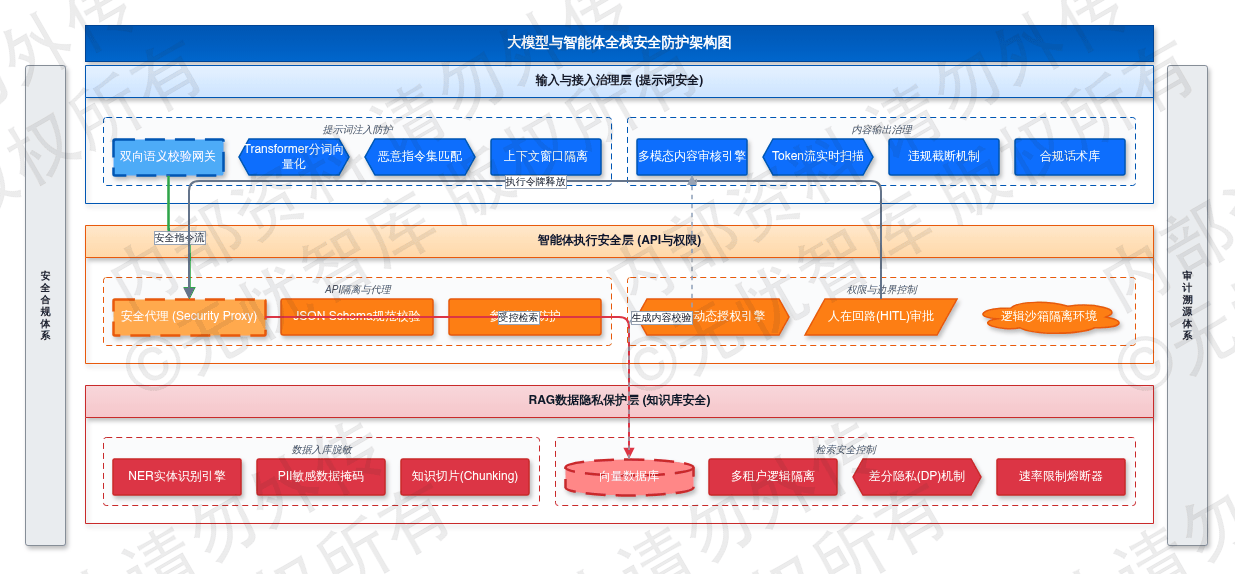
如上图所示,该架构构建了从输入层到执行层再到数据层的三层防御纵深。输入层聚焦于提示词风险识别与清洗,执行层侧重于智能体API调用的权限隔离与动态拦截,数据层则通过RAG隐私保护技术确保私有知识库的安全性。这种全栈式的防护机制,能够有效应对大模型应用在复杂生产环境中的特有安全挑战,确保业务智能化的稳健运行。
第8章 工程化保障与系统集成方案
本章聚焦于构建标准化、自动化的软件工程体系,旨在解决大规模分布式架构下的研发协同、环境一致性及跨系统集成挑战。工程化保障体系以DevSecOps为核心,将安全合规与质量控制嵌入软件开发生命周期(SDLC)的每个阶段。通过建立统一的代码托管与分支管理规范,系统实现了从源码提交到生产部署的全链路自动化,有效降低了人工干预带来的操作风险。
在持续集成与持续交付(CI/CD)层面,方案采用声明式流水线定义,整合静态代码分析(SAST)、软件成分分析(SCA)及容器镜像安全扫描,确保交付产物符合信创环境的安全性要求。基础设施即代码(IaC)技术的引入,保障了开发、测试与生产环境的配置镜像化,消除了因环境差异导致的部署故障。研发团队依托容器化编排技术,实现了应用组件的快速拉起与弹性扩缩,为高并发场景下的系统稳定性提供了底层支撑。
系统集成方案重点解决异构组件间的通信与数据交换。依托高性能API网关与分布式消息中间件,构建松耦合的集成架构,支持同步调用与异步解耦的灵活切换。针对跨部门、跨平台的集成场景,方案定义了标准化的接口契约与版本控制机制,通过契约测试验证接口兼容性,降低了多系统联调时的沟通成本与技术摩擦。
质量保障体系涵盖了多维度的自动化测试框架,包括单元测试、集成测试、性能压测及端到端业务仿真。系统通过设置质量门禁,强制执行代码覆盖率与漏洞修复率指标,未达标版本禁止进入发布流程。灰度发布与蓝绿部署策略的应用,为系统变更提供了可靠的回滚机制,显著提升了生产环境的变更成功率与业务连续性。
全栈可观测性平台作为工程化保障的监控核心,通过采集指标(Metrics)、日志(Logs)与链路追踪(Tracing)数据,实现对系统运行状态的实时洞察。基于Prometheus与ELK协议栈的深度整合,运维团队能够快速定位跨服务调用的性能瓶颈或逻辑异常。通过定义服务等级目标(SLO)与自动告警触发机制,系统平均修复时长(MTTR)得到有效压缩,确保了复杂系统在长期运行中的高可用性与技术债的可控性。本章所确立的工程化路径,为系统从开发态向运行态的平滑演进提供了标准化的操作指南。
8.1 敏捷开发与DevSecOps流水线设计
针对千万级高并发业务的快速迭代需求,本项目构建了敏捷开发与DevSecOps一体化交付体系。该体系通过标准化迭代流程与自动化流水线,将安全防护与质量控制嵌入研发全生命周期,实现了基础设施的自动化编排与配置的动态管理。系统在保障交付频率的同时,利用深度集成的工具链确保了生产环境的稳定性与合规性。
8.1.1 敏捷开发模式与双周迭代机制
项目采用Scrum敏捷开发框架,构建基于“双周迭代”的快速交付机制。产品待办列表(Backlog)根据业务价值与技术复杂度进行原子化拆解,并在Sprint Planning阶段确定迭代目标。为应对高并发场景下的技术挑战,迭代计划同步纳入了架构演进与技术债治理任务。每日站会(Stand-up Meeting)聚焦于识别并解决技术阻塞点(Blockers),确保风险在24小时内得到响应。
执行严格的完成定义(DoD)标准是质量控制的核心。功能特性在进入部署阶段前,必须满足单元测试覆盖率不低于80%、代码静态扫描零高危漏洞、且通过同行评审(Code Review)。迭代末期的Sprint Review用于向干系人展示可工作的软件增量,而Sprint Retrospective则利用根因分析(RCA)优化流程瓶颈。该机制使交付周期缩短了40%,并显著降低了需求变更引发的返工成本。
8.1.2 DevSecOps自动化流水线架构
流水线以GitLab CI为编排核心,利用Docker与Kubernetes技术保障开发、测试、生产环境的高度一致性。代码提交至主干分支将触发自动化构建,流水线同步启动静态应用安全测试(SAST),利用SonarQube扫描代码异味与潜在逻辑缺陷。生成的镜像自动打标并推送到Harbor私有仓库,确保了软件产物的全路径可追溯。
安全维度落实“安全左移”原则,流水线集成Dependency-Check以识别第三方组件的CVE漏洞。在准生产环境(Staging)中,系统自动执行动态应用安全测试(DAST)与自动化回归测试套件,涵盖接口契约测试与业务链路压测。只有通过所有质量门禁(Quality Gate)的变更,方可进入生产发布流程。系统支持蓝绿发布与金丝雀发布策略,将单次部署的人力介入降低了90%,并将平均修复时间(MTTR)缩短至分钟级。
DevSecOps自动化流水线整体架构如下图所示:
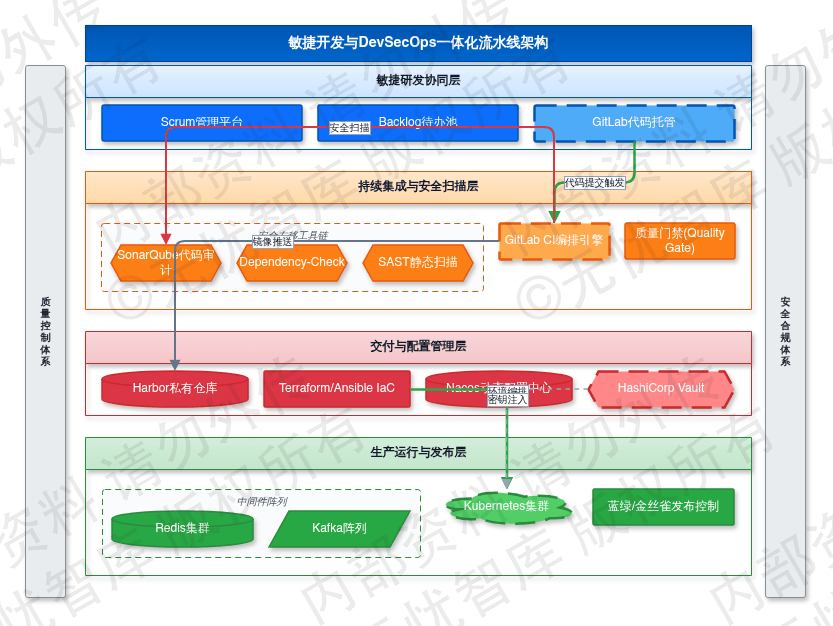
如上图所示,该架构通过集成GitLab CI、SonarQube、Harbor及K8s集群,构建了从代码提交、安全扫描、镜像构建到自动化部署的全链路闭环,确保了交付效率与运行安全。
8.1.3 基础设施即代码(IaC)与配置管理
为消除配置漂移风险,项目全面采用基础设施即代码(IaC)理念。利用Terraform进行多云资源的生命周期管理,并配合Ansible执行应用级的精细化配置。所有HCL脚本与Playbooks均纳入Git版本控制,遵循与业务代码相同的审核流程。标准化模块(Modules)支持一键拉起包含负载均衡(SLB)、Redis集群、Kafka阵列及数据库实例的完整拓扑环境,确保了环境的镜像级对等。
配置管理依托Nacos构建动态配置中心,实现了业务参数的实时下发与秒级生效。针对数据库凭据、API密钥等敏感信息,系统集成HashiCorp Vault进行加密存储与动态注入,避免了代码库中的硬编码泄露。通过IaC与动态配置的结合,运维团队实现了从手动操作向架构治理的转型。在应对突发流量时,系统可基于预设模板在3分钟内完成水平扩容(Scale-out),增强了系统的弹性伸缩能力。
下表列出了DevSecOps流水线中关键工具链的选型及核心指标:

通过上述工具链的深度整合,项目构建了具备高度确定性的工程化保障体系,确保了系统在复杂业务场景下的高质量运行。
8.2 微服务治理与全链路可观测性
8.2.1 微服务治理框架选型与服务生命周期管理
针对复杂业务场景下服务粒度细化导致的调用链路冗长问题,系统弃用传统的 SDK 侵入式治理方案,转而采用基于云原生架构的 Istio 服务网格(Service Mesh)。该架构将流量管理、安全通信与策略执行逻辑从业务代码中剥离,下沉至 Sidecar 代理层(Envoy),实现了业务逻辑与治理逻辑的物理隔离。服务发现机制依托 Consul 构建高可用集群,利用其 Raft 协议保证注册信息的一致性,并支持跨数据中心的服务同步。当实例发生故障时,Consul 健康检查机制可在毫秒级内感知状态异常,并驱动控制平面实时更新负载均衡端点列表,确保失效节点被自动剔除。
在流量调度层面,系统在 Sidecar 层面配置了加权轮询(Weighted Round Robin)与最少连接数(Least Connections)算法,以应对异构节点性能差异。熔断机制设定了严格的触发阈值:当特定服务的 5xx 错误率连续 30 秒超过 5%,或 P99 响应延迟突破 500ms 警戒线时,熔断器立即切断请求链路并进入半开状态,防止局部故障演变为系统性雪崩。
服务生命周期管理覆盖了从定义到销毁的全过程。所有微服务接口强制遵循 RESTful 规范,利用 Swagger 自动生成接口契约并同步至 API 网关。服务准入阶段需通过自动化压测校验,单实例在 16核/64G 资源配额下必须达到 3000 QPS 的性能基准。针对存量服务的退役,系统执行灰度下线流程:首先在网关层将接口标记为“Deprecated”并返回特定响应头,随后持续监控 48 小时流量数据,确认无调用请求后,由 DevOps 流水线自动触发容器销毁与注册信息注销,维持架构的精简性。
8.2.2 全链路追踪与多维监控体系构建
为消除微服务架构下的“黑盒”效应,系统基于 OpenTelemetry 标准构建分布式追踪体系。通过 Java Agent 无侵入式注入技术,为每个进入系统的入口请求分配全局唯一的 TraceID,并采用 W3C Trace Context 协议将其透传至数据库访问、Kafka 消息积压及第三方支付接口等环节。Span 数据经由 Collector 实时汇聚至 Jaeger 存储后端。架构师可据此生成服务拓扑图,直观分析请求在各微服务间的耗时占比,精准定位响应耗时超过 2s 的性能瓶颈节点。
监控体系采用 Prometheus 与 Grafana 的组合,构建了覆盖基础设施、容器、应用及业务的四级观测模型。基础设施层重点采集节点 CPU 负载与磁盘 I/O 吞吐;容器层实时监控 K8s Pod 的重启频率与网络丢包率;应用层深度探测 JVM 堆内存波动、线程池饱和度及慢 SQL 执行计划;业务层则通过埋点提取订单转化率与支付成功率等核心指标。
微服务治理与可观测性系统的逻辑架构如下图所示:
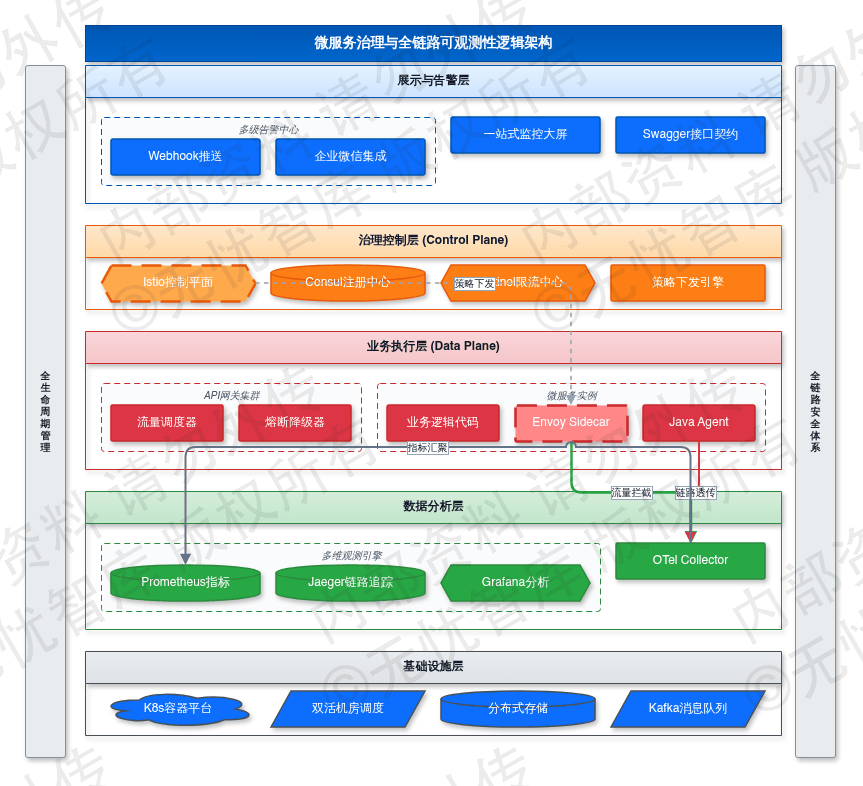
如上图所示,该架构实现了控制平面与数据平面的解耦。底层数据采集层负责全量指标抓取,中间分析层通过特征提取将零散的日志、指标与链路数据转化为结构化视图,顶层展示层则为运维人员提供一站式监控大屏,支撑故障的快速定位与闭环处理。监控系统配置了多级告警策略,一旦指标触达阈值,Webhook 将实时推送至企业微信,确保运维团队达成“分钟级发现、五分钟定位”的保障目标。
8.2.3 异常处理与系统容灾降级策略
分布式环境下的业务连续性依赖于多层级的容错设计。系统设计了三级异常处理机制:第一级为本地异常捕获,针对幂等性接口配置 3 次指数退避重试(Exponential Backoff),以消除网络瞬时抖动影响;第二级为服务降级(Fallback),当非核心链路(如推荐、积分)出现异常时,系统自动切换至备用逻辑,返回静态缓存数据,优先保障主交易链路的可用性;第三级为全局流量调度,在双活机房架构下,若 A 机房发生物理故障,API 网关将在 30 秒内根据健康检查结果将全量流量切向 B 机房。
针对极端高并发场景,系统部署了 Sentinel 分布式限流组件。基于压测获取的系统承载上限,在网关层实施全局令牌桶限流,在微服务层实施热点参数限流。例如,秒杀业务中针对特定商品 ID 的访问频率被限制在 500 QPS 以内,超出部分直接拦截。此外,系统定期开展混沌工程(Chaos Engineering)演练,通过主动注入网络延迟、模拟磁盘损坏等故障场景,验证系统自愈能力与降级预案的有效性,确保核心业务可用性不低于 99.99%。
下表展示了系统核心治理参数的配置基准:

8.3 遗留系统集成与API网关对接
8.3.1 遗留系统资产识别与集成适配策略
针对存量ERP、CRM及自研业务系统,需解决异构协议下的数据互通与业务连续性问题。本项目通过自动化扫描工具提取系统元数据,对通信协议、数据交互频率及安全机制进行全量审计。根据审计结果,将集成路径划分为适配器封装与数据异步同步两类。
对于具备业务逻辑复用价值的SOAP/XML WebService或基于TCP私有协议的系统,开发高性能适配器(Adapter)实现服务化转换。适配器层采用Netty框架构建,负责字节流解析、字符集转码及报文格式映射(如XML与JSON互转)。针对TCP私有协议,适配器通过自定义Codec处理器解析报文头,提取业务指令并封装为标准的RESTful接口,确保新旧系统在不改动源码的前提下完成对接。
对于仅需数据共享的孤岛系统,采用CDC(变更数据捕获)技术实时监听数据库Binlog或归档日志。通过Kafka消息队列将增量数据分发至共享数据层,实现数据层面的解耦。所有集成接口均需通过GB/T 32907-2016标准的安全扫描,严格控制遗留资产的暴露面,防止因旧系统漏洞引发的链式安全风险。
8.3.2 统一API网关架构设计与流量治理
系统采用基于云原生架构的高性能API网关作为全域服务入口。网关层部署于应用层前端,执行请求路由、协议转换、安全防护与流量整形。网关集群采用无状态分布式架构,利用Nginx高性能内核支撑万级并发。在流量治理方面,网关内置令牌桶算法(Token Bucket),支持按IP、AppID、接口路径配置多维度限流策略。单节点吞吐上限设定为8000 QPS,当流量超过阈值时,网关执行丢弃或排队逻辑,保护后端遗留系统免受瞬时洪峰冲击。
API网关的技术架构与集成逻辑如下图所示:
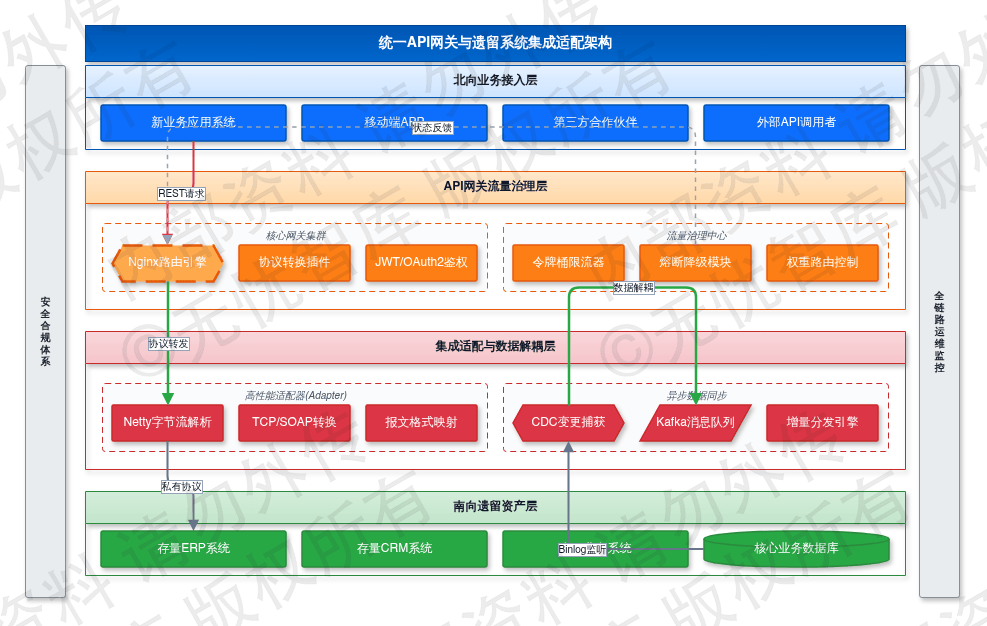
如上图所示,该架构实现了南向接入遗留系统与北向支撑新业务应用的对接。网关安全插件集成JWT鉴权与OAuth 2.0协议,对每笔调用进行身份校验。同时,网关配置熔断降级机制,当探测到遗留系统接口响应时延超过500ms或错误率达到30%时,自动触发断路器,返回预设的缓存数据或友好提示。所有调用链路通过OpenTelemetry接入全链路追踪系统,实现毫秒级监控与故障定位。
8.3.3 接口标准化与兼容性保障机制
接口定义的标准化是确保跨系统协同效率的关键。本项目执行严格的接口版本化管理,在URL中显式标注版本号(如/v1/、/v2/),支持新旧逻辑并存。针对遗留系统升级导致的接口变更,采用双版本并行运行策略,通过网关层的权重路由功能,按照5%、20%、50%到100%的比例逐步切换流量。
在兼容性保障方面,利用自动化回归工具对存量接口进行100%契约测试(Contract Testing)。测试涵盖报文格式、字段类型、必填项及业务逻辑一致性校验。下表展示了网关层核心配置参数规格:

系统通过日志审计模块实时记录非法请求与异常调用,满足等保2.0网络安全审计要求。网关层不仅作为流量闸口,更为后续业务全量上云与微服务化改造提供了标准化的集成底座。通过对接口调用频率与错误率的持续分析,运维团队可精准识别遗留系统的性能瓶颈,为后续的系统重构或下线提供数据支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)