Java开发者AI转型第十四课!Spring AI向量数据库实操:检索召回与相似度检索实战详解
本文为 Java 开发者 AI 转型第十四节内容,基于 Spring AI 结合 Redis 向量库,详解 RAG 核心检索召回与相似度检索实战。讲解 Top-K、相似度阈值、元数据过滤三大核心参数,完成文档自动化入库、精准检索代码实操,重点剖析 Redis 元数据索引失效致命坑,梳理 RAG 检索常见问题与优化方案,助力开发者落地企业级向量检索业务。
大家好,我是直奔標杆!专注Java开发者AI转型之路,每节课都力求干货落地、实战导向,和各位同行一起深耕技术、直奔标杆~ 今天带来《Spring AI 零基础到实战》系列的第十四课,也是RAG架构核心环节的实战课,手把手教大家搞定向量数据库的检索召回与相似度检索,彻底解决“大海捞针”式的知识匹配难题!
回顾前几节课,我们已经完整跑通了ETL全流程——从文本抽取、智能切片,到向量化转换、最终入库,成功把私有文档变成高维空间的“浮点数矩阵”,稳稳存进了VectorStore这个“数字文件柜”里。
前置工作全部到位,真正的工程考验来了:当用户输入一个模糊的自然语言问题,比如“公司最新N+1离职赔偿怎么算?”,我们该如何从几万字的规章制度里,精准揪出有用的内容?这就是RAG(检索增强生成)架构中最关键的R(Retrieve,检索召回)环节,也是今天我们重点攻克的核心!
本节学习目标(建议收藏,对照实操)
-
底层解密:搞懂Spring AI如何自动将自然语言查询,转化为高维空间的“检索探针”;
-
参数调优:掌握决定检索质量的3个核心标尺——Top-K(截断策略)、Threshold(相似度及格线)、Metadata Filters(元数据过滤);
-
实战落地:熟练用SearchRequest构建器,写出带强过滤条件的相似度检索代码;
-
避坑指南:避开Spring AI搭配Redis向量库时,最容易踩的“元数据索引丢失”天坑(亲测踩过,分享解决方案)。
高维空间的“精准定位”:3个核心标尺搞定检索质量
很多同行第一次做向量检索,都会遇到“搜得不准、搜得太杂”的问题,其实核心就是没吃透这3个关键参数。咱们用通俗的比喻,结合实际场景,一次性讲明白(建议结合代码实操理解):
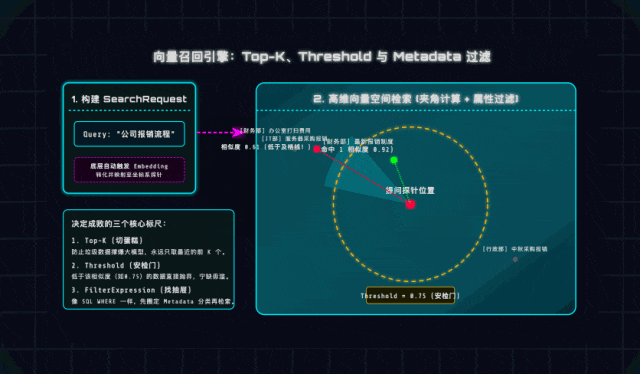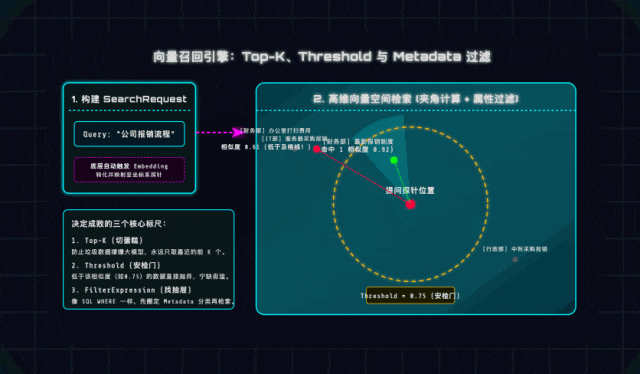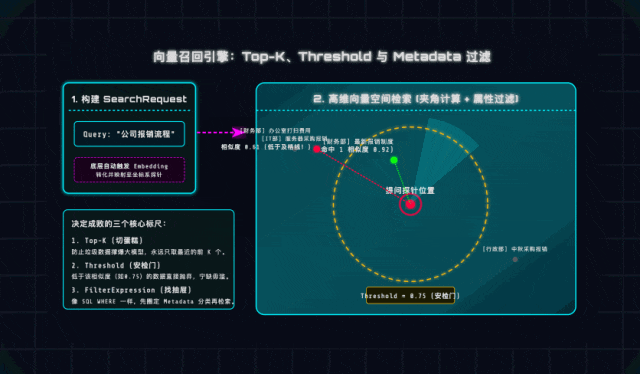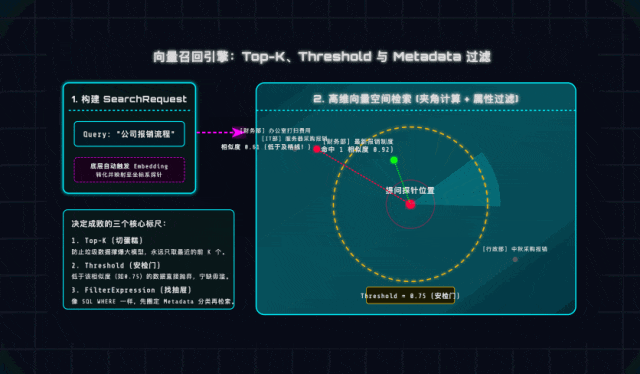
1. Top-K(切蛋糕策略)
大模型的Prompt上下文容量是有限的,就像一块蛋糕,我们不能把所有“疑似相关”的内容都塞进去。Top-K就是“只取距离探针最近的前K个切片”,一般推荐设置3~5个。
这里提醒大家一个坑:如果Top-K设得太大(比如20),不仅会浪费LLM API额度,还会导致大模型注意力分散,出现“Lost in the middle(中间注意力丢失)”现象,反而找不到重点——检索的核心是“精”,不是“多”!
2. Threshold(相似度安检门)
这是一个0~1之间的小数,相当于检索的“及格线”。比如用户在规章制度库里问“红烧肉怎么做”,距离最近的可能是“食堂安全管理办法”,但二者毫无关联。
设置合理的Threshold(比如0.75),就相当于给检索加了一道安检门:宁可告诉用户“未找到相关内容”,也不把无关数据喂给大模型,避免出现“答非所问”的尴尬,这也是生产环境必须注意的细节!
3. Metadata Filters(元数据抽屉)
实际开发中,很多文档会有明确的分类、年份等属性,比如《2023年报销标准》和《2026年报销标准》,单纯靠语义相似度很容易搜错。
Spring AI提供的FilterExpression,就像SQL的WHERE语句,能帮我们“精准找抽屉”——比如设置filter.eq("year", "2026"),就能直接过滤掉非2026年的文档,大幅减少干扰项,提升检索准确率。这一点在企业级项目中非常实用,建议大家重点掌握!
实战演练:Spring AI + Redis 全链路检索实操
理论讲完,直接上实战!咱们以Redis作为底层向量存储(高性能、易集成,企业常用),结合一份《2026年企业内部管理综合手册.md》,实现“自动化入库+精准检索”全流程,代码可直接复制到项目中测试(注释详细,新手也能看懂)。
第一步:自动化ETL入库(复用前序代码,优化细节)
先把文档自动读取、打元数据标签、智能切片、向量化入库,形成一条自动化流水线,避免手动复制粘贴的繁琐操作。
// 直奔標杆 实战代码:自动化ETL入库(可直接复用)
@Value("classpath:/docs/2026 年企业内部管理综合手册.md")
private Resource resource;
/**
* 阶段一:全自动ETL(抽取->打标记->切片->入库)
* 核心:给文档切片统一打元数据标签,方便后续过滤检索
*/
@Test
void ingestFileAutomatically() {
// 1. 抽取(Extract):自动读取Markdown文档,同时设置元数据
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withAdditionalMetadata(Map.of(
"filename", resource.getFilename(), // 文档名称(溯源用)
"doc_category", "COMPANY_POLICY", // 文档分类(企业制度)
"year", "2026" // 年份标签(核心过滤字段)
))
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(this.resource, config);
List<Document> rawDocuments = reader.get();
// 2. 转换(Transform):智能语义切片,避免语义割裂(复用我们之前封装的切分器)
SemanticTokenTextSplitter splitter = SemanticTokenTextSplitter.builder()
.withDefaultChinesePunctuations() // 支持中文标点,避免切在句子中间
.build();
List<Document> chunkedDocs = splitter.apply(rawDocuments);
// 3. 加载(Load):自动向量化并写入Redis(底层调用EmbeddingModel)
vectorStore.add(chunkedDocs);
System.out.println("向量化入库成功!共写入 " + chunkedDocs.size() + " 个切片(可根据切片数量调整Top-K)。");
}第二步:封装精准检索逻辑(核心代码,重点掌握)
入库完成后,编写带元数据过滤的检索逻辑。重点关注FilterExpressionBuilder的用法——它是Spring AI的抽象层,不管底层用Redis、PgVector还是Milvus,都能统一过滤语法,不用关心不同数据库的方言,跨库迁移更轻松!
/**
* 阶段二:带元数据过滤的精准向量检索
* @param query 用户自然语言查询
* @param targetYear 目标年份(过滤条件)
*/
void searchCompanyPolicy(String query, String targetYear) {
// 1. 初始化过滤器构建器(Spring AI提供,强类型,避免语法错误)
FilterExpressionBuilder filter = new FilterExpressionBuilder();
// 2. 构建SearchRequest,设置三大核心参数(Top-K、Threshold、过滤条件)
SearchRequest searchRequest = SearchRequest.builder()
.query(query) // 传入用户自然语言,底层自动转为向量
.topK(2) // 只取前2个最相关的切片(根据需求调整)
.similarityThreshold(0.75) // 相似度及格线:低于0.75的不返回
.filterExpression( // 硬过滤:只检索2026年的企业制度
filter.eq("year", targetYear).build()
)
.build();
// 3. 执行检索:计算向量夹角,返回符合条件的结果
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 检索结果诊断(便于调试,生产环境可优化为日志输出)
if (results.isEmpty()) {
System.out.println("在【" + targetYear + "】年的制度中,未找到高度相关的内容~");
return;
}
System.out.println("检索成功!共召回 " + results.size() + " 条相关记录:\n");
for (int i = 0; i < results.size(); i++) {
Document doc = results.get(i);
System.out.println("【命中知识 " + (i + 1) + "】(相似度得分: " + doc.getScore() + ")");
System.out.println("核心片段: " + doc.getText().trim());
System.out.println("溯源标签 (Metadata): " + doc.getMetadata() + "\n");
}
}第三步:测试验证(两种场景,验证过滤效果)
写两个测试用例,分别验证“错误年份过滤”和“正确条件检索”,看看我们的过滤逻辑是否生效,大家可以跟着跑一遍,加深理解。
测试场景A:搜索错误年份(验证Filter拦截效果)
// 测试:搜索2025年的加班打车报销政策(实际只有2026年数据)
@Test
void testSearchWrongYear() {
searchCompanyPolicy("晚上加班太晚了,自己打车能报销吗", "2025");
}运行结果(符合预期): 在【2025】年的制度中,未找到高度相关的内容~
测试场景B:正确条件检索(验证检索精准度)
// 测试:搜索2026年的加班打车报销政策(正确条件)
@Test
void testSearchCorrect() {
searchCompanyPolicy("晚上加班太晚了,自己打车能报销吗", "2026");
}运行结果(符合预期): 检索成功!共召回 1 条相关记录:
【命中知识 1】(相似度得分: 0.807824) 核心片段: 为保障夜间加班员工的人身安全,工作日晚上超过 22:00 (含) 下班的员工,可使用企业滴滴打车直接叫车回家,费用由公司企业账户统一代付,无需个人垫资和贴票。关于部门团建费用,每位转正员工每季度享有 200 元的团建活动经费... 溯源标签 (Metadata): {doc_category=COMPANY_POLICY, filename=2026 年企业内部管理综合手册.md, distance=0.192175, year=2026}
结果解析(重点划重点)
-
语义穿透:用户问“加班太晚”,精准匹配到“超过22:00下班”,相似度0.807,超过0.75的及格线,说明检索精准;
-
防伪溯源:Metadata中的filename、year等标签,可直接用于前端展示引用来源,避免大模型“无中生有”,这也是RAG解决幻觉问题的关键;
-
过滤生效:错误年份无结果,正确年份精准召回,证明Metadata Filters配置有效。
避坑指南:Spring AI + Redis 过滤失效?这个天坑必看!
这是我实操时踩过的真实坑,相信很多同行也会遇到:明明数据已经存入Redis,但加上filter.eq("year", "2026")后,却搜不到任何结果!其实问题出在“元数据索引未建立”。
问题原因
Spring AI的spring-ai-starter-vector-store-redis依赖会自动装配RedisVectorStore,但默认情况下,不会为我们自定义的Metadata字段(比如year、doc_category)建立倒排索引。Redis的RediSearch引擎没有索引,过滤查询会直接返回空集——不是数据没存进去,是搜不到!
破局方案:覆盖默认Bean,手动配置元数据索引
只需在配置类中加入以下代码,明确告诉Redis为哪些Metadata字段建立索引,就能解决问题(代码可直接复制,注释详细):
/**
* 覆盖默认RedisVectorStore Bean,解决元数据过滤失效问题
* 核心:显式配置metadataFields,为自定义元数据建立索引
*/
@Bean
public RedisVectorStore vectorStore(EmbeddingModel embeddingModel, RedisVectorStoreProperties properties,
JedisConnectionFactory jedisConnectionFactory,
ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<VectorStoreObservationConvention> customObservationConvention,
BatchingStrategy batchingStrategy) {
// 初始化Redis连接(复用项目中的连接配置)
JedisPooled jedisPooled = new JedisPooled(jedisConnectionFactory.getHostName(), jedisConnectionFactory.getPort());
return RedisVectorStore.builder(jedisPooled, embeddingModel)
.initializeSchema(true) // 允许自动建表(首次运行需开启)
.indexName(properties.getIndexName()) // 复用配置文件中的索引名称
.prefix(properties.getPrefix())
// 核心配置:为元数据字段建立索引,根据字段类型选择tag或text
.metadataFields(
RedisVectorStore.MetadataField.tag("doc_category"), // tag:精确匹配(eq)
RedisVectorStore.MetadataField.tag("year"), // tag:年份精确匹配
RedisVectorStore.MetadataField.text("filename") // text:文件名模糊匹配
).build();
}重要提醒(必看!)
如果之前已经运行过旧代码,Redis中已经建立了没有元数据索引的旧索引,就算修改了上述Bean,Spring AI也不会主动修改旧索引结构!
解决方案:进入Redis客户端,执行命令 FT.DROPINDEX spring-ai-document-index 删除旧索引(或直接清空Redis库),然后重新执行入库方法,新索引才能生效!
进阶思考:RAG检索失效?4个常见问题及解决方案
很多同行跑通Demo后,投入生产就会遇到“搜得牛头不对马嘴”的问题,结合我的实战经验,总结了4个高频问题,对照自查,轻松避坑:
1. 暴力切块导致“语义腰斩”
问题:盲目按字数硬切,把完整的语义(比如“请假流程”)从中间劈开,大模型拿到的切片没头没尾,无法理解上下文。
解决方案:使用我们自定义的SemanticTokenTextSplitter,设置合理的Overlap(重叠区),确保切分在标点符号句末,保留完整语义。
2. 迷信向量模型“全知全能”
问题:公司内部黑话(比如项目代号“XJ-9000”),通用Embedding模型无法识别,生成的向量方向错误,检索失效。
解决方案:垂直领域可微调Embedding模型;或在检索前,通过LLM将用户查询中的“黑话”重写为通用词汇(Query Rewrite),提升匹配度。
3. 用向量检索替代精准匹配
问题:向量检索擅长“语义相似”,不擅长“字符串精准匹配”(比如搜索订单号No.123456),单纯靠向量会返回无关结果。
解决方案:向量检索不能替代传统倒排索引!明确的属性查询(如订单号、ID),提取为Metadata用FilterExpression硬过滤;或开启BM25+向量的混合检索(Hybrid Search)。
4. Top-K贪大求全
问题:担心检索不到内容,把Top-K设为20,导致大模型上下文冗余、注意力涣散,反而答非所问。
解决方案:严格控制Top-K为3~5,只给大模型喂最相关、最纯净的切片,兼顾效率和准确率。
本节总结(核心要点,快速回顾)
今天我们彻底吃透了RAG架构的“检索脉门”:以SearchRequest为“高维探针”,用Top-K、Threshold、Metadata Filters三大标尺“大浪淘沙”,从向量数据库中精准召回有价值的文本切片。
现在我们手里有两件“利器”:一是具备强大总结能力的大语言模型(LLM),二是通过similaritySearch检索到的私有知识切片。把二者结合,让大模型基于检索到的真实资料回答问题,就是解决大模型“幻觉”的最完美工程方案!
最后想说:Java开发者转型AI,不用怕踩坑,每一个问题都是成长的契机。我会持续分享实战干货,和大家一起从零基础到实战,直奔技术标杆~
下节预告
跑通了检索环节,你是不是还在手动拼接检索结果、硬塞进Prompt?太繁琐了!
第十五课:《Spring AI 魔法:全新模块化 RAG 引擎一键闭环》,我们将学习Spring内置的RAG Advisors组件,只需一行配置,就能自动接管提问、检索、拼接Prompt、调用大模型,彻底告别“胶水代码”,实现RAG全流程极简闭环!
精彩继续,咱们下节见!
往期内容(循序渐进,建议按顺序学习)
-
Java开发者AI转型第十一课!文本切分避坑指南:Spring AI 智能分块与Overlap语义防割裂实战
-
Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义
-
Java开发者AI转型第十三课!知识库终局方案:Spring AI Vector Store架构演进与ETL全链路入库实战
我是直奔標杆,专注Java AI转型实战分享,每节课都力求干货落地。如果觉得本文对你有帮助,欢迎点赞、收藏、评论,一起交流学习,共同进步!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)