【YOLO】
YOLO:一个目标检测算法 (使ai理解物体在空间当中的存在方式)传统目标检测方式:R-CNN,Fast R-CNN,Faster R-CNN这些方法都是先找到东西,再进行分类,耗时长、步骤多,对于算力的要求极高;而YOLO,速度快,精确度也非常高YOLO的运行机制:统一建模,划分出最合适的格子,依靠置信度(判断预测是否准确)去预测物体;采用NMS(非极大值抑制):去掉重复框.(一)归一化混淆矩阵
YOLO:一个目标检测算法 (使ai理解物体在空间当中的存在方式)
传统目标检测方式:R-CNN,Fast R-CNN,Faster R-CNN 这些方法都是先找到东西,再进行分类,耗时长、步骤多,对于算力的要求极高;而YOLO,速度快,精确度也非常高
YOLO的运行机制:统一建模,划分出最合适的格子,依靠置信度(判断预测是否准确)去预测物体;采用NMS(非极大值抑制):去掉重复框.
(一) 归一化混淆矩阵:机器学习里专门用来 “给模型打分” 的成绩单
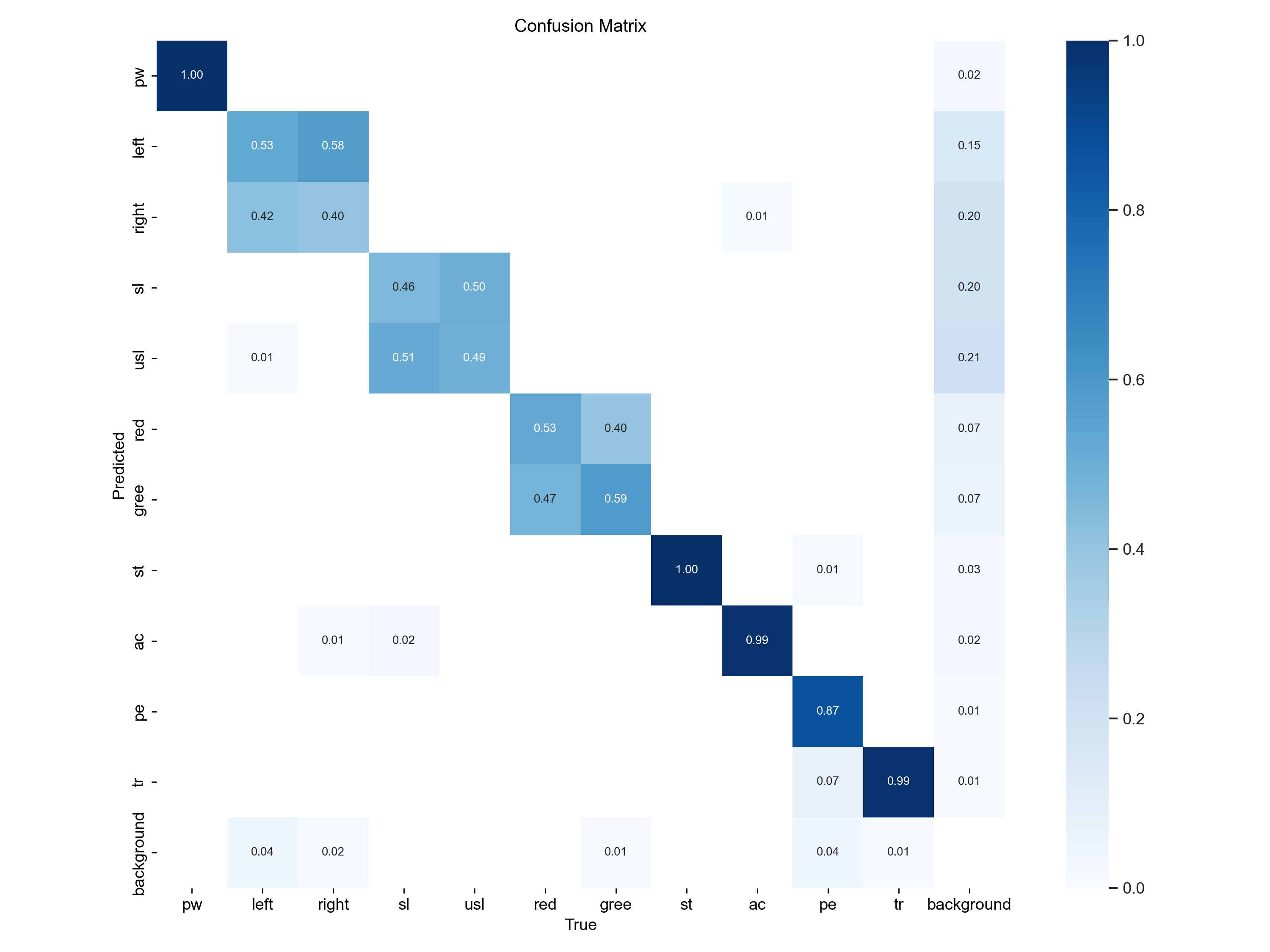 核心作用:告诉我们在这个分类模型中,哪些类别认得准、哪些类别经常认错、谁和谁最容易搞混。
核心作用:告诉我们在这个分类模型中,哪些类别认得准、哪些类别经常认错、谁和谁最容易搞混。
形式:一个 行 × 列 的表格,加上颜色深浅来辅助我们看清楚数值大小。
纵轴(Predicted,预测值),横轴(True,真实值)
数字范围:0~1(0%~100%),颜色越深,数字越大。
(二) F1-Confidence Curve(F1 值 - 置信度曲线)
——评估分类模型在不同置信度下的性能表现的图
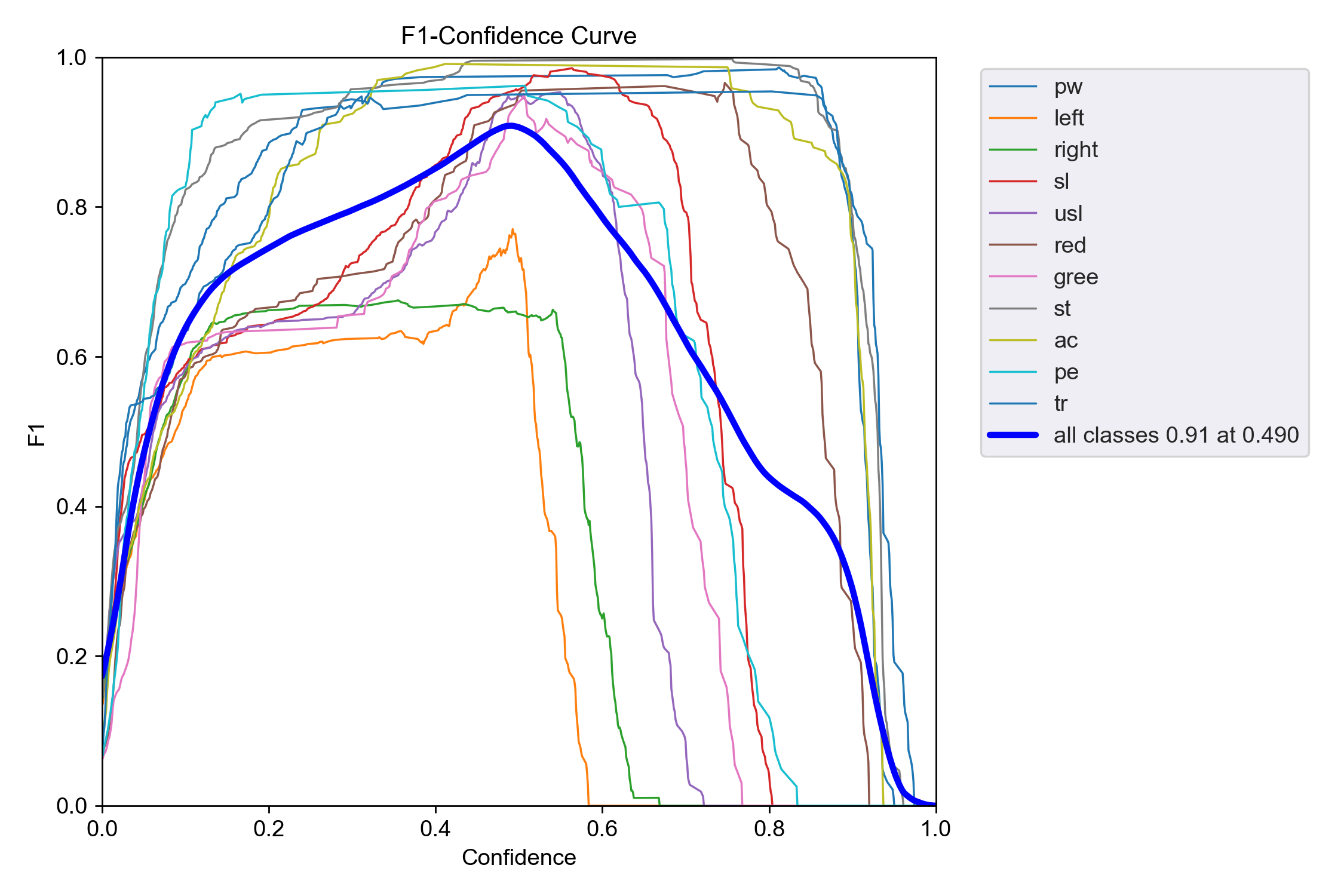
- 横轴:Confidence(置信度),就是模型对自己预测结果的 “自信程度”,从 0(完全没把握)到 1(100% 确定)。
- 纵轴:F1 值,是模型分类性能的综合指标,范围 0~1,越接近 1,说明分类效果越好。
- 每条彩色线:代表一个类别在不同置信度下的 F1 值变化。
- 那条粗蓝线:是所有类别的平均表现,图里标了 “all classes 0.91 at 0.490”,意思是:当置信度设为 0.490 时,所有类别的平均 F1 值达到了 0.91,这是模型整体的最佳平衡点。
(三) 由 4 小图组成的数据集 / 数据分布分析面板
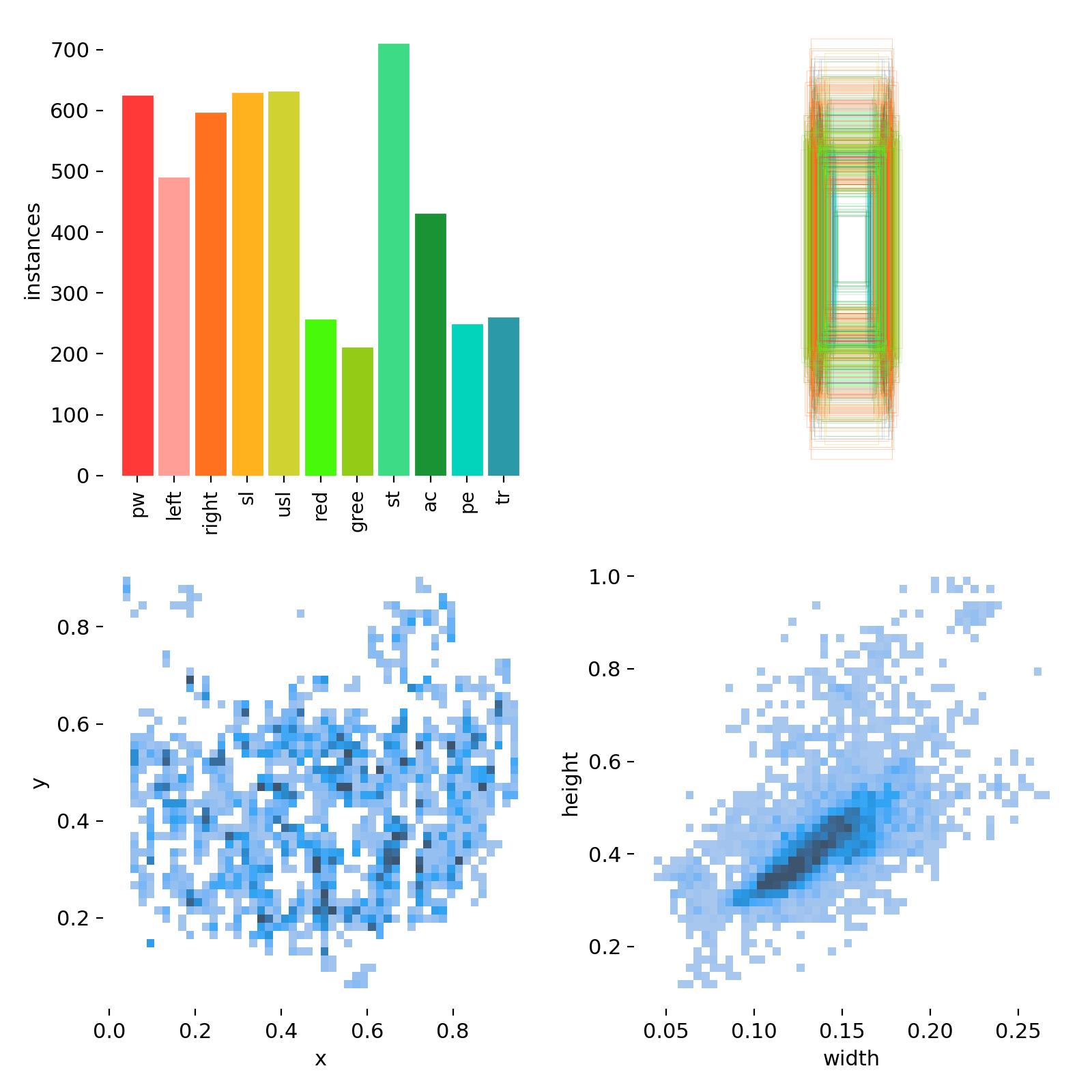
1.左上角:类别样本数量柱状图(最直观的类别分布 )
横轴: 11 个类别,纵轴:每个类别的样本数量(Instances)
缺点:有的类别数据多,有的类别数据少,这可能会导致模型对样本少的类别学不好
2.右上角:边界框(Bounding Box)叠加图
这张图是将所有样本的标注框叠在一起,看目标在画面里的位置和大小分布:
- 不同颜色对应不同类别的框,颜色越深 / 线条越密,说明这个位置的框越多。
- 观测结果:所有目标都集中在画面中间的垂直区域,上下的框很少,说明目标位置比较集中,模型很容易学会 “找中间区域”,但也可能对边缘的目标不敏感。
- 框的大小很统一,大多是细长矩形,说明所有目标的形状、比例都差不多。
3.左下角:目标中心点坐标(x,y)散点图
这张图看的是目标中心在画面里的位置分布:
- 横轴
x:目标中心的水平位置,从左(0)到右(1) - 纵轴
y:目标中心的垂直位置,从上(0)到下(1) - 点越密集,说明这个位置的目标越多。
- 能看出来:目标的 x 坐标集中在 0.1~0.8 之间,y 坐标集中在 0.2~0.7 之间,和右上角的图对应上了 —— 目标基本都在画面中间,很少出现在边缘
4.右下角:目标宽高(width, height)散点图
这张图看的是目标本身的大小和比例:
- 横轴
width:目标框的宽度(占整个画面的比例) - 纵轴
height:目标框的高度(占整个画面的比例) - 点越密集,说明这个宽高组合的目标越多。
- 能看出来:大部分目标的宽度在 0.1~0.15 之间,高度在 0.3~0.5 之间,而且高度明显比宽度大,是典型的 “瘦高个” 形状,和右上角的框形状相对应
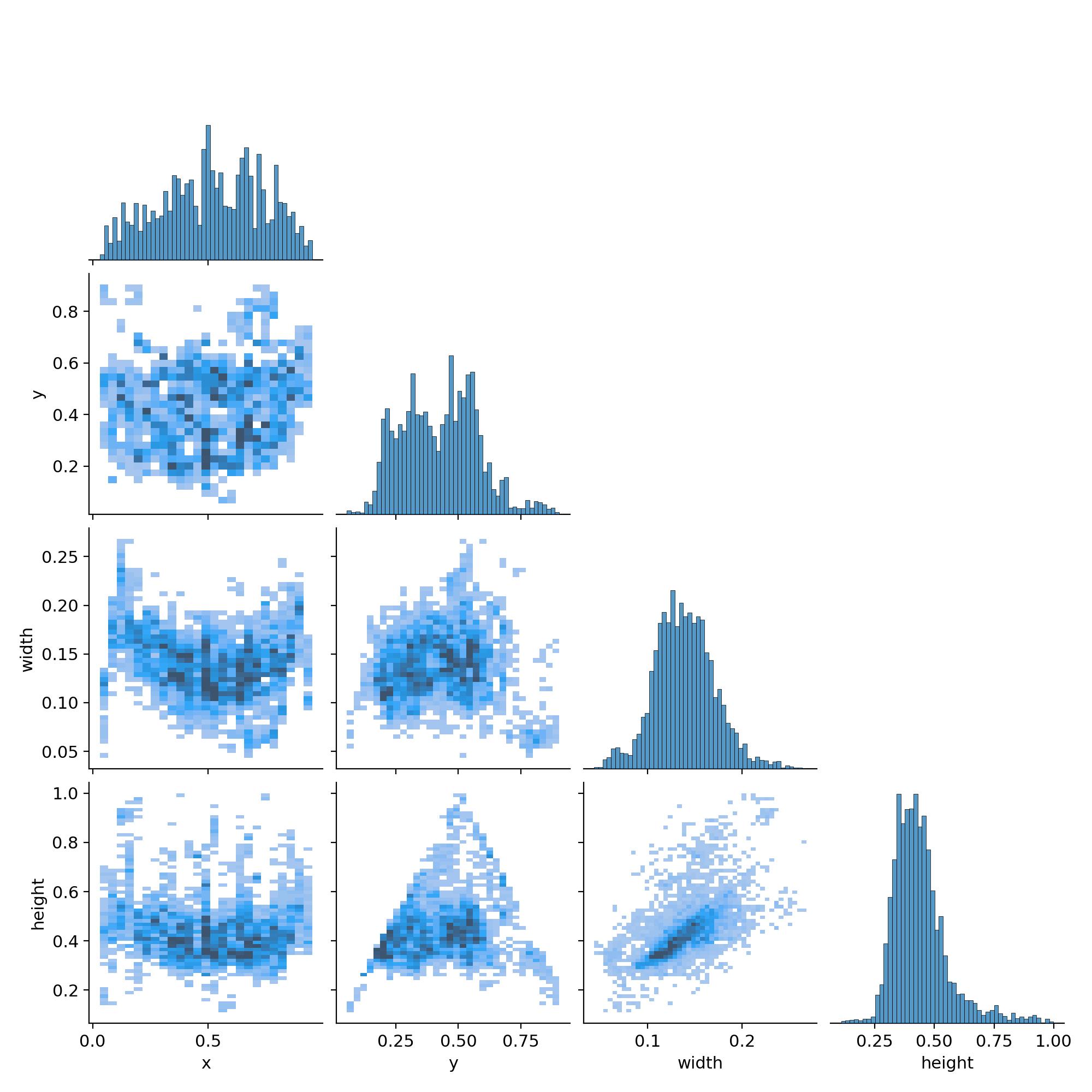 (四) 配对图(Pair Plot)
(四) 配对图(Pair Plot)
-
x:目标框中心点的水平位置(0 = 最左,1 = 最右) -
y:目标框中心点的垂直位置(0 = 最上,1 = 最下) -
width:目标框的宽度(占整个画面的比例) -
height:目标框的高度(占整个画面的比例) -
对角线:每个特征自己的分布直方图,告诉我们这个特征的样本大多集中在哪个范围。
-
非对角线:两个特征之间的散点热力图,颜色越深 = 样本越多,能看出两个特征有没有关联。
逐个部分拆解:
1. 对角线:每个特征的分布情况
- x 分布(最上):目标中心的水平位置,大多集中在
0.2~0.7之间,说明目标基本都在画面水平中间区域,很少出现在最左 / 最右边缘。 - y 分布(第二行):目标中心的垂直位置,大多集中在
0.2~0.6之间,说明目标基本都在画面垂直中间区域,很少出现在最上 / 最下边缘。 - width 分布(第三行):目标框的宽度,大多集中在
0.1~0.15之间,说明目标的宽度普遍很小,大部分目标都比较窄。 - height 分布(最右):目标框的高度,大多集中在
0.3~0.6之间,说明目标的高度普遍比宽度大很多,是典型的 “瘦高个” 形状。
2. 非对角线:特征之间的关联关系
- x 和 y(第二行第一个图):目标的水平位置和垂直位置没有明显的关联,说明目标在画面中间区域是均匀分布的,不会出现 “越靠左就越靠上” 这种规律。
- width 和 x/y(第三行前两个图):目标的宽度和它在画面里的位置几乎没关系,不管目标在画面左边还是右边、上边还是下边,宽度都差不多。
- height 和 x/y(第四行前两个图):目标的高度和位置也几乎没关系,不管目标在画面哪个位置,高度都比较稳定。
- width 和 height(第四行第三个图):这里能看到一个很明显的关联:目标越宽,高度也越高,而且大部分样本都集中在 “窄 + 中等高度” 的区域,只有少数目标又宽又高,说明数据里大部分目标的形状比例是很固定的。
核心结论:
- 目标位置高度集中:几乎所有目标都在画面的中心区域,边缘几乎没有目标。
- 目标形状高度统一:大部分目标都是 “窄而高” 的矩形,宽高比例非常固定,而且宽和高有正相关关系。
- 特征之间独立性强:目标的位置和大小几乎没有关联,不会出现 “在角落的目标就特别大 / 特别小” 的情况。
(五)Precision-Confidence Curve(精确率 - 置信度曲线)
——评估模型性能

- 横轴:Confidence(置信度),模型对自己预测结果的 “自信程度”,从 0(完全没把握)到 1(100% 确定)。
- 纵轴:Precision(精确率),也叫 “查准率”,表示「模型预测为某类别的样本里,有多少是真的属于这个类别」。数值越接近 1,说明模型预测的结果越靠谱
- 每条彩色线:对应一个类别(
pw、left、right等),表示这个类别在不同置信度下的精确率变化。 - 粗蓝线:所有类别的平均精确率,标注 “all classes 1.00 at 0.877”,意思是当置信度设为 0.877 时,所有类别的平均精确率能达到 1.00(也就是 100%)。
核心逻辑:
- 曲线越高,说明这个类别的预测越 “准”,模型喊它是 X,它真的是 X 的概率越高。
- 曲线越早升到 1.0,说明这个类别哪怕在较低的置信度下,预测结果也很靠谱。
- 曲线一直上不去、波动大,说明这个类别的预测里 “掺假” 很多,模型经常认错。
粗蓝线:所有类别的平均精确率曲线,它的最高点在置信度 = 0.877 的位置,精确率达到了 1.
说明:当我们把模型的置信度阈值设为 0.877 时,所有类别的预测结果都非常靠谱,几乎没有错误
- 优点:几乎不会认错,精确率 100%。
- 缺点:很多置信度低于 0.877 的正确预测会被直接过滤掉,导致模型漏检很多目标,召回率会大幅下降。所以这个点是 “只准不全” 的平衡点,和我们之前 F1 曲线里 “0.490” 那个 “既准又全” 的平衡点是互补的。
核心结论:
- 模型的两极分化很明显:
pw、st、ac、tr这些类别预测极准,但left/right几乎全是错的。 - 高置信度能保证精确率,但会牺牲召回率:0.877 的阈值能让预测结果 100% 正确,但会漏掉很多目标;而低置信度下,很多类别的预测里会掺假。
left/right是模型的硬伤:不管置信度设得高还是低,这两个类别的预测结果都不靠谱,是模型最需要优化的地方。
(六)Precision-Recall(精确率 - 召回率)曲线
——评估每个类别性能的 “终极成绩单”
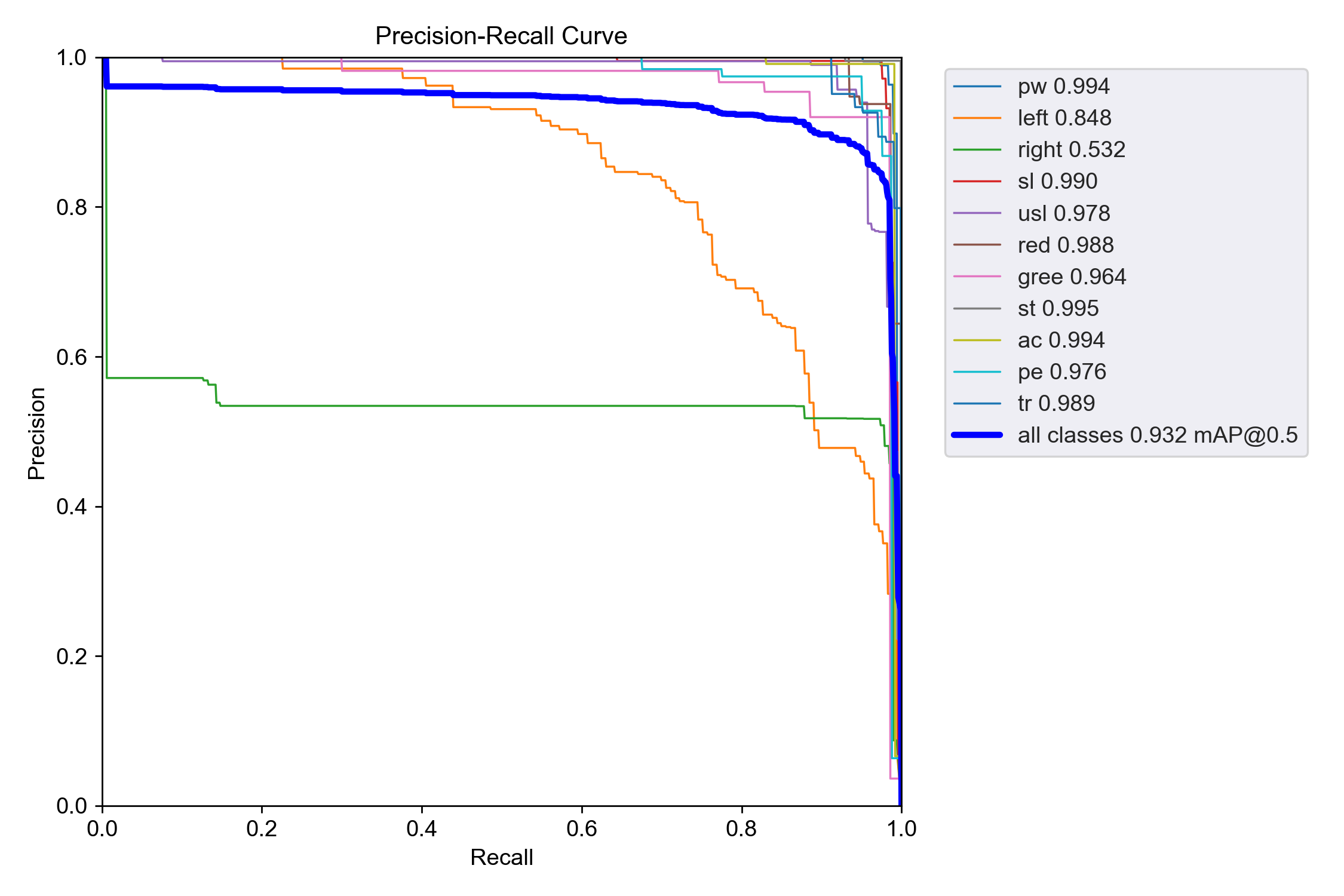
- 横轴(Recall,召回率):模型能找对的目标,占所有真实目标的比例(越高 = 漏检越少)。
- 纵轴(Precision,精确率):模型预测出来的目标里,真正正确的比例(越高 = 错检越少)。
- 对每个类别来说,曲线越靠近右上角(1,1),性能越好;曲线下的面积,就是这个类别的 AP(平均精度),图里图例上的数字就是每个类别的 AP 值
粗蓝线:是所有类别的平均表现,标注 all classes 0.932 mAP@0.5,意思是在 IoU=0.5 的标准下,模型整体的 mAP(平均 AP)是 0.932,这是目标检测的核心指标。
核心结论:
- 和混淆矩阵对应:
left和right的 AP 最低,和它们在混淆矩阵里互相混淆严重的结果完全对应;而pw、st的 AP 最高,也和它们零混淆的表现一致。 - 和 F1 / 精确率 / 召回率曲线对应:
right的曲线几乎平着不动,说明不管置信度怎么调,精确率和召回率都没法同时提升,和你之前看到的 “right 的曲线掉得最早、最惨” 完全对应。 - 和训练曲线对应:整体 mAP@0.5=0.932,和你训练曲线里最后稳定在 0.9 左右的 mAP 数值完全匹配,说明训练是成功的,只是个别类别拖
(七) Recall-Confidence Curve(召回率 - 置信度曲线)
——体现模型找目标的能力

- 横轴:Confidence(置信度),模型对预测结果的 “自信程度”,0 = 完全没把握,1=100% 确定。
- 纵轴:Recall(召回率),也叫 “查全率”,表示「真实属于这个类别的样本里,有多少被模型找出来了」。越接近 1,说明模型 “漏检” 越少,找得越全。
- 每条彩色线:对应一个类别(
pw、left等),表示这个类别在不同置信度下的召回率变化。 - 粗蓝线:所有类别的平均召回率,标注 “all classes 1.00 at 0.000”,意思是当置信度设为 0 时,所有类别的平均召回率能达到 1.00(100%)。
核心逻辑:
- 曲线越高,说明这个类别模型找得越全,漏检越少。
- 曲线下降得越晚、越平缓,说明这个类别在高置信度下也不容易漏检。
- 曲线掉得越早、越快,说明这个类别模型很容易漏检,置信度稍微设高一点就找不到了。
粗蓝线:所有类别的平均召回率曲线(标注 “1.00 at 0.000”)
- 当置信度设为 0 时,模型不会过滤任何预测,所有目标都会被找出来,召回率是 100%。
- 优点:不会漏检任何目标,找得最全。
- 缺点:会包含大量错误的预测,精确率会极低,很多 “假目标” 也会被当成真的。所以这个点是 “全而不准” 的平衡点,和之前精确率曲线里 “0.877” 那个 “准而不全” 的点正好相反。
(八) YOLO 模型训练过程的监控面板
——模型训练时,损失和性能指标是怎么变化的。

- 横轴:训练的轮数(epoch),从 0 到 100+,代表模型训练了多少轮。
- 纵轴:对应的损失值或指标数值。
- 蓝色线:原始数据;橙色虚线:平滑后的趋势,方便你看整体变化。
- 损失(loss)越低,说明模型的预测越接近真实值;指标(precision/recall/mAP)越高,说明模型性能越好。
第一行:训练集损失(train loss)
这三张图看的是模型在训练数据上的学习情况:
train/box_loss(定位损失):衡量模型预测的目标框位置准不准。曲线从 0.2 左右一路下降到 0.05~0.07,说明模型越来越会 “找位置”,框的位置越来越准。train/obj_loss(置信度损失):衡量模型判断 “这里有没有目标” 的能力。曲线从 0.06 左右下降到 0.03 左右,说明模型越来越会区分目标和背景。train/cls_loss(分类损失):衡量模型判断 “目标属于哪个类别” 的能力。曲线从 0.04 左右下降到 0.015 左右,说明模型越来越会给目标分类。 结论:模型在训练集上的学习很顺利,定位、置信度、分类能力都在稳步提升。
第二行:验证集损失(val loss)
这三张图看的是模型在没见过的验证数据上的表现,用来判断模型有没有过拟合:
val/box_loss:从 0.25 左右下降到 0.05,和训练集的趋势一致,说明定位能力在新数据上也有效。val/obj_loss:从 0.3 左右下降到 0.05,和训练集同步下降,说明目标置信度的泛化能力不错。val/cls_loss:从 0.1 左右下降到 0.01,分类损失也稳定下降,说明分类能力在新数据上也有效。
结论:训练集和验证集的损失都在同步下降,而且没有出现 “训练损失继续降,验证损失开始升” 的情况,说明模型没有过拟合,泛化能力很好。
第三部分:性能指标(metrics)
这四张图看的是模型的核心性能,越往上走越好:
metrics/precision(精确率):模型预测的目标里,真正正确的比例。曲线从 0 一路涨到接近 0.9,说明模型预测的结果越来越靠谱,错的越来越少。metrics/recall(召回率):真实存在的目标里,被模型找出来的比例。曲线从 0 涨到接近 0.9,说明模型漏检的目标越来越少,找得越来越全。metrics/mAP_0.5(IoU=0.5 时的平均精度):目标检测最核心的指标之一,衡量模型在 “位置偏差一半以内” 时的整体性能。曲线从 0 涨到接近 0.9,说明模型的整体性能在稳步提升。metrics/mAP_0.5:0.95(IoU 从 0.5 到 0.95 的平均精度):更严格的指标,衡量模型在不同位置偏差下的平均性能。曲线从 0 涨到接近 0.7,说明模型在不同精度要求下的表现都在变好。
结论:所有性能指标都在持续上升,没有出现 “震荡、停滞或下降”,说明模型训练得很成功,性能一直在提升。
整体总结:
- 训练过程非常健康:训练集和验证集的损失同步下降,没有过拟合,也没有梯度消失 / 爆炸的问题。
- 模型性能稳步提升:精确率、召回率、mAP 都在持续上涨,说明模型的定位、分类、目标检测能力都在变强。
- 当前的训练状态:在 100 轮左右,损失已经基本稳定,指标也接近平台期,再继续训练提升空间不大,可以考虑停止训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)