在矩池云上开箱即用 ProteinX:RNA 结构预测实战指南
ProteinX v0.5.0是目前最接近 AlphaFold3 能力的开源蛋白质结构预测大模型框架,主要用于:蛋白质三维结构预测、蛋白-蛋白复合物预测、蛋白-小分子(药物)结合预测、DNA/RNA 复合物建模、生物医药、药物发现方向研究,实现用 AI 大幅降低生物分子研究的实验成本与时间。
欢迎来到 矩池云实战课程!
本期我们带来一个超实用的生物科研教程—在矩池云上用ProteinX预测RNA 结构。不管是在做生物/医药方向、AI Research、还是想快速入门结构生物信息学,矩池云目前已部署该镜像,轻松实现开箱即用。
PART.01:镜像介绍:proteinx inference
镜像名称:proteinx inference
框架介绍:ProteinX v0.5.0 是目前最接近 AlphaFold3 能力的开源蛋白质结构预测大模型框架,主要用于:蛋白质三维结构预测、蛋白-蛋白复合物预测、蛋白-小分子(药物)结合预测、DNA/RNA 复合物建模、生物医药、药物发现方向研究,实现用 AI 大幅降低生物分子研究的实验成本与时间。
主要功能:
-
预测 RNA 的 3D 原子坐标(输出 CIF 格式文件)
-
同时支持 DNA / 蛋白质/小分子 结构预测
-
基于 Transformer + 扩散模型,精度高、使用简单
一句话:通过一段蛋白序列(氨基酸序列),它能预测这个蛋白折叠后的 3D 结构。
PART.02 实操教程
1.登录 矩池云官网 → 选择GPU云服务器,推荐 RTX 4090 (24GB)
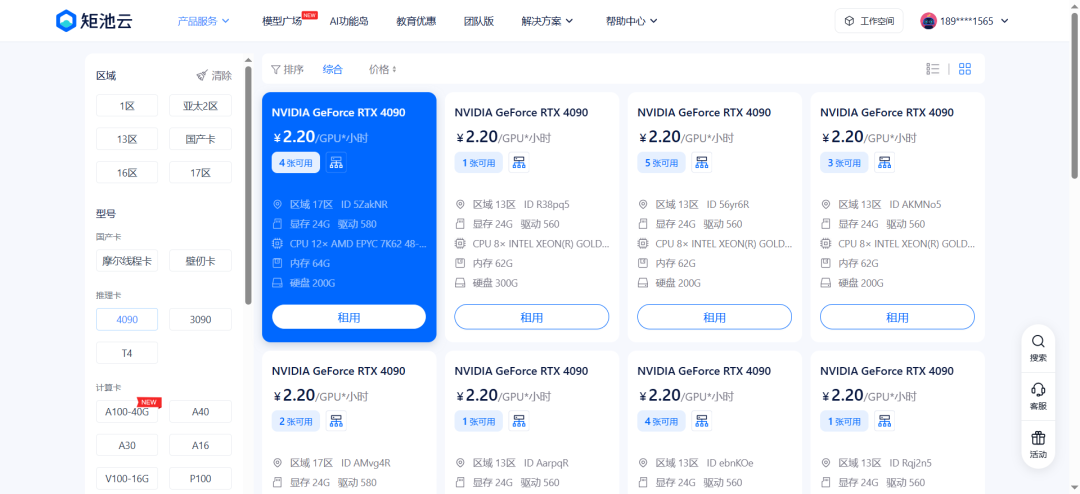
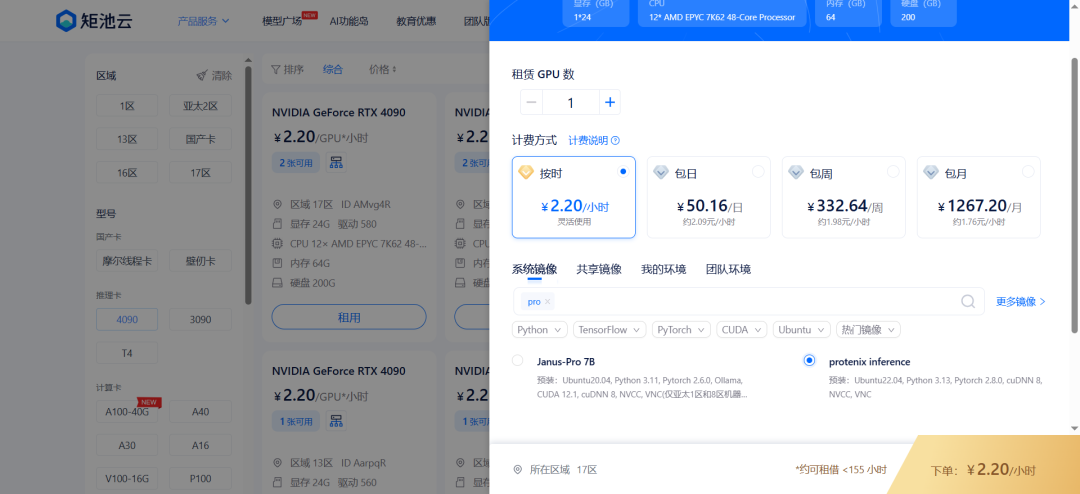
2. 选择镜像:搜索 "protenix inference",启动实例(约 2~3 分钟)
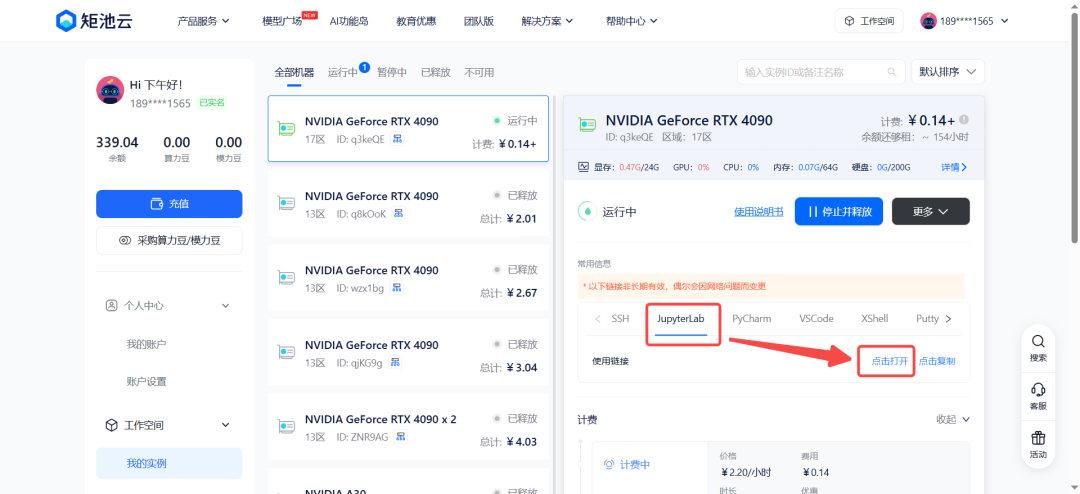
3. 启动后,进入JupyterLab, 打开链接,进入界面
4. 进入主界面:搜索 AI Camp RNA目录" 赛题文件夹"直接使用
也可以自行上传 JSON 文件(通过 Web 文件管理或 scp)
JSON 格式文件准备,如果不懂可以让ai帮你写一段,每个任务用一个 JSON 文件定义 RNA 序列。例如 1.json:
{
"name": "R1107",
"sequences": [
{
"rnaSequence": {
"sequence": "GGGAAACCC",
"id": "A"
}
}
],
"dialect": "alphafold3",
"version": 1
}序列只包含 A/U/G/C,id 是链标识符(单链通常用 "A")。5. 运行baseline:运行模式:读取 JSON → 编码序列 → 扩散采样 5 次 → 输出 5 个候选 3D 结构(CIF 格式)
查找命令:
bash/AI_Camp_RNA_2026/run_protenix_inference.sh
出现以下代表文件推理完成


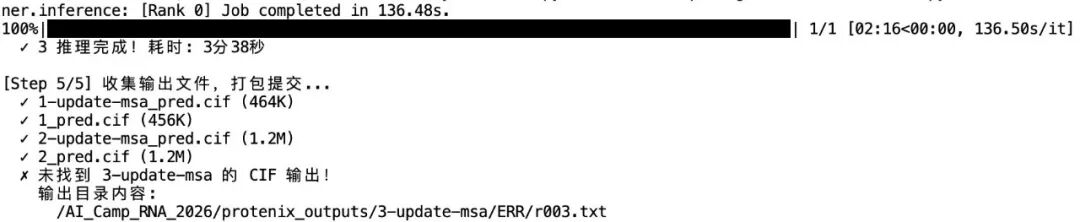
6. CIF 文件导出结果:打开protenix_outputs文件夹,右击下载output.zip文件夹
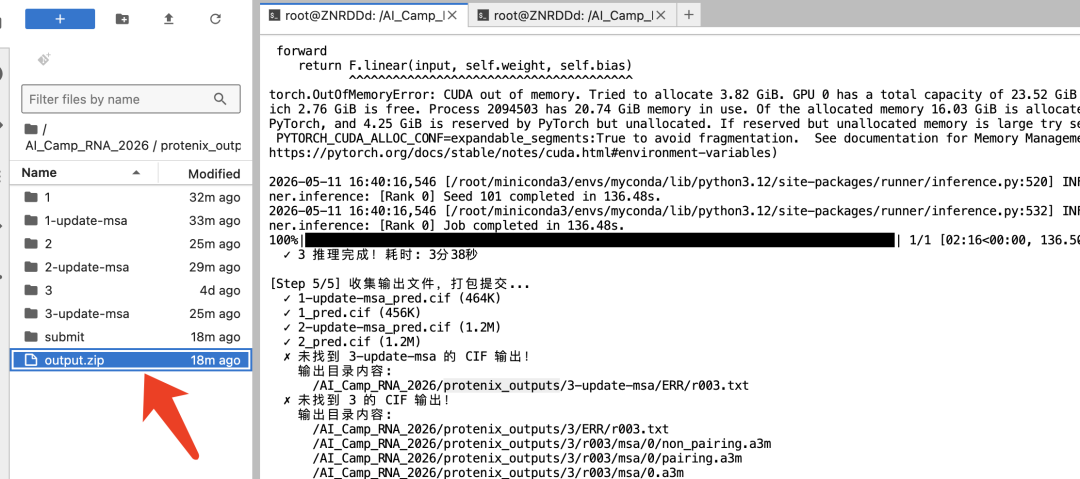
7.结果展示: 在文件管理器里右键下载 CIF 文件,CIF 文件 包含每个原子的 (x, y, z) 坐标,
打开网页(https://www.rcsb.org/3d-view)查看器,把 cif 文件拖进去,就能看到一个可旋转的 3D 模型——你的画长什么样、蛋白和 RNA 怎么贴在一起,一目了然。
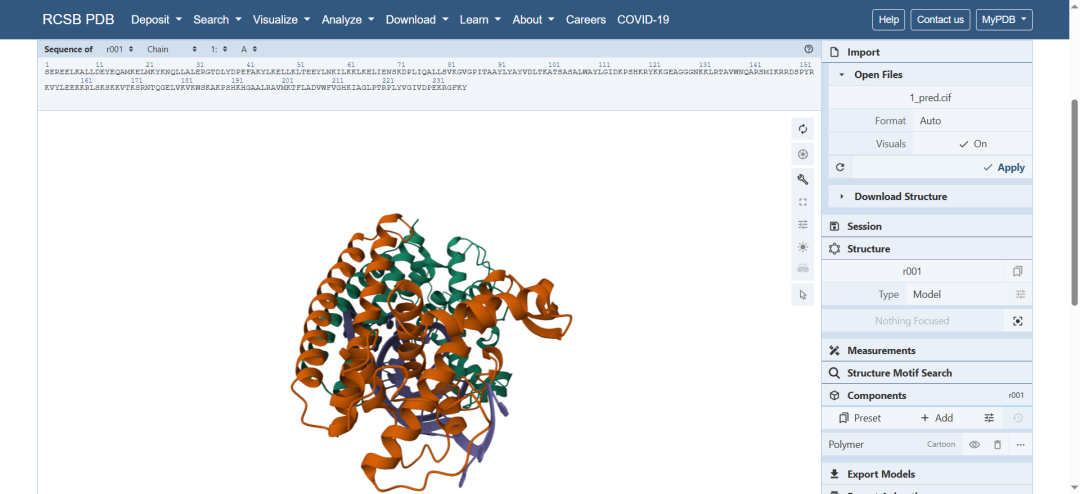
8. 效果评估:看每张画的"把握度评分"
每张备选画的同一目录下,都有一个 summary_confidence_*.json 文件,可以查到每张画的把握度评分
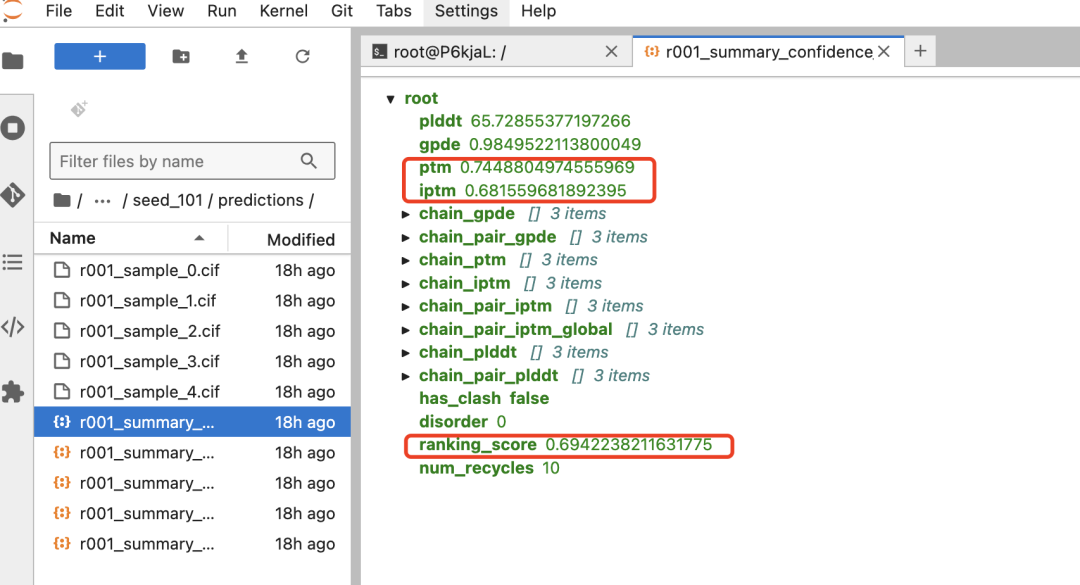
|
指标 |
指标含义 |
指标含义怎么看 |
|
|
整体形状的把握度 |
越大越好(0~1) |
|
|
蛋白和 RNA 怎么贴的把握度 |
越大越好(0~1),这是 RNA 任务的题眼 |
|
|
画师综合给自己打的"总分"(通常基于 iptm 和 ptm 加权) |
越大越好,挑画的时候直接看这个就行 |
怎么找到summary_confidence_*.json文件?
在 AI_Camp_RNA_2026/protenix_outputs/ 这个目录,左边有 1、2、3、submit、output.zip。
json 文件在 1、2、3 这三个文件夹里面的更深处。以 1(就是 r001)为例,点进去:
-
第一步:双击
1文件夹 → 进去后会看到一个r001文件夹 -
第二步:双击进入
r001→ 里面会有一个seed_101(或seed_xxx)文件夹 -
第三步:双击进入
seed_101→ 里面会有一个predictions文件夹 -
第四步:双击进入
predictions→ 里面就是 5 个 cif + 5 个 json
PART.03 优化攻略
方向 1 :救回 r003(把白卷补上) ⭐ 涨分最多
按尝试难度从低到高:
方案 A:减小 batch / 降低 sample 数(不花钱,先试这个)
让 Protenix 一次少画几张备选(比如从 5 张降到 1-2 张),内存压力会小很多。
💬 怎么改?让 AI 给你方案:
"我在用 Protenix 跑结构预测,r003 这个样本因为太大(920 个氨基酸的蛋白)出现 CUDA out of memory 错误。
我用的是 24GB 显存的 A10 GPU。请告诉我:
有哪些可以不换硬件就降低显存占用的命令行参数(比如 --num_samples、--use_lower_precision 之类的)
给我一个修改后的 protenix predict 命令,只针对 r003 用更省显存的参数
这样改之后精度大概会损失多少?"
方案 B:把 r003 单独换更大显存的 GPU 跑
如果方案 A 还是不行,可以单独把 r003 换到 32GB 或 40GB 显存的 GPU 上跑(r001 和 r002 继续用免费 A40)—矩池云上可以同时租赁几张卡同时跑,按小时计费
方案 C:用 CPU offload(把部分计算挪到内存)
Protenix 支持把一部分中间结果暂存到内存(而不是显存),代价是速度更慢。这个相对复杂,建议方案 A、B 都试过再考虑。需要额外内存(建议 用矩池云A100 40G)
💬 完全卡住了?把报错丢给 AI:
"我是 AI 生物赛新手。运行 Protenix 时遇到了这个报错:
[粘贴完整报错]
我的环境是 Linux + NVIDIA A10 24GB 显存 + Python 3.10 + Protenix 0.5.0。请帮我:
解释这个报错的原因
给出 3 种从易到难的修复方案
每个方案给可以直接复制的修复命令"
方向2 :打开 MSA(让画师参考同类作品)
为什么要做这个?
Baseline 默认关掉了 MSA(多序列比对)——开启 MSA 需要联网拉同源序列数据库,这一步比较慢且容易出错,所以示例代码里关掉了。
但 MSA 的作用就像我们前面说的:让画师同时看十几张近亲的照片,精度会显著提升——这是 Protenix 官方推荐的标准用法,关掉等于砍了模型一条腿。
🔰 最简单的做法
绕过"实时联网拉 MSA 数据库"的问题,有两条路:
-
存储:本地 MSA 数据库可能要几十 GB 到上百 GB(看选哪个数据库)
-
时间:MSA 生成本身比较慢,长蛋白(如 r003 的 920 残基)可能要几小时
路径 A:本地预先准备好 MSA 文件(推荐)
很多公开数据库(比如 ColabFold、UniRef)提供预先算好的 MSA,你可以下载下来放在云电脑里,然后告诉 Protenix"用这些本地文件",就不用联网了。
路径 B:用 ColabFold 等在线服务先生成 MSA,再喂给 Protenix
ColabFold 是免费的在线服务,可以只生成 MSA、不跑模型。先在 ColabFold 上拿到 MSA 文件,再传到云电脑里给 Protenix 用。
💬完全没接触过 MSA?让 AI 给你完整方案:
"我在用 Protenix 做 RNA-蛋白结构预测。Baseline 默认关掉了 MSA(
--use_msa false),因为联网拉数据库会失败。我想把 MSA 用起来,请帮我:
解释 MSA 在 Protenix 里到底是怎么用的、为什么对精度重要
给我两条路径(本地预算 MSA / 用 ColabFold 在线生成)的具体操作步骤
每条路径需要哪些工具、大概要多少时间和存储
如果选 ColabFold,给我一个最简单的入口"
📌 几个常见的坑:
-
MSA 生成可能很慢(蛋白长度越长越慢,r003 可能要几小时)
-
蛋白和 RNA 的 MSA 处理方式不同——RNA 的同源序列数据库远小于蛋白(Rfam vs UniProt),且 RNA 同源性识别本身就更难,所以开 MSA 对蛋白部分的精度提升更明显,对 RNA 部分提升相对有限
第二档:进阶玩家(有时间精力再碰)
这一档的方向门槛较高、收益不一定大。建议做完前两档之后有余力再尝试。
方向 3:换更强的模型 / 自己微调
Protenix 默认用的是 protenix_base_default_v0.5.0——这是通用的基础版。如果你有时间和算力,可以:
-
试试 Protenix 的其他变体模型(比如更大的版本、专门针对 RNA 微调过的版本)—通用基础版可以用矩池云 A100。
-
自己针对 RNA-蛋白复合物数据微调(需要大量公开数据 + 多张高端 GPU,通常 4-8 张 A100 40GB 起步,成本很高)
矩池云ProteinX镜像,把原本需要配置 CUDA、安装生物信息库、调试扩散模型的数周工作量,压缩到了 10 分钟上手。无论你是发论文、打比赛,还是单纯好奇 RNA 长什么样子,都值得试一试。
👉点击矩池云, 搜索“proteinx inference”镜像,开始你的第一个 RNA 结构预测吧!
本次课程感谢Datawhale社区。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)