【AI应用开发框架】大语言模型(LLM)
本篇本章主要介绍了大语言模型的几种接入方式,以及认识嵌入模型,嵌入模型的应用场景以及嵌入模型和大语言模型的区别,嵌入模型的接入方式。最后介绍了两种开源的模型平台。

背景
当我们自己构建AI应用时,无法直接使用大语言模型的客户端,那么就需要我们通过代码的方式,接入原生LLM的方式
1. LLM的接入方式
常见的原生LLM接入的方法主要有三种:API远程调用,本地部署,SDK和官方客户端库。
1.1 API接入
这是最主流、最便捷的接入方式,适用于快速开发、集成到现有应用的场景。
通过HTTP请求直接调用模型提供方部署在云端的大语言模型服务。
流程:
- 注册账号并获取API Key: 在模型的提供商平台注册,获取用户验证的密钥。
- 查阅API文档: 了解请求的端点、参数(模型名称,提示词,最大生成长度)和返回数据格式。
- 构建HTTP请求: 在我们的代码中,使用http客户端库构建一个包含API Key(通常在Header中)和请求体(JSON格式,包含我们的提示和参数)的请求。
- 发送请求并处理响应: 将请求发送到提供方指定的API地址,并解析返来的JSON数据,提取生成文本。
1.2 本地部署
大模型本地部署,这种是将开源的大语言模型部署在我们自己的硬件环境中(本地服务器或者私有云)。核心概念是:将下载模型的文件(权重和配置文件),使用专门的推理框架在本地服务器或GPU上加载并运行模型,然后用类似API的方式进行交互。
流程:
-
获取模型: 从Hugging Face(国外)、魔塔社区(国内)等平台下载开源模型的权重。
-
准备环境: 配置具有足够显卡(NVIDIA GPU)的服务器,安装必要的驱动和推理框架。
-
选择推理框架: 使用专为生产环境设计的框架来部署模型,例如:
vLLM: 注重高吞吐量的推理服务,性能极佳。
TGI: Hugging Face推出的推理框架,功能比较全面。
Ollama: 非常用户友好,可以一键拉取并运行模型,适合快速入门和本地开发。
LM Studio: 提供图形化界面,让本地使用模型像使用软件一样简单。 -
启动服务并调用: 框架会启动一个本地API服务器,我们可以像调用云端API一样向这个本地地址发送请求。
1.3 SDK接入
SDK方式接入大语言模型,本质上就是:不用我们自己手搓HTTP请求,而是 通过官方或者第三方提供的开发包(SDK)来调用模型的能力。
- API = 服务接口(底层是HTTP)
- SDK = 对API的封装(更方便开发)
比如我们直接调用API:
POST /v1/chat/completions
Authorization: Bearer xxx
Content-Type: application/json
{
"model":"xxx",
"messages":[
{"role":"user","content":"你好"}
]
}
而SDK会帮我们封装成:
client.chat("你好");
1.4 问题与思考
对于以上的三种接入模式,我们应该如何选择?
- 数据敏感性: 如果我们要处理的数据及其的敏感,我们就选择本地部署的模式,可以保证我们数据的安全。
- 技术实力和资源: 如果我们的团队没有足够强大的MLops(机器学习运维)能力,也没有足够预算购买GPU服务器,云端API是一个非常不错的选择。
- 成本和规模: 如果应用规模很大 ,长期来看,本地部署的固定成本可能低于持续的API调用费用。反之,小规模调用API更加划算。
- 定制需求: 如果我们只是使用模型的通用能力,云端的API已经足够。如果需要用自己的数据微调模型,则需要选择支持微调的API或直接本地部署。
实际上,只要是原生的LLM,无论我们怎样接入都会有限制。
- 输入长度的限制: 所有的LLM都有固定的输入长度(如4k,8k,128k,400k Token)。我们无法将几百页的pdf或者整个公司的知识库交给模型。
- 缺乏私有知识: 模型的训练数据有截至日期,且不包含我们的私人数据(如公司的文档,个人笔记等)。让模型基于这些只是进行问题的回答是非常的困难的。
- 复杂任务处理能力弱: 原生的API本质上是一个“一问一答”的接口。对于需要多个步骤的复杂任务,我们需要编写复杂的逻辑来拆解任务,多次调用API并管理中间状态。
- 输出格式不可控: 虽然我们可以通过提示词来要求模型按照一定格式的方式输出,但是它仍可能产生格式错误或者不合规的内容,需要我们自己编写代码来校验和清洗。
Langchain这样的框架,正是为了系统性的解决这些问题而诞生的。
2. 认识嵌入模型
2.1 什么是嵌入模型?
嵌入模型,我们可以理解成为:把我们人类能读懂的内容(文本、图片、代码)转化成机器更容易计算和比较的向量。
说的更直白一点就是:大模型擅长生成,嵌入式模型擅长理解和表示。
举个例子:
比如下面的这三句话:
今天天气真好
今天阳光不错
我想吃烧烤
在我们看来,这三句话的前两句意思相近,第三句完全不同,但是在机器看来,只是一堆的字符串。它并不知道语义关系。
嵌入模型会把他们变成向量:
[0.12 , -0.33 , 0.89 , …]
[0.10 , -0.30 , 0.85 , …]
[-0.77 , 0.91 , -0.22 , …]
然后通过向量距离来判断:
- 前两个向量的距离近 -> 语义相似
- 第三个距离远 -> 语义不同
这就是 Embedding 的核心。
2.2 嵌入模型的应用场景
-
语义搜索
传统搜索:依赖的是关键词匹配(搜”苹果“,只能找到包含“苹果”这个词的文档)。
语义搜索:则将我们要查询的词和匹配的文档都转化为向量的形式,通过计算向量间的相似度来查找相关的内容,即使文档中没有确切的词也能被检索到。 -
知识库问答(RAG)
这是当前大语言模型应用的核心模式。当用户向LLM提问时,系统首先使用嵌入模型在知识库中进行语义搜索,找到相关的内容,然后将这些内容和问题一起交给LLM来生成答案。这可以极大的提高答案的准确性和时效性。 -
推荐系统
将我们用户(根据历史行为、偏好)和物品(商品、电影、新闻)都转化为向量。喜欢相似物品的用户,其向量会接近。相似的物品,向量也会接近。通过计算用户和物品向量的相似度,就可以进行精准推荐。 -
异常检测
正常数据的向量通常会聚集在一起。如果新数据的向量远离大多数向量的聚集区,他就可能是一个异常点(如垃圾邮件、异常交易)。
例如:一个信用卡交易反欺诈系统,通过学习海量的正常交易(如金额、地点、时间、商户类型等特征的向量)形成一个正常交易的向量聚集区。当有一天有一笔新的交易的时候,系统将其转化为向量。如果该向量出现在正常交易向量聚合区之外(如:一笔发生在通常交易地之外的一笔高额交易),系统就会将其标记为潜在的欺诈交易并进行报警。
2.3 和大语言模型的区别
| 模型类型 | 作用 |
|---|---|
| LLM | 生成内容 |
| Embedding | 表示内容 |
一个负责说话,一个负责理解
2.4 常见嵌入模型
- OpenAI的text-embedding系列
- Qwen3-Embedding-8B(阿里巴巴)
- gemini-mebedding-001(Google)
2.5 嵌入模型接入方式
嵌入模型的接入方式和使用方式根据模型的类型(闭源或开源)有根本性的不同。
下图清晰的展示了两种典型的接入流程: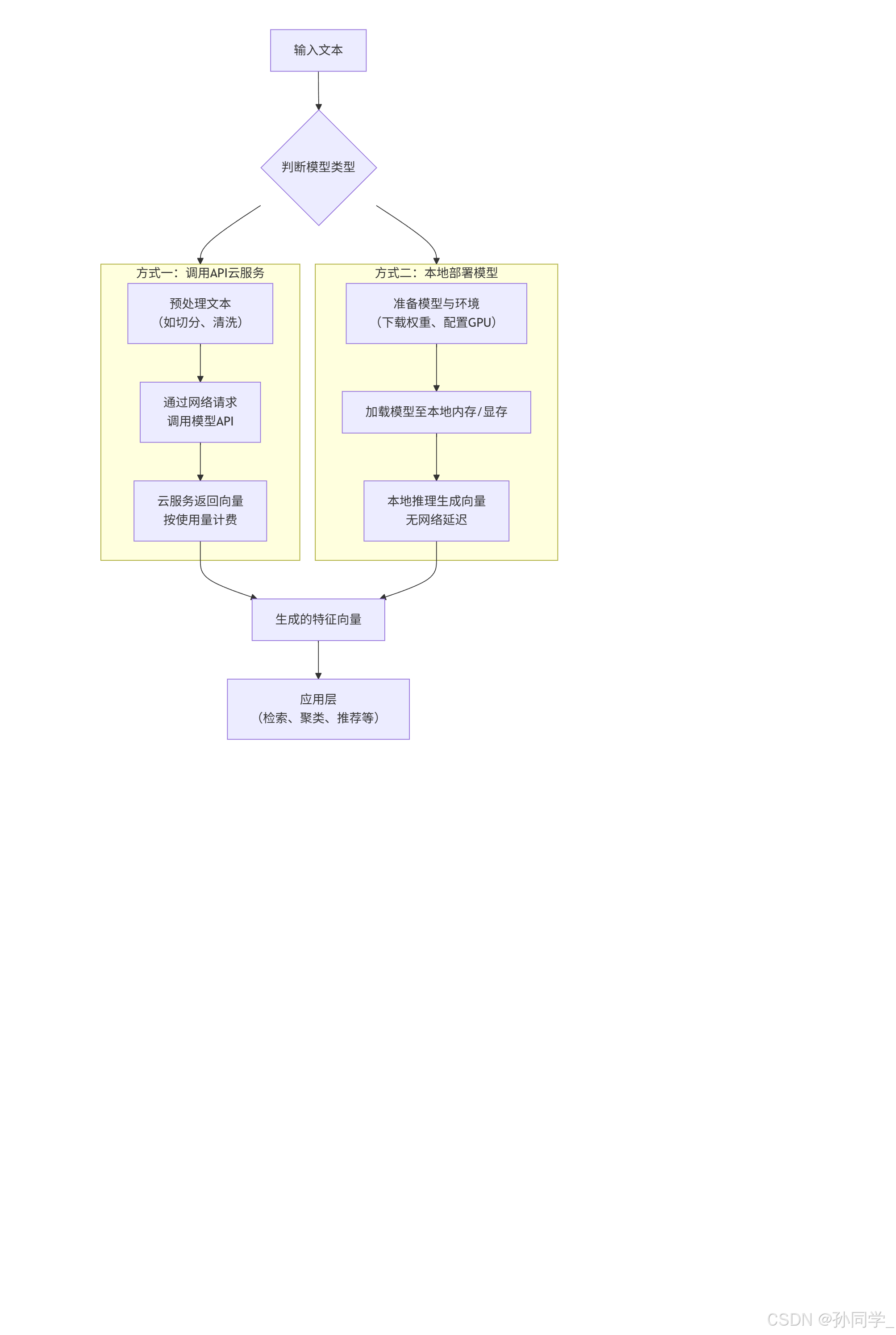
2.5.1 API接入(闭源)
这是最快速,最简单的方式,无需管理任何基础设施。只需要向模型提供商的服务端发送一个HTTP的请求即可。
通用步骤:
- 注册账号并获取API Key: 在对应的云服务平台上注册账号,获取用于身份验证的API Key.
- 安装SDK或者构建HTTP请求: 使用官方提供的SDK(如open ai)或者直接构造HTTP请求。
- 调用API并处理响应: 发送文本,接收返回的JSON格式的向量数据。
流程:
客户端 -> Embedding API -> 返回向量
示例1:发起HTTP请求
curl https://api.openai.com/v1/embeddings
-H "Content-Type: application/json"
-H "Authorization: Bearer $OPENAI_API_KEY"
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'
收到响应:响应包含嵌入向量(浮点数列表)以及一些其他元数据:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
2.5.2 本地接部署(模型下载到本地)
直接在本地跑Embedding模型。这种方式需要自行准备计算资源(通常是带有GPU的机器)来运行模型。适合对数据隐私、成本和控制权有更高要求的场景。
通用步骤:
- 环境准备: 准备一台有足够GUP的显存服务器(对于Qwen3-Embedding-8B,需要至少16GB以上的显存)
- 模型下载: 从Hugging Face等模型仓库下载模型的权文件和配置文件。
- 代码集成: 使用像transformers这样的库来加载模型并进行推理。
3. 模型平台
- Hugging Face(国外)
Hugging Face 是⼀个知名的开源库和平台,该平台以其强大的Transformer 模型库和易用的 API 而闻名,为开发者和研究人员提供了丰富的预训练模型、工具和资源。对于从事 AI 研究的人来说,其重要性不亚于 GitHub。
官方网站:Hugging Face
- 魔塔社区(国内)
魔搭(ModelScope)是由阿里巴巴达摩院推出的开源模型即服务(MaaS)共享平台,汇聚了计算机视觉、自然语言处理、语⾳等多领域的数千个预训练 AI 模型。其核心理念是"开源、开放、共创",通过提供丰富的工具链和社区生态,降低 AI 开发门槛,尤其为企业本地私有化部署提供了一条高效路径。
官方网站:魔塔社区

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)