AI 入门先学什么?一条更稳的路线图
网上最显眼的内容,往往是应用层:几句 Prompt、一个 Agent Demo、几小时搭个聊天机器人。这样不是“看过”,而是真的会用。所以,“先学大模型更贴近市场”只对已有编程和建模基础的人更成立。现在岗位更看重你能否把数据、模型、代码、评估和部署串成闭环,而不是知道多少热门名词。如果你已经会 Python、会处理数据、能看懂基本评估,这条路没问题。这一层的重点不是推公式,而是建立判断力:模型为什
很多人学 AI,第一步就走偏了:一上来追大模型、Agent、Prompt。短期很热闹,也能搭出 Demo,但很难做出完整项目。
如果你正在做学术研究,可以升级一下GPT套餐,升级到plus以上,目前Agent、 Deep Research、Codex这种精华功能,只有plus能用。如果不方便可以找靠谱一点渠道升级。 https://gptbuys.com/ 我个人自用的GPT一直是找协助充值的,使用了大半年很稳定。以及 claude、gemini等各大模型API: ZeoAPI
问题通常不是不努力,而是学习顺序错了。现在岗位更看重你能否把数据、模型、代码、评估和部署串成闭环,而不是知道多少热门名词。
一句话结论
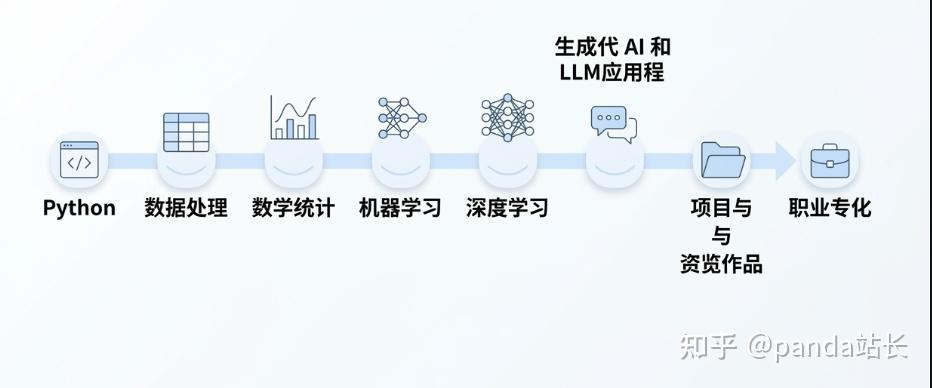
零基础学 AI,最稳的顺序是:Python → 数据处理 → 数学/统计基础 → 机器学习基础 → 深度学习基础 → 生成式 AI/LLM 应用 → 小项目与作品集 → 按岗位分流。
这不是保守,而是多数主流路线图的共识。
核心观点速览
- Python、数据处理、数学统计 应该放在最前面。
- 机器学习基础 仍是 AI 入门的中枢。
- 多数人不是学得慢,而是学得碎,做不成闭环。
- 可靠路线都强调 项目实践和作品集。
- Prompt、RAG、Agent 很重要,但更适合放在基础之后。
为什么不建议一开始就冲大模型

网上最显眼的内容,往往是应用层:几句 Prompt、一个 Agent Demo、几小时搭个聊天机器人。它们反馈快,也容易让人误以为“我已经入门”。
但真正的入门,需要更基础的能力:
- 会 Python,才能读懂训练和推理脚本。
- 会数据处理,才能面对真实世界的脏数据。
- 懂统计和评估,才能判断模型是否真的变好。
- 学过机器学习,才能理解微调、RAG、泛化和评测。
所以,“先学大模型更贴近市场”只对已有编程和建模基础的人更成立。对零基础来说,它很可能只是捷径幻觉。
共识路线图
1. 编程与数据
先学 Python,不必追求语法大全,但要能:
- 写基础函数、循环、条件判断。
- 读写文件。
- 处理表格数据。
- 看懂基础脚本。
- 做简单清洗和可视化。
目标很具体:拿到一个 CSV,你能读进来、筛选、统计,并画出基本图表。
2. 数学与统计思维
不必先啃完整本高数,但至少要理解:
- 概率、分布、均值、方差。
- 特征和标签。
- 训练集、验证集、测试集。
- 过拟合、欠拟合。
- 损失函数和评估指标。
这一层的重点不是推公式,而是建立判断力:模型为什么变好,为什么失效。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

3. 机器学习基础
这是 AI 入门的分水岭。你需要理解:
- 监督学习与无监督学习。
- 分类、回归、聚类。
- 线性回归、逻辑回归。
- 决策树、随机森林。
- 准确率、召回率、泛化能力等指标。
目标不是背算法名词,而是能回答:
- 这是分类、回归还是聚类问题?
- 为什么训练集表现好,测试集却变差?
- 为什么准确率高,不一定代表模型可用?
4. 深度学习基础
这一层开始理解现代模型结构,包括:
- 神经网络。
- 反向传播。
- CNN、RNN 或基础序列模型。
重点不是马上做前沿研究,而是知道现代 AI 模型大致如何工作。
5. 生成式 AI 与 LLM 应用
这时再进入:
- Transformer。
- LLM。
- Prompt。
- 微调。
- RAG。
- 评估与部署。
有了前面的基础,你就不只是记术语,而能判断:
- 什么时候该检索。
- 什么时候该微调。
- 问题出在模型、数据还是流程。
6. 按岗位分流
- AI Developer:偏应用开发与集成。
- AI Engineer:偏系统落地、部署、服务化。
- ML Engineer:偏模型训练、优化、数据管线。
这才更接近真实就业路径。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

关键对比表

| 维度 | 错误的热门入门法 | 共识型基础路线 | 面向 LLM 的延伸路线 | 最终产出 |
|---|---|---|---|---|
| 起点 | 直接学 Prompt、Agent | Python、数据处理 | 基础后再学 Transformer/LLM | 可复用能力 |
| 数学要求 | 基本跳过 | 统计、概率、评估思维 | 理解训练与评测 | 能解释模型效果 |
| 核心中段 | 拼工具、调接口 | 机器学习基础 | 深度学习与生成式 AI | 知识链条完整 |
| 实践方式 | 做几个 Demo | 每阶段配小项目 | 做 RAG、微调、评估、部署 | 形成作品集 |
| 适合人群 | 有技术背景者 | 零基础、学生、转行者 | 想做 NLP/LLM 应用者 | 更贴近岗位要求 |
| 常见风险 | 概念多,闭环弱 | 入门略慢,后劲强 | 跳过基础会失真 | 减少返工 |
更值得执行的学习顺序
1)先把 Python 学到“能处理数据”
重点不是全学会,而是达到最低闭环:
- 基础语法。
- 文件读写。
- 列表、字典等数据结构。
- 用 Python 清洗简单数据。
- 看懂基础脚本。
2)补数据处理和统计直觉
这一步常被低估。现实中很多问题出在数据上,而不是模型不够强。
重点理解:
- 缺失值、异常值。
- 数据分布。
- 训练/验证/测试集拆分。
- 基础可视化。
- 过拟合与欠拟合。
3)用机器学习建立“模型思维”
至少完整做一遍:
- 选一个真实数据集。
- 训练一个分类或回归模型。
- 做验证和评估。
- 解释结果。
只要完整跑通一次,很多概念就不再抽象。
4)再进入深度学习与 LLM 项目
有了基础后,再做 LLM 小项目更容易形成真正能力。可以尝试:
- 文本分类增强。
- 简单问答。
- 基础 RAG。
重点不是炫功能,而是把数据、模型、评估、结果串起来。
争议点与常见问题 FAQ
Q1:现在还学传统机器学习,有必要吗?
有,而且很有必要。
原因有两点:
- 很多业务不需要大模型。 例如结构化数据预测、推荐排序、风控评分、异常检测,传统 ML 依然高效。
- 机器学习是理解现代 AI 的底层语法。 不懂训练、评估、泛化、偏差与方差,就很难理解 LLM 为什么会失效。
传统 ML 不是过时了,而是变成了更重要的基础层。
Q2:能不能先学 Prompt、RAG、Agent,边做项目边补基础?
可以,但不适合多数零基础。
如果你已经会 Python、会处理数据、能看懂基本评估,这条路没问题。
但如果完全零基础,常见后果是:
- 项目能跑,但改不动。
- 名词知道不少,但解释不清。
- 一遇到数据和效果问题就卡住。
更合理的方式不是“学完全部基础再碰项目”,而是:基础和小项目同步推进,但整体顺序不要颠倒。
行动清单
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

如果你是零基础,直接按这 4 步走:
- 第 1 步:用 7 天补齐 Python 最小闭环 目标是能读写文件、处理表格、写基础函数。
- 第 2 步:用一个真实数据集做清洗和分析 学会看分布、做可视化、拆分训练集。
- 第 3 步:训练第一个机器学习模型 哪怕只是基础分类或回归,也要完整走一遍训练、验证、评估流程。
- 第 4 步:有 ML 基础后再做一个 LLM 小项目 例如基础问答、文本分类增强或简单 RAG。重点是形成闭环,不是堆热词。
结论
AI 入门最贵的成本,不是学得慢,而是一开始把顺序学反了。
如果你想把 AI 学成可交付的能力,就别从最热的地方起步。先搭好底层能力,再学大模型、RAG、Agent。这样不是“看过”,而是真的会用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)