第三周+第四周-5.12
一般在全连接层中使用,在卷积层中也会见到,在卷积层中有时候并不是将神经元置零,而是将某些特征映射整体置零,比如讲颜色通道中的某几个整体置零。因为反向传播使用链式求导法则chainrule,所以求梯度的计算是通过一些导函数的值连乘得到,如果导函数的值越接近0,那么连乘在一起就会更加接近0。又因为反向传播求导是从后往前的,所以越靠近输入层的参数求导时,连乘在一起的项越多,越有可能一堆接近0的数值不断连
第三周+第四周-5.12
梯度消失
因为反向传播使用链式求导法则chainrule,所以求梯度的计算是通过一些导函数的值连乘得到,如果导函数的值越接近0,那么连乘在一起就会更加接近0。
又因为反向传播求导是从后往前的,所以越靠近输入层的参数求导时,连乘在一起的项越多,越有可能一堆接近0的数值不断连乘,导致梯度值越来越接近0。
当连乘之后的梯度值越接近0,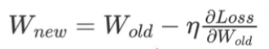
就会使得W参数调整越甚微,出现这种现象就叫做梯度消失问题。反过来另一个极端情况就叫做梯度爆炸。
避免梯度消失
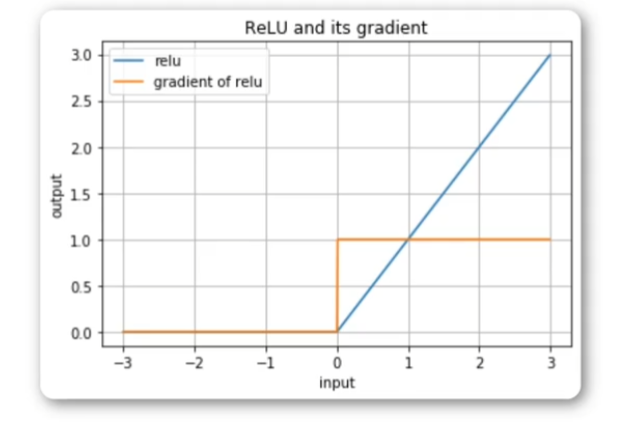
ReLU激活函数不会像Sigmoid函数或Tanh函数压扁输出在特定的范围,ReLU允许信号大于O的部分通过。因此,ReLU有更强的输出值。
当数值小于0的时候梯度是0,当数值大于0的时候梯度是1;梯度值是1确保了信号反向传播时保持强度。
在隐藏层中使用ReLU取代Sigmoid和Tanh,帮助避免梯度消失问题。
Dropout
是防止过拟合的手段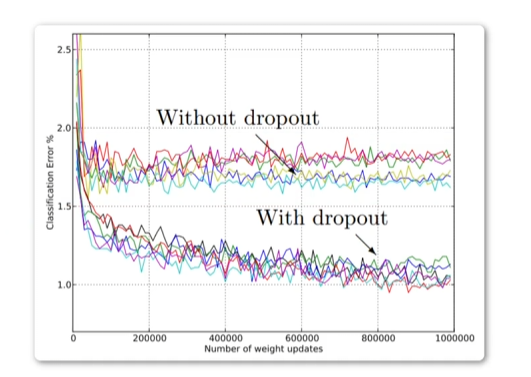
●训练时每次迭代,从BaseNetwork随机一个Subnetwork进行训l练,多次迭代就训ll练了参数共享的
Subnetworks,只要迭代次数足够多,整个BaseNetwork都将得到训l练;
●换个角度理解即,每个神经元有一定的概率(dropoutrate)输出值置为0;
●预测的时候不起任何作用,相当于神经网络中每个参数都参与计算;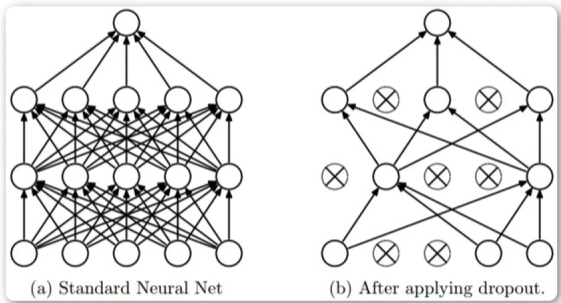
Dropout是正则化中非常常用的技巧。我们把一部分神经元置零,置零指的是将神经元的激活函数置零。一般在全连接层中使用,在卷积层中也会见到,在卷积层中有时候并不是将神经元置零,而是将某些特征映射整体置零,比如讲颜色通道中的某几个整体置零。Dropout一定程度上消除了特征之间的依赖关系,这样网络就只能用一些学习到的零散特征来进行判断。
深度学习框架中会封装有Dropout层,这样需要将哪一层输出随机的丢弃一些,那么就在哪一层后面跟Dropout 层即可。
PyTorch实战
MNIST手写数字识别
import torch
from torchvision import datasets,transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
#设置对数据进行预处理的方法
transforn =transforms.Compose([
#转换为张量
transforms.ToTensor(),
#归一化(均值和方差已经提前知晓)
transforms.Normalize((0.1307,),(0.3081,))
])
#获取数据集
datasets1 = datasets.MNIST('data',train=True,download=True,transform=transforn)
datasets2 = datasets.MNIST('data',train=False,download=True,transform=transforn)
#设置数据集的加载器,设置批次大小,设置是否打乱数据
train_loader = torch.utils.data.DataLoader(datasets1,batch_size=128,shuffle=True)
test_loader = torch.utils.data.DataLo𝑎𝑑𝑒𝑟(𝑑𝑎𝑡𝑎𝑠𝑒𝑡𝑠2,𝑏𝑎𝑡𝑐ℎ𝑠𝑖𝑧𝑒=1000)
#通过自定义类来构建模型
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(784,128)#第一层全连接
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(128,10)#第二层全连接
def forward(self,x):
x = torch.flatten(x,1)#变为一维张量
x = self.fc1(x)
x = F.relu(x)#激活函数,非线性变换
x = self.dropout(x)#随机失活
x = self.fc2(x)
output = F.log_softmax𝑥,𝑑𝑖𝑚=1#激活函数,非线性变换
return output
#创建模型
model = Net()
#定义训练模型的逻辑
def train(data,target, model,optimizer):
optimizer.zero_grad()#梯度清零
output = model(data)#模型输出
loss = F.nll_loss(output,target)#nll代表负对数似然
loss.backward()#反向传播,求梯度
#应用梯度去调参
optimizer.step()#模型参数更新
return loss
#定义测试逻辑
def test(data,target, model,test_loss,test_accuracy):
output = model(data)#模型输出
#累积测试损失
test_loss += F.nll_loss(output,target,reduction='sum').item()
#获取对数概率的最大索引
pred = output.argmax(dim=1,keepdim=True)
#累积测试准确率
test_accuracy += pred.eq(target.view_as(pred)).sum().item()
return test_loss,test_accuracy
#创建训练调参使用的优化器
optimizer = optim.Adam(model.parameters(),lr=0.001)
#真正分批次训练
EPOCHS = 10
for epoch in range(EPOCHS):
model.train()
for batch_idx,(data,target) in enume𝑟𝑎𝑡𝑒(𝑡𝑟𝑎𝑖𝑛𝑙𝑜𝑎𝑑𝑒𝑟):
loss = train(data,target,model,optimizer)#训练逻辑
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx /𝑙𝑒𝑛(𝑡𝑟𝑎𝑖𝑛𝑙𝑜𝑎𝑑𝑒𝑟), loss))#batch_idx * len(data):当前批次的样本数,len(train_loader.dataset):训练集的样本数, 100. * batch_idx / len(train_loader):当前批次的百分比
model.eval()#测试
test_loss = 0
test_accuracy = 0
with torch.no_grad():
for data,target in test_loader:
test_loss,test_accuracy = test(data,target,model,test_loss,test_accuracy)#测试逻辑
test_loss /= len(test_loader.dataset)#测试损失
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, test_accuracy, len(test_loader.dataset),
100. * test_accuracy / len(test_loader.dataset)))
决策树
一种对实例进行分类的树形结构,通过多层判断区分目标所属类别
本质:通过多层判断,从训练数据集中归纳出一组分类规则
优点:计算量小,易于理解
缺点:忽略属性间的相关性,样本类别分布不均匀时,容易影响模型表现
目标:根据训练数据集构建一个决策树模型,使它能够对实例进行正确的分类
ID3、C4.5、CART
ID3
利用信息熵原理选择信息增益最大的属性作为分类属性,递归地拓展决策树的分
枝,完成决策树的构造
信息熵(entropy)(不确定性):度量随机变量不确定性的指标,熵越大,变量的不确定性
就越大。假定当前样本集合D中第k类样本所占的比例为pk,则D的信息熵为: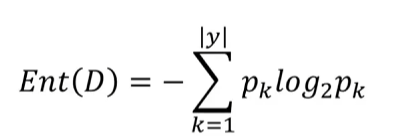
根据信息熵计算信息增益: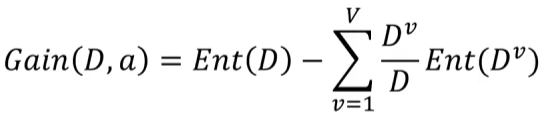

目标:划分后样本分布不确定性尽可能小,即划分后信息熵小,信息增益大
构建模型步骤
1.计算表格中使用ID3算法建
立决策树时各节点的信息增益
2.根据信息增益画出决策树
3.编程建立决策树模型
异常检测
对不符合预期模式的数据进行识别
概率密度:概率密度函数是一个描述随机变量在某个确定的取值点附近的可能性的函数
高斯分布的概率密度函数是: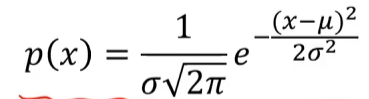
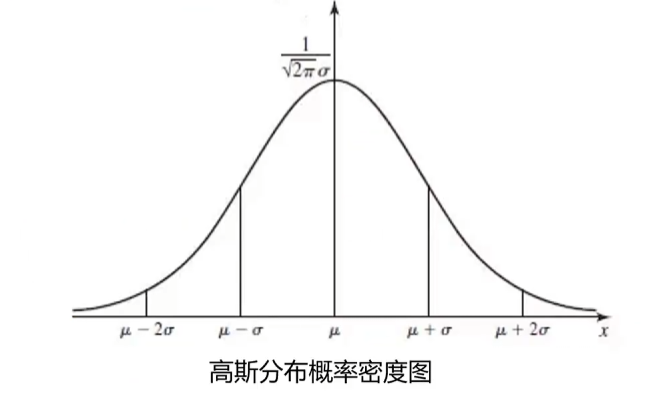
对于多维:计算各个维度P(x)再相乘,与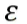
比较
主成分分析
数据降维
数据降维,是指在某些限定条件下,降低随机变量个数,得到一组“不相关”
主变量的过程。
作用:减少模型分析数据量
提升处理效率,降低计算难度;实现数据可视化。
PCA(principal components analysis):数据降维技术中
寻找k维新数据
如何保留主要信息,投影后的不同特征数据尽可能分得开(即不相关),使投影后方差最大
计算过程:原始数据预处理(标准化:μ=0,σ=1)
计算协方差矩阵特征向量、及数据在各特征向量投影后的方差
根据需求(任务指定或方差比例)确定降维维度k
选取k维特征向量,计算数据在其形成空间的投影
数据分离和混淆矩阵
建立模型的意义,不在于对训练数据做出准确预测更在于对新数据的准确预测
1、把数据分成两部分:训练集、测试集
2、使用训练集数据进行模型训练
3、使用测试集数据进行预测,更有效地评估模型对于新数据的预测表现
混淆矩阵
准确率可以方便的用于衡量模型的整体预测效果,但无法反应细节信息,具体
表现在:
没有体现数据预测的实际分布情况
(0、1本身的分布比例)
没有体现模型错误预测的类型
用于衡量分类算法的准确程度
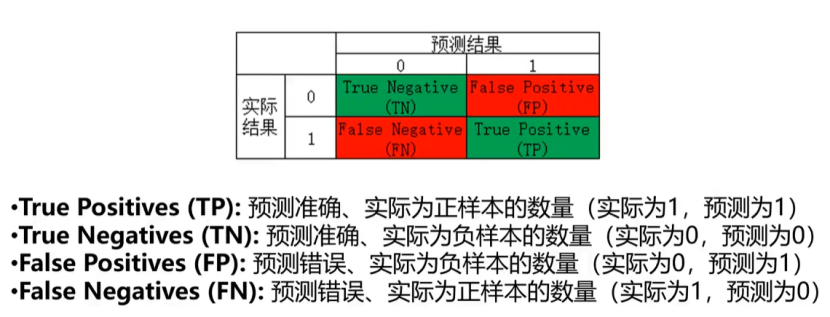
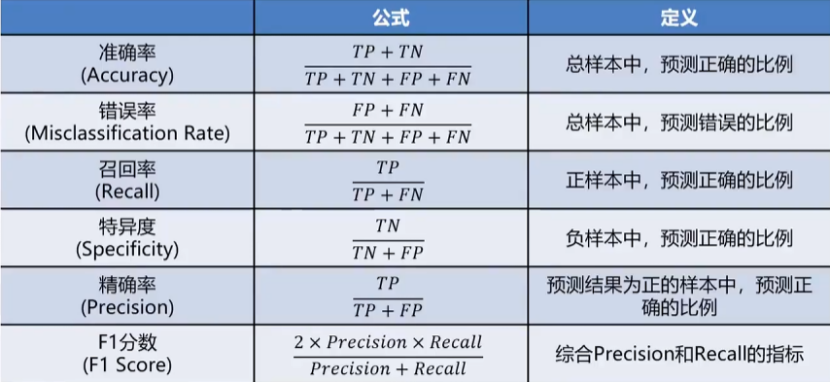
混淆矩阵指标特点:
分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信(TP\TN\FP\FN)
通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型
模型优化
Always check:
1、数据属性的意义,是否为无关数据
2、不同属性数据的数量级差异性如何
3、是否有异常数据
4、采集数据的方法是否合理,采集到的数据是否有代表性
5、对于标签结果,要确保标签判定规则的一致性(统一标准)
Always try:
1、删除不必要的属性
2、数据预处理:归一化、标准化
3、确定是否保留或过滤掉异常数据
4、尝试不同的模型,对比模型表现
Benefits:
1、减少过拟合、节约运算时间
2、平衡数据影响,加快训练收敛提高鲁棒性
3、帮助确定更合适的模型
卷积神经网络
·输入层:输入图像等信息
·卷积层:用来提取图像的底层特征
·池化层:防止过拟合,将数据维度减小
·全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
·输出层:根据全连接层的信息得到概率最大的结果
卷积运算导致的两个问题:
1.图像被压缩,造成信息丢失
2.边缘信息使用少,容易被忽略
通过在图像各边增加像素,使其在进行卷积运算后维持原图大小
通过padding增加像素的数量,由过滤器尺寸与stride决定
1.参考经典的CNN结构搭建新模型(LeNet-5,AlexNet,VGG)
2.使用经典的CNN模型结构对图像预处理,再建立MLP模型
LeNet-5

AlexNet

输入图像:227X227X3RGB图,3个通道
训练参数:约60,000,000个
特点:1、适用于识别较为复杂的彩色图,可识别1000种类别
2、结构比LeNet更为复杂,使用Relu作为激活函数
VGG-16

输入图像:227X227X3RGB图,3个通道
训练参数:约138,000,000个
特点:
1、所有卷积层filter宽和高都是3,步长为1,padding都使用same convolution
2、所有池化层的filter宽和高都是2,步长都是2;
3、相比alexnet,有更多的filter用于提取轮廓信息,具有更高精准性
卷积+池化 成对使用
搭建新模型
加载经典的CNN模型,剥除其FC层,对图像进行预处理
2、把预处理完成的数据作为输入,分类结果为输出,建立一个mIp模型
3、模型训练
实战(一):
建立CNN实现猫狗识别
图片加载:
from keras.preprocessing.image import ImageDataGenerator
#图像增强/预处理配置(数值归一化、缩放、旋转、平移等)
train_datagen =ImageDataGenerator(rescale= 1./255)
#加载图像:
training_set = train_datagen.flow_from_directory('./Dataset/training_set',
target_size =(50, 50),
batch_size= 32,
class_mode ='binary')
建立CNN模型:
from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D,Flatten, Dense
model = SequentialO
# 卷积层
model.add(Conv2D(32, (3, 3), input_shape = (50, 50, 3), activation = 'relu'))
# 池化层
model.add(MaxPooling2D(pool_size =(2, 2))
#第二个卷积、池化层
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size =(2, 2))
# Flattening层
model.add(FlattenO)
#全连接层
model.add(Dense(units =128, activation ='relu')
model.add(Dense(units =1, activation='sigmoid'))
训练与预测:
#配置模型
model.compile(optimizer ='adam', loss ='binary_crossentropy', metrics =['accuracy'_])
#查看模型结构
model.summary()
#训练模型
model.fit_generator(training_set,epochs = 25)
#计算预测准确率
model.evaluate_generator(training_set)
实战(二)
基于VGG16、结合mlp实现猫狗识别
图片加载:
from keras.preprocessing.image import img_to_array, load_img
img_path='1jpg'
img =load_img(img_path, target_size=(224, 224))
img = img_to_array(img)
图片预处理:
from keras.applications.vgg16 import preprocess_input
x= np.expand_dims(img,axis=0)#加维度
#把图片矩阵转化为可用于VGG16输入的矩阵
X = preprocess_input(x)
载入VGG16结构(去除全连接层):
from keras.applications.vgg16 import VGG16
model_vgg = VGG16(weights='imagenet', include_top=False)
特征提取:
features = model_vgg.predict(x)
建立mlp模型:
#建立一个Sequential顺序模型并添加各层
from keras.models import Sequential
model =SequentialO
from keras.layers import Dense
model.add(Dense(units=10, activation='relu', input_dim=25088))
model.add(Dense(units=1, activation='sigmoid'))
model.summaryO
#通过.compileO配置模型求解过程参数
model.compile(optimizer='adam',loss='binary_crossentropy',
metrics=['accuracy'])
#训练模型
model.fit(X_train, y_train, epochs=50)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)