AI 时代的船:一次 Thinking Skills 多技能协同的奇点复盘
AI 时代的船:一次 Thinking Skills 多技能协同的奇点复盘

这不是一个宏大的奇点。
没有模型突然觉醒,也没有什么科幻式的瞬间。它只是一次很具体的协作:我在整理 Netty 系列文章、业务架构师定位、真实项目经验和学习计划时,第一次清楚地看见,AI 不再只是回答一个问题,而是在多个 domain skill 的约束下,围绕同一个真实产物共同工作。
这个瞬间让我很兴奋。
因为我突然意识到,Thinking Skills 不只是一些提示词,也不只是“让 AI 更会回答问题”的技巧。它开始像一个可以运行、可以复盘、可以自我改进的工作系统。
一个小但真实的奇点
一开始,我只是让 AI 看一下我给自己定的底座型知识全景图和 60 天学习计划。
这个问题表面上像是学习计划问题,但它其实很复杂。
它既涉及技术深度,也涉及学习负载;既涉及业务架构师定位,也涉及真实项目经验;甚至还涉及我的身体状态,因为那段时间我经历了严重失眠,学习和输出节奏都受到了影响。
然后我看到这样一幕,AI 对话截图: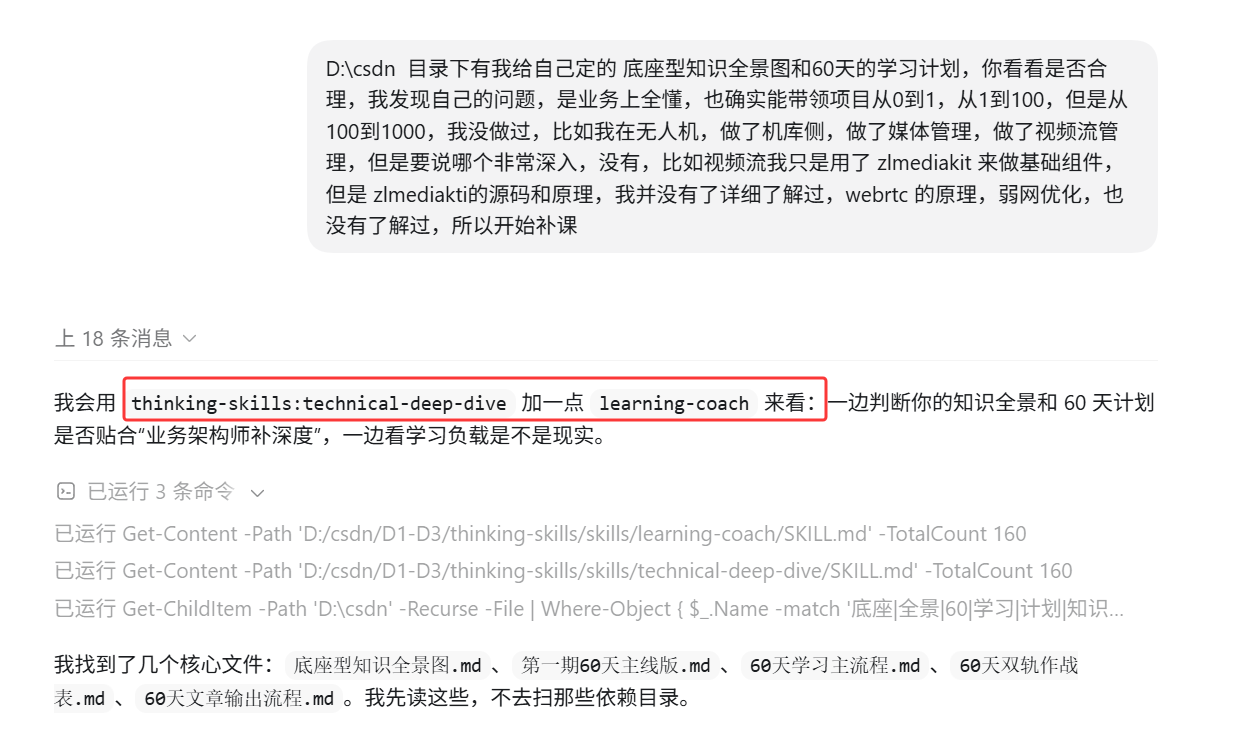
图里红框的位置很关键:AI 同时触发了 technical-deep-dive 和 learning-coach。
这件事本身不复杂,但它让我意识到一个变化:
Thinking Skills 开始从单点回答,转向
多技能协同。
technical-deep-dive 负责判断我的知识全景是否真的贴合业务架构师能力缺口。
learning-coach 负责判断这个学习计划是否现实,学习负载是否可持续。
这不是简单地“多调用几个模块”,而是在一个复杂问题里识别出不同维度,然后让不同 skill 各自承担自己的职责。
为什么单一 skill 不够
后来我们继续协作,主题从学习计划扩展到了 Netty 系列文章。
我原本有一批 Netty 源码分析文章,内容包括 EventLoop、Pipeline、ByteBuf、writeAndFlush、编解码、Spring Cloud Gateway、epoll、零拷贝等。
如果只从技术角度看,这些文章可以写成普通源码分析。
但这不是我真正想要的。
我真正想做的是:通过 Netty 源码,把自己的底层技术认知补起来,并且把这些认知映射到我真实做过的业务系统里,比如无人机、机库、云端 MQTT、流媒体链路、云边协同、网关设计。
于是这个任务同时变成了几个问题:
- 技术问题:Netty 源码机制讲得是否准确。
- 架构问题:这些机制如何映射到真实业务系统。
- 写作问题:CSDN 文章如何组织才适合阅读。
- 风险问题:内部项目名、真实 topic、配置、类名不能暴露。
- 学习问题:文章首先服务我自己的认知重建,而不是追求外部爆款。
- 复盘问题:哪些有效协作模式应该写回 Thinking Skills。
这时候单一 skill 就不够了。
只用 technical-deep-dive,文章会扎实,但可能读起来很硬。
只用 content-creator,文章会顺,但技术判断可能飘。
只用 learning-coach,学习路径会清楚,但不一定能处理源码和架构边界。
只用 conversation-review,能复盘模式,但不能单独完成文章改造。
真正有效的是让它们围绕同一个产物协同。
多 skill 协同不是平权开会
我后来问 AI,它是怎么协调多个 skill 的。
它给了我一个让我非常惊喜的回答:多 skill 协同不是几个 skill 平权开会,而是先判断主任务,再分配约束层。
比如改 Netty / CSDN 文章时,主轴一定是 technical-deep-dive。
因为这类文章最怕技术判断不稳。源码、线程模型、Pipeline、ByteBuf、Gateway、MQTT 边界,这些必须先站住。
然后 content-creator 负责文章结构、CSDN 阅读体验、标题、开头、收尾和平台格式。
如果反过来,以内容创作为主,文章可能会更像一篇好看的随笔,但底层技术会飘。
这就是多 skill 协同的关键:
| 场景 | 主 skill | 辅助 skill | 目的 |
|---|---|---|---|
| 源码文章涉及真实业务架构 | technical-deep-dive |
content-creator |
技术不飘,同时文章能读 |
| 学习计划涉及补深度和负载 | technical-deep-dive |
learning-coach |
判断内容价值,也判断执行现实性 |
| 工作压力影响判断 | emotional-support |
technical-deep-dive |
先稳住人,再分析事 |
| 发现可复用协作模式 | conversation-review |
skill 修改流程 | 复盘并写回规则 |
我觉得这个地方非常关键。
多 skill 协同不是把几个 skill 都叫出来说几句,而是让它们围绕一个共同对象施加不同约束。
共同对象:一套 Netty 系列文章
这次共同对象就是一套 Netty 系列文章。
它有几个目标:
- 技术上要扎实,不能把 Netty 源码讲虚。
- 文章上要适合 CSDN 阅读,不能全是生硬的源码堆叠。
- 定位上要服务我“业务架构师”的成长路线。
- 安全上要避免暴露内部项目名、真实 topic、真实配置和真实类名。
- 学习上要帮助我把底座知识转成架构判断。
比如讲 Pipeline 时,我们不只是分析 ChannelPipeline 和 ChannelHandlerContext。
我们会进一步映射到机库侧 MQTT Gateway:本地 MQTT 消息进入系统后,先经过日志、特殊 topic 处理、anti-loop 过滤、业务消费,再决定是否转发到云端 MQTT。
这和 Netty Pipeline 的思想非常像:
- 消息有方向。
- 处理链有边界。
- 有些节点消费消息。
- 有些节点继续传播。
- 有些消息需要过滤。
- 双向转发时要防止回环。
再比如讲 ByteBuf 时,不只是分析 readerIndex、writerIndex、堆内/堆外内存、引用计数。
它会被映射成高吞吐数据链路里的“数据路径意识”:
- 视频流不要只看协议转换,还要看持续数据搬运和缓冲压力。
- MQTT 消息不要只看 topic,还要看 payload 解析、转发和对象创建成本。
- 大文件上传不要和实时控制链路混在一起评估,要单独看带宽、分片、重试和内存占用。
- Gateway 响应不要只看路由成功,还要看慢客户端和写出缓冲是否会拖住系统。
这样一来,Netty 源码就不再是孤立知识点,而变成了我理解业务系统的底座。
真正的闭环:从 self-review 到 skill rule
这次协作里最让我兴奋的,不只是文章改得更好了。
更重要的是,我们发现了一个可以写回系统的小问题。
我在看 CSDN 文章截图时发现,文章里大量使用 text 代码块,阅读体验很差。普通概念、观点句、问题列表、结论句不应该放进黑色代码块里。
代码块应该留给真正需要格式的内容,比如:
- Java / SQL / YAML / Bash 代码
- 配置
- 日志
- 协议报文
- 堆栈
- Mermaid 图
普通概念应该用段落、列表、表格、引用块和行内代码。
这个问题不大,但非常真实。
于是我们做了三件事:
- self-review,确认这是一个可复用失败信号。
- 修改
content-creatorskill,把 CSDN 代码块使用规则写进去。 - 提交并推送到 GitHub。
后来我们又把这次多 skill 协同本身记录成 golden case。
整个闭环是这样的:
这件事让我意识到,Thinking Skills 和普通 prompt 最大的区别,不是“回答更好”,而是:
经验可以回写系统。
一次协作里发现的问题,不只是这次修掉,而是可以变成下一次默认遵守的规则。
Thinking Skills 到底是什么
对我来说,Thinking Skills 不是一堆提示词。
它更像一套可运行的认知分层系统。
每个 skill 都代表一种相对稳定的工作方式:
technical-deep-dive:负责事实、源码、机制、架构边界。learning-coach:负责学习路径、认知负载、可复述能力。content-creator:负责文章结构、读者体验、平台格式。emotional-support:负责人在压力、焦虑、失眠、工作冲突里先稳住。conversation-review:负责复盘对话,发现失败信号和黄金模式。
它们不是为了炫技,而是为了让 AI 在复杂任务里少走偏。
普通 prompt 更像一次性请求。
Thinking Skills 更像一个工作系统:它能路由、能执行、能复盘、能保存成功模式,也能把失败信号写回规则。
这也是我今天感到“奇点”的原因。
不是 AI 突然变成了人,而是它开始像一个可持续进化的协作系统。
AI 时代的船
我之前写过一个比喻:大模型是水,普通开发者的船是什么?
今天我对这个比喻有了更具体的感受。
如果大模型是水,那么 Thinking Skills 像船体结构。不同模型像不同的发动机、雷达和顾问。有的模型更会找问题,有的模型更像朋友,有的模型更擅长执行。
但船真正能不能航行,不只取决于水有多大,也不只取决于发动机有多强。
更重要的是,人能不能把自己的判断、经验、复盘和创造力组织成结构。
今天这个小奇点让我意识到:
AI 时代真正重要的,不是让模型替我思考,而是把我的思考方式做成可以被 AI 放大的系统。
这就是 Thinking Skills 对我的意义。
它不是终点。
它更像一艘船开始真正下水的时刻。
附件
self-review 机制截图

AI 自我分析截图

项目地址与安装方式
Thinking Skills 目前仍然是一个 Alpha 阶段的开源项目。
它不是一个已经定型的标准答案,而是一套可以安装到本地 agent 环境里、在真实对话中使用、复盘和继续改进的 thinking skill 框架。
项目地址:
https://github.com/huajiexiewenfeng/thinking-skills
如果你的环境支持 Skills CLI,可以直接安装:
npx skills add huajiexiewenfeng/thinking-skills
安装之后,本地 agent 就可以发现这些 first-party skills,也就是项目内置的第一批核心技能:
thinking-router:领域路由,判断用户请求应该进入哪种思考模式。content-creator:内容创作,处理文章、标题、大纲、论点和写作结构。technical-deep-dive:技术深潜,处理代码、架构、调试、性能、接口和验证。learning-coach:学习教练,帮助理解概念、建立心智模型和发现知识盲区。emotional-support:情绪支持,处理焦虑、自责、关系困扰、burnout 和情绪梳理。conversation-review:对话复盘,也就是 Dolores 机制,用来回看 skill 使用轨迹和失败信号。skill-evaluator:技能评估器,用来分类失败原因并提出最小修改建议。benchmark-assistant:评测助手,用来运行、生成、评分和解释 benchmark 评测流程。
也就是说,Thinking Skills 的使用方式不是“复制一段 prompt”,而是把一组可路由、可复盘、可评测的 thinking skills 安装到本地环境里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)