你的AI是怎么学会新技能的?深挖ClawHub这台“技能自动贩卖机“的底层密码
回到文章开头的那个场景——你的 AI 助手突然学会了点咖啡。这背后发生的一切,本质上是 ClawHub 这台"技能自动贩卖机"在默默运转:有人在某个角落写好了技能文件,上传到注册表;向量搜索引擎把它编入了语义索引;安全扫描确认它没有问题;你的 AI 通过 CLI 发现了这个新技能,下载、安装、生效。整个过程快到你几乎感知不到,但每一步都有扎实的工程底座在支撑。AI 的能力边界,不只取决于模型有多大
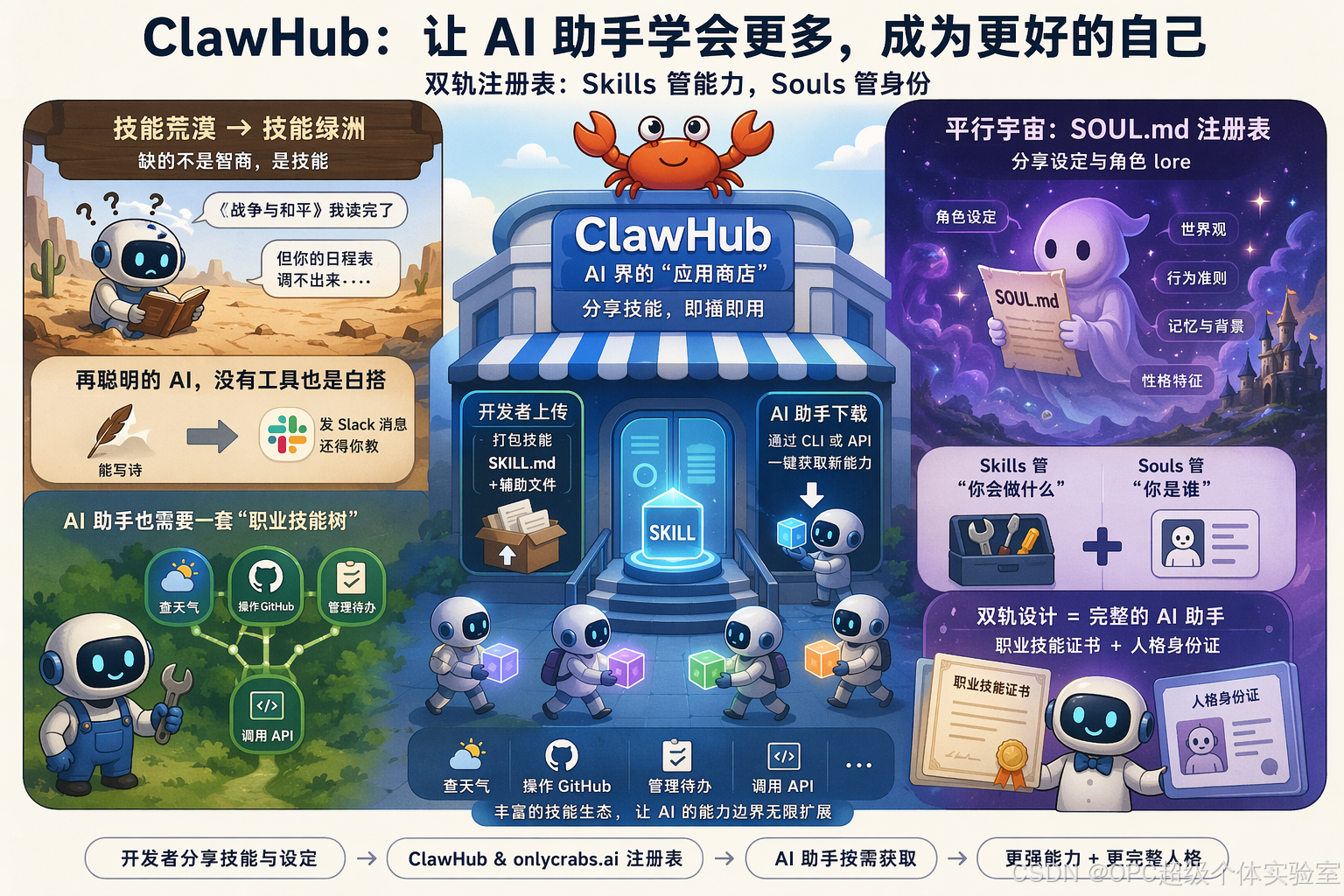
想象一下:某天早上,你对你的AI助手说"帮我订一杯咖啡",它愣了两秒,然后坦白——"不好意思,我不会这个。"你叹了口气,心想这货连点咖啡都不会,还能干啥?但十秒钟后,它突然说:"等等,我刚从ClawHub学了一个新技能,现在可以试试。"下一秒,你的订单确认邮件已经躺在收件箱里了。这台"技能自动贩卖机"到底是怎么运作的?今天咱们就掀开它的后盖,看看里面藏着哪些工程密码。
一、从一个"技能荒漠"说起
在AI助手刚火起来的那阵子,大家都沉浸在一个美好的幻觉里:觉得只要模型够大、参数够多,AI就能无所不能。但现实很快就给了当头一棒——再聪明的脑子,没有"工具"也是白搭。你的AI可能熟读《战争与和平》,却连你的日程表都调不出来;它能写十四行诗,但帮你发个 Slack 消息却得靠你手把手教。
问题出在哪?缺的不是智商,是技能。
就像人类社会中,医生会做手术、厨师会颠勺、程序员会写 Bug(哦不,是写代码),AI助手也需要一套"职业技能树"。但问题是,这些技能该放在哪儿?怎么管理?怎么让AI像逛超市一样,按需取用、即插即用?
这时候,ClawHub 登场了。
ClawHub 是 OpenClaw 生态的公共技能注册表,你可以把它理解成 AI 界的"应用商店"——只不过这里不卖游戏和短视频,而是卖各种各样的"本领"。开发者把技能打包成一个 SKILL.md 文件加上若干辅助文件,上传到 ClawHub,其他 AI 助手就能通过 CLI 或者 API 把这些技能"下载"到本地,瞬间获得新能力。从查天气到操作 GitHub,从管理待办事项到调用第三方 API,ClawHub 让 AI 的"技能荒漠"变成了一片绿洲。
更妙的是,ClawHub 还兼顾了另一套平行宇宙——SOUL.md 注册表(托管在 onlycrabs.ai 上),专门用来分享系统设定和角色 lore。Skills 管"你会做什么",Souls 管"你是谁"。这个双轨设计,怎么看怎么像给 AI 助手同时配了"职业技能证书"和"人格身份证"。
二、技术架构:不是"大而全",而是"巧而精"
打开 ClawHub 的代码库,第一眼可能会让你觉得"这人是不是把一辈子的技术债都堆在这儿了"——Convex 函数上百个、表结构几十张、前端路由层层叠叠。但别被表象吓住,仔细品味之后你会发现,这套架构的精髓恰恰在于**"克制"与"分层"**。
2.1 前端:TanStack Start 的"轻快舞步"
ClawHub 的前端选用了 TanStack Start,一个在 React 社区里逐渐崭露头角的元框架。很多人可能会问:为啥不用 Next.js?那玩意儿不是更火吗?
答案藏在 ClawHub 的产品气质里。这个平台要的不是一个重型的"企业级中台",而是一个轻快、流畅、有 SPA 手感的浏览体验。TanStack Start 基于 Vite 和 Nitro,冷启动快得像闪电侠喝咖啡,路由系统基于文件自动生成(看看 src/routeTree.gen.ts 就知道了),而且自带预加载和乐观更新——用户点一下链接,页面内容几乎是瞬移过来的。
更值得一提的是,ClawHub 前端还玩了一手"双面人生":同一个代码库,根据访问的域名不同(clawhub.ai 还是 onlycrabs.ai),会切换成 Skills 模式或 Souls 模式。首页的 SLOT_WORDS 数组里塞满了 "Equip"、"Install"、"Unleash"、"Hack" 这类动词,像一台自动旋转的霓虹灯牌,每次刷新都换一种态度跟你打招呼。这种细节,说大不大,但恰恰体现了团队对"产品气质"的执着。
2.2 后端:Convex 的"实时魔法"
如果说前端是舞台,那 Convex 就是那个会变魔术的后台。ClawHub 把整个后端——数据库、文件存储、HTTP 路由、定时任务——全部交给了 Convex。这在传统架构里可能需要拆成五六七八个服务:一个 Postgres 管数据、一个 S3 管存储、一个 Express/FastAPI 管接口、一个 Redis 管缓存、一个 Cron 服务管定时任务……但在 Convex 的世界里,这些东西被装进了一个统一的"黑匣子"。
Convex 的核心哲学是**"实时同步"**。你写一条数据,订阅这条数据的客户端会立刻收到更新,不需要你手动去轮询或者搞 WebSocket。对于 ClawHub 这种需要展示"最新技能"、"实时评论"、"下载统计"的平台来说,这简直是量身定制。
但 Convex 也不是银弹。它的查询模型有一些独特的"脾气"——比如没有字段投影,读一行就是读一整行;比如 .filter() 会带来全表扫描的灾难;比如单次查询有 32K 文档的硬上限。ClawHub 的工程师们显然深谙这些门道,整个代码库里随处可见 .withIndex() 的身影,索引设计之密集,简直像是在数据库上织了一张精密的蜘蛛网。
三、核心实现:那些藏在代码里的"工程心机"
如果说架构是骨架,那核心实现就是血肉。ClawHub 的代码里有几处特别值得细细品味的工程设计,每一处都透着"老江湖"的气息。
3.1 搜索:当向量语义遇上"老派"词法
搜索,是 ClawHub 的命门。用户想找"一个能操作 GitHub 的技能",他可能会输入 "github",也可能输入 "代码仓库",甚至可能输入 "帮我管管我的项目"。传统的关键词匹配在这时候就显得力不从心——你总不能指望用户每次都能精准命中技能名称吧?
ClawHub 的解法是**"混合搜索"**——把向量语义搜索和词法搜索拧成一股绳。
具体怎么玩?当用户输入查询词时,系统会同时启动三条战线:
第一战线:向量语义搜索。 借助 OpenAI 的 text-embedding-3-small 模型,把查询词转成 1536 维的向量,然后在 Convex 的向量索引里找"最相近"的技能嵌入。这一步负责理解用户的"意图"——哪怕用户说的词和技能描述里的词完全不一样,只要语义相近,就有可能被捞回来。
第二战线:前缀匹配。 如果用户输入的是一个类似 slug 的短词(比如 "github"),系统会直接去 skillSearchDigest 表里做前缀扫描,把slug或显示名称匹配上的结果迅速捞出来。这一步胜在快、准、狠。
第三战线:词法回退。 如果前两步加起来还不够数,系统会启动一次兜底扫描,在最近的活跃技能 digest 里做逐词匹配。这一步虽然慢一些,但能保证"不漏"。
三条战线的结果会被合并、去重、打分,最后按一个综合分数排序返回给用户。打分公式里也藏着小心机:向量相似度占大头,但 slug 精确匹配会给 2.5 倍的额外加成,名称匹配也有 1.1 倍加成,下载量还会通过一个对数函数贡献一点" popularity 加成"。换句话说,一个新上线的优质技能不会因为还没积累下载量就被彻底埋没,但那些久经考验的热门技能也确实能享受到一点"老玩家福利"。
更妙的是,搜索的 hydration 过程被极致优化了。Convex 读文档是按整行收费的,而 skillEmbeddings 表里每行 embedding 足足有 12KB。ClawHub 的工程师们为了省钱,专门建了一张 embeddingSkillMap 表——只有约 100 字节一行,专门用来把 embeddingId 映射到 skillId。搜索时先读这张"轻量地图",再去读 skillSearchDigest(约 800 字节一行),最后万不得已才去碰完整的 skills 表(3-5KB 一行)。这种"层层剥洋葱"式的查询策略,说到底就是一个字:省。省带宽、省 latency、省账单。
// 搜索打分的核心逻辑:向量分 + 词法加成 + popularity 加成
function scoreSkillResult(
queryTokens: string[],
vectorScore: number,
displayName: string,
slug: string,
downloads: number,
) {
const lexicalBoost = getLexicalBoost(queryTokens, displayName, slug);
const popularityBoost = Math.log1p(Math.max(downloads, 0)) * POPULARITY_WEIGHT;
return vectorScore + lexicalBoost + popularityBoost;
}
3.2 Schema 设计:一张表里的"千层饼"
翻开 convex/schema.ts,你会有种走进图书馆索引室的错觉——每一张表都贴着密密麻麻的索引标签,仿佛生怕漏掉任何一种查询姿势。
以 skills 表为例,这张表承载了技能的核心元数据,但同时也是一个"千层饼":
-
版本管理:
latestVersionId指向最新版本,tags是一个 map,可以把任意字符串标签(比如latest、stable)绑定到某个具体版本上。回滚版本?简单,把latest标签挪到旧版本就行。 -
审核状态:
moderationStatus标记 active/hidden/removed,badges记录官方认证、高亮推荐、废弃标记等状态。 -
安全扫描:
vtAnalysis(VirusTotal 扫描)、llmAnalysis(LLM 风险评估)、staticScan(静态代码扫描)三个字段并排而立,仿佛三个保安同时盯着每个技能。 -
统计双写:
statsDownloads、statsStars等顶层字段和嵌套的stats.downloads、stats.stars同时存在。这是在进行中的字段迁移——新代码读顶层字段,老数据还靠嵌套字段兜底。
索引设计更是教科书级别。ClawHub 不仅给 slug、ownerUserId 这类高频查询字段建了索引,还给各种组合查询预建了索引:按 owner + 活跃状态 + 更新时间排序、按下载量排序、按 stars 排序、按"非可疑"状态过滤后再排序……甚至连 normalizedSlugFirstToken 这种用于前缀搜索的派生字段都单独建了索引。这种"索引即产品"的思路,让人不禁想起那句话:**"在 Convex 里,慢查询不是技术问题,是经济问题。"**
3.3 安全体系:给 AI 技能配了"三道安检门"
如果说技能注册表是机场,那 ClawHub 显然不是一个"随到随走"的小站。每个上传的技能都得过三道安检门:
第一道:静态扫描。 系统会解析 SKILL.md 里的 frontmatter,检查元数据是否完整、依赖声明是否规范、文件类型是否符合要求(只允许文本文件,总大小不超过 50MB)。如果 frontmatter 里声明了需要 TODOIST_API_KEY,但代码里偷偷访问了别的环境变量,扫描就会报 "metadata mismatch"。
第二道:VirusTotal 扫描。 技能文件会被送去做恶意软件检测,返回 malicious / suspicious / undetected / harmless 四个维度的评分。
第三道:LLM 风险评估。 这是最有意思的一环。系统会让大模型去审阅技能内容,从三个维度给出风险评估:abnormal_behavior_control(异常行为控制)、permission_boundary(权限边界)、sensitive_data_protection(敏感数据保护)。如果发现某个技能试图越权操作系统文件或者悄悄外传数据,LLM 会给出 "concern" 级别的警告,并附上具体的代码片段和解释。
三道门都过了,技能才能安心上架。即便如此,平台还设置了"软删除"机制——owner、moderator 和 admin 都可以随时把有问题的技能下架,而不是直接物理删除。这种"留有余地"的设计,既保护了用户,也给开发者留下了申诉和修复的空间。
3.4 版本管理与重命名:让"搬家"不丢快递
在传统的包管理器里,重命名一个包往往是件伤筋动骨的事——旧链接失效、依赖断裂、用户找不到北。ClawHub 在这个问题上做了非常贴心的设计:
技能重命名时,旧 slug 会被保留在 skillSlugAliases 表里,继续作为重定向别名存在。用户访问旧链接,会被无缝导向新地址,就像邮局转发邮件一样自然。
技能合并时,源技能会被隐藏,其 slug 同样变成目标技能的重定向别名。两套技能的历史版本、评论、星标,都归并到目标技能名下。
所有权转移也被设计成了一个完整的"握手协议":发起方提出申请,接收方可以选择接受、拒绝或者放着不管。整个过程被记录在 skillOwnershipTransfers 表里,配合审计日志,谁也赖不了账。
这些设计看起来像是"边缘功能",但对于一个长期运营的注册表来说,它们决定了平台是"能用"还是"好用"。毕竟,谁也不想自己辛苦积累的技能因为一次改名就人间蒸发。
四、CLI:开发者的"瑞士军刀"
光有一个漂亮的网站是不够的。ClawHub 真正的"主战场"其实在命令行里。
clawhub CLI 是开发者与注册表交互的主要界面。它的设计哲学可以概括为:**"在终端里完成一切"**。从登录认证到搜索浏览,从安装更新到发布同步,几乎所有操作都能通过几行命令搞定。
几个特别实用的设计:
-
**
clawhub sync**:扫描本地目录里所有包含SKILL.md的文件夹,自动检测变更并上传新版本。对于同时维护多个技能的开发者来说,这简直是救命稻草——再也不用逐个手动发布了。 -
指纹比对更新:
clawhub update会先计算本地文件的 SHA-256 指纹,和注册表里的版本比对。如果本地文件被改过但还没发布,CLI 会默认拒绝覆盖,除非你显式加--force。这种"谨慎覆盖"的策略,有效避免了"手滑把本地修改冲掉"的悲剧。 -
多源发布:
clawhub package publish支持从本地文件夹、GitHub 仓库、甚至 npm tarball 直接发布插件。配合 GitHub Actions 的可复用工作流,整个 CI/CD 链路可以全自动跑通。
CLI 和注册表之间的 API 通信基于一套精心设计的 V1 HTTP API,路径以 /api/v1/ 为前缀,涵盖了 skills、souls、packages、stars、transfers、users 六大资源域。每个路由都严格区分 GET/POST/DELETE,返回结构统一,错误码清晰。这套 API 不仅供 CLI 使用,也向第三方开放,让 ClawHub 有机会成为更广泛的生态基础设施。
五、我们能从 ClawHub 身上学到什么?
读完整套代码,我最深的感受不是"这技术真牛",而是**"这帮人真懂取舍"**。
5.1 "够用就好"的选型智慧
ClawHub 没有追新潮去搞微服务,也没有为了"云原生"而云原生。一个 Convex 包打天下,前端用一个 TanStack Start,CLI 用 Node/Bun 生态,就这么简单。这种"够用就好"的选型哲学,让团队可以把精力集中在产品逻辑上,而不是浪费在infra的泥潭里。
5.2 "省钱即架构"的性能观
在 Convex 这样的按量计费平台上,性能优化和成本控制是一枚硬币的两面。ClawHub 的工程师们把这一点刻进了 DNA 里:
-
用
skillSearchDigest做轻量级投影,避免读完整的 skill 文档。 -
用
embeddingSkillMap做 embedding 到 skill 的映射,避免读 12KB 的向量文档。 -
用 cursor-based 分页代替
skip(),用增量回溯代替全表扫描。 -
统计数据双写 + 事件溯源,既保证了查询速度,又保留了审计能力。
这些优化单独看都不起眼,但堆在一起,就能让一个 16K 行的表从"每次查询读 16MB"变成"每次查询读几KB"。在规模上去之后,这就是生与死的区别。
5.3 "安全不是事后补丁"
ClawHub 把安全扫描做进了发布流程的"必经之路",而不是作为一个可选的"增值服务"。静态扫描、VT 检测、LLM 风险评估三道门,加上 comment 和 skill 的 scam scan(防诈骗检测),构建了一个纵深防御体系。更值得称道的是,这些安全能力不是黑箱运行的——扫描结果会写入 skillVersions 表的各个分析字段,owner 和 moderator 都能看到具体的 findings 和 evidence。
六、未来:当"技能"成为 AI 的通用货币
ClawHub 目前已经是 OpenClaw 生态中不可或缺的一环,但它的野心显然不止于此。
从代码中透露的蛛丝马迹来看,未来的演进方向至少包括这几个维度:
插件生态的扩张。 packages 和 packageReleases 两张表已经支持 code-plugin 和 bundle-plugin 两种新的 package family,这意味着 ClawHub 正在从"纯文本技能"向"可执行代码插件"延伸。配合 openclaw.compat.pluginApi 和 openclaw.build.openclawVersion 的兼容性声明,一个真正的"AI 插件市场"正在成型。
信任体系的升级。 packageVerification 字段里已经预留了 structural、source-linked、provenance-verified、rebuild-verified 四个验证层级。未来,官方插件可以通过源码关联和可重复构建来证明"我就是你看到的样子",这对于企业级部署来说至关重要。
搜索的进一步智能化。 目前的混合搜索已经是业内领先的水平,但随着技能数量增长,向量索引的召回率和 latency 还会面临新的挑战。引入多向量索引、查询重写、甚至是用户行为反馈的 learning-to-rank,都是可能的下一步。
跨平台协同。 OpenClaw 的长期愿景里提到了 macOS、iOS、Android、Windows、Linux 的 companion app。ClawHub 作为技能分发的核心枢纽,必然要在多平台同步、离线缓存、增量更新等方面做更多功课。
七、写在最后
回到文章开头的那个场景——你的 AI 助手突然学会了点咖啡。这背后发生的一切,本质上是 ClawHub 这台"技能自动贩卖机"在默默运转:有人在某个角落写好了技能文件,上传到注册表;向量搜索引擎把它编入了语义索引;安全扫描确认它没有问题;你的 AI 通过 CLI 发现了这个新技能,下载、安装、生效。整个过程快到你几乎感知不到,但每一步都有扎实的工程底座在支撑。
ClawHub 告诉我们一个道理:AI 的能力边界,不只取决于模型有多大,还取决于生态有多开放、分发有多高效、信任有多牢固。 当技能可以像商品一样被生产、被检索、被交易、被评价,AI 助手才真正从一个"聪明的聊天机器"进化成了一个"有手艺的数字工匠"。
而这台贩卖机的"厂工们"——那些写在 schema 里的索引、藏在搜索函数里的打分逻辑、嵌在版本控制里的重定向规则——正是让这一切 smoothly 运转的幕后英雄。它们不显眼,但缺了谁都不行。
下次当你的 AI 又学会了一个新把戏,不妨在心里给它背后的这台机器点个赞。毕竟,学会新技能这件事,从来都不是一个人的战斗。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)