【Springboot升级AI】(大模型部署)LangChain4j、会话记忆、隔离消失持久化问题、ollama、RAG知识库、Tools工具
观看黑马课程进行总结,方便回忆
黑马程序员LangChain4j从入门到实战项目全套视频课程,涵盖LangChain4j+ollama+RAG,Java传统项目AI智能化升级_哔哩哔哩_bilibili
一、大模型api 传入与响应参数

二、LangChain4j
jdk要求17及以上!!!
必备依赖与格式:
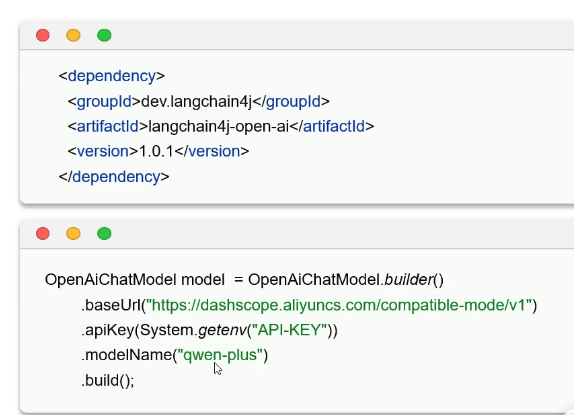
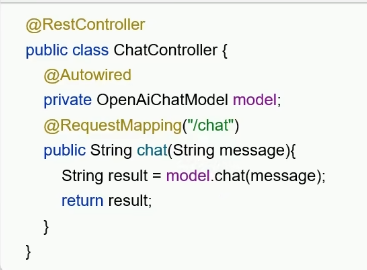
传统方法:
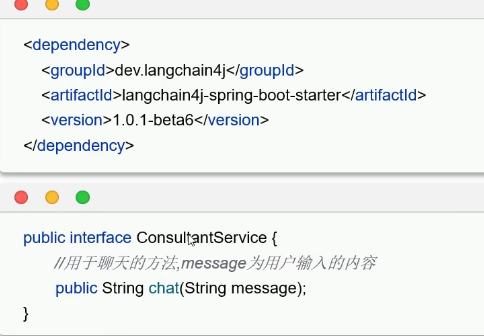
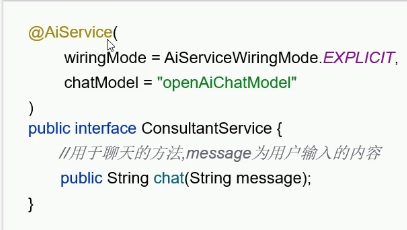
引入工具类,更方便:
三、流式调用stream:
引入依赖
配置流式模型对象
切换接口返回值类型 Flux<String>,service和control都改
指定streamingChatModel的模型
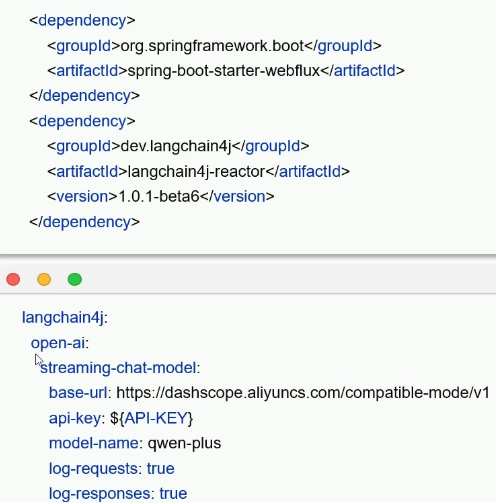

四、消息注解 @SystemMessage @UserMessage
@SystemMessage系统自我设定
可直接写,字多可放txt文件

@UserMessage用户设定
可和消息混合只认{{it}},也可加@V注解 自定义{{}}的内容

五、会话记忆
所有的会话,都先存储到后端的存储里,一起发给大模型
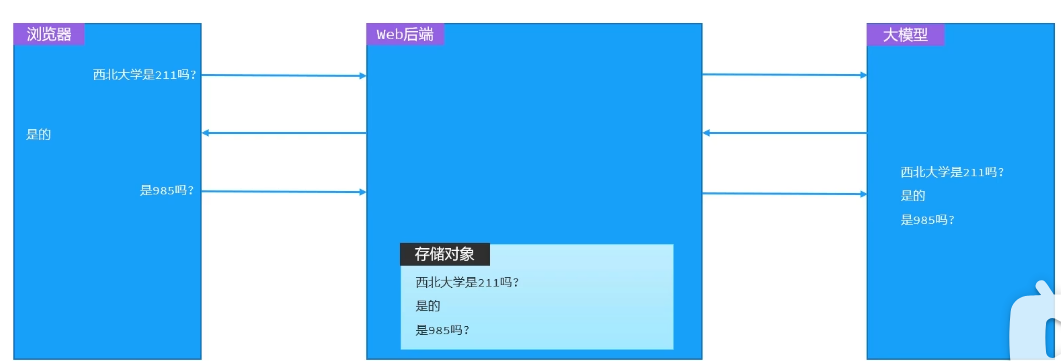
定义会话对象ChatMemory:
ChatMemory下分两个实现方案:TokenWindowsChatMemory和 MessageWindowChatMemory
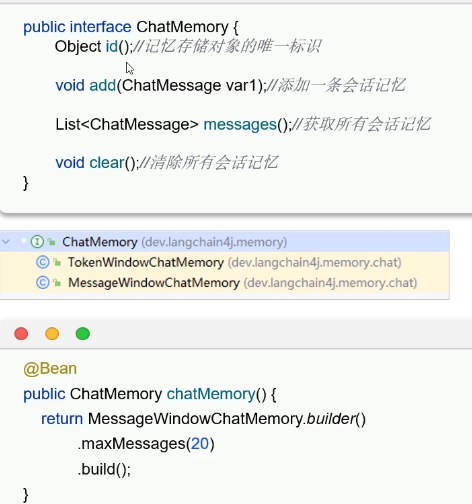
配置会话对象:@AiService里装上ChatMemory
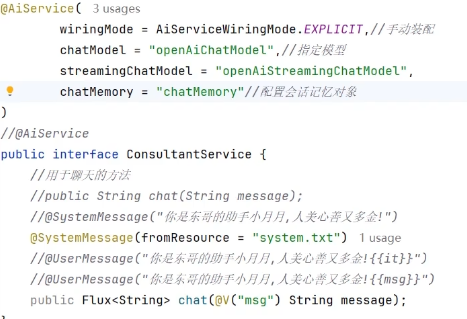
@V与@UserMessage配套使用
六、会话记忆隔离(串味问题)
两个会话主题不一样,发生了串味,混起来回答
解决方法:每个会话有自己的memoryId,例如上面ChatMemory的id()。设置一个会话容器,当用户发送会话1时,将会话1存入容器。当用户发送下一个会话,先去容器找,有就使用已有的,没有就新建会话
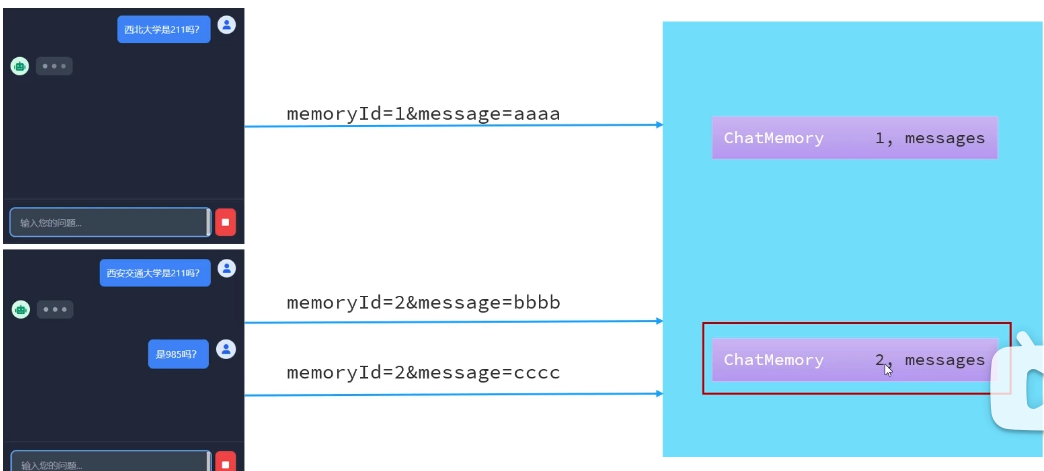
具体实现:

1、定义容器:get来看是否有id

2、配置容器:
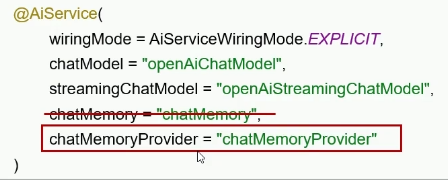
3、给service添加memorId,消息多了要写清楚是user还是system
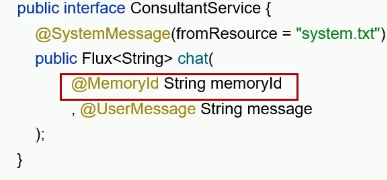
4、control接口的chat接口接收memoryId

七、重启后会话消失
store负责管理会话记录

在store中包含三种具体方法:

ChatMemoryStore靠以下两种方法实现:默认SingleSlot

SingleSlotChatMemoryStore内部:通过List表存储Message

解决办法:由于store重启会消失,因此将会话messages放在其他地方如Redis
会话记忆持久化(Redis)
redis配置就不赘述了,直接上memory操作
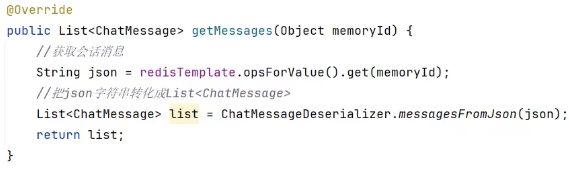
1、提供ChatMemoryStore实现类:对以下方法进行重写
新建RedisChatMemoryStore文件

重写:(注意加入@Repository将当前实现类交给容器)
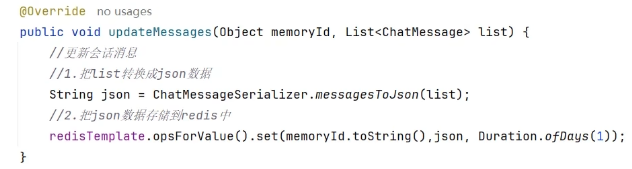

2、将重写好的ChatMemoryStore方法交给MessWindowsChatMemory使用

八、RAG知识库(向量数据库)
原理:
检索增强生成,通过检索外部知识库来增强大模型的能力
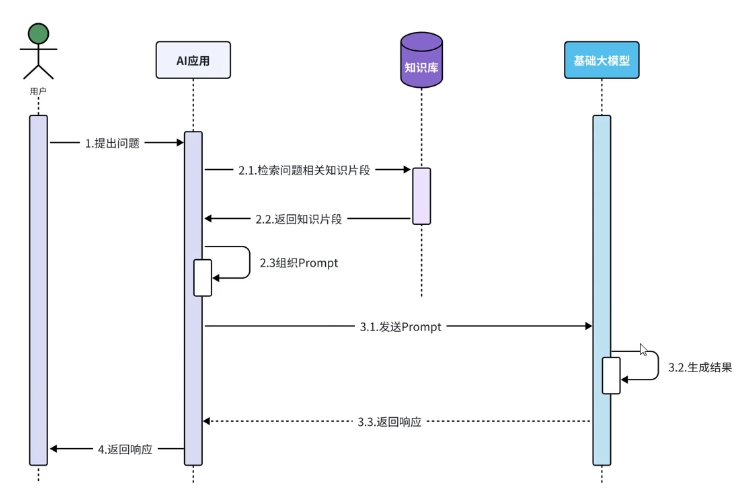
在多维里也适用:

将文本进行切割片段,这些片段进入向量模型 生成向量Embeddings,最后一起存入向量数据库
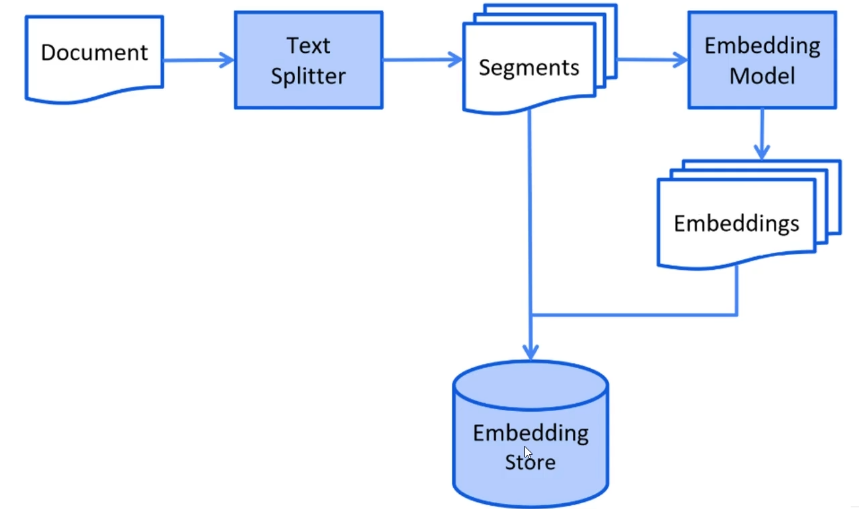
用户的问题 先进向量模型生成向量,存入向量数据库,进行余弦相似度匹配,把相关的向量片段和会话一起发给大模型
操作1 :构建向量数据库-操作对象
1、引入依赖

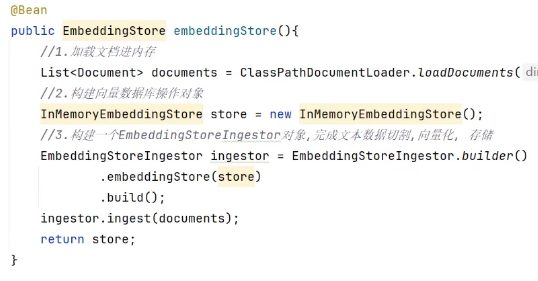
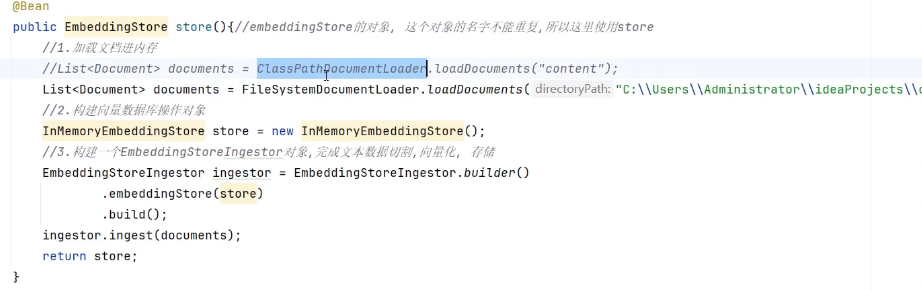
2、加载知识数据文档
![]()
3、构建向量数据库操作对象
![]()
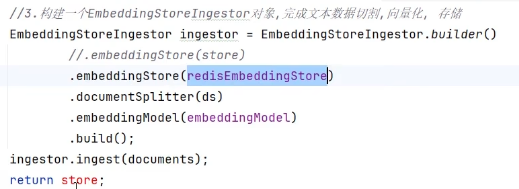
4、把文档切割、向量化并存在向量数据库中

总结在下面:EmbeddingStore记得改名,依赖已内置,不能重名
操作2 :构建向量数据库-检索对象
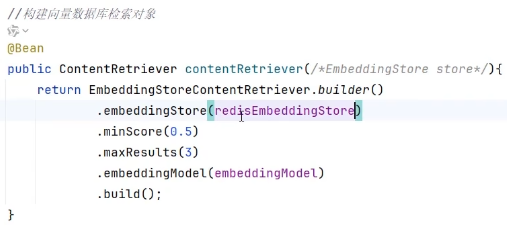
1、构建检索对象
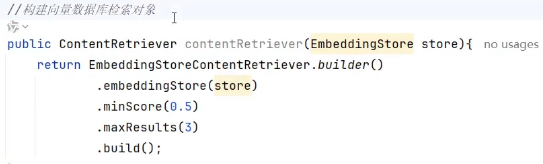
检索对象store、结果数3个、最小余弦分数0.6
2、配置检索对象


九、RAG核心API
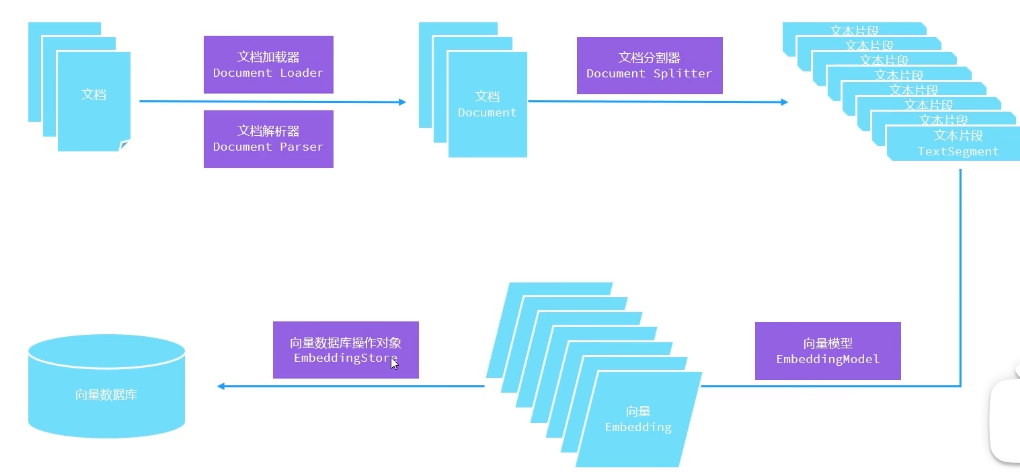
1、文档加载器
FileSystemDocumentLoader 根据本地磁盘绝对路径加载
ClassPathDocumentLoader 相对于类路径加载
UrlDocumentLoader 根据url路径加载
之前是ClassPathDocumentLoader,现在换成FileSystemDocumentLoader
2、文档解析器
解析加载器加载的内容,将非文本变成纯文本

new一下替换就行

3、文档分割器

片段之间设置重叠内容,可设置字数。这样上个片段的结尾内容会添加到下个片段开头。
构建文本分割器:

使用文本分割器:

4、向量模型
把文档分割后的内容、用户查询时输入的内容向量化
内置的向量模型比较拉胯,需要引入大厂的
配置
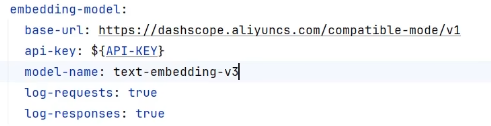

5、EmbeddingStore
操作向量数据库

给构建部分注入
给检索注入
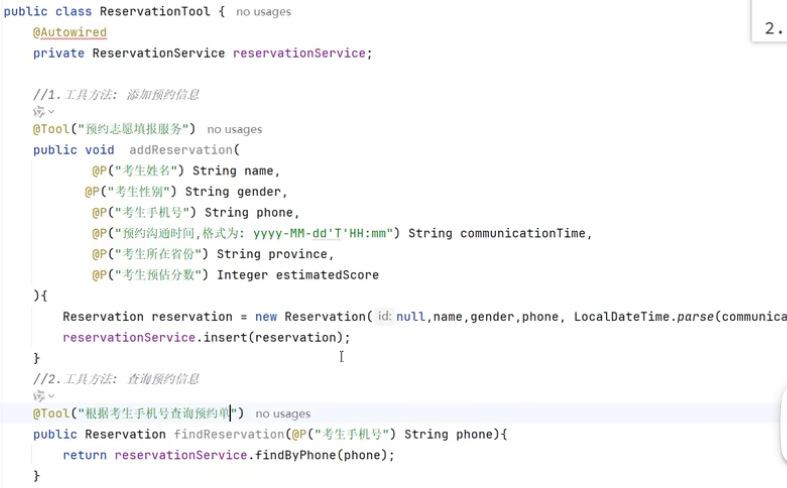
十、Tools工具


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)