2026年Go后端找工作有多难?面试了600+人后,我想说几句真话
这篇文章写得很长,因为我想把真正有价值的东西讲清楚,而不是给你灌鸡汤。Go+AI方向的就业机会是真实存在的,但前提是你得有真东西。CRUD项目、背八股、刷LeetCode,这些是基本功,不是区分度。区分度来自于你做过什么有技术深度的项目,遇到问题怎么思考、怎么解决。如果你正在Go+AI方向求职,遇到了一些困惑,欢迎评论区留言或者私信交流。目前我和团队在做Go+AI方向的就业辅导,有兴趣的同学可以私
大家好,我是地鼠哥,一个在Go+AI方向摸爬滚打多年的后端开发。
过去几年,我主导过AI教育电商平台、AI工具系统等核心商业项目的架构设计与研发落地,也面试了600+位学员,做过的模拟面试已经数不清了,帮很多人拿到了自己满意的结果。
今天不聊虚的,我想聊聊2026年Go后端求职的真实情况,以及我观察到的几个致命问题。如果你正在找工作,或者准备换方向,希望这篇文章能给你一些启发。
先说结论:市场没有你想的那么差,但你的准备方式可能全错了
很多人一上来就跟我抱怨:“投了几十家,连面试机会都没有。”
我看了他们的简历,问题一目了然——项目全是CRUD,面试官一深问就露馅,简历上写的东西自己都讲不清楚。
问题不是市场没岗位,是你在面试官眼里没有区分度。
Go后端求职的5个致命问题
问题一:项目没有亮点,简历千篇一律
我看过太多简历,项目经历写的是:用户管理、权限校验、增删改查。面试官看到这种简历,30秒就跳过了。
你的项目需要让人眼前一亮。 不是说你要造轮子,而是你的项目要能体现你在架构设计、技术选型、性能优化方面有真实的思考。
问题二:项目做了但讲不出来
很多人做了项目,但面试时被问"你这个项目最大的技术难点是什么",支支吾吾半天说不出。
这不是你技术不行,是你没有梳理过。每个项目都应该提前准备好这几个问题的答案:
- 项目的技术架构是什么?为什么这么选?
- 遇到了什么技术难点?怎么解决的?
- 如果重新做,你会怎么优化?
问题三:想学AI但完全没有方向
2026年,AI已经不是"加分项"了,它正在变成"必选项"。但很多Go开发者想学AI,不知道从哪里开始,学了一堆概念,写不出一行能用的代码。
我的建议是:不要从论文和概念开始,从工程化落地开始。 用Go写一个真正能跑的AI应用,比你看100篇论文都有用。
问题四:八股背了但用不上
很多人面试前疯狂背八股,但面试官一问项目场景,八股文完全对不上。
八股要和项目关联起来。 比如你做了RAG系统,面试官问你"Redis和本地缓存怎么选",你就能结合向量检索的缓存策略来回答,而不是背书式的"Redis支持分布式"。
问题五:面试前没有系统准备
很多人面试前就是刷刷LeetCode、背背八股,从来没有模拟过完整的面试流程。自我介绍说不利索,项目讲不清楚,反问环节不知道问什么。
面试是门技术活,需要练。 你不去模拟,到了真面就只会紧张。
接下来,我用两个真实项目,讲讲Go+AI方向到底该怎么做
下面这两个项目,都是我已经落地商用、在面试中验证过有效性的项目。我会重点讲架构设计和技术难点,不是为了展示项目有多牛,而是想让你知道:一个能经得起面试官追问的项目,到底长什么样。
项目一:AI智能面试平台——多Agent协作+RAG引擎的工程实践
项目背景
这是一个AI驱动的面试平台,核心功能是:用户上传简历 → AI分析简历 → 生成针对性面试问题 → 用户回答 → AI评估回答质量并给出反馈。
这个项目已经上线商用,完成了出海部署,有真实的美元收益。我们甚至和人民邮电出版社合作,把项目的技术实践写成了一本书,很快就会和大家见面。
技术架构
技术栈:Go + Eino + Hertz + Milvus + Next.js
架构风格:DDD分层架构
为什么选DDD?因为这个项目业务复杂度高——简历解析、问题生成、回答评估,每个领域都有独立的业务逻辑和规则。DDD可以让每个领域的代码自治,避免一坨意大利面条式的代码。
核心技术点一:多Agent协作
这是这个项目最有意思的部分。
我们没有用一个大模型搞定所有事情,而是拆成了多个Agent:
- 简历分析Agent:解析简历内容,提取关键技能和经验
- 问题生成Agent:根据简历分析结果,生成针对性的面试问题
- 回答评估Agent:评估用户的回答质量,给出改进建议
为什么不用一个Agent? 因为一个Agent的Prompt太长时,模型容易"失焦",输出质量不稳定。拆成多个Agent,每个Agent的职责单一,Prompt精简,输出更可控。
多Agent协作的难点在哪? 状态管理。多个Agent之间需要传递上下文,比如简历分析的结果要传给问题生成Agent,问题的内容要传给回答评估Agent。我们用Eino Graph来编排Agent的执行流程,用状态机来管理Agent之间的数据传递。
这里踩过的坑:Agent之间传递的上下文如果太大,会导致Token消耗暴增,响应变慢。我们的解决方案是对上下文做摘要压缩,只传递Agent真正需要的信息。
核心技术点二:RAG引擎
面试问题的生成不是凭空的,我们有一个知识库,里面存储了各个技术方向的面试题和评估标准。
RAG的检索策略:
我们用的是混合检索,不是单纯的向量检索:
- 向量检索(Milvus):语义相似度检索,找到语义上最相关的内容
- BM25关键词检索:精确匹配关键词,解决向量检索"语义相近但关键词不匹配"的问题
- RRF(Reciprocal Rank Fusion)重排序:把向量检索和BM25的结果做融合排序,取两者之长
为什么不用纯向量检索? 举个实际例子:简历里写了"Kubernetes",知识库里有一条面试题关于"K8s的Pod调度策略"。纯向量检索可能匹配不到,因为"Kubernetes"和"K8s"的语义向量不一定很近(取决于模型)。但BM25如果做了同义词扩展,就能匹配到。RRF把两者融合,准确率提升明显。
核心技术点三:流式响应SSE
面试问题生成和回答评估都是流式输出的,用户不需要等大模型生成完才看到结果。
SSE的实现不难,但踩过的坑不少:
- 断连处理:网络不稳定时SSE连接会断开,需要做断线重连,并且从断点继续输出,不能从头再来
- 背压控制:大模型生成速度和前端消费速度不一致,需要做缓冲控制,避免内存溢出
- 超时处理:大模型偶尔会卡住不输出,需要设置合理的超时时间,给用户友好的提示
面试时怎么讲这个项目?
面试官大概率会问:
- “多Agent之间怎么通信?状态怎么管理?” → 你讲Eino Graph的编排和状态机
- “RAG的检索准确率怎么保证?” → 你讲混合检索和RRF重排序
- “SSE断连了怎么办?” → 你讲断线重连和断点续传的实现
这些问题,如果你只是看了一篇文章知道概念,和真正做过项目踩过坑的人,回答完全不一样。面试官一听就知道。
项目二:工业级RAG知识库系统——从文档处理到MCP协议集成
项目背景
这是一个企业级RAG知识库系统,核心功能是:用户上传各种格式的文档 → 系统自动解析、切片、向量化 → 用户提问 → 系统检索知识库并生成回答。
这个项目最特别的地方在于:它支持MCP协议,可以和Claude Desktop、Cursor等AI工具直连,让AI工具直接访问你的私有知识库。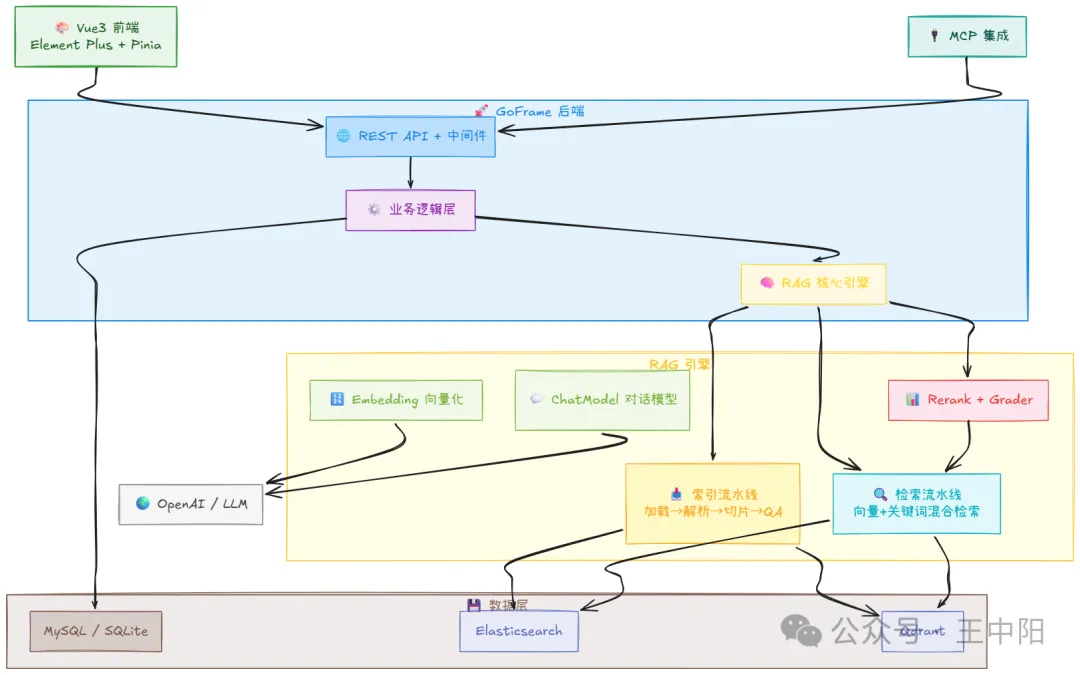
技术架构
技术栈:GoFrame + Eino + Qdrant + Elasticsearch + MCP协议
核心技术点一:文档处理流水线
文档处理是RAG系统最容易被低估的环节。很多人觉得"不就是把文档切成块然后向量化吗?"——真做起来,坑非常多。
多格式解析: 我们需要支持PDF、Markdown、Excel等多种格式。每种格式的解析逻辑完全不同:
- PDF需要处理表格、图片、多栏排版
- Markdown需要保留标题层级关系
- Excel需要处理多Sheet、合并单元格
切片策略: 这是最影响检索质量的环节。我们支持两种切片策略:
- 定长切片:按固定字符数切分,简单但有风险——可能把一段完整的内容切成两半
- 语义切片:按语义边界切分,保留内容的完整性,但计算成本更高
实际生产中,我们的经验是:先用语义切片保证质量,再通过定长切片兜底处理边界情况。
核心技术点二:混合检索
和第一个项目类似,但这个项目用的是Qdrant(而不是Milvus)做向量检索,ES做BM25关键词检索。
为什么这个项目换了向量数据库? 因为Qdrant对过滤查询的支持更好。知识库场景经常需要"在某个分类下检索",Milvus的过滤性能在数据量大时会有瓶颈,Qdrant在这方面更优。
手写RRF重排序: 网上大部分RRF实现都是Python的,Go的几乎没有。我们手写了Go版本的RRF,核心逻辑不复杂,但调参很有讲究——k值的选择直接影响最终排序结果。我们经过大量测试,最终确定了一个适合知识库场景的k值,准确率比单路检索提升了约30%。
核心技术点三:MCP协议集成
这是这个项目最有"面试杀伤力"的亮点。
MCP(Model Context Protocol)是什么? 简单说,它是一个标准化的协议,让AI工具(如Claude Desktop、Cursor)可以调用外部工具和数据源。
在我们的系统里,MCP的集成意味着:
用户在Claude Desktop里直接问问题,Claude会通过MCP协议调用我们的知识库系统,检索到相关内容后,结合检索结果生成回答。
从工程角度看,MCP集成的价值在于:
- 你的知识库不再是孤岛,而是AI生态的一部分
- 面试时讲MCP协议集成,能让面试官意识到你理解AI生态的工程化集成,而不是只会调API
MCP集成的实现要点:
- 定义标准的Tool Schema,描述知识库的能力和参数
- 实现MCP Server,处理Claude/Cursor的请求
- 做好权限控制和速率限制,防止滥用
Eino Graph DAG任务调度
整个文档处理流水线,我们用Eino Graph来编排。文档上传 → 格式解析 → 切片 → 向量化 → 入库,每个环节是一个节点,节点之间用DAG(有向无环图)连接。
DAG的好处: 有些步骤可以并行执行(比如不同格式的文档可以同时解析),DAG调度器会自动处理并行和依赖关系。
两个项目放在一起看:Go+AI方向的核心能力模型
做完这两个项目,我总结一下Go+AI方向的核心能力模型:
| 能力维度 | 具体要求 |
|---|---|
| Go后端基础 | 框架选型(Gin/GoFrame/Hertz)、架构设计(DDD/微服务)、性能优化 |
| AI工程化 | 大模型对接、RAG引擎搭建、Agent设计、Prompt工程 |
| AI基础设施 | 向量数据库(Milvus/Qdrant)、检索策略(混合检索/重排序) |
| 工程协作 | 流式响应、状态管理、协议集成(MCP)、CI/CD |
| 面试表达 | 能讲清楚为什么这么设计,而不只是怎么做的 |
这5个维度,每个维度都需要真实的项目实践来支撑。光看文章、背八股,面试时是经不起追问的。
关于简历,我有一个建议
不要站在你的角度自说自话,要站在面试官的角度思考:企业需要什么样的人才,你的简历就要呈现什么样的价值。
我面试过600+人,你的简历有没有包装痕迹、项目是否经不起推敲,有经验的人一眼就能看出来。
具体来说:
- 项目描述要有技术深度:不要只写"开发了XX功能",要写"通过XX方案解决了XX问题,性能提升了XX%"
- 技术栈要和项目匹配:你写了一堆技术栈,但项目里没体现,面试官会追问
- 简历要有主线:所有项目应该围绕一个方向展开,让面试官看到你的成长脉络
最后说几句
这篇文章写得很长,因为我想把真正有价值的东西讲清楚,而不是给你灌鸡汤。
Go+AI方向的就业机会是真实存在的,但前提是你得有真东西。CRUD项目、背八股、刷LeetCode,这些是基本功,不是区分度。区分度来自于你做过什么有技术深度的项目,遇到问题怎么思考、怎么解决。
如果你正在Go+AI方向求职,遇到了一些困惑,欢迎评论区留言或者私信交流。目前我和团队在做Go+AI方向的就业辅导,有兴趣的同学可以私信我聊聊,先聊聊看合不合适,不合适不勉强。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)