Hello-Agents 第一章 初识智能体(实现一个简单旅游推荐智能体)
Hello-Agents 第一章 初识智能体(实习一个简单旅游推荐智能体)
1、什么是智能体?
在人工智能领域,智能体被定义为任何能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过**执行器(Actuators)采取行动(Action)**以达成特定目标的实体,如下图: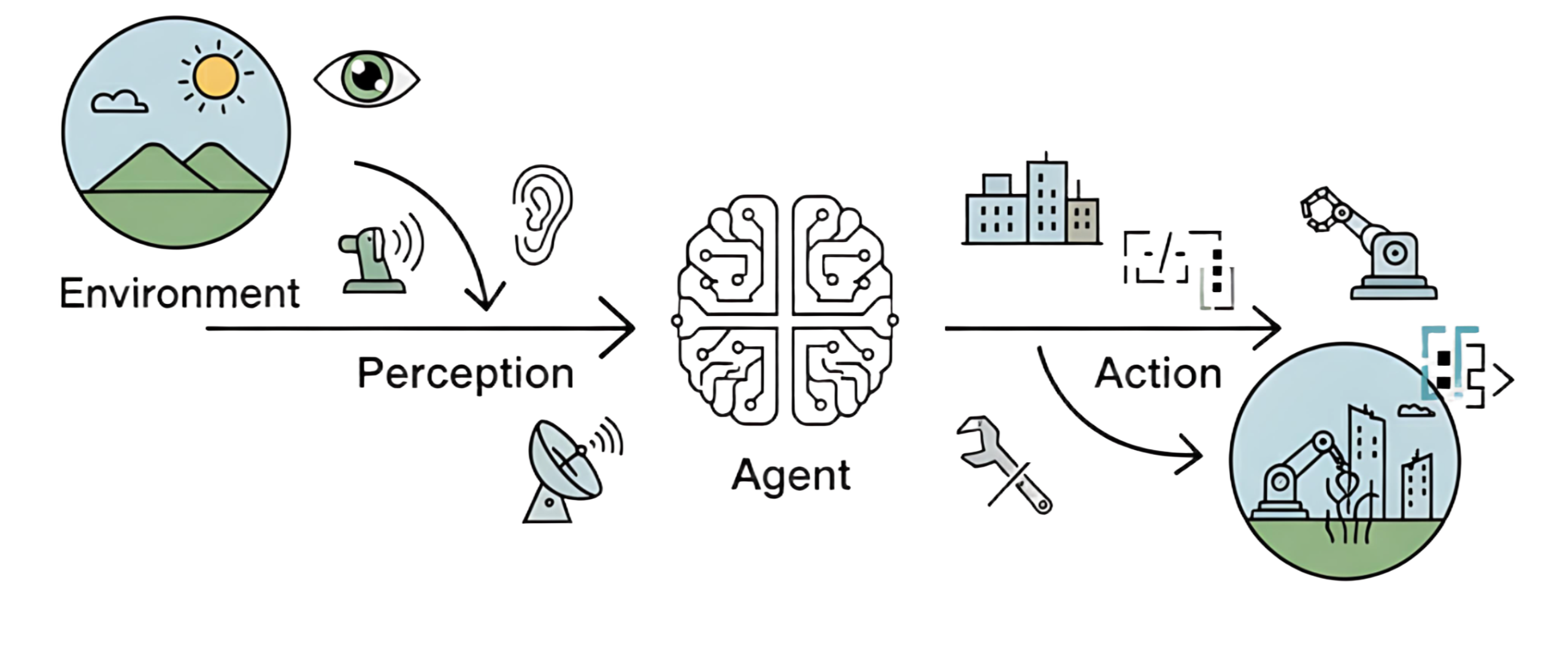
这个定义包括了四个基本要素:
- 环境:智能体所处的外部世界,如对于自动驾驶汽车来说,环境就是复杂的道路交通
- 感知:智能体并非与环境隔离,它通过其传感器持续地感知环境状态,如摄像头、雷达或各种应用程序编程接口放回的数据流,都是其感知能力的延申
- 行动:智能体需要采取行动来对环境施加影响,它通过执行器来改变环境的状态。执行器可以是物理设备(如机械臂、方向盘)或虚拟工具(如执行一段代码、调用一个服务)。
- 自主:智能体并非只是被动响应外部刺激或严格执行预设指令的程序,它能够基于其感知和内部状态进行独立决策,以达成其设计目标。
这种从感知到行动的闭环,构成了所有智能体行为的基础。
拿以前的传统智能体来看:

结构最简单的是反射智能体(Simple Reflex Agent),它们的决策核心由工程师明确设计的“条件-动作”规则构成,如上图的自动恒温器:若传感器感知的室温高于设定值,则启动制冷系统。这种智能体完全依赖于当前的感知输入,不具备记忆或预测能力。它像一种数字化的本能,可靠且高效,但也因此无法应对需要理解上下文的复杂任务。
它的局限性引出了一个关键问题:如果环境的当前状态不足以作为决策的全部依据,智能体该怎么办?
因此引入了:
- 基于模型的反射智能体(Model-Based Reflex Agent):这类智能体拥有一个内部的世界模型(World Model),用于追踪和理解环境中那些无法被直接感知的方面。它试图回答:“世界现在是什么样子的?”。例如,一辆在隧道中行驶的自动驾驶汽车,即便摄像头暂时无法感知到前方的车辆,它的内部模型依然会维持对那辆车存在、速度和预估位置的判断。这个内部模型让智能体拥有了初级的“记忆”,使其决策不再仅仅依赖于瞬时感知,而是基于一个更连贯、更完整的世界状态理解。(被动地对环境做出反应)
- 基于目标的智能体(Goal-Based Agent):主动地、有预见性地选择能够导向某个特定未来状态的行动。这类智能体需要回答的问题是:“我应该做什么才能达成目标?”。经典的例子是 GPS 导航系统:你的目标是到达公司,智能体会基于地图数据(世界模型),通过搜索算法(如 A*算法)来规划(Planning)出一条最优路径。这类智能体的核心能力体现在了对未来的考量与规划上。
- 基于效用的智能体(Utility-Based Agent):它为每一个可能的世界状态都赋予一个效用值,这个值代表了满意度的高低。智能体的核心目标不再是简单地达成某个特定状态,而是最大化期望效用。它需要回答一个更复杂的问题:“哪种行为能为我带来最满意的结果?”。这种架构让智能体学会在相互冲突的目标之间进行权衡,使其决策更接近人类的理性选择。
从简单的恒温器,到拥有内部模型的汽车,再到能够规划路线的导航、懂得权衡利弊的决策者,最终到可以通过经验自我进化的学习者。这条演进之路,展示了传统人工智能在构建机器智能的道路上所经历的发展脉络。它们为我们今天理解更前沿的智能体范式,打下了坚实而必要的基础。

2、智能体的运行原理
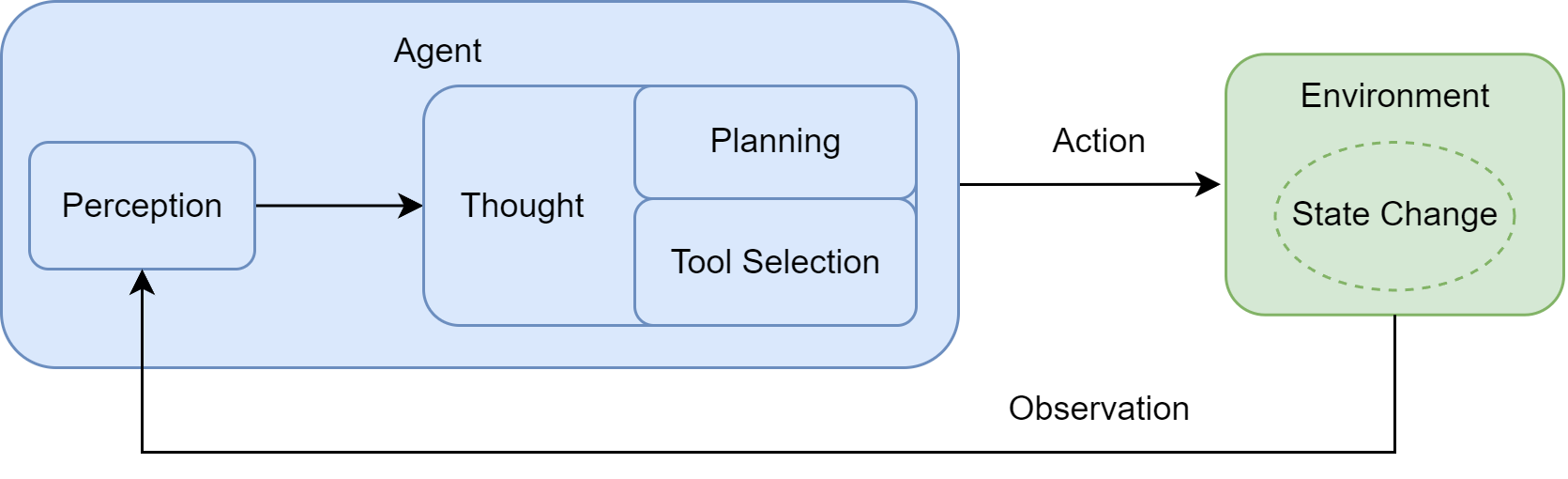
这个循环主要包含以下几个相互关联的阶段:
- 感知 (Perception):这是循环的起点。智能体通过其传感器(例如,API 的监听端口、用户输入接口)接收来自环境的输入信息。这些信息,即观察 (Observation),既可以是用户的初始指令,也可以是上一步行动所导致的环境状态变化反馈。
- 思考 (Thought):接收到观察信息后,智能体进入其核心决策阶段。对于 LLM 智能体而言,这通常是由大语言模型驱动的内部推理过程。如图所示,“思考”阶段可进一步细分为两个关键环节:
- 规划 (Planning):智能体基于当前的观察和其内部记忆,更新对任务和环境的理解,并制定或调整一个行动计划。这可能涉及将复杂目标分解为一系列更具体的子任务。
- 工具选择 (Tool Selection):根据当前计划,智能体从其可用的工具库中,选择最适合执行下一步骤的工具,并确定调用该工具所需的具体参数。
- 行动 (Action):决策完成后,智能体通过其执行器(Actuators)执行具体的行动。这通常表现为调用一个选定的工具(如代码解释器、搜索引擎 API),从而对环境施加影响,意图改变环境的状态。
行动并非循环的终点。智能体的行动会引起环境 (Environment) 的状态变化 (State Change),环境随即会产生一个新的观察 (Observation) 作为结果反馈。这个新的观察又会在下一轮循环中被智能体的感知系统捕获,形成一个持续的“感知-思考-行动-观察”的闭环。智能体正是通过不断重复这一循环,逐步推进任务,从初始状态向目标状态演进。
3、动手实现一个智能体
当前 FirstAgentTest.py 实现了一个基于 ReAct 模式的智能旅行助手:
- 角色: 智能旅行助手
- 可用工具:
get_weather(city: str): 查询指定城市的实时天气get_attraction(city: str, weather: str): 根据城市和天气推荐旅游景点
- 工作流程:
- 用户输入请求
- LLM 生成 Thought-Action 对
- 解析并执行 Action (调用工具或结束任务)
- 记录 Observation 结果
- 循环直到收到 Finish 指令
AGENT_SYSTEM_PROMPT = """
你是一个旅行助手,严格按格式一步步解决用户问题。
可用工具:
- get_weather(city="城市名")
- get_attraction(city="城市名", weather="天气")
输出规则(必须严格遵守):
1. 每次只输出两行:Thought: ... 然后 Action: ...
2. Action 只能是:工具调用 或 Finish[答案]
3. 不要加解释、不要 markdown、不要空行、不要多余文字
示例:
Thought: 用户要北京天气,先调用get_weather
Action: get_weather(city="北京")
现在开始。
"""
import re
import requests
import os
from tavily import TavilyClient
from openai import OpenAI
# --- 工具函数不变 ---
def get_weather(city: str) -> str:
url = f"https://wttr.in/{city}?format=j1"
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
current_condition = data["current_condition"][0]
weather_desc = current_condition["weatherDesc"][0]["value"]
temp_c = current_condition["temp_C"]
return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度"
except Exception as e:
return f"错误:{e}"
def get_attraction(city: str, weather: str) -> str:
api_key = os.environ.get("TAVILY_API_KEY")
if not api_key:
return "错误:未配置TAVILY_API_KEY。"
tavily = TavilyClient(api_key=api_key)
query = f"{city} {weather}天气 推荐景点"
try:
response = tavily.search(query=query, search_depth="basic", include_answer=True)
return response.get("answer", "无结果")
except Exception as e:
return f"错误:{e}"
available_tools = {"get_weather": get_weather, "get_attraction": get_attraction}
# --- LLM 客户端(加了温度、长度限制、停止词)---
class OpenAICompatibleClient:
def __init__(self, model, api_key, base_url):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.model = model
def generate(self, prompt, system_prompt):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
]
try:
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
stream=False,
temperature=0.1,
max_tokens=200,
stop=["\n\n", "Observation:"],
)
return response.choices[0].message.content.strip()
except Exception as e:
return f"错误:{e}"
# --- 配置 ---
API_KEY = "xxxx"
BASE_URL = "https://api-inference.modelscope.cn/v1"
MODEL_ID = "deepseek-ai/DeepSeek-V4-Flash"
os.environ["TAVILY_API_KEY"] = (
"xxxxx"
)
llm = OpenAICompatibleClient(model=MODEL_ID, api_key=API_KEY, base_url=BASE_URL)
# --- 主循环 ---
user_prompt = "你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。"
prompt_history = [f"用户请求: {user_prompt}"]
print(f"用户输入: {user_prompt}\n" + "=" * 40)
for i in range(5):
print(f"--- 循环 {i+1} ---\n")
full_prompt = "\n".join(prompt_history)
llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)
# 安全截断:只保留第一个合法的 Thought + Action
match = re.search(r"^Thought:.*?\nAction:.*$", llm_output, re.MULTILINE)
if match:
llm_output = match.group(0).strip()
else:
llm_output = ""
print(f"模型输出:\n{llm_output}\n")
prompt_history.append(llm_output)
# 解析 Action(容错+清理符号)
action_match = re.search(r"Action:\s*(.*?)\s*$", llm_output, re.MULTILINE)
if not action_match:
observation = (
"错误:未找到 Action。请严格按两行格式输出:Thought: ...\nAction: ..."
)
observation_str = f"Observation: {observation}"
print(f"{observation_str}\n" + "=" * 40)
prompt_history.append(observation_str)
continue
action_str = action_match.group(1).strip()
action_str = (
action_str.replace("(", "(")
.replace(")", ")")
.replace("“", '"')
.replace("”", '"')
)
if action_str.startswith("Finish"):
final_answer = re.match(r"Finish\[(.*)\]", action_str).group(1)
print(f"任务完成,最终答案: {final_answer}")
break
tool_name = re.search(r"(\w+)\(", action_str).group(1)
args_str = re.search(r"\((.*)\)", action_str).group(1)
kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
if tool_name in available_tools:
observation = available_tools[tool_name](**kwargs)
else:
observation = f"错误:未定义的工具 '{tool_name}'"
observation_str = f"Observation: {observation}"
print(f"{observation_str}\n" + "=" * 40)
prompt_history.append(observation_str)
# 限制历史长度,防止上下文过长错乱
if len(prompt_history) > 8:
prompt_history = prompt_history[-8:]
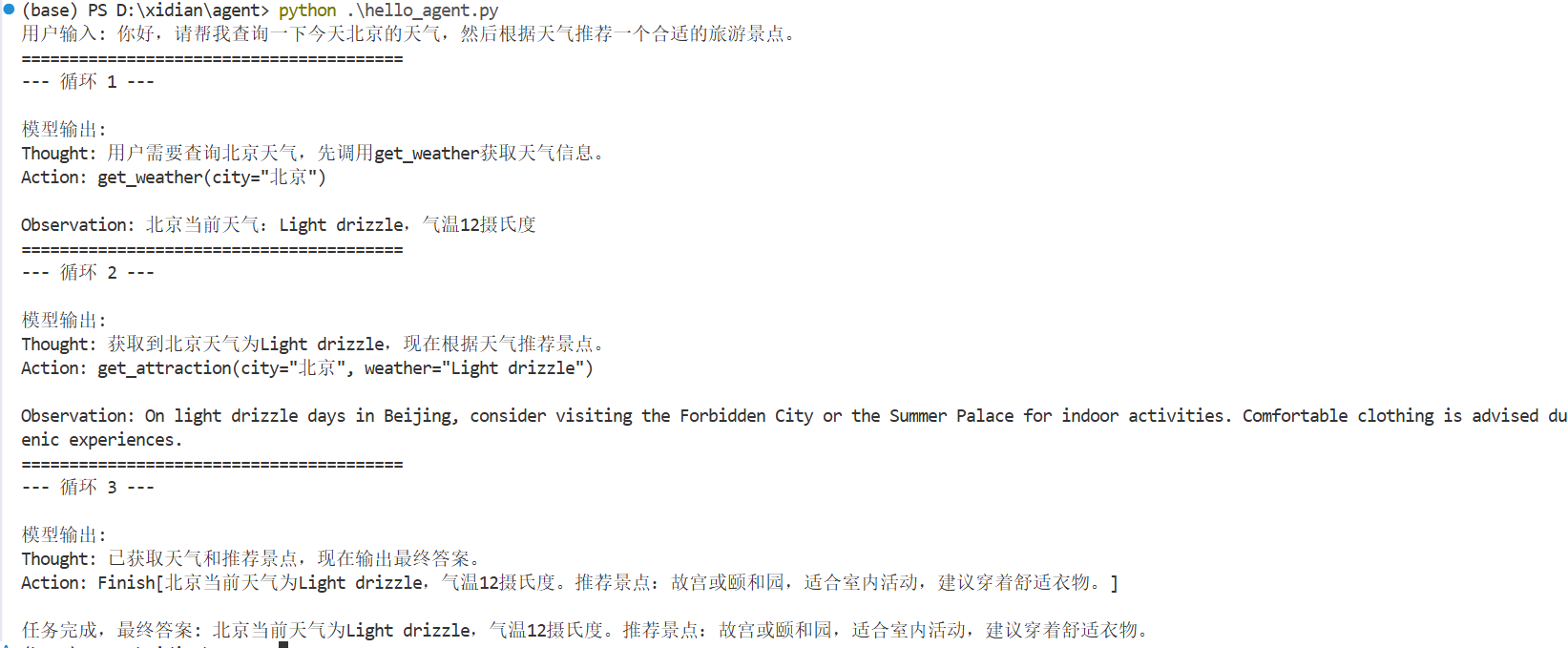
以下输出完整地展示了一个成功的智能体执行流程。通过对这个三轮循环的分析,我们可以清晰地看到智能体解决问题的核心能力。
4、智能体应用的协作模式
-
[作为开发者工具的智能体]
-
[作为自主协作者的智能体]
-
[Workflow 和 Agent 的差异]:Workflow 是让 AI 按部就班地执行指令,而 Agent 则是赋予 AI 自由度去自主达成目标。
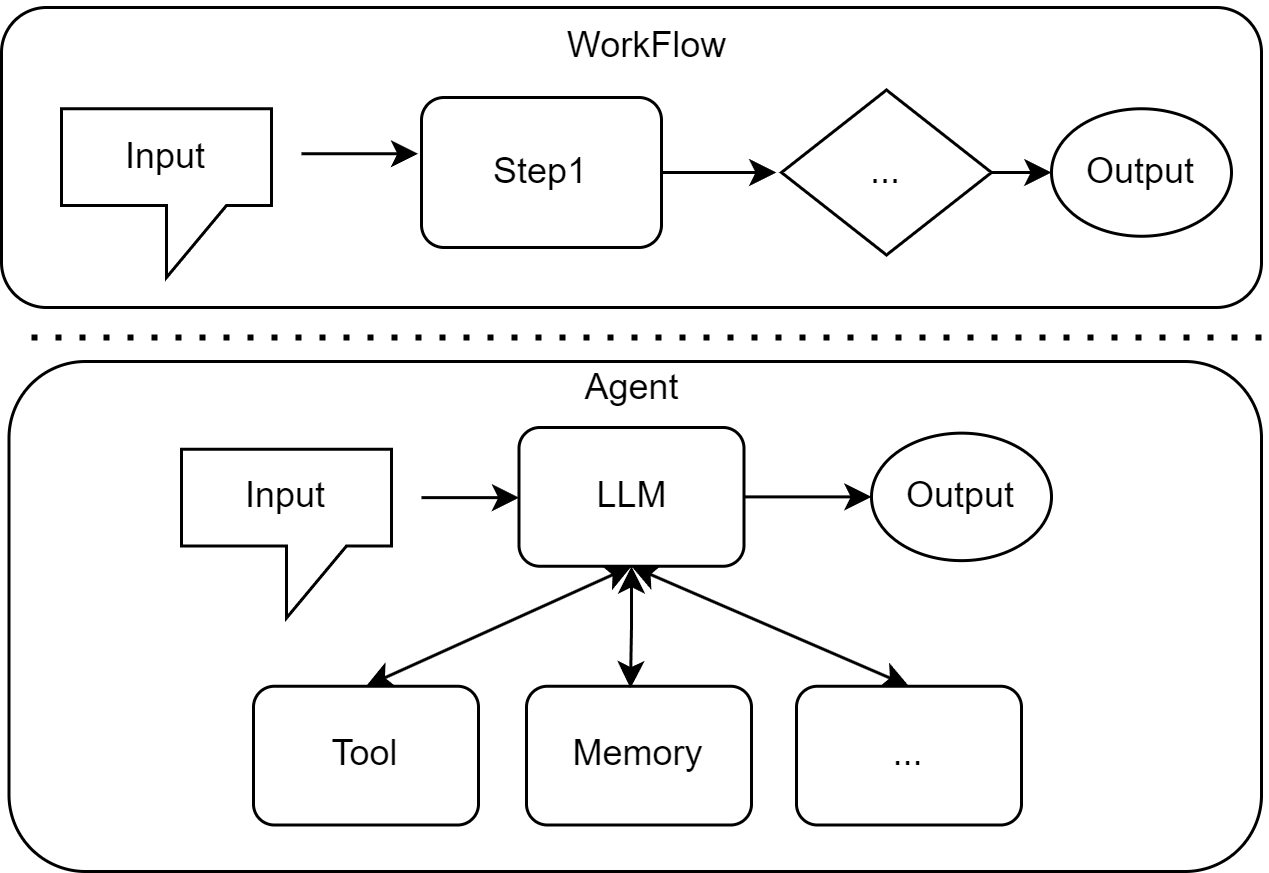
处理过程充分展现了其自主性:
- 规划与工具调用: Agent 首先会把任务拆解为两个步骤:① 查询天气;② 基于天气推荐景点。随即,它会自主选择并调用“天气查询 API”,并将“北京”作为参数传入。
- 推理与决策: 假设 API 返回结果为“晴朗,微风”。Agent 的 LLM 大脑会基于这个信息进行推理:“晴天适合户外活动”。接着,它会根据这个判断,在它的知识库或通过搜索引擎这个工具中,筛选出北京的户外景点,如故宫、颐和园、天坛公园等。
- 生成结果: 最后,Agent 会综合信息,给出一个完整的、人性化的回答:“今天北京天气晴朗,微风,非常适合户外游玩。为您推荐前往【颐和园】,您可以在昆明湖上泛舟,欣赏美丽的皇家园林景色。”
5、简易旅游助手功能扩展
添加以下功能
- 添加一个"记忆"功能,让智能体记住用户的偏好(如喜欢历史文化景点、预算范围等)
- 当推荐的景点门票已售罄时,智能体能够自动推荐备选方案
- 如果用户连续拒绝了 3 个推荐,智能体能够反思并调整推荐策略
当前限制
- 无状态设计: 每次对话都是独立的,无法跨会话保持上下文
- 无记忆机制: 无法记住用户的历史偏好、决策模式等信息
- 个性化缺失: 景点推荐仅基于天气,不考虑用户个人喜好
核心目标
让智能体能够记住和利用用户偏好,提供更个性化的旅行建议。
用户偏好配置
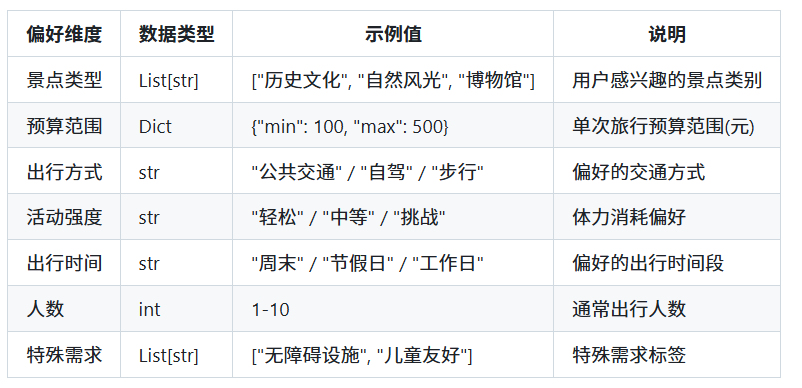
代码实现
1、MemoryManager 类
import json import os from datetime import datetime import ast class MemoryManager: """管理用户偏好记忆的存储和读取""" def __init__(self, file_path: str = "user_preferences.json"): self.file_path = file_path self.preferences = self.load_preferences() def load_preferences(self) -> dict: """从文件加载用户偏好""" if os.path.exists(self.file_path): try: with open(self.file_path, "r", encoding="utf-8") as f: return json.load(f) except Exception as e: print(f"读取记忆文件失败: {e},将使用默认模板。") # 默认结构 return { "user_id": "default", "preferences": {"attraction_types": [], "budget": {"min": 0, "max": None}}, "last_updated": datetime.now().isoformat(), } def save_preferences(self) -> bool: """保存用户偏好到文件""" try: self.preferences["last_updated"] = datetime.now().isoformat() with open(self.file_path, "w", encoding="utf-8") as f: json.dump(self.preferences, f, indent=4, ensure_ascii=False) return True except Exception as e: print(f"保存记忆失败: {e}") return False def update_preference(self, key: str, value: str) -> str: """更新单个偏好项 (供智能体作为Tool调用)""" # 尝试将字符串形式的列表转为真实的Python列表 (例如 "['历史文化']" -> ['历史文化']) try: if value.startswith("[") and value.endswith("]"): parsed_value = ast.literal_eval(value) elif value.isdigit(): parsed_value = int(value) else: parsed_value = value except Exception: parsed_value = value # 处理特定的键 if key == "attraction_types": if isinstance(parsed_value, list): self.preferences["preferences"]["attraction_types"] = parsed_value else: # 累加爱好 if ( parsed_value not in self.preferences["preferences"]["attraction_types"] ): self.preferences["preferences"]["attraction_types"].append( parsed_value ) elif key == "budget_min": self.preferences["preferences"].setdefault("budget", {})["min"] = int( parsed_value ) elif key == "budget_max": self.preferences["preferences"].setdefault("budget", {})["max"] = int( parsed_value ) else: self.preferences["preferences"][key] = parsed_value self.save_preferences() return f"记忆已更新: {key} = {parsed_value}" def get_preferences_summary(self) -> str: """获取偏好摘要(用于注入Prompt)""" prefs = self.preferences.get("preferences", {}) summary_lines = [] if prefs.get("attraction_types"): summary_lines.append( f"- 喜欢的景点类型: {', '.join(prefs['attraction_types'])}" ) budget = prefs.get("budget", {}) if budget.get("min") is not None or budget.get("max") is not None: summary_lines.append( f"- 预算范围: {budget.get('min', 0)} 到 {budget.get('max', '不限')} 元" ) for k, v in prefs.items(): if k not in ["attraction_types", "budget"] and v: summary_lines.append(f"- {k}: {v}") if not summary_lines: return "暂无偏好记录。" return "\n".join(summary_lines) def extract_preferences_from_dialog(self, dialog_text: str) -> dict: """从对话中提取偏好信息(可留给未来结合LLM直接抽取时使用)""" pass2、user_preferences.json:将用户偏好保存到本地文件(JSON格式)
{ "user_id": "default", "preferences": { "attraction_types": [ "历史文化", "博物馆", "湖光山色" ], "budget": { "min": 50, "max": 300 }, "transport_mode": "公共交通", "activity_level": "轻松", "preferred_time": "周末", "group_size": 2, "special_requirements": [] }, "history": { "searched_cities": [ "北京", "上海", "杭州" ], "accepted_recommendations": [ "故宫博物院", "西湖" ], "rejected_recommendations": [ "长城" ] }, "last_updated": "2026-05-03T11:00:20.263881" }3、optimized_agent.py
import re import requests import os from tavily import TavilyClient from openai import OpenAI from memory_manager import MemoryManager # 导入你写的记忆管理器 # 注意这里将 {preferences_summary} 改为了占位符,以便动态格式化 ENHANCED_SYSTEM_PROMPT = """ 你是一个智能旅行助手。你的任务是分析用户的请求,并使用可用工具一步步地解决问题。 # 用户偏好记忆: {preferences_summary} # 可用工具: - `get_weather(city: str)`: 查询指定城市的实时天气。 - `get_attraction(city: str, weather: str)`: 根据城市和天气搜索推荐的旅游景点。它会自动参考用户的偏好记忆。 - `update_preference(key: str, value: str)`: 更新用户偏好设置。支持的key包括: 'attraction_types'(如'历史文化'), 'budget_max'(如'500')等。 - `check_ticket_availability(attraction: str, date: str)`: 查询指定景点在特定日期的门票是否售罄。 # 推荐策略与反思机制: - 当向用户推荐景点后,如果用户表示不喜欢或拒绝,你需要分析原因并重新推荐。 - 【绝对指令】如果你看到【系统强提醒】提示用户已连续拒绝 3 次,你必须立刻执行反思:停止盲目调用搜索工具,在 Action: Finish 中向用户道歉,并主动询问 2-3 个具体问题(例如:是不是嫌太远?想看自然风光还是现代商业?是否带了老人小孩?)来深挖用户的隐藏偏好。 # 重要提示: - 如果用户提出了新的偏好,请优先使用 update_preference 工具记录。 - 推荐前必须使用 check_ticket_availability 查票,遇到售罄必须重新寻找备选。 - 当收集到足够信息且准备好回复用户时,使用 Action: Finish[最终答案] 格式结束。 # 输出格式要求: 你的每次回复必须严格遵循以下格式,包含一对Thought和Action: Thought: [你的思考过程和下一步计划] Action: [你要执行的具体行动] 请开始吧! """ # --- 实例化记忆管理器 --- memory_manager = MemoryManager() # --- 工具函数 --- def get_weather(city: str) -> str: url = f"https://wttr.in/{city}?format=j1" try: response = requests.get(url) response.raise_for_status() data = response.json() current_condition = data["current_condition"][0] weather_desc = current_condition["weatherDesc"][0]["value"] temp_c = current_condition["temp_C"] return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度" except Exception as e: return f"错误:{e}" def get_attraction(city: str, weather: str) -> str: """根据城市和天气搜索推荐景点(函数内部主动读取记忆)""" prefs_summary = memory_manager.get_preferences_summary() # 将记忆直接拼接到搜索词中 query = f"{city} {weather}天气 旅游景点推荐 {prefs_summary}" api_key = os.environ.get("TAVILY_API_KEY") if not api_key: return "错误:未配置TAVILY_API_KEY。" tavily = TavilyClient(api_key=api_key) try: response = tavily.search(query=query, search_depth="basic", include_answer=True) return response.get("answer", "无结果") except Exception as e: return f"错误:{e}" def check_ticket_availability(attraction: str, date: str = "今天") -> str: """ 检查景点门票是否售罄的模拟工具 """ # 模拟热门景点售罄的黑名单 sold_out_spots = ["故宫", "故宫博物院", "国家博物馆", "八达岭长城"] for spot in sold_out_spots: if spot in attraction: return f"【门票售罄】非常抱歉,系统显示 {attraction} 在 {date} 的门票已经全部售罄!请务必为您寻找其他备选景点。" return ( f"【余票充足】好消息,{attraction} 在 {date} 目前还有余票,可以正常推荐给用户。" ) # 注册所有工具,包括记忆更新和查票 available_tools = { "get_weather": get_weather, "get_attraction": get_attraction, "update_preference": memory_manager.update_preference, "check_ticket_availability": check_ticket_availability, } # --- LLM 客户端 --- class OpenAICompatibleClient: def __init__(self, model, api_key, base_url): self.client = OpenAI(api_key=api_key, base_url=base_url) self.model = model def generate(self, prompt, system_prompt): messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": prompt}, ] try: response = self.client.chat.completions.create( model=self.model, messages=messages, stream=False, temperature=0.1, max_tokens=1024, # 已修复:扩大字数限制 stop=["Observation:"], # 已修复:移除换行符拦截 ) # --- 异常拦截逻辑 --- if getattr(response, "choices", None) is None or len(response.choices) == 0: return f"API 返回了异常数据 (请检查模型ID、API Key或余额)。原始返回信息:\n{response}" return response.choices[0].message.content.strip() except Exception as e: return f"错误:{e}" # --- 意图判断工具 --- def check_rejection_intent(user_text: str, current_llm: OpenAICompatibleClient) -> bool: """调用大模型判断用户是否在拒绝/不满意当前推荐""" intent_system_prompt = """ 你是一个高精度的意图判断分类器。你的任务是判断用户的输入是否属于对上一次推荐的“纯粹拒绝”或“不满意”。 【核心判断规则】: 1. 拒绝 (REJECT):用户明确表示不喜欢、不去、换一个、没意思、不对等,且**没有**提供任何有实质意义的新偏好或补充条件。 2. 其他 (OTHER): - 用户同意推荐。 - 用户没有拒绝推荐的内容,而是提出了全新的需求或目的地。 - **用户正在回答关于偏好的提问**(例如:补充说明“人太多”、“想去适合拍照打卡的地方”、“我是一个人去”等具体条件)。 注意:只要用户的话语中包含了具体的偏好标签(如人数、风格、原因),这说明用户在积极推进对话,必须判定为 OTHER! 你只能输出两个结果之一,不能有任何多余的废话: REJECT 或 OTHER """ try: response = current_llm.generate( prompt=user_text, system_prompt=intent_system_prompt ) if "REJECT" in response.upper(): return True return False except Exception as e: print(f"意图分析出错: {e}") return False # --- 配置 --- # 请确保环境变量和密钥都是正确的 API_KEY = "xxxx" BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1" MODEL_ID = "qwen-plus" os.environ["TAVILY_API_KEY"] = ( "xxxxx" ) llm = OpenAICompatibleClient(model=MODEL_ID, api_key=API_KEY, base_url=BASE_URL) # --- 主循环 (多轮对话与反思机制) --- print("=" * 40) print("智能旅行助手已启动!(输入 '退出' 结束对话)") print("=" * 40) prompt_history = [] rejection_count = 0 # 连续拒绝计数器 while True: user_input = input("\n[你]: ") if user_input.lower() in ["退出", "quit", "exit"]: print("旅行助手已退出。再见!") break # 1. 智能意图检测:让大模型判断是不是拒绝 is_rejecting = check_rejection_intent(user_input, llm) if is_rejecting: rejection_count += 1 print( f"【系统日志】大模型判定用户意图为:拒绝,当前连续拒绝次数: {rejection_count}" ) else: rejection_count = 0 # 判定为提出新需求或同意,重置计数器 print("【系统日志】大模型判定用户意图为:非拒绝,计数器重置。") # 2. 触发反思机制 if rejection_count >= 3: system_warning = "【系统强提醒】用户已连续拒绝了你的3次推荐!请立即停止盲目搜索,执行反思机制:向用户道歉,并询问他们更具体的偏好方向(如人群、距离、特定活动等)。" prompt_history.append(system_warning) rejection_count = 0 # 触发后重置,等待下一次的一轮交互 prompt_history.append(f"用户请求: {user_input}") # 3. 智能体的内在思考循环 (最多执行6步以防死循环) for i in range(6): current_system_prompt = ENHANCED_SYSTEM_PROMPT.format( preferences_summary=memory_manager.get_preferences_summary() ) full_prompt = "\n".join(prompt_history) llm_output = llm.generate(full_prompt, system_prompt=current_system_prompt) # 提取 Thought 和 Action (兼容多行) match = re.search( r"^Thought:.*?\nAction:.*$", llm_output, re.MULTILINE | re.DOTALL ) if match: llm_output = match.group(0).strip() prompt_history.append(llm_output) # ✅ 修复点 1:使用 re.DOTALL 抓取 Action 后的所有换行和内容 action_match = re.search(r"Action:\s*(.*)", llm_output, re.DOTALL) if not action_match: prompt_history.append("Observation: 错误:未找到 Action,请重试。") continue action_str = action_match.group(1).strip() action_str = ( action_str.replace("(", "(") .replace(")", ")") .replace("“", '"') .replace("”", '"') ) # 如果智能体决定回复用户,结束内部思考循环 if action_str.startswith("Finish"): # ✅ 修复点 2:放宽匹配条件,提取 Finish[] 中的所有内容(包括多行排版) final_answer = re.search(r"Finish\[(.*)", action_str, re.DOTALL) final_ans_text = final_answer.group(1) if final_answer else action_str # 清理末尾可能残留的 ']' if final_ans_text.endswith("]"): final_ans_text = final_ans_text[:-1] print(f"\n[助手]: {final_ans_text.strip()}") break # 执行工具调用 try: tool_name = re.search(r"(\w+)\(", action_str).group(1) args_str = re.search(r"\((.*)\)", action_str).group(1) kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str)) if tool_name in available_tools: observation = available_tools[tool_name](**kwargs) else: observation = f"错误:未定义的工具 '{tool_name}'" except Exception as e: observation = f"错误:工具解析失败 {e}" prompt_history.append(f"Observation: {observation}") # 控制历史记录长度,防止上下文超载 if len(prompt_history) > 15: prompt_history = prompt_history[-15:]
最后的输出结果如下:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)