Apache Doris 4.1:面向 AI & Search 的统一数据存储与检索底座
1.1 新增 IVF 向量索引IVF 是大规模高维向量检索中最经典的 ANN 算法之一,核心思路是“先聚类分桶,再局部搜索”。相比 4.0 的 HNSW,IVF 可以在接受少量召回率损失的前提下,用更低的内存支撑更大规模的向量数据。
AI 时代,数据库已成为智能 Agent、RAG 系统、大模型应用和 AI 可观测平台 的基础设施。它不仅要能存结构化数据,更要能承载长上下文、向量、全文、Trace、事件流等新型数据。不仅要能分析,更要能实时检索、混合召回、在线服务和系统治理。
如果说 Apache Doris 4.0 开始顺应这一趋势,那么 Apache Doris 4.1,则是真正面向这一趋势完成了系统性演进。
这是一个面向 AI & Search 场景深度演进的重要版本。它不只是新增某几个功能,而是围绕 AI 应用落地过程中最核心的几类问题,给出了更完整、更统一的解决方案:
· 如何低成本存储海量 AI 数据
· 如何把结构化过滤、全文检索、向量检索统一在一个系统里
· 如何承载百万 Token 长上下文与超宽半结构化数据
· 如何支撑模型服务、Agent、RAG 的实时查询与可观测分析
· 如何继续保持 Doris 一贯领先的 OLAP 性能与湖仓能力
· 如何支撑 ETL 大规模离线计算与实时处理协同统一
➡️ GitHub 下载:https://github.com/apache/doris/releases
➡️ 官网下载:https://doris.apache.org/download
AI & Search
4.1 版本将结构化查询、全文检索与向量搜索,进一步整合到统一 SQL 和统一存储体系中。
1. 向量检索能力增强,支撑更大规模、更低成本部署
在 4.1 中,Doris 在向量索引和向量查询性能上有明显增强,其目标是让向量检索可规模化生产部署。
在性能方面,Doris 4.1 引入了 Ann Index Only Scan 优化,使向量搜索在执行过程中可以完全避免对原始列的 I/O 读取,从而显著降低查询开销。得益于这一优化,向量索引查询性能相比 4.0 提升最高可达 4 倍。
在典型测试环境(100 万向量规模、16 核 CPU、64GB 内存)下,Doris 可实现约 900QPS,同时保持 97% 的召回率,已能够稳定支撑绝大多数生产级向量检索场景。
根据 VectorDBBench 公布的数据(截至 2026 年 1 月),Doris 在索引构建速度上优于 Milvus、Qdrant、pgvector 等系统,这一优势主要得益于其数据分层架构。
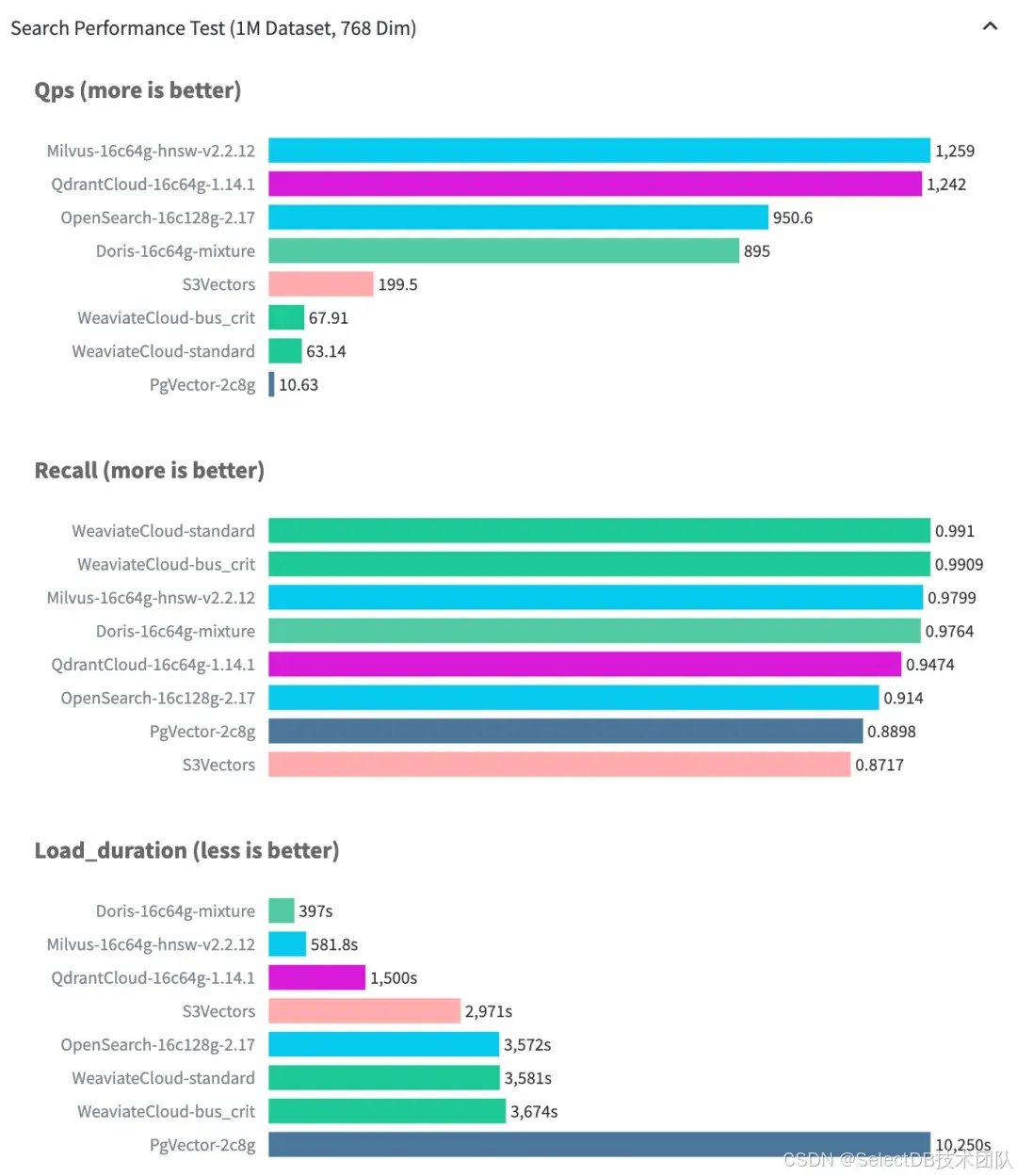
在功能新增及优化上,主要聚焦于大规模数据处理及使用成本。接下来,将对这些关键能力进行详细介绍。
1.1 新增 IVF 向量索引
IVF 是大规模高维向量检索中最经典的 ANN 算法之一,核心思路是“先聚类分桶,再局部搜索”。相比 4.0 的 HNSW,IVF 可以在接受少量召回率损失的前提下,用更低的内存支撑更大规模的向量数据。
在生产环境中,其价值体现:
-
同样机器资源下,能支撑更大向量规模
-
内存成本显著下降
-
更适合大规模向量检索场景的落地
简要示例:如需使用 IVF 索引,请在索引属性中设置"index_type"="ivf"。
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT"",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="ivf",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT"OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);1.2 IVF_ON_DISK
很多向量检索系统(如 Faiss)在千万级数据规模还能保持性能,但一旦进入百亿甚至更大规模,索引全内存的模式就会迅速推高成本。
Apache Doris 基于 IVF 进一步实现了 IVF_ON_DISK(优化方式参考 SPANN 论文https://www.microsoft.com/en-us/research/wp-content/uploads/2021/11/SPANN_finalversion1.pdf)。通过内存缓存 + 本地文件系统缓存结合,以极低的成本实现了高效的向量剪枝。
· 在存算分离架构下,可实现低成本、高性能的超大规模向量剪枝与召回。
· 相比 DiskANN,更低索引构建开销,给万亿级别向量搜索提供了切实可行的新路径。
· 更适合 AI 知识库、推荐召回、海量 embedding 检索等场景
使用 IVF_ON_DISK 几乎与使用 IVF 相同:只需指定 "index_type"="ivf_on_disk" 即可。
CREATE TABLE for_ivf_on_disk (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type"="ivf_on_disk",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
1.3 向量量化
除了索引算法,Doris 还支持多种向量量化方式,包括:
· INT8 标量量化
· INT4 标量量化
·Product Quantization( PQ)
这些能力可以在略微牺牲召回率的情况下,将索引内存占用压缩到原来的 1/4 到 1/8。配合 IVF_ON_DISK,可以进一步降低大规模向量检索的机器成本。
以下示例展示了对 128 维向量进行 PQ 压缩的 DDL:
CREATE TABLE product_quant (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type"="ivf_on_disk",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024",
"quantizer"="pq",
"pq_m"=64,
"pq_nbits"=8
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");2. 全文检索 search() 函数:一条 SQL 统一文本搜索和分析
如果说向量能力解决的是“语义召回”,那么全文搜索解决的是“关键词精确定位、故障排查、日志搜索、文本分析”等场景。Doris 4.1 新增的 search() 函数,将全文搜索能力直接嵌入 SQL 中,一条 SQL 同时完成搜索过滤与聚合分析。
-
兼容 ES query_string 风格语法,迁移十分简单。
-
内置支持 TERM、PHRASE、WILDCARD、REGEXP、PREFIX、NOT、NESTED 等丰富算子,并支持任意嵌套组合
-
内置 BM25 相关性打分,存储层 TopN 优化,避免全量结果传输
-
支持嵌套搜索(Nested),配合 VARIANT 类型,可在嵌套 JSON 数组内部搜索
-
支持多字段搜索,支持
best_fields(精确匹配同一字段)和cross_fields(跨字段分散匹配)两种策略。
典型用例:
-- Multi-condition: TERM + PHRASE + NOT evaluated in a single pass
SELECT request_id, error_msg, latency_ms
FROM inference_logs
WHERE search('
level:ERROR
AND error_msg:"CUDA out of memory"
AND NOT module:healthcheck
AND model_name:gpt*
')
AND log_time > NOW() - INTERVAL 1 HOUR
ORDER BY latency_ms DESC LIMIT 100;
-- BM25 relevance scoring
SELECT request_id, error_msg, score() AS relevance
FROM inference_logs
WHERE search('error_msg:"memory allocation failed" OR error_msg:"CUDA error"')
ORDER BY relevance DESC LIMIT 20;
-- Nested search: query inside a VARIANT array
SELECT * FROM agent_logs
WHERE search('NESTED(steps, status:error AND tool:code_exec)');
-- search + aggregation: filter and analyze in one query
SELECT model_name, COUNT(*) AS error_count,
PERCENTILE_APPROX(latency_ms, 0.99) AS p99_latency
FROM inference_logs
WHERE search('level:ERROR AND error_msg:"CUDA out of memory"')
AND log_time > NOW() - INTERVAL 1 HOUR
GROUP BY model_name ORDER BY error_count DESC;search() 返回一个布尔谓词,该谓词直接参与连接、窗口函数和子查询,从而使全文搜索成为 SQL 的标准组成部分。
3. 原生支持 100MB JSON 文档存储
在长上下文、多轮对话、RAG 和 AI Agent 等场景中,将完整交互生命周期作为单个文档存储,已成为实际需求。
Apache Doris 4.1 原生支持单行最大 100MB JSON 文档,可将完整 AI 会话数据直接存储在数据库中,包括多轮对话、长文档文本、音视频转录、Agent 执行轨迹、工具调用日志以及 RAG 上下文等,均无需拆分、无需截断,也无需依赖外部存储。
这些超大文档在写入后,可以像普通数据一样被直接查询与分析,支持过滤、条件查询、聚合以及 JOIN 等操作。大型 AI 上下文数据变成了可管理、可查询、结构化的数据资产。
依托 Doris 百万 Token 超大文本能力,带来显著变化包括:
· 消除对独立对象存储的依赖
· 移除元数据和原始内容之间的一致性维护逻辑
· 消除分段存储和重新组装的开发开销
· 实现更低的查询延迟、更强的事务性保证和更简单的运维足迹
4. Segment V3:宽表的元数据解耦
在 Search & AI 场景中,数据往往具有超宽、稀疏、半结构化的特点,这类数据字段数量多、变化快,同时存在明显的冷热分化,对随机读、点查和高并发写入都有很高要求。
在 4.1 之前,Doris 使用 Segment V2 存储格式,将元数据集中在文件尾部(Footer)。这种设计在批量扫描场景表现良好,但在随机读取和小范围查询时,每次都需要加载完整元数据,带来额外 I/O 和解析开销,影响性能。
为此,Doris 4.1 引入 Segment V3,借鉴了 Lance 以及 Vortex 等新型文件存储格式的做法,将元数据从 footer 中分离,按需加载,解决万列场景下最容易碰到的元数据膨胀、文件打开慢和随机读开销问题。适用于超宽表、大量 VARIANT 子列、对象存储冷启动敏感、随机读较多的 AI 和车联网半结构化数据场景。
以一张包含 7,000 列、10,000 个 Segment 的超宽表为例。在 Segment 打开阶段,V3 相比 V2 实现了显著提升:
· 打开速度提升最高达 16 倍
· 内存占用降低最高达 60 倍
在超宽表和高并发访问场景中,这意味着更快的响应速度与更低的资源成本。

如何启用:在表属性中指定 "storage_format" = "V3"。
CREATE TABLE table_v3 (
id BIGINT,
data VARIANT
)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);
参考文档: https://doris.apache.org/zh-CN/docs/4.x/table-design/storage-format
5. 稀疏列优化:Sparse Sharding 与 Sparse Cache
针对宽 JSON 中“热点 path 少、长尾 path 多”的特点,Doris 4.1 优化了 sparse 读取链路,避免长尾路径集中在单列带来的性能瓶颈。
· 冷热分层:热点 path 保留为列式子列,长尾 path 进入 sparse 存储,避免子列膨胀
· Sparse Sharding:通过variant_sparse_hash_shard_count将长尾 path 分散到多个 sparse 列,降低单列读放大
· Sparse Cache:为 sparse 列增加缓存,减少重复 I/O、解码与反序列化开销
适用于广泛的 JSON 数据,如车联网、用户画像、埋点日志等超宽 JSON 场景(字段数量极多,其中只有几十到几百个路径会被频繁查询)。
使用示例:
CREATE TABLE user_feature_wide (
uid BIGINT,
features VARIANT<
'user_id' : BIGINT,
'region' : STRING,
properties(
'variant_max_subcolumns_count' = '2048',
'variant_sparse_hash_shard_count' = '32'
)
>
)
DUPLICATE KEY(uid)
DISTRIBUTED BY HASH(uid) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);参考文档:
基准测试结果: https://doris.apache.org/zh-CN/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#%E6%80%A7%E8%83%BD
文档: https://doris.apache.org/zh-CN/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#sparse-%E6%A8%A1%E5%BC%8F 关键字:稀疏分片
6. DOC 模式:更快写入,更高效整条读取
当半结构化数据更关注写入效率或整条 JSON 返回时,DOC 模式是更合适的选择。它保留原始 JSON,并将子列提取延迟到 compaction 阶段,从而降低写入成本、减少写放大。
-
延迟物化:写入阶段不立即展开子列,降低小批量写入开销。
-
DOC Sharding:通过
variant_doc_hash_shard_count对 Doc Store 分片,提升整条 JSON 返回与 path 提取性能。 -
物化阈值控制:用
variant_doc_materialization_min_rows控制物化阈值,低于阈值的数据延迟处理,统一在 compaction 阶段完成。
适用于 AI/LLM 输出、Trace、上下文快照、事件回放等需要频繁读取完整文档的场景。
如何配置:
使用时开启 variant_enable_doc_mode,并结合数据规模配置物化阈值与分片数;与 sparse 模式互斥,建议二选一,并配合 storage_format = "V3" 使用。
CREATE TABLE trace_archive (
ts DATETIME,
trace_id STRING,
span VARIANT<
'service_name' : STRING,
properties(
'variant_enable_doc_mode' = 'true',
'variant_doc_materialization_min_rows' = '100000',
'variant_doc_hash_shard_count' = '32'
)
>
)
DUPLICATE KEY(ts, trace_id)
DISTRIBUTED BY HASH(trace_id) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);参考文档:
测试结果:https://doris.apache.org/zh-CN/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#%E6%80%A7%E8%83%BD
文档:https://doris.apache.org/zh-CN/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#doc-mode-template 关键字:文档模式
更快的 OLAP
查询性能直接影响分析吞吐量、基础设施成本和业务响应时间,Apache Doris 4.1 在这一方向持续演进:通过减少无效计算、降低数据流动、提升执行效率,让复杂查询在真实场景中依然保持高性能。
1️⃣ 多表分析场景中
在多表连接和聚合性能标准基准测试中,Doris 4.1 相比 4.0 有较好的提升:
· SSB 提升 14.3%。
· TPC-H 提升 22.6%
· TPC-DS 提升 19.1%

2️⃣ 宽表分析场景中
ClickBench 使用 100GB 的数据量和 43 个复杂查询,对列式存储、向量化执行和压缩性能进行压力测试,是业内要求最高的单表基准测试之一。
在 c7a.metal-48xl 实例测试,Apache Doris 4.1 在冷查询性能和存储空间方面排名第一。其总分排名第二,仅次于 ClickHouse(web)。
冷查询:

综合得分:

这些性能表现得益于 4.1 的系统性演进,接下来介绍较为重要的优化点。
1. 聚合下推:降低关联计算成本
通过 Aggregate Pushdown Through Join 将高聚合率算子拆分并下推到 Join 两侧,先对单表数据进行局部聚合,再进行关联,最后完成全局聚合。这种“先压缩、再关联”的方式,从源头减少参与 Join 的数据量,显著降低内存占用与计算延迟。
基准测试集上,整体性能提升超过 200%。超过半数的测试用例提升超过 50%。近三分之一的测试用例提升超过 100 倍。
2. 聚合扩展优化:先缩数据,再做多维聚合
通过智能识别最细粒度聚合组及其聚合率,在满足条件时,将执行方式从“多组并行聚合”调整为:先完成最细粒度聚合,大幅缩减数据规模,再基于结果计算其他聚合组,从而显著降低计算延迟。
基准测试集上,整体性能提升超过 10%。超过 1/5 的测试用例改进幅度超过 20%,最大改进幅度为 160%,最大回退低于 5%。
3. 嵌套列裁剪:只读需要的数据
嵌套列裁剪可精确解析嵌套字段结构。当查询仅涉及某个子字段时,仅读取对应数据,跳过无关字段,从而显著减少 I/O 开销。在 Apache Doris 4.1 中,嵌套列剪枝适用于内部表以及外部 ORC 和 Parquet 数据。
基准测试集上,整体性能提升超过 60%。在个别场景下,提升幅度超 700%。
4. Condition Cache:避免重复过滤计算
在大规模分析中,查询通常会在多次执行中重复使用相同的过滤条件,例如:
SELECT * FROM orders WHERE region = 'ASIA';
SELECT count(*) FROM orders WHERE region = 'ASIA';这些查询在相同的段上反复执行相同的过滤逻辑,从而浪费了 CPU 和 I/O 资源。
Condition Cache 通过缓存条件在 Segment 上的过滤结果,在后续查询中直接复用,减少重复扫描与计算。复杂查询场景下整体性能提升超过 10%。
参考文档:https://doris.apache.org/docs/4.x/query-acceleration/condition-cache
5. 中间结果 Cache:复用中间聚合结果
在分析型工作负载中,相同的聚合查询通常会针对未更改的数据反复执行,例如:
SELECT region, SUM(revenue) FROM orders WHERE dt = '2024-01-01' GROUP BY region;
SELECT region, SUM(revenue) FROM orders WHERE dt = '2024-01-01' GROUP BY region;每次执行都会扫描相同的分片并重新计算相同的聚合结果,从而浪费 CPU 和 I/O。
Query Cache 会缓存执行过程中的中间聚合结果,当查询上下文一致时直接返回缓存结果,大幅降低计算与 I/O 开销。
文档:https://doris.apache.org/docs/4.x/query-acceleration/query-cache
6. CASE WHEN 优化
Case When 是分析场景中的核心语法,用于实现复杂业务逻辑与多维条件计算。
Apache Doris 4.1 版本通过引入分支合并,分支消除,公共子表达式提取,枚举值提取和下推等优化手段。显著提升了包含 Case When 语句的执行表现。
基准测试集上,平均性能提升超过 200%。在个别场景下,提升幅度超过 50 倍。
存算分离架构打磨
pache Doris 的存算分离架构目前已有超过 2000 家企业用户。随着采用率的增长,稳定性和查询性能已成为主要关注领域。4.1 版本持续投入深度优化,不断打磨架构可靠性与执行效率。
1. File cache 优化
支持 File cache 元数据持久化,避免了早期版本在启动阶段重建缓存状态所带来的大量 I/O 开销。同时新增系统表information_schema.file_cache_info,通过 SQL 即可查看块级缓存明细,支持按 tablet_id、be_id、cache_path、type 等维度查询,帮助用户快速定位热点数据、缓存倾斜和异常膨胀问题。
典型用法 1:定位缓存明细,查看单个 Tablet 的缓存构成
mysql> select * from information_schema.file_cache_info where TABLET_ID = 1761571031445;
+----------------------------------+---------------+-------+--------+-------------+-----------------+---------------+
| HASH | TABLET_ID | SIZE | TYPE | REMOTE_PATH | CACHE_PATH | BE_ID |
+----------------------------------+---------------+-------+--------+-------------+-----------------+---------------+
| 468448215c52334ae5bee147259b1027 | 1761571031445 | 15120 | index | | /mnt/disk1/project/filecache | 1761571031251 |
| 71bb73d34cd8ffe280b16dd329df5ba1 | 1761571031445 | 13117 | index | | /mnt/disk1/project/filecache | 1761571031251 |
| 77c6b69d1a7c4fe740a11bab5c1bbaa3 | 1761571031445 | 12249 | index | | /mnt/disk1/project/filecache | 1761571031251 |
+----------------------------------+---------------+-------+--------+-------------+-----------------------------------------------------------------------------+---------------+典型用法 2:聚合分析缓存分布,评估节点间缓存均衡性与资源占用情况
SELECT be_id, tablet_id, type, SUM(size) AS cache_bytes
FROM information_schema.file_cache_info
WHERE tablet_id = 1761571031445
GROUP BY be_id, tablet_id, type
ORDER BY cache_bytes DESC;2. 弹性伸缩、冷查询及其他优化
-
弹性伸缩:在存算分离模式下,百万级分片的扩缩容操作可在几分钟内完成。调度机制不再依赖全局分片数量,显著提升整体弹性能力。
-
冷查询优化:基于 Doris 页面扫描语义引入预取机制,提升内部表冷查询性能。通过参数调优,可更充分利用远端存储带宽,获得更优 I/O 表现。
-
大规模部署优化:对 FE 中的副本与表对象进行精简,在百万级规模下,FE 内存使用量降低 30%+。
-
Meta-service 性能优化:通过引入缓存机制,减少对 Meta Service 的重复请求,提升元数据访问吞吐。同时优化了存算分离模式下部分系统表的访问路径。
-
对象存储成本优化:在高频导入场景下,通过节点级请求合并,减少对象存储请求次数及小文件数量,整体成本最高可降低 90%。
-
列压缩与编码优化:引入更高效的二进制编码与预解码机制,降低运行时解码成本;默认压缩逐步切换至 ZSTD,在压缩率与解压性能之间取得更优平衡。在宽表与明细查询场景中,体现为更低存储占用与更优冷读性能。
-
更完整的一体化湖仓能力
4.1 在数据湖方向实现了重要升级,从格式支持、查询性能到生态兼容性,全面增强 Doris 作为统一湖仓分析引擎的能力。用户无需依赖 Spark 等外部引擎,仅通过 Doris SQL 即可完成 Iceberg、Paimon 等主流湖格式数据的读写与管理。
1. Lakehouse 全生命周期管理
Apache Doris 4.1 为主要的开放湖格式添加了完整的生命周期管理。表创建、数据插入、更新和删除都可以通过 Doris SQL 进行操作,这是一个涵盖整个数据湖工作流程的单一引擎。
-
Iceberg V2/V3 完整支持:支持 INSERT、UPDATE、DELETE、MERGE INTO 等操作,并支持 Iceberg V3 中的 Deletion Vector、Row Lineage 等特性,实现数据摄入、更新与删除的全流程闭环,无需依赖外部引擎。
-
Paimon 库表管理:支持通过 SQL 直接进行库表管理(CREATE DATABASE / TABLE 等),后续版本将进一步支持写入能力。
文档:
-
https://doris.apache.org/docs/4.x/lakehouse/catalogs/iceberg-catalog
-
https://doris.apache.org/docs/4.x/lakehouse/catalogs/paimon-catalog
2. 湖仓查询性能优化
引入了多项针对性的优化手段,显著提升了湖上数据的查询性能。
-
Iceberg 排序写入:支持按指定列排序写入数据,并生成排序元信息(lower/upper bounds),查询时可高效裁剪无关数据文件。在 TPC-DS 测试中,查询性能提升约 15%。
-
Iceberg Manifest 缓存:新增 Manifest 级元数据缓存,避免查询规划阶段对 Manifest 的重复读取与解析,显著降低 I/O 与 CPU 开销。在高频查询场景下,复杂元数据解析延迟可降至百毫秒级。
-
Parquet Page Cache:新增 Page Cache,将已解压的数据页缓存到内存,减少重复解压与磁盘 I/O。在高频查询场景下显著降低延迟,ClickBench 测试中整体性能提升约 20%。
参考文档:
-
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/catalogs/iceberg-catalog#%E5%88%9B%E5%BB%BA%E5%92%8C%E5%88%A0%E9%99%A4%E8%A1%A8
-
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/catalogs/iceberg-catalog#meta-cache
-
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/best-practices/optimization#parquet-page-cache
3. 联邦分析易用性
在 4.1 版本中,Doris 进一步增强了数据互操作性与易用性:
-
缓存准入控制:通过多维规则(用户、Catalog、Database、Table)精细控制缓存写入,避免冷数据挤占缓存,提升热点数据命中率;规则以 JSON 文件存放于指定目录,修改后自动生效,无需重启 FE 节点。支持
EXPLAIN可观测,便于调优 -
MaxCompute 数据写入:支持在 MaxCompute 外部 Catalog 中执行建表与写入操作,打通 Doris 向 MaxCompute 的数据导出链路,并支持 ARN 跨账号访问,实现与阿里云生态的高效集成。
-
Parquet 元数据探查:新增 Parquet 元数据 TVF,支持通过 SQL 查询分区、Row Group、列统计等信息,便于排查文件结构问题、验证分区裁剪及优化查询性能。
文档:
-
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/data-cache
-
https://doris.apache.org/zh-CN/docs/4.x/lakehouse/catalogs/maxcompute-catalog
-
https://doris.apache.org/zh-CN/docs/4.x/sql-manual/sql-functions/table-valued-functions/parquet-meta
离线计算能力增强
持续推进实时在线一体化,在同一引擎内统一支持交互式分析与大规模批处理,减少多系统架构复杂度。本版本进一步增强原生 ETL/ELT 能力:
MERGE INTO
支持通过单条标准 SQL MERGE INTO 完成 INSERT / UPDATE / DELETE(UPSERT),简化增量数据(如 CDC)合并流程,降低开发与维护成本。
MERGE INTO target t
USING source s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET t.value = s.value
WHEN NOT MATCHED THEN
INSERT (id, value) VALUES (s.id, s.value);Spill to Disk 增强
面向大表 Join、高基数聚合、全局排序等内存敏感场景,全面强化溢写能力:
· 支持多层级递归溢写(Recursive Spill),避免内存峰值压力。
· 全面覆盖 Join、Aggregation、Sort 等核心算子
· 动态触发溢写,平衡内存使用与磁盘 IO,保障查询稳定性。
在该机制增强下,Doris 实现了关键突破:单个 BE 节点 + 8GB 内存即可完成 TPC-DS 10TB 全量查询,进一步验证了其在大规模分析场景下优于 Hadoop、Greenplum、Spark 等传统方案,以更低资源成本提供更强查询性能。
易用性增强
Doris 4.1 在易用性上进一步增强,补齐关键分析语法,提升复杂场景下的表达能力,跨系统兼容性。
1. 执行引擎能力扩展
UNNEST:原生支持UNNEST 语法,简化 JSON、日志等半结构化数据中 ARRAY 或嵌套结构的分析流程,避免复杂函数改写。
SELECT user_id, tag
FROM user_profile,
UNNEST(tags) AS t(tag);递归公用表表达式(Recursive CTE):支持递归查询,适用于组织树、层级结构、图路径等场景,实现更灵活的数据遍历与关系分析。
WITH RECURSIVE org_tree AS (
SELECT id, parent_id, name
FROM org
WHERE parent_id IS NULL
UNION ALL
SELECT o.id, o.parent_id, o.name
FROM org o
JOIN org_tree t ON o.parent_id = t.id
)
SELECT * FROM org_tree;ASOF JOIN:支持 ASOF JOIN,可按时间“最近匹配”的关联查询(<= / >=),适用于金融、IoT、监控等时序场景,实现数据对齐与最近值匹配。
SELECT t1.ts, t1.value, t2.price
FROM trades t1
ASOF JOIN prices t2
ON t1.symbol = t2.symbol
AND t1.ts >= t2.ts;2. 数据接入与写入路径增强
S3 持续导入:支持基于 S3 文件源创建持续导入 Job,系统可自动发现新增文件并持续执行导入,适用于对象存储场景下的增量数据接入。
MySQL / PostgreSQL 实时同步:支持 MySQL 和 PostgreSQL 数据库变更实时接入 Doris,覆盖全量初始化与后续增量同步,可帮助用户更便捷地构建数据库到 Doris 的实时分析链路,满足业务库实时数仓、数据汇聚和分析加速等场景需求。
文档:
· https://doris.apache.org/zh-CN/docs/4.x/data-operate/import/streaming-job/continuous-load-s3
· https://doris.apache.org/zh-CN/docs/4.x/data-operate/import/streaming-job/continuous-load-mysql-table
· https://doris.apache.org/zh-CN/docs/4.x/data-operate/import/streaming-job/continuous-load-postgresql-table
3. 写入与更新模型优化
· 自适应写入调度:支持自适应调整 MemTable Flush 线程池规模,可根据集群实时负载自动匹配更合适的写入并发度,在高写入场景下更好兼顾吞吐、资源利用率与稳定性。
· 主键模型多流合并更新(sequence-aware):支持通过 sequence_mapping 实现多流合并更新。不同数据流可分别更新同一张表的不同列,并按各自顺序字段完成合并,适合实时流更新与离线补数并行写入的场景。
· Routine Load 增强:支持 flexible partial update,实现非主键列的按需更新;支持动态参数调整与自适应批处理,提升高吞吐场景稳定性。
· 导入审计可观测性:支持将 Stream Load 记录写入审计日志系统表,便于统一查询导入历史、排查问题和做审计分析。
4. TIMESTAMPTZ:原生时区时间支持
在全球化与多时区场景(如跨地域日志、用户行为分析、金融交易)中,时间数据往往携带明确时区信息。传统使用无时区的 DATETIME 类型,需要在应用层手动处理转换,易出错且增加开发成本。
Doris 4.1 引入 TIMESTAMPTZ(TIMESTAMP WITH TIME ZONE),提供标准化的时区时间支持:
· 统一存储:写入时将时间转换为 UTC 存储
· 自动转换:查询时根据会话时区自动转换展示
· 灵活输入:支持带时区或无时区时间输入,自动完成解析与转换
· 类型兼容:支持与 DATETIME 相互转换,并兼容现有函数使用
该设计将时区处理从应用层下沉至数据库内核,提升跨系统数据一致性,降低多时区数据处理复杂度。
结束语
Apache Doris 4.1 是面向 AI 时代的一次重要数据基础设施能力演进。从向量检索、长上下文存储,到混合检索与统一分析能力,Doris 正在逐步构建更完整的数据处理闭环。
如果你正在探索 AI 应用落地、实时分析或湖仓一体化架构,欢迎进一步了解 Apache Doris,并在实际场景中进行验证:
👉 官网文档:https://doris.apache.org
👉 GitHub:https://github.com/apache/doris
对于希望在生产环境中获得更稳定性能与企业级支持的用户,也可以了解基于 Apache Doris 构建的云原生产品 SelectDB(www.selectdb.com),在弹性扩展、运维效率和大规模部署方面提供更完善的支持。
欢迎加入社区,一起探索 AI 时代的数据基础设施演进方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)