OpenAI重回巅峰:GPT‑5.5全球SOTA,碾压Opus 4.7
OpenAI正式发布GPT-5.5。OpenAI给GPT‑5.5的定位是“为真实工作而生的新一代智能”。你丢给它一坨乱七八糟的多步骤任务,它能自己规划、调用工具、检查结果、处理歧义,一路把活干完。编码、科研、办公文档、数据操作,它在Agent(智能体)方向上的进步比任何一次版本迭代都要明显。这个模型的核心变化是能力重心从"对话式回答"转向"自主完成任务",编码能力在Terminal-Bench 2
OpenAI正式发布GPT-5.5。

OpenAI给GPT‑5.5的定位是“为真实工作而生的新一代智能”。
你丢给它一坨乱七八糟的多步骤任务,它能自己规划、调用工具、检查结果、处理歧义,一路把活干完。
编码、科研、办公文档、数据操作,它在Agent(智能体)方向上的进步比任何一次版本迭代都要明显。
这个模型的核心变化是能力重心从"对话式回答"转向"自主完成任务",编码能力在Terminal-Bench 2.0上拿到了82.7%的当前最高分。
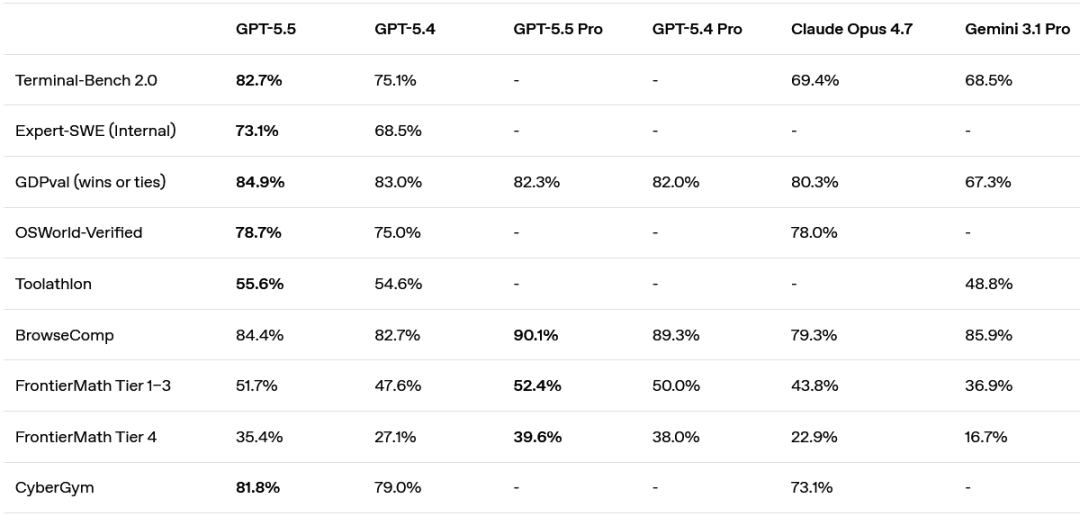
模型能力表现
在过去的一年里,我们看到 AI 极大地加速了软件工程的发展。
同样的变革正开始延伸到科学研究和人们在计算机上进行的更广泛的工作中。
OpenAI 的目标是为智能体 AI 构建全球基础设施,使世界各地的人们和企业能够利用 AI 完成工作。
在这些领域中,GPT‑5.5 不仅更智能,而且在处理问题时更高效,能以更少的 Token 和更少的重试次数获得更高质量的输出。
Artificial Analysis 的编程指数中,GPT‑5.5 以竞争对手前沿编程模型一半的成本,提供了最先进的智能水平。
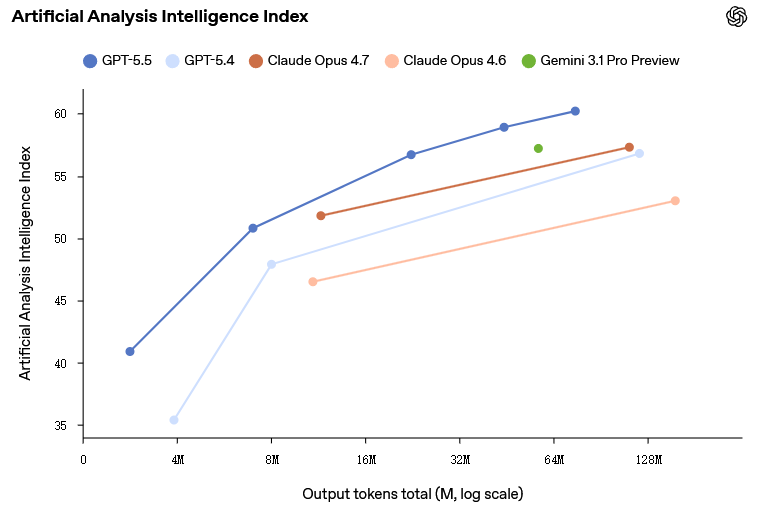
Artificial Analysis 智能指数包含 AA-LCR、AA-Omniscience、CritPt、GDPval-AA、GPQA Diamond、Humanity’s Last Exam、IFBench、SciCode、Terminal-Bench Hard、τ²-Bench Telecom 这 10 项评估,是由外部机构运行的 的加权平均值。
GPT‑5.5 是迄今为止最强的智能体编程模型。
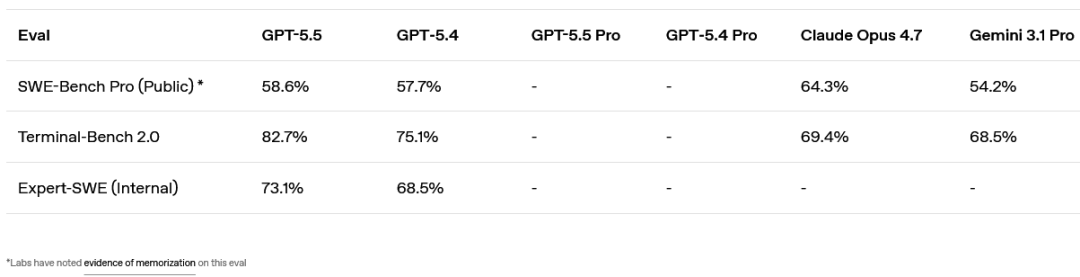
在需要规划、迭代和工具协调的复杂命令行工作流测试 Terminal-Bench 2.0 上,它达到了 82.7% 的业界最高准确率。
在评估真实 GitHub 问题解决的 SWE-Bench Pro 上,它达到了 58.6%,单次通过端到端解决的任务比以前的模型更多。
在针对长周期编程任务的内部前沿评估 Expert-SWE(人类预估完成时间中位数为 20 小时)上,GPT‑5.5 也优于 GPT‑5.4。
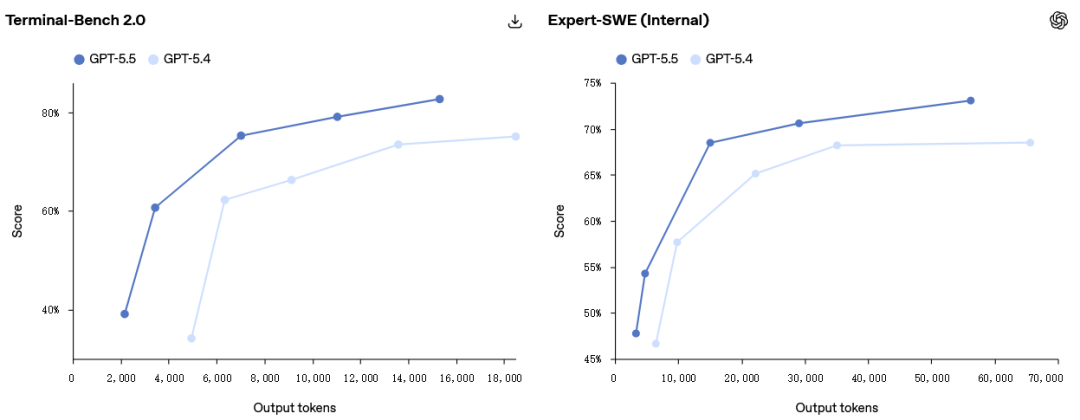
在这三项评估中,GPT‑5.5 在使用更少 Token 的同时,得分均高于 GPT‑5.4。
该模型的编程优势在 Codex 中表现得尤为明显,它可以承担从实现、重构到调试、测试和验证等各种工程工作。GPT‑5.5 在真实工程工作所依赖的行为上表现更好,例如在大型系统中保持上下文、推理模糊的故障、使用工具检查假设,以及在周围的代码库中贯彻修改。
例如,简单提示词:“用 Three.js 做一个 UFO 射击游戏,玩家控制坦克击落头顶飞过的飞碟,低多边形但要好看,先给出完整文件结构和需要改动的文件清单,再写全部代码,完成之前不许停”。
GPT-5.5 从文件结构到 Three.js 渲染到射击判定,一口气交付了一个可玩的 3D 游戏。
,时长00:14
测试过该模型的高级工程师表示,在推理和自主性方面,GPT‑5.5 明显强于 GPT‑5.4 和 Claude Opus 4.7,它能够提前发现问题,并在无需明确提示的情况下预测测试和审查需求。
一位 NVIDIA 的早期体验工程师甚至表示:“失去 GPT‑5.5 的访问权感觉就像被截肢了一样。”
自主完成知识型工作
GPT‑5.5 擅长编程的优势,同样使其在计算机上的日常工作中表现出色。
由于该模型更善于理解意图,它可以更自然地完成知识型工作的整个循环:查找信息、理解重点、使用工具、检查输出,并将原始材料转化为有用的东西。
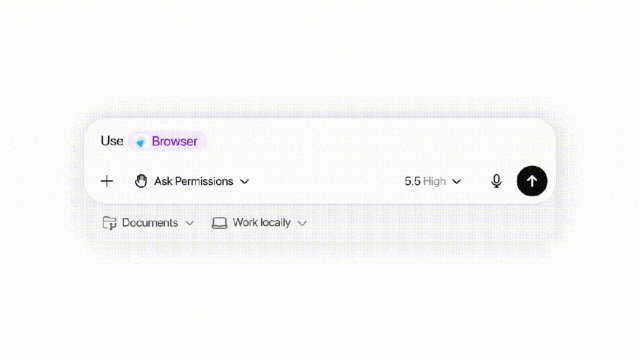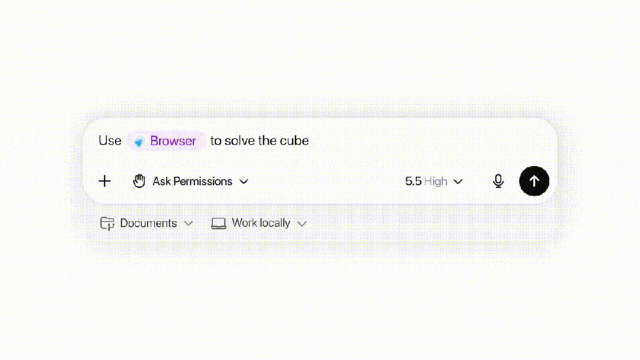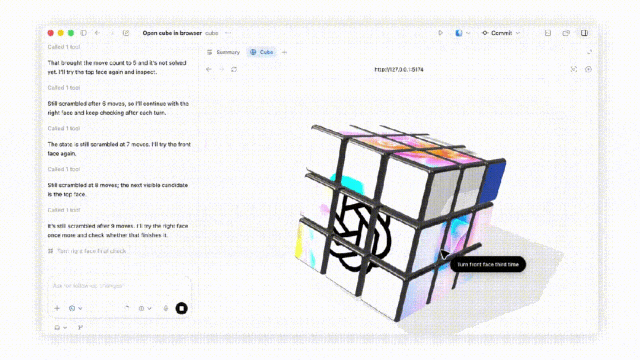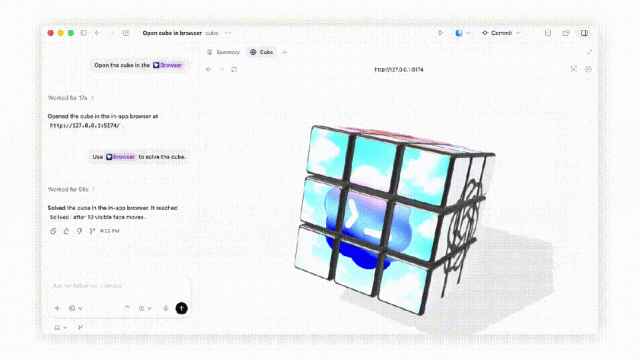

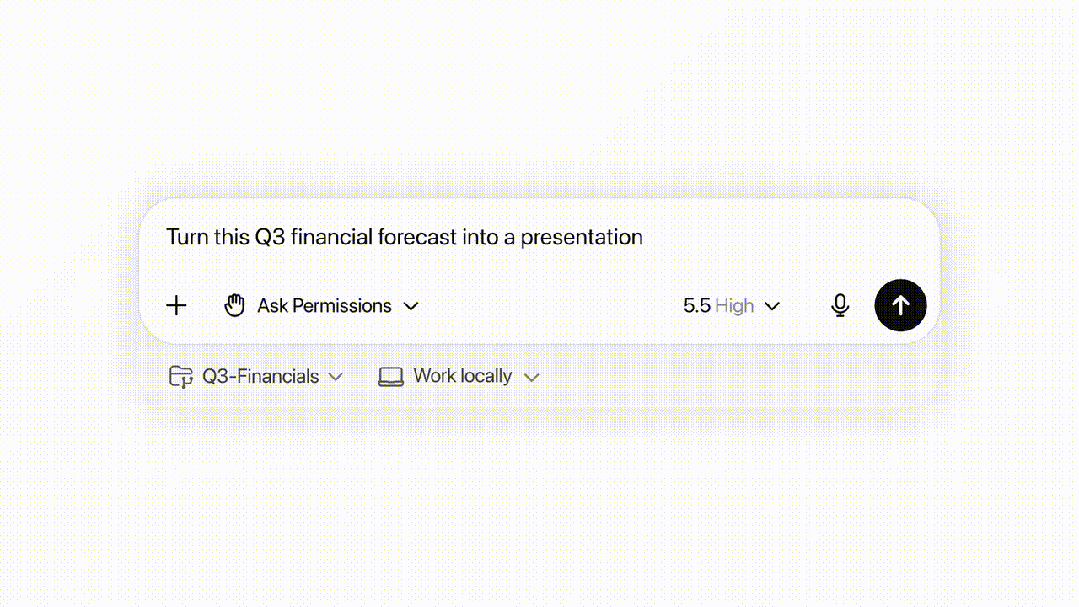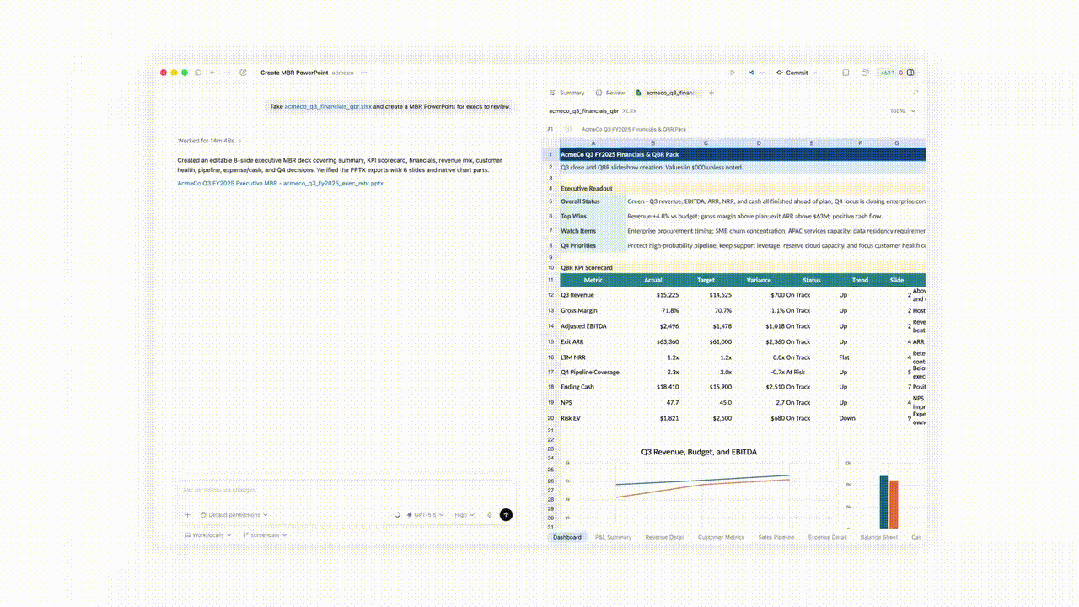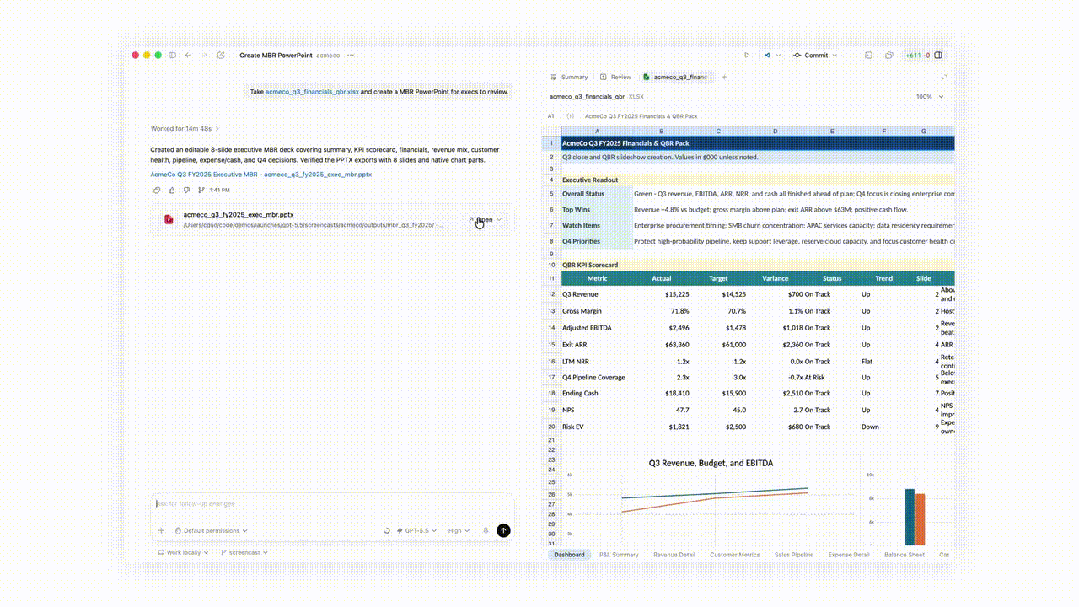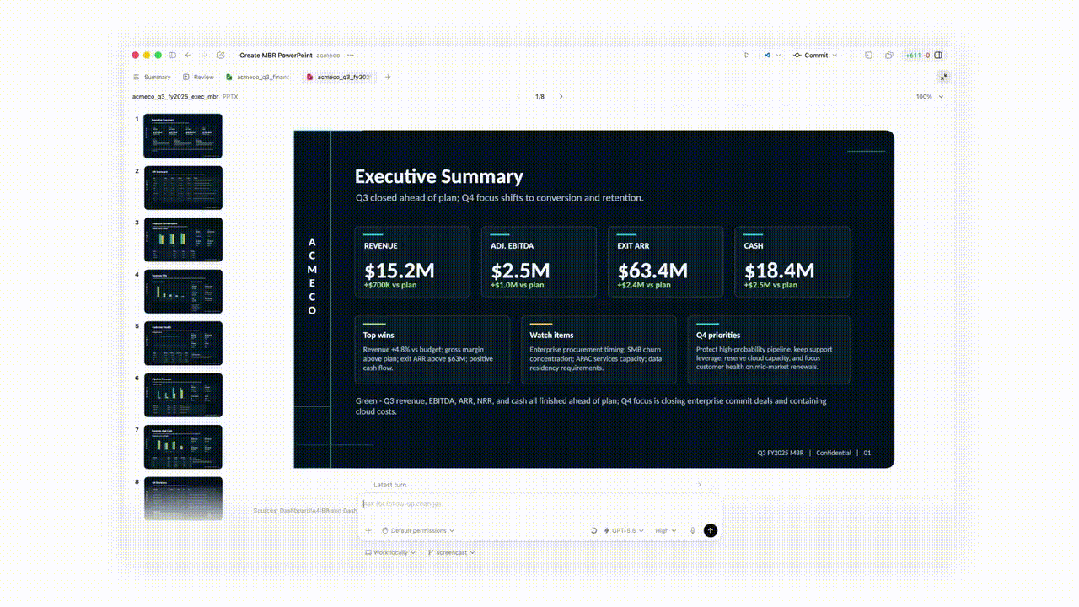
在 Codex 中,GPT‑5.5 在生成文档、电子表格和幻灯片演示方面优于 GPT‑5.4。
结合 Codex 的计算机使用技能,GPT‑5.5 可以和你一起使用电脑:看到屏幕上的内容、点击、打字、导航界面,并精确地在工具之间切换。

OpenAI 自己介绍,团队已经在实际工作流程中使用了这些优势。
公司超过 85% 的员工每周都在使用 Codex,涵盖软件工程、财务、通讯、营销、数据科学和产品管理等部门。
在通讯团队,他们使用 Codex 中的 GPT‑5.5 分析了六个月的演讲请求数据,构建了评分和风险框架,并验证了一个自动化 Slack 代理,以便低风险请求可以自动处理,而高风险请求仍路由给人工审核。
在财务团队,他们使用 Codex 审查了 24,771 份总计 71,637 页的 K-1 税表,该工作流程排除了个人信息,帮助团队比上一年提前两周完成了任务。
在走向市场(Go-to-Market)团队,一位员工自动化了每周业务报告的生成,每周节省了 5-10 个小时。

GPT‑5.5 在测试智能体跨 44 个职业生成规范知识工作能力的 GDPval 上,GPT‑5.5 得分为 84.9%。
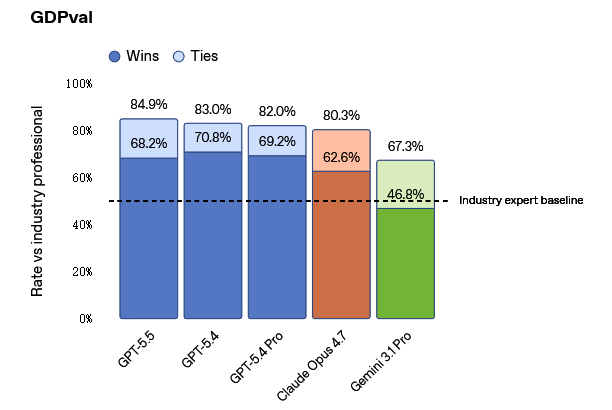
在衡量模型是否能独立操作真实计算机环境的 OSWorld-Verified 上,它达到了 78.7%。
在测试复杂客户服务工作流的 Tau2-bench Telecom 上,它在没有提示调优的情况下达到了 98.0%。
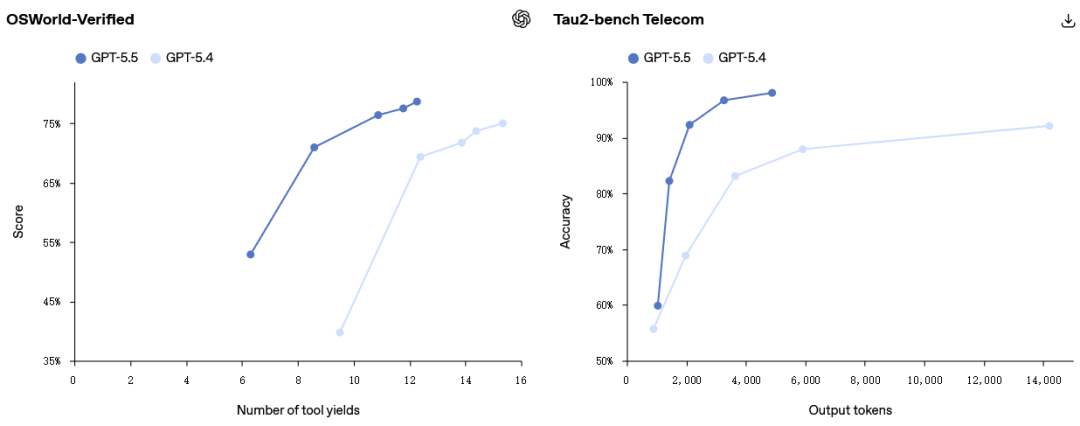
GPT‑5.5 在其他知识型工作基准测试中也表现出色:FinanceAgent 上得分为 60.0%,内部投资银行建模任务上为 88.5%,OfficeQA Pro 上为 54.1%。
科学研究更强
GPT‑5.5 在科学和技术研究工作流方面也突出,这些工作流需要研究人员探索想法、收集证据、测试假设、解释结果,并决定下一步尝试什么。
GPT‑5.5 比其他模型更能坚持在这个循环中推进。
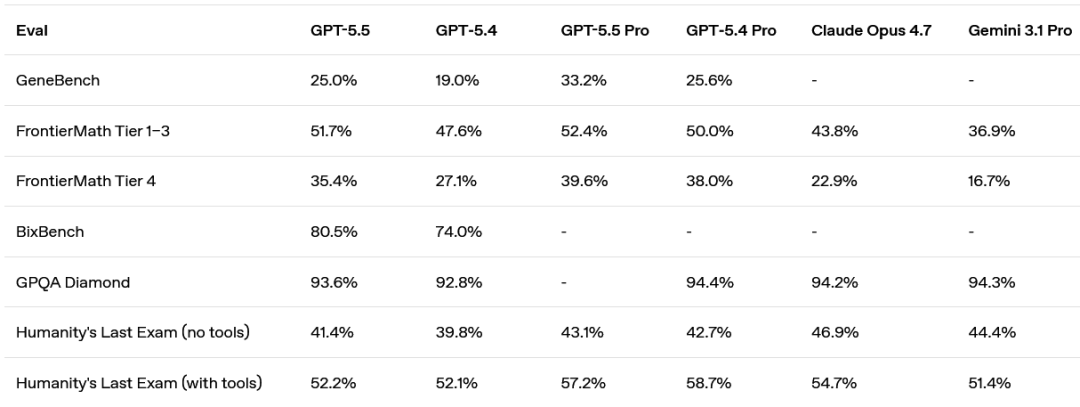
在 GeneBench(一项专注于遗传学和定量生物学中多阶段科学数据分析的新评估)上,GPT‑5.5 相比 GPT‑5.4 有明显提升。
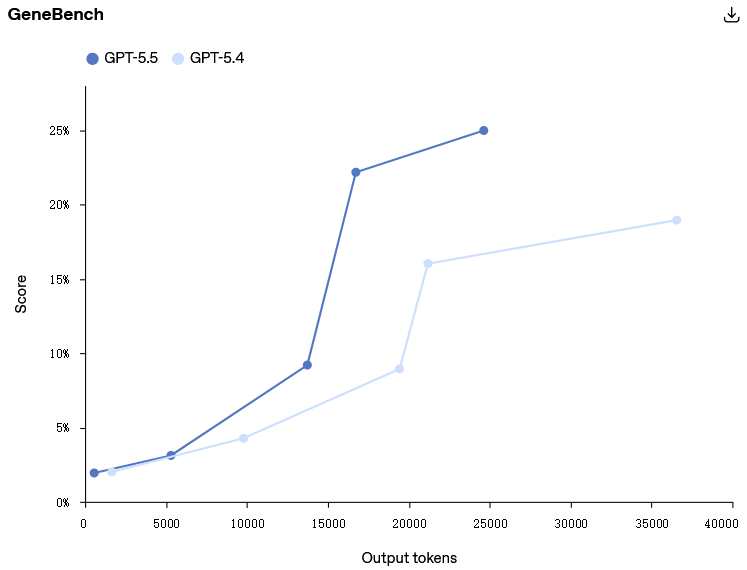
这些问题要求模型在监督指导极少的情况下,对潜在模糊或错误的数据进行推理,解决隐藏的混杂因素或质控(QC)失败等现实障碍,并正确实施和解释现代统计方法。
同样,在 BixBench(一项围绕真实世界生物信息学和数据分析设计的基准测试)上,GPT‑5.5 在已公布分数的模型中取得了领先性能。
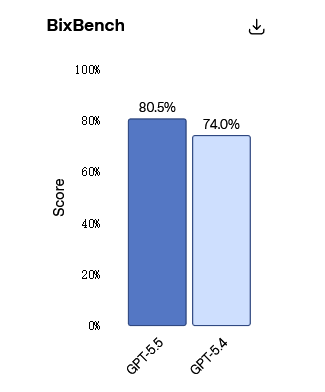
该模型已经可以作为真正的“共创科学家”(co-scientist),有意义地加速生物医学前沿研究的进展。
在一个例子中,带有自定义工具的 GPT‑5.5 内部版本,帮助发现了一个关于拉姆齐数(Ramsey numbers)的新证明,拉姆齐数是组合学的核心对象之一。
组合学研究离散对象如何组合在一起:图、网络、集合和模式。拉姆齐数大致探讨的是一个网络必须有多大,才能保证某种秩序必然出现。
这一领域的研究结果很罕见,且通常在技术上非常困难。
GPT‑5.5 找到了一个关于非对角拉姆齐数长期渐近事实的证明,该证明后来在 Lean 中得到了验证。

GPT‑5.5 不仅仅贡献代码或解释,而是在核心研究领域,提供了一个令人惊讶且有用的数学论证的具体例证。
推理效率与定价
GPT‑5.5 是与 NVIDIA GB200 和 GB300 NVL72 系统共同设计、训练和部署的。
Codex 和 GPT‑5.5 已经共同促进 AI 的进化。
Codex 帮助团队更快地从想法过渡到可基准测试的实现,勾勒方法轮廓,串联实验,并帮助确定哪些优化值得深入投入。GPT‑5.5 帮助找到并实现了堆栈本身的关键改进。也就是模型帮助改进了为其提供服务的基础设施。
其中一项改进是负载均衡和分区启发式算法。为了更好地利用 GPU,Codex 分析了几周的生产流量模式,并编写了自定义启发式算法,以最佳方式对工作进行分区和平衡。这一努力使 Token 生成速度提高了 20% 以上。
GPT‑5.5 正在向 ChatGPT 和 Codex 用户推出,而 GPT‑5.5 Pro 正在向 ChatGPT 中的 Pro、Business 和 Enterprise 用户推出。很快 GPT‑5.5 和 GPT‑5.5 Pro 将在 API 中可用。
在 ChatGPT 中,GPT‑5.5 Thinking 向 Plus、Pro、Business 和 Enterprise 用户开放。
专为更难问题和更高准确率工作设计的 GPT‑5.5 Pro 向 Pro、Business 和 Enterprise 用户开放。
在 Codex 中,GPT‑5.5具有 400K 上下文窗口。GPT‑5.5 还提供快速模式, Token 生成速度快 1.5 倍,成本为 2.5 倍。
对于 API 开发者,GPT-5.5 将很快在 Responses 和 Chat Completions API 中可用,价格为每 100 万输入 Token 5 美元,每 100 万输出 Token 30 美元,具有 100 万上下文窗口。
GPT-5.5-pro 将在 API 中发布,以实现更高的准确率,定价为每 100 万输入 Token 30 美元,每 100 万输出 Token 180 美元。
官方说,虽然 GPT‑5.5 的定价高于 GPT‑5.4,但它 Token 效率大幅提升。在 Codex 中,GPT‑5.5 使用比 GPT‑5.4 更少的 Token 就能提供更好的结果,同时继续在各个订阅级别提供充足的使用额度。
评估数据
最后来感受一下评估数据的震撼表现。
编码:
专业领域:
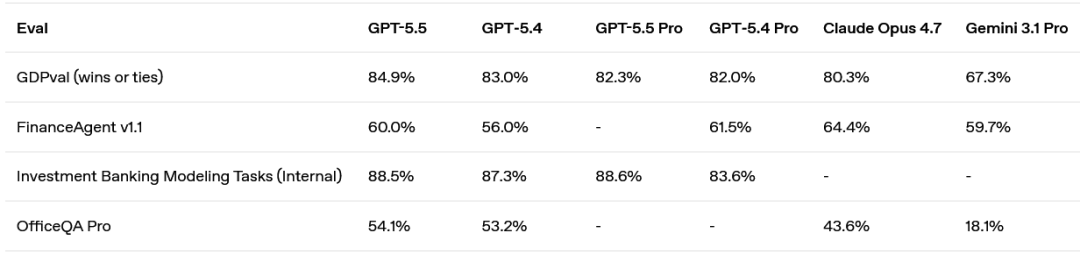
计算机使用与视觉:

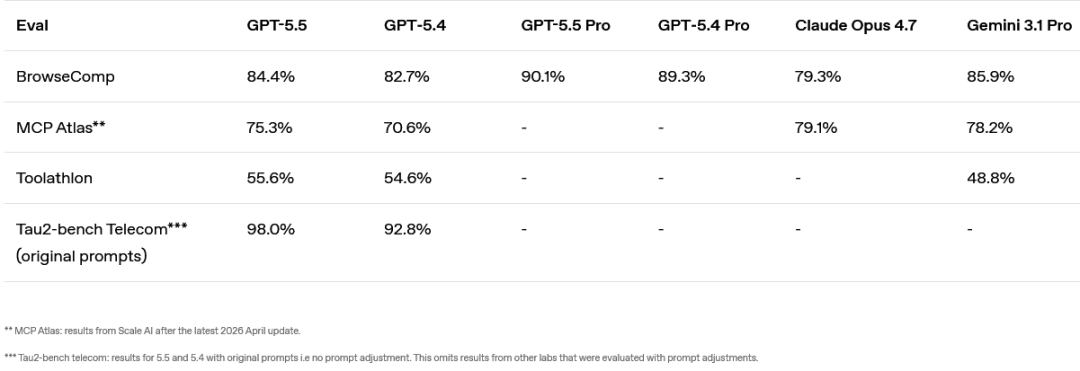
工具调用:
学术:
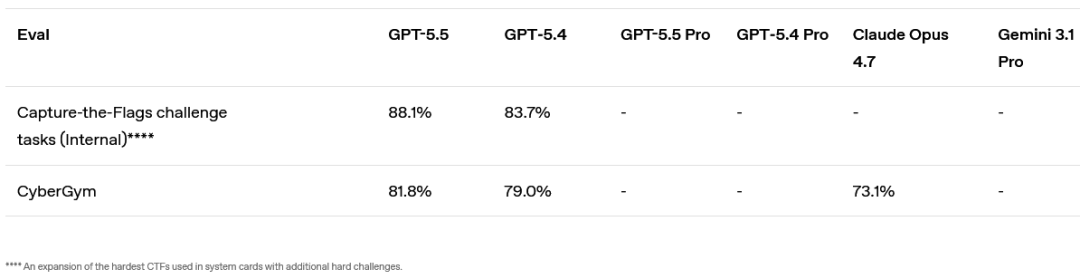
网络安全:
长上下文:
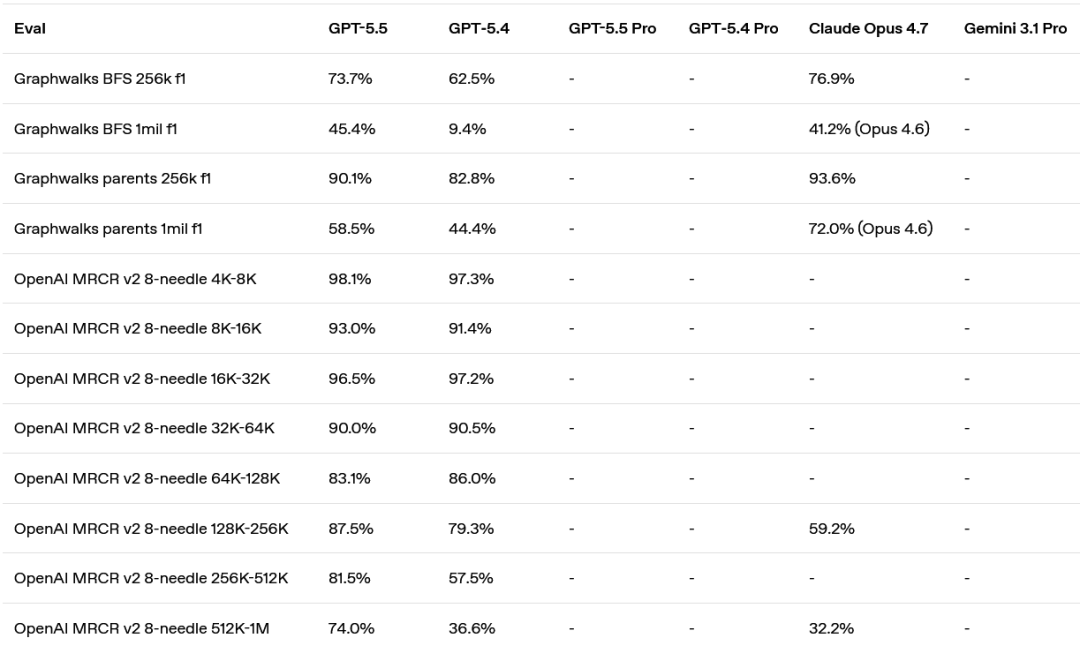
抽象推理:

参考资料:
https://openai.com/index/introducing-gpt-5-5/
https://cdn.openai.com/pdf/6dc7175d-d9e7-4b8d-96b8-48fe5798cd5b/Ramsey.pdf

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献278条内容
已为社区贡献278条内容

所有评论(0)