论文142:Deep learning to quantify the pace of brain aging in relation to neurocognitive changes
开发一种直接从纵向MRI(同一个体在不同时间点t1t1和t2t2的T1扫描)估计脑衰老速度PP的3D-CNN纵向模型,并用显著性图实现神经解剖可解释性。
文章目录
1 要点
标题:Deep learning to quantify the pace of brain aging in relation to neurocognitive changes
中文: 用深度学习量化脑衰老速度及其与神经认知变化的关系
作者: Chenzhong Yin, Phoebe Imms, Nahian F. Chowdhury, Nikhil N. Chaudhari, Heng Ping, Haoqing Wang, Paul Bogdan, Andrei Irimia*, and the Alzheimer’s Disease Neuroimaging Initiative
机构: University of Southern California (USC)
期刊: PNAS 2025, Vol. 122, No. 10, e2413442122
时间线: 投稿 2024.7.5 → 接收 2024.12.19 → 发表 2025.2.24
代码:https://github.com/irimia-laboratory/USC_BA_estimator
研究背景:
脑龄(BA)是从单次MRI估计的横截面生物学年龄,反映出生到扫描时刻的累积衰老量,但它无法传达近期或同步的衰老趋势。而衰老速度 P P P 才直接反映认知衰退和疾病转化的速率。现有P的测量主要依赖全血DNA甲基化时钟(如DunedinPACE),但血脑屏障将神经细胞与血液分离。因此,血液表观遗传测量无法精确反映脑内衰老。如果用横截面3D-CNN在两个时间点分别估计BA再计算 P P P,则忽略了纵向MRI的联合信息,两次独立估计的误差传播导致P极不精确。
研究目标:开发一种直接从纵向MRI(同一个体在不同时间点 t 1 t_1 t1和 t 2 t_2 t2的T1扫描)估计脑衰老速度 P P P的3D-CNN纵向模型,并用显著性图实现神经解剖可解释性。
关键技术:
- 纵向模型:3D-CNN以两次扫描的体素级差值 Δ I = I ( t 2 ) − I ( t 1 ) ΔI = I(t_2)−I(t_1) ΔI=I(t2)−I(t1) 为输入,直接回归年龄变化 Δ B A ΔBA ΔBA。然后 P ≃ Δ B A / Δ C A P ≃ ΔBA/ΔCA P≃ΔBA/ΔCA,其中CA为实际年龄。关键是联合使用纵向信息,避免两次独立BA估计的误差传播。
- δP(百分比偏离): δ P = 100 × ( Δ B A / Δ C A − 1 ) δP = 100×(ΔBA/ΔCA − 1) δP=100×(ΔBA/ΔCA−1),用于量化个体 P P P偏离认知正常(CN)人群期望值的程度。
- 显著性映射:蒙版梯度方法使用用一阶泰勒级数 S ( V 0 ) ≈ w 0 T V 0 + b 0 S(V_0) ≈ w_0ᵀV_0 + b_0 S(V0)≈w0TV0+b0近似评分函数,其中 w 0 = ∂ S / ∂ V ∣ V 0 w_0 = ∂S/∂V|_{V_0} w0=∂S/∂V∣V0。然后将体素显著性高斯加权投影到皮层表面,归一化为概率图,支持按性别/诊断/年龄段分组比较。
数据集:训练集包括2,055例CN(UKBB数据集1,712例,ADNI-CN数据集343例,年龄为47-88岁);测试集1,304例CN;独立验证集 包括104例的NACC中的CN样本,以及140例ADNI-AD样本。所有被试个体均有纵向的T1 MRI。
2 引言
2.1 从脑龄到衰老速度
神经退行性疾病的风险随实际年龄(Chronological Age, CA)增长而升高,但生物学衰老在细胞、组织、器官乃至个体之间差异悬殊。磁共振成像(Magnetic Resonance Imaging, MRI)可通过皮层厚度、体积等指标刻画生物学衰老——例如,海马、额叶和颞叶的萎缩程度,以及白质高信号的体积,均与从正常认知向阿尔茨海默病(Alzheimer’s Disease, AD)的演进密切相关。然而,这些指标中与疾病相关的那部分变异,CA的捕捉能力很差。正是这一局限,催生了对脑龄(Brain Age, BA)的关注。
BA的估计思路如下:在认知正常(Cognitively Normal, CN)成年人的MRI上训练神经网络,让模型从脑影像特征预测CA,并通过最小化BA与CA的差值来优化。在CN成年人中,BA与CA高度吻合,但在AD等神经退行性疾病患者中,BA则显著高于同龄CN对照。正因如此,BA有潜力比CA更灵敏地反映疾病风险。
BA的根本局限在于,它从单次MRI推断的是从出生到扫描时刻的累积生物学衰老量。因此,它无法捕捉近期或当下的衰老趋势。与之互补的是衰老速度(Pace of aging, P),其衡量的是神经生物系统完整性随时间衰退的快慢。 P P P越快,认知衰退越快,进而推高患病率和死亡风险。
2.2 现有 P P P测量方法的根本缺陷
目前测量P的主流手段依赖全血DNA甲基化,即表观遗传时钟(如DunedinPACE [22]、DunedinPoAm [24])。但问题在于,血脑屏障(Blood-Brain Barrier, BBB)在物理和生化层面将神经细胞与血液隔离开来。这意味着,神经系统内部的衰老过程与外周血液中测得的衰老指标并不完全同步。
另一种思路是用横截面三维卷积神经网络(3D-CNN)在 t 1 t₁ t1和 t 2 t₂ t2两个时间点分别估计BA,再以 [ B A ( t 2 ) − B A ( t 1 ) ] / ( t 2 − t 1 ) [BA(t₂)−BA(t₁)]/(t₂−t₁) [BA(t2)−BA(t1)]/(t2−t1)近似 P P P。但这条技术路线有三个致命缺陷。其一,两次估计各自独立进行,完全忽略了前后两次MRI之间的纵向联合信息。其二,两次估计各自的误差在相减过程中被传播和放大。其三,即便CNN本身具备可解释性,经过两次独立推断之后,各脑区特征对P的贡献也变得模糊难辨。
2.3 本文的核心思路
本文提出了一种纵向模型(Longitudinal Model, LM),从设计理念上彻底绕开了上述困境。LM中的3D-CNN不再接受单次MRI扫描,而是直接接收两次T1加权(T1-weighted, T1w)MRI的体素级差值 Δ I = I ( t 2 ) − I ( t 1 ) ΔI = I(t₂)−I(t₁) ΔI=I(t2)−I(t1),并端到端地回归年龄变化量 Δ B A ΔBA ΔBA(在训练目标上等价于 Δ C A ΔCA ΔCA),再以 P ≃ Δ B A / Δ C A P ≃ ΔBA/ΔCA P≃ΔBA/ΔCA算出衰老速度。
这一设计带来了三重优势。第一,两次扫描的纵向联合信息被一次性馈入模型,而非割裂使用。第二,彻底规避了两次独立BA估计导致的误差传播。第三,显著性映射得以直接定位对衰老速度P(而非对累积衰老BA)最为关键的脑区,使得"大脑哪些区域驱动了加速衰老"这一问题首次有了可解释的答案。
3 方法
3.1 P P P的数学定义
令 Δ B A ≡ B A ( t 2 ) − B A ( t 1 ) ΔBA ≡ BA(t₂)−BA(t₁) ΔBA≡BA(t2)−BA(t1), Δ C A ≡ t 2 − t 1 ΔCA ≡ t₂−t₁ ΔCA≡t2−t1。LM的任务是从 Δ I ΔI ΔI中估计 Δ B A ΔBA ΔBA(训练目标为 Δ C A ΔCA ΔCA),随后:
P ≃ Δ B A Δ C A P \simeq \frac{\Delta BA}{\Delta CA} P≃ΔCAΔBA从形式上看, P P P是 B A BA BA对时间的导数 P = d ( B A ) / d t P = d(BA)/dt P=d(BA)/dt。举例来说, P = 2 P=2 P=2意味着 B A BA BA正以实际时间流速的两倍增长。由于 C A CA CA只能以恒定速率 1 1 1流逝, d ( C A ) / d t ≡ 1 d(CA)/dt ≡ 1 d(CA)/dt≡1恒成立。因此,我们有
- P > 1:脑衰老快于参考速率(加速衰老)
- P < 1:脑衰老慢于参考速率(减速衰老)
BA 与 P 的理论关系: B A > C A BA > CA BA>CA意味着生命历程中至少有一段时期 P > 1 P > 1 P>1。反之 B A < C A BA < CA BA<CA则意味着至少有一段时期 P < 1 P < 1 P<1。例如,一个人 B A = 50 BA = 50 BA=50岁而 C A = 40 CA = 40 CA=40岁,则在其生命中的某个阶段,生物衰老必然曾以加速模式( P > 1 P > 1 P>1)进行。
3.2 δ P δP δP:可解释的百分比偏离指标
δ P = 100 × ( Δ B A Δ C A − 1 ) = 100 × ( P − 1 ) \delta P = 100 \times \left(\frac{\Delta BA}{\Delta CA} - 1\right) = 100 \times (P - 1) δP=100×(ΔCAΔBA−1)=100×(P−1)
- δ P > 0 → P > 1 δP > 0 → P > 1 δP>0→P>1:脑衰老速度快于CN人群期望水平
- δ P < 0 → P < 1 δP < 0 → P < 1 δP<0→P<1:脑衰老速度慢于CN人群期望水平
设计意图: δ P δP δP以百分比直接表示个体偏离正常衰老速度的程度,比原始 P P P值更直观易懂。
3.3 3D-CNN架构
输入 Δ I ΔI ΔI:两次T1 MRI的体素级代数差。两次扫描均经FreeSurfer(一种自动化脑影像分割与配准软件)进行颅骨剥离,保存为brain.mgz文件。
预处理:
- 原始分辨率1 mm³ → 降采样至2³ = 8 mm³(缩短训练时间,降低显存占用)
- 裁去脑组织周围的空白体素
- 矩阵从128×128×128缩减至82×86×100
网络结构:
| 模块 | 组成 | 滤波器数 | 输出尺寸 |
|---|---|---|---|
| Conv Block 1 | 3D Conv → BN → ReLU → MaxPool → Dropout | 64 | — |
| Conv Block 2 | 3D Conv → BN → ReLU → MaxPool → Dropout | 64 | — |
| Conv Block 3 | 3D Conv → BN → ReLU → MaxPool | 128 | 18×18×18×128 |
| Dense Block | GAP → Dense → Dropout(0.2) | — | 128×1 |
| Output | Dense → 单个神经元(回归输出) | — | 1 |
其中:BN与ReLU激活函数搭配使用;GAP(全局平均池化)将 18³×128 的特征图压缩为 128×1 向量,再经Dense全连接层增强特征表达,最后由单个输出神经元回归 Δ B A ΔBA ΔBA。Dropout(比率 0.2)与BN共同抑制过拟合。
训练配置:
- 损失函数:MSE(Mean Squared Error,均方误差),使 Δ B A ΔBA ΔBA与 Δ C A ΔCA ΔCA处于同一量纲
- 优化器:Adam(Adaptive Moment Estimation),初始学习率0.001,配合指数衰减调度
- 超参数搜索:对模块数量、滤波器维度、卷积核尺寸、权重衰减(weight decay)进行多维网格搜索,以最低 MSE 为选择标准
- 实现:Python 3.8 + TensorFlow 2.12.0
- 硬件:Intel Core i7 2.2 GHz CPU + 32 GB NVIDIA V100 GPU
- LM从零训练,不使用任何预训练权重
3.4 训练/测试划分
LM在 UKBB(UK Biobank,英国生物银行)和ADNI(Alzheimer’s Disease Neuroimaging Initiative,阿尔茨海默病神经影像学计划)的共3,359 例CN个体上进行训练和测试。具体的,随机抽取2,055 例(~60%)作为训练集,剩余 1,304 例(~40%)作为测试集。这一随机重采样策略旨在增强训练的鲁棒性。
独立验证:NACC(National Alzheimer’s Coordinating Center,美国国家阿尔茨海默病协调中心)的104例CN成年人,CA范围22–92岁(均值 71.24 ± 12.69)——年龄跨度远超训练集的47–88岁,构成对模型泛化能力的严格检验。另含140例ADNI 中的 AD 患者(55–90 岁)。
3.5 对比模型
| 模型 | 训练数据 | 预训练 | 输入 | P 计算方式 |
|---|---|---|---|---|
| LM(本文) | 2,055CN | 无 | Δ I ΔI ΔI(差值图像) | 直接回归 Δ B A ΔBA ΔBA |
| 3D-CNN [11] | 4,681CN(UKBB+HCP+ADNI) | 有 | 单次MRI | B A ( t 2 ) − B A ( t 1 ) BA(t₂) − BA(t₁) BA(t2)−BA(t1) |
| SFCN [20] | 5,698 UKBB CN | 有 | 单次 MRI | B A ( t 2 ) − B A ( t 1 ) BA(t₂) − BA(t₁) BA(t2)−BA(t1) |
| SFCN-reg [21] | 53,542 CN(21 个来源) | 有 | 单次 MRI | B A ( t 2 ) − B A ( t 1 ) BA(t₂) − BA(t₁) BA(t2)−BA(t1) |
SFCN(Simple Fully Convolutional Network,简单全卷积网络);HCP(Human Connectome Project,人类连接组计划)。所有模型在同一 1,304 例CN被试集上验证,确保公平比较。
3.6 显著性映射
将2D-CNN的蒙版梯度技术适配到三维空间 [11],是理解LM依据哪些脑区来估计P的关键工具。
Step 1 — 泰勒近似:
评分函数 S ( V ) = w T V + b S(V) = wᵀV + b S(V)=wTV+b( V V V为向量化的MRI体积)。由于3D-CNN本身高度非线性,在 V 0 V₀ V0处做一阶泰勒展开:
S ( V 0 ) ≈ w 0 T V 0 + b 0 , w 0 = ∂ S ∂ V ∣ V 0 , b 0 = b ∣ V 0 S(V_0) \approx w_0^T V_0 + b_0, \quad w_0 = \frac{\partial S}{\partial V}\Big|_{V_0}, \quad b_0 = b|_{V_0} S(V0)≈w0TV0+b0,w0=∂V∂S
V0,b0=b∣V0 w 0 w₀ w0即为蒙版梯度,表示体素级的显著性权重。
Step 2 — 皮层投影:
在FreeSurfer生成的中间厚度皮层表面每个顶点处,沿垂直于局部表面的方向取一圆柱体(高度和半径均等于局部皮层厚度),选取其中的 ribbon 体素,用高斯加权平均(FWHM(Full Width at Half Maximum,半高全宽) ≃ 4 ≃ 4 ≃4 mm, σ = 5 / 3 σ = 5/3 σ=5/3 mm)得到该顶点的平均显著性值。
Step 3 — 标准化:
从个体原生空间配准到FreeSurfer标准图谱空间 → 被试间叠加平均 → 将显著性图M转化为显著性概率图 S:每个脑区的显著性值除以全脑显著性总和→值域 [0, 1]。经此标准化后,跨被试、跨组的显著性方可直接比较。
Step 4 — 分组对比公式:
- 性别差异: Δ S = ( S M − S F ) / [ ( S F + S M ) / 2 ] ΔS = (S_M − S_F) / [(S_F + S_M)/2] ΔS=(SM−SF)/[(SF+SM)/2],以女性为参考
- 诊断差异: Δ S = ( S C I − S C N ) / S C N ΔS = (S_{CI} − S_{CN}) / S_{CN} ΔS=(SCI−SCN)/SCN,以CN为参考,CI(Cognitive Impairment,认知障碍)
- 年代差异: Δ S = ( S 70 − S 50 ) / S 50 ΔS = (S_{70} − S_{50}) / S_{50} ΔS=(S70−S50)/S50,以50岁组为参考
3.7 神经认知测量
认知分数变化计算: Δ m [ Δm[%] = 100 × [m(t₂)−m(t₁)] / m(t₁) Δm[,即相对于基线分数的改善或恶化百分比。
三个来源的认知测验:
-
ADNI(9 项):ADAS(Alzheimer’s Disease Assessment Scale,阿尔茨海默病评估量表)11项和13项版本(分数越高认知越差)、ADAS Q4(延迟词语回忆)、RAVLT(Rey Auditory Verbal Learning Test,Rey 听觉词语学习测验,含 15 词 × 7 试次 × 30 min 延迟——测量学习和记忆)、RAVLT 学习/即时/遗忘分量、LMem 延迟回忆(LMem(Logical Memory,逻辑记忆),30 min 延迟)、SDS(Symbol Digit Substitution,符号数字替换,90 秒——精神运动速度)、TMT(Trail Making Test,连线测验)B部分(视运动功能 / 认知灵活性)
-
UKBB(5 项):TMT A/B、SDS、DS 正向(DS(Digit Span,数字广度)正向——工作记忆)、PAL(Paired Associate Learning,配对联结学习——抽象词对记忆)
-
NACC(10 项):TMT A/B、VF 动物/VF 蔬菜(VF(Verbal Fluency,词语流畅性),60 秒命名——语义流畅性)、SR 即时/延迟/时间(SR(Story Recall,故事回忆),合并 LMem + Craft Story 21)、PN(PN(Picture Naming,图片命名),合并Boston Naming + Multilingual Naming)、DS 正向/反向(合并 DS + Number Span)
NACC 跨版本任务的合并方法:统一转换为正确率百分比。
4. 实验结果
4.1 P P P估计精度(表1, 图1–2)
对于测试集中的每个被试,LM直接输出 Δ B A ΔBA ΔBA的估计值。然后计算误差 ε = Δ B A − Δ C A ε = ΔBA − ΔCA ε=ΔBA−ΔCA,以及 P ≃ Δ B A / Δ C A P ≃ ΔBA / ΔCA P≃ΔBA/ΔCA。所有模型均展示MAE(即 ∣ ε ∣ |ε| ∣ε∣的平均值,单位年)、 ε ε ε的均值 μ ( ε ) μ(ε) μ(ε)和标准差 σ ( ε ) σ(ε) σ(ε)、以及决定系数 R 2 R² R2(衡量 Δ B A ΔBA ΔBA在多大程度上能解释 Δ C A ΔCA ΔCA的变异)。表1 汇总了所有模型在三个数据集上的完整统计。图1以散点图展示各模型的 Δ B A ΔBA ΔBA估计值与真实 Δ C A ΔCA ΔCA的对应关系(点越靠近对角线,估计越准)。图2展示 P P P值的分布直方图(A–C)以及 P P P是否随CA变化(D–F)。


CN测试集(1,304例):LM的 R 2 = 0.78 R² = 0.78 R2=0.78,而三个对比模型的 R 2 R² R2均不到0.02,表明通过两次独立 B A BA BA估计相减来计算 P P P,误差在传播过程中将解释力消耗殆尽。对比图1中各模型散点图的离散程度即可直观感受这一差异。
独立NACC CN集(104 例):LM MAE = 0.20 年,与测试集0.16年可比,泛化良好。3D-CNN MAE = 4.53 年(较测试集1.85年大幅恶化),所有差异p< 0.05。这组数据的意义在于:NACC 的年龄范围(22–92 岁)远超训练集(47–88 岁),是对泛化能力的严格压力测试。
AD患者集(140例):LM MAE = 0.50 年(有所退化但仍比3D-CNN的2.02年好约4倍)。LM在 A D AD AD上的 μ ( P ) μ(P) μ(P)偏离期望值1更远、 σ σ σ 更大。因为LM仅在CN数据上训练,AD的神经解剖模式与CN差异显著。
P P P独立于CA的验证:将每个被试的 P P P值对其CA作图,拟合趋势线。无论CN还是AD, P P P均不随CA系统变化(无显著趋势),表明确认 P P P是衰老速率指标,而非年龄的代理变量。CN中 μ ( P ) ≃ 0.98 μ(P) ≃ 0.98 μ(P)≃0.98,接近理论期望值1。这也是模型合理性的一个侧面验证:如果模型有系统性偏差,CN人群的P均值不会恰好落在1附近。
4.2 δP 与神经认知变化(图3–4)
对ADNI中的CN 被试(N = 35),计算每个人的 δ P = 100 × ( P − 1 ) δP = 100 × (P − 1) δP=100×(P−1)。同时,从神经心理测验中提取每个被试在两个时间点的认知分数变化 Δ m Δm Δm(以基线百分比变化表示)。然后将 δ P δP δP与各测验的 Δ m Δm Δm做Spearman秩相关分析。选用Spearman是因为认知数据经Anderson-Darling检验确认为非正态分布,不满足Pearson相关的前提。为控制多重比较的假阳性,所有 p p p值经Benjamini-Hochberg FDR校正。图3展示了 δ P δP δP与各项认知测验变化的相关强度。图4是关键排他性验证的可视化对比。


UKBB CN(图3左列):全部5项测验的 δ P δP δP关联在校正后均未达显著。可能原因是UKBB被试年龄偏轻(均值~65 岁),认知变异幅度本身较小,不足以在统计上检测出稳健相关。
ADNI CN(图3中列): δ P δP δP与ADAS13分数的变化呈显著正相关( r S = 0.414 r_S = 0.414 rS=0.414,校正后 p < 0.05 p < 0.05 p<0.05)。正相关指 δ P δP δP越大(脑衰老越快),ADAS13 分数升高越多(认知恶化越严重)。ADAS11、ADAS Q4、RAVLT 即时回忆呈趋势但未达显著。
NACC CN(图3右列):SR延迟回忆和TMT B呈趋势但不显著。
关键的排他性验证(图4):排除一种替代解释,即 δ P δP δP与认知变化有关,但也许任何脑结构变化指标都能做到同样的效果。为此,在完全相同的35例ADNI CN样本上,分别计算 δ P δP δP以及脑体积变化百分比、皮层厚度变化百分比与 A D A S 13 ADAS13 ADAS13变化的相关。结果表明, δ P δP δP是唯一与ADAS13认知衰退显著相关的指标,连脑体积和皮层厚度的纵向变化都做不到这一点。这说明LM从 Δ I ΔI ΔI中提取的衰老速度信号,其信息量超越了传统结构度量的简单变化。
方向一致性检验: δ P > 0 δP > 0 δP>0(衰老加速)时,ADAS分数升高(错误增多=恶化)、RAVLT分数降低(回忆词数减少=记忆下降)、TMT B耗时增加(速度变慢=执行功能退化)——所有测验的变化方向一致指向"加速衰老=多领域认知恶化",排除了偶然方向混杂的可能。
对比算法BA与认知的关联(附录表S4–S6,非正文图表):3D-CNN / SFCN / SFCN-reg在 t 1 t₁ t1时刻估计的BA确实与 t 1 t₁ t1时刻的认知分数相关。但这与P和认知变化的相关是两个不同层面的证据:BA回答"当前认知状态如何",P回答"认知衰退有多快"。
4.3 δ P δP δP预测未来CI转化
在NACC和ADNI中筛选出一批在 t 1 t₁ t1被临床判定为CN的个体,追踪其后续诊断记录。其中31例在 t 2 t₂ t2之后某个时间点转化为CI(Cognitive Impairment,认知障碍),定义为"转化者";211例至研究结束时始终保持CN,为"非转化者"。用LM计算每个被试在 t 1 → t 2 t₁→t₂ t1→t2期间的δP,然后做两件事:1)用独立样本 t t t检验比较两组 δ P δP δP均值是否有显著差异;2)在转化者内部,用Spearman秩相关检验 δ P δP δP与"距转化天数"( t 2 t₂ t2到确诊日期的天数)的关系。
结果表明:
- 转化者的 δ P δP δP显著更高,即在尚未表现出临床症状变化的时间窗口内,未来会转化为CI的人,其脑衰老速度已经明显快于保持CN的人。
- 在转化者内部, δ P δP δP与距转化天数呈显著负相关,即 δ P δP δP越高,距离确诊越近,呈现出加速恶化的时间梯度。
这表明 δ P δP δP不仅捕捉到了同步的认知衰退,还可能通过量化脑衰老速度来提供前瞻性的CI风险预警。但必须注意:转化者仅31例,样本较小,统计学效力有限,结论需要更大纵向样本的外部复制才能确立。
4.4 显著性映射:解剖可解释性
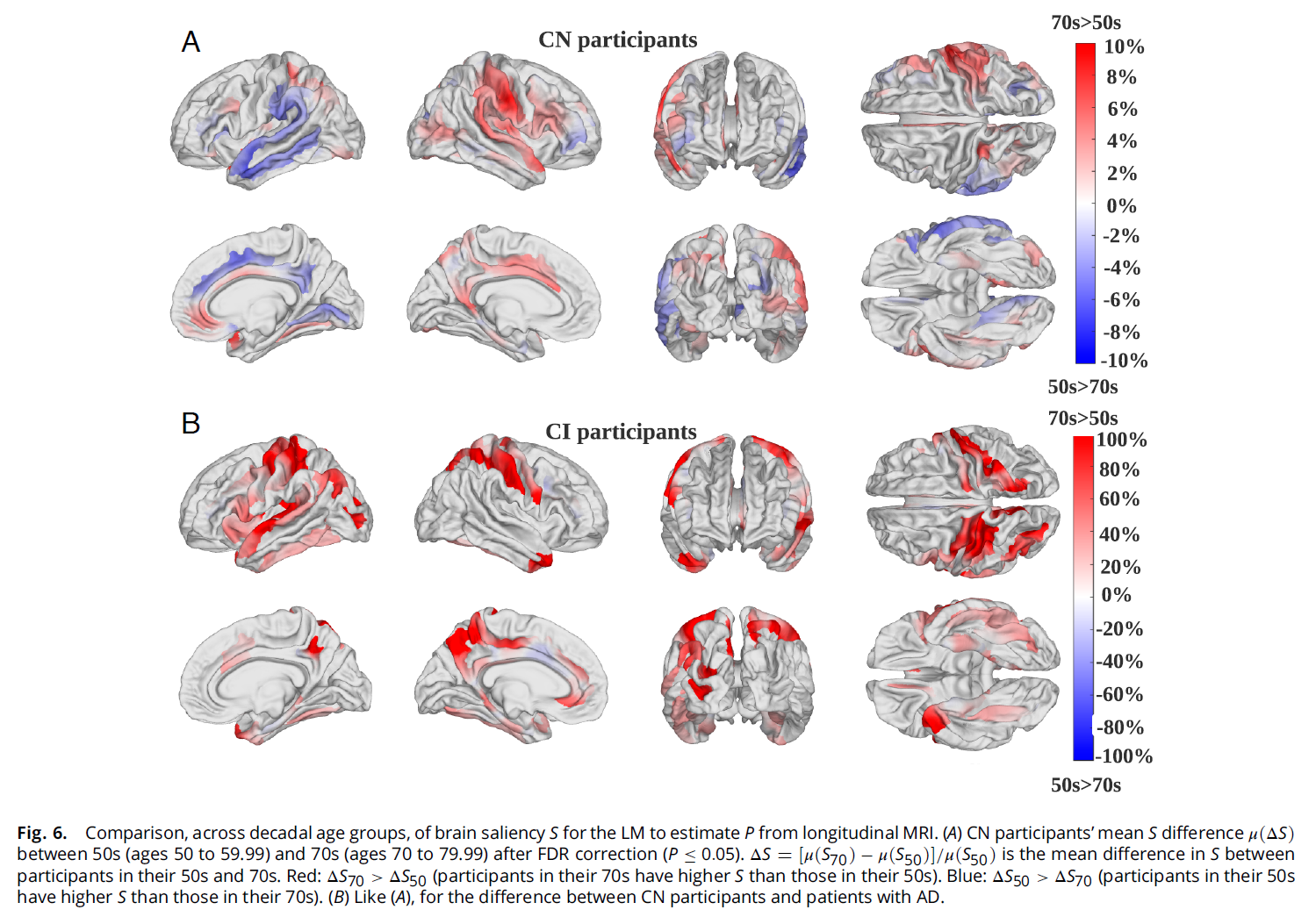
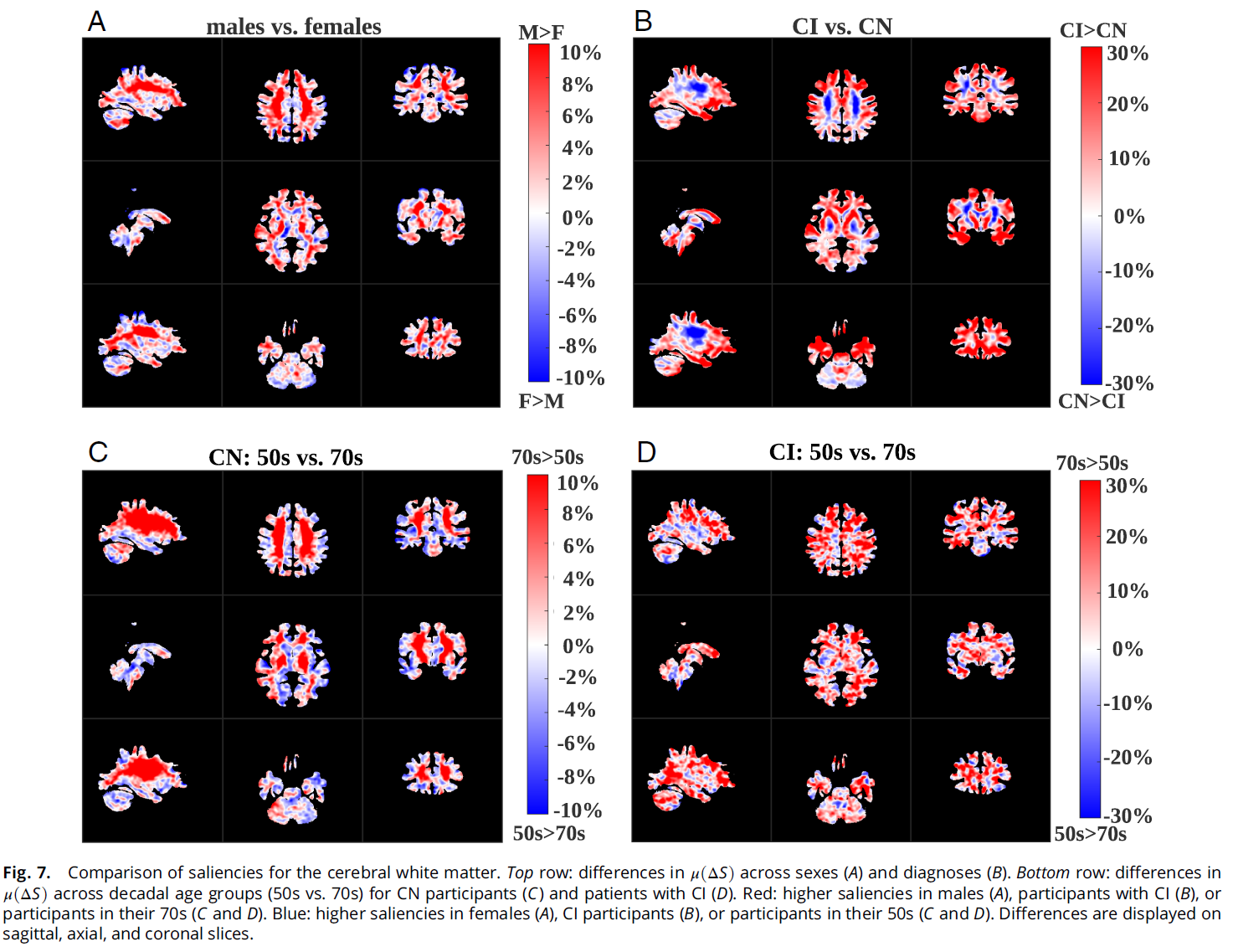
首先使用蒙版梯度为每个被试生成体素级显著性图 S S S。 S S S值越大的体素,对LM估计 P P P的贡献越大。然后将个体显著性图投影到FreeSurfer标准皮层表面,在被试间叠加平均,再按全脑总和归一化为显著性概率图(值域[0, 1])。最后按性别、诊断、年龄段分组,计算组间差异 Δ S ΔS ΔS,并对 Δ S ΔS ΔS做统计检验(FDR p ≤ 0.05 p ≤ 0.05 p≤0.05的脑区视为显著)。图5展示了皮层表面的组间显著性差异,图6按年龄段对比,图7深入到灰质/白质层面。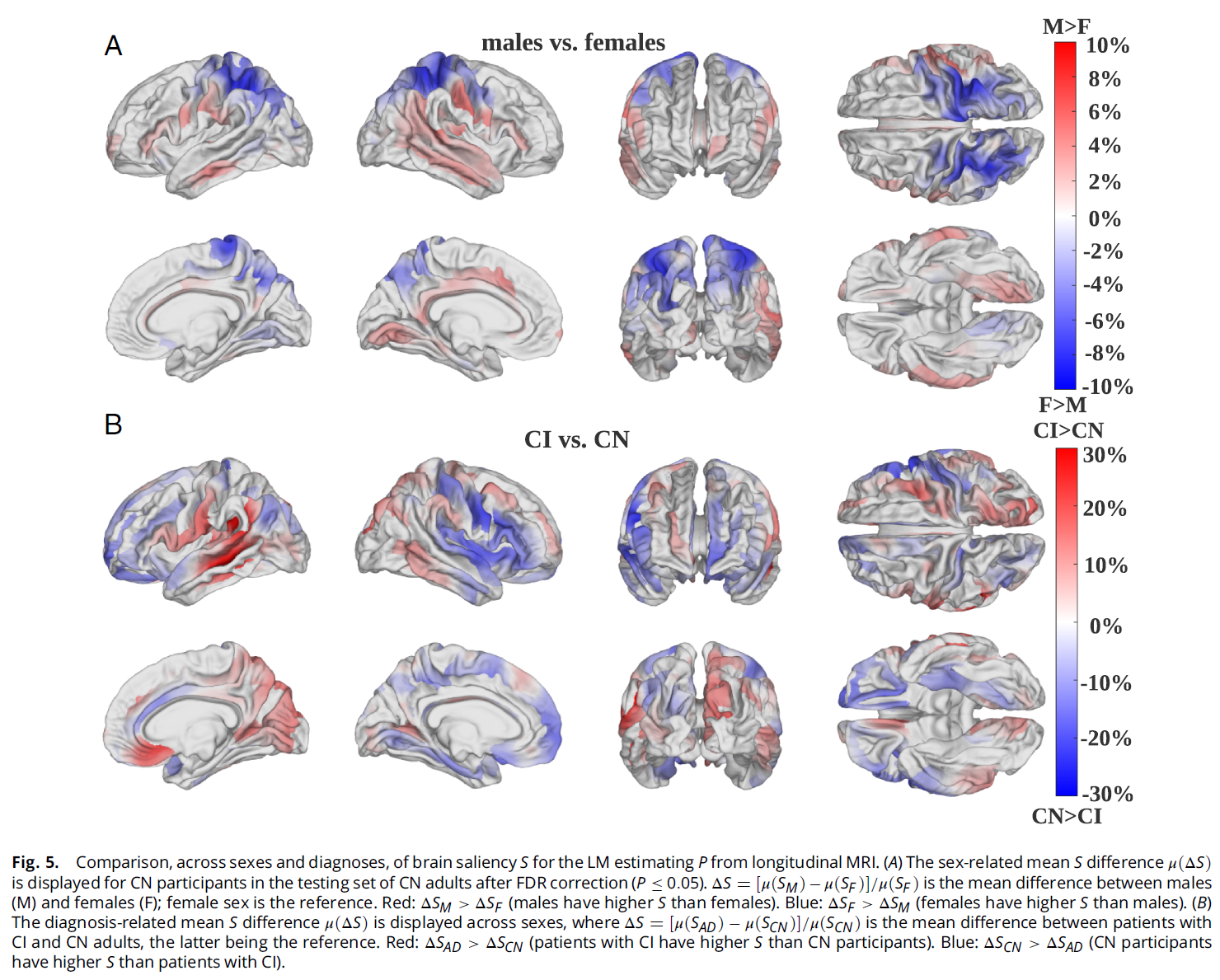
按性别(图5A;1,304例CN测试集):
- 女性 P P P更依赖的脑区:右侧中央前回、双侧中央后回、楔前叶、顶上小叶、双侧旁中央小叶,集中在中央沟周围的初级感觉运动皮层和顶叶。
- 男性P更依赖的脑区:左侧额极横回、右侧缘上回、双侧subcentral gyri、扣带回的右侧中前部和左侧中后部,集中在扣带回(默认模式网络DMN核心节点)和缘上回(执行控制网络)。
- 深层结构差异(图7A):将显著性按灰质和白质分别统计后发现,男性的 P P P比女性更依赖白质变化(均值差 < 10%),女性对灰质的依赖相对更大。
空间分布模式:男性的显著性集中分布于回冠(gyral crowns,脑回的顶部),女性则集中分布于沟底(sulcal troughs,脑沟的底部),这与先前关于性别差异影响脑沟扩大的研究[11]相互印证。
按诊断:CN vs CI(图5B):
- CN的 S S S更高:右侧中央后回、左侧额回、扣带回前部。
- CI的 S S S更高:右侧后外侧枕叶、右侧额上回、左侧缘上回。
- 深层结构差异(图7B):CI的 P P P更多由灰质和浅表白质(靠近皮层的白质)驱动;CN的 P P P更多由深部白质驱动。这暗示一个值得关注的转变:正常衰老的 P P P主要由白质信号驱动,而向认知障碍转变时,灰质萎缩信号开始主导。
按年龄段:50岁组vs70岁组(图6):分组标准为 [ C A ( t 1 ) + C A ( t 2 ) ] / 2 [CA(t₁) + CA(t₂)] / 2 [CA(t1)+CA(t2)]/2落在50–59.99或70–79.99。
- CN中50岁组 S S S更高(图6左列):左侧外侧颞叶、右侧内侧枕叶、左侧缘上回、左侧额上回,区域相对局限。
- CN中70岁组 S S S更高(图6左列):右侧中央/中央后回、左侧扣带回、左侧内侧枕叶,涉及更广泛的区域,提示随年龄增长, P P P的估计需要更分散的脑特征来支撑。
- CI中50岁组 S S S更高(图6右列):额下沟、左侧扣带回中前部,非常局限。
- CI中70岁组 S S S更高(图6右列):顶叶、枕叶、外侧颞叶大面积区域,以及直回、胼胝体下回、额上回部分,CI 高龄组几乎全脑显著性升高,表明疾病进展使衰老速度的神经解剖表征高度弥散,不再局限于特定脑区。
深层结构差异(图7C–D):CN 70岁组白质 S S S略高(< 10%);CI在多个灰质和白质位置 S S S 均更高。
4.5 各子组的 MAE 和 R 2 R² R2(表2)
将测试集中的被试按性别(男/女)、诊断(CN/CI)和年龄段(50 岁组/70 岁组)交叉划分,在每个子组内分别计算LM的MAE和 R 2 R² R2,检验模型在不同人群切片上是否存在系统性性能差异。
Table 2的完整结果此处不逐行列,结果表明CN 50岁组的 R 2 R² R2高达0.953,即LM 在中年健康人群中几乎实现了完美估计。CI 70岁组的 R 2 R² R2仅0.443,在老年AD患者中, Δ B A ΔBA ΔBA的变异仅有不到一半能被模型解释(疾病异质性带来的 Δ I ΔI ΔI变化超出了CN训练所能覆盖的范围)。男性与女性的性能差异极小(MAE分别为0.153和0.156),说明模型无显著的性别偏倚。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)