DeepSeek-V4来了:百万字上下文、Agent能力超Sonnet 4.5,这波真的猛
摘要: DeepSeek发布全新开源模型DeepSeek-V4,包含Pro(1.6T参数)和Flash(284B参数)两个版本,均支持1M上下文长度,成为全球首个标配百万级上下文的开源模型。其Agent能力超越Sonnet 4.5,接近闭源顶级模型Opus 4.6,推理性能领跑开源领域,数学、STEM等评测表现优异。通过创新的稀疏注意力机制(DSA),显著降低长文本计算成本。Flash版本性价比更
DeepSeek 今天放了个大招。
全新系列模型 DeepSeek-V4 预览版正式上线,同步开源。两个版本:

- deepseek-v4-pro:1.6T 参数、49B 激活、1M 上下文
- deepseek-v4-flash:284B 参数、13B 激活、1M 上下文
百万字上下文,直接成了 DeepSeek 所有官方服务的标配。
Agent 能力:开源最强,超了 Sonnet 4.5
官方说得很明确。在 Agentic Coding 评测中达到了当前开源模型最佳水平。DeepSeek 内部员工已经在用 V4-Pro 做 Agentic Coding,体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式。
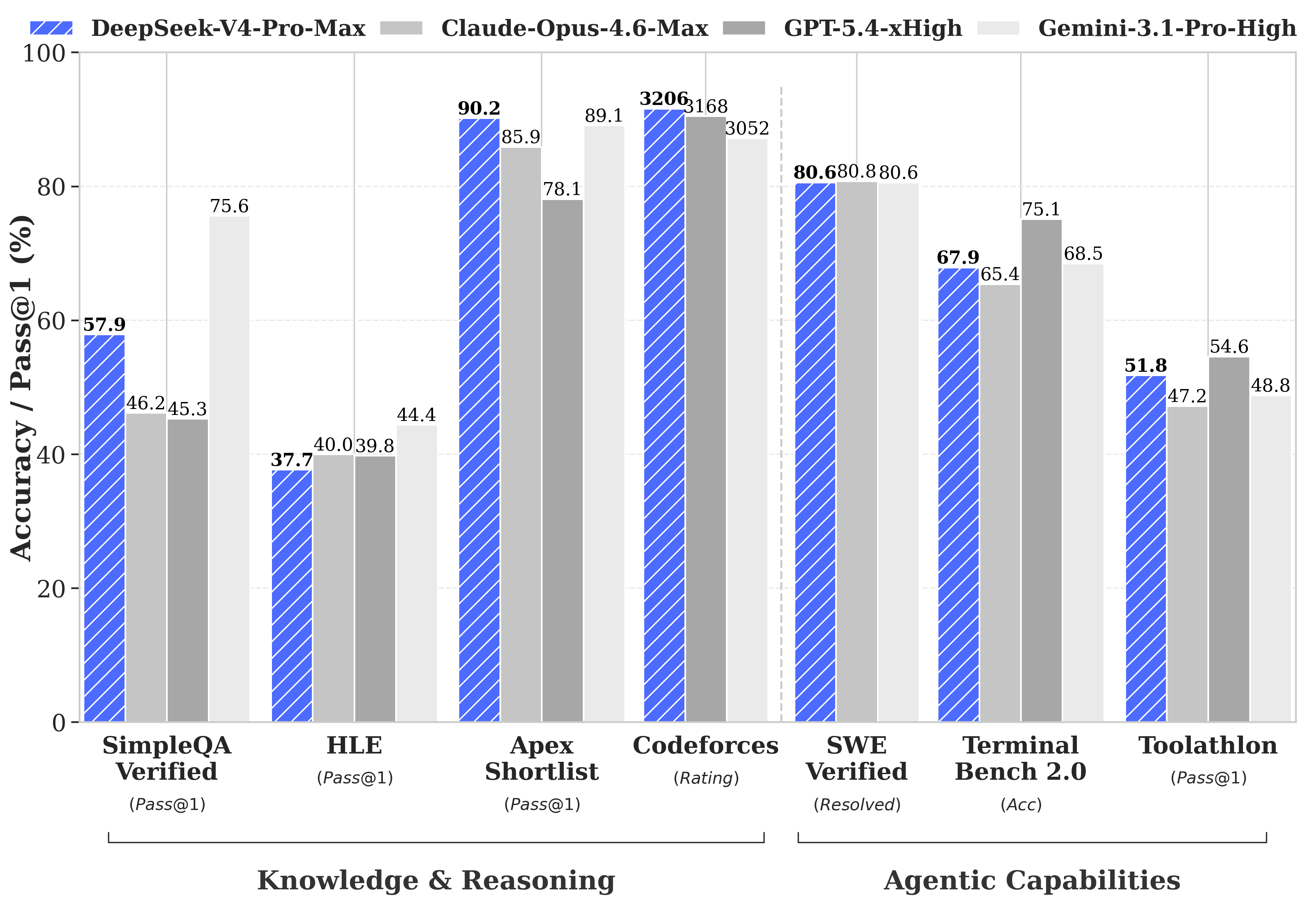
注意是接近 Opus 4.6。虽然跟思考模式还有差距,但一个开源模型能把闭源顶级模型逼到这个份上,说实话有点恐怖。
推理性能:超越所有已公开评测的开源模型
数学、STEM、竞赛型代码评测,DeepSeek-V4-Pro 拿到了超越所有已公开评测的开源模型的成绩。比肩世界顶级闭源模型。
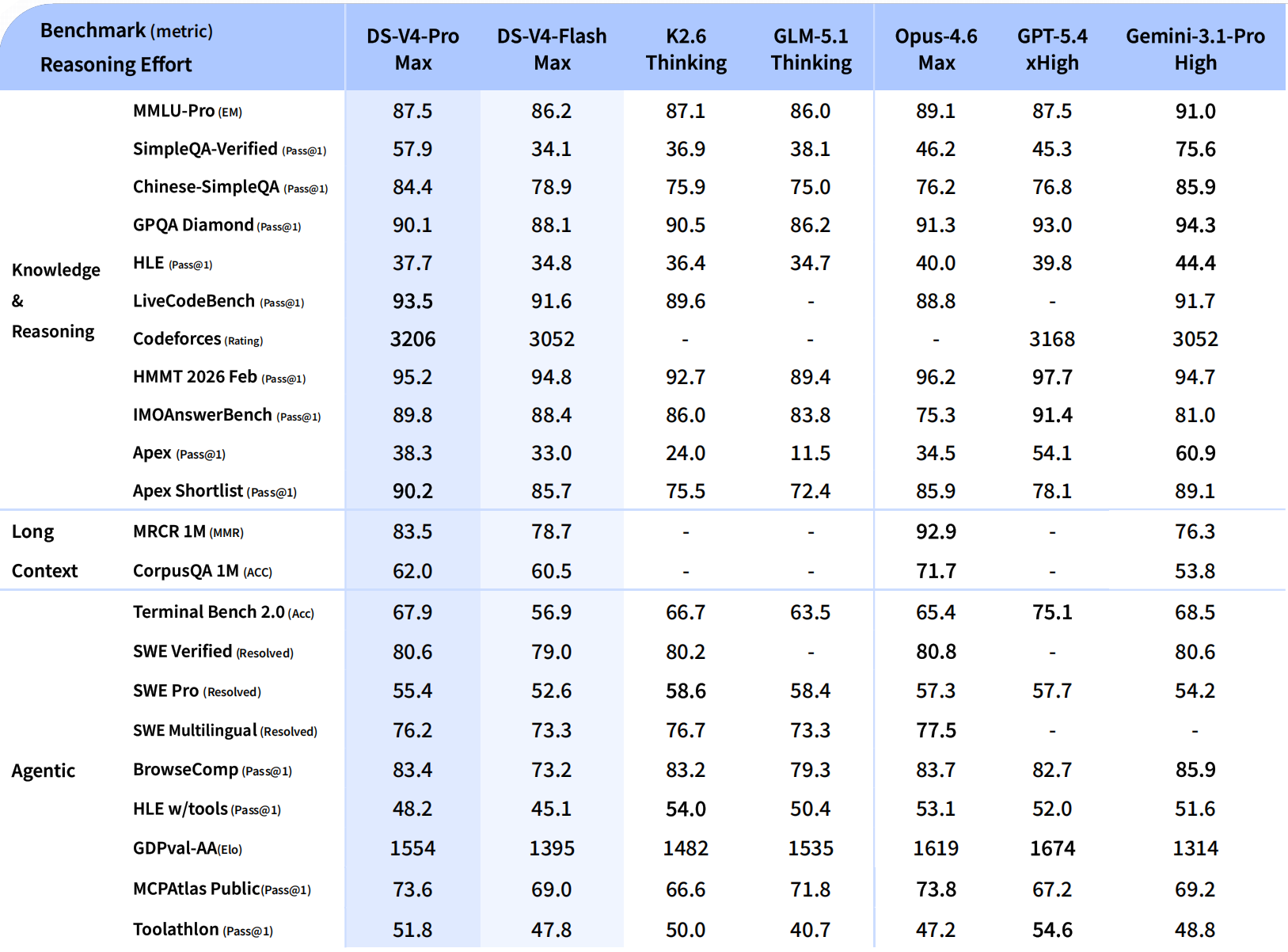
世界知识方面也大幅领先其他开源模型,仅稍逊于 Gemini-Pro-3.1。
也就是说,综合能力已经是开源第一梯队,直逼闭源天花板。
1M 上下文怎么做到的?
DeepSeek-V4 开创了全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力。相比传统方法大幅降低计算和显存需求。
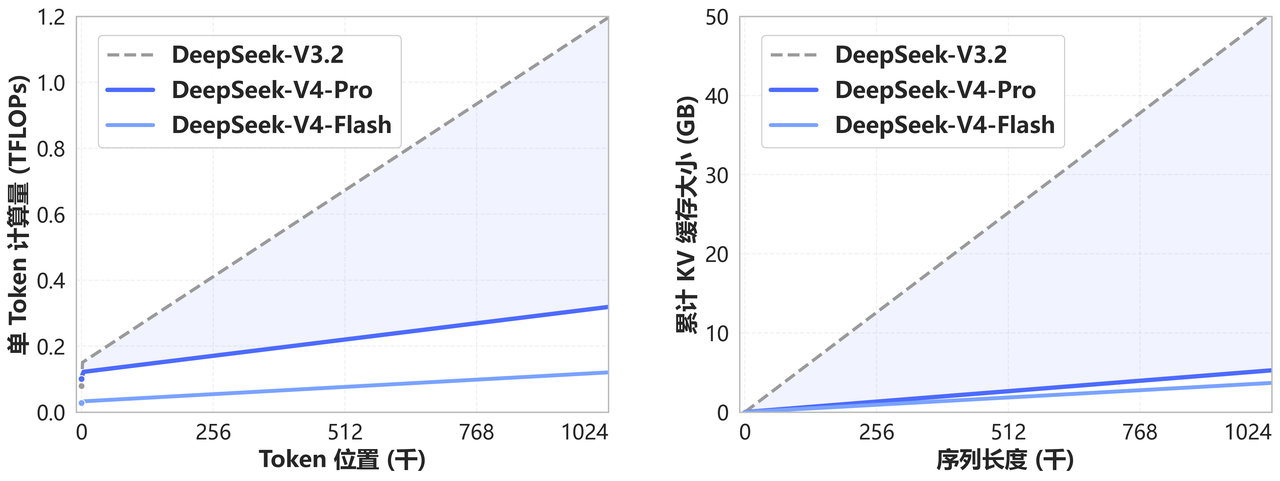
从现在开始,1M 上下文是标配。不是选配,不是付费功能,是标配。
Flash 版本:更便宜更快
V4-Flash 是经济之选。推理能力接近 Pro,但参数更小、速度更快、价格更低。简单 Agent 任务跟 Pro 旗鼓相当,高难度任务有差距。
对大多数 API 调用场景来说,Flash 性价比极高。
API 迁移
model 参数改成 deepseek-v4-pro 或 deepseek-v4-flash 就行了。base_url 不变。旧接口 deepseek-chat 和 deepseek-reasoner 到 2026 年 7 月 24 日停用。
支持 OpenAI ChatCompletions 接口和 Anthropic 接口。思考模式支持 reasoning_effort(high/max),复杂 Agent 场景建议用思考模式+max 强度。
另外,官方明确提到针对 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产品做了适配优化。
说点题外话
DeepSeek 这个公司的节奏一直很特别。不声不响,一出手就是重磅。V4 这次在 Agent 和长上下文上的突破,说明他们不只盯着"刷榜",而是在解决真实场景中的核心痛点。
现在越来越多的产品已经在接入 DeepSeek 的模型了。
比如Ai好记,一个做音视频转图文笔记的工具,就引入了 DeepSeek 的能力来优化转录和语义分析的效果。

我平时做内容全靠它提效,播客和视频直接转成结构化笔记,DeepSeek 的推理能力在关键信息提取这块确实帮了大忙。

其实 DeepSeek 在多模态领域的布局一直很深。从文本到代码到 Agent,再到现在长上下文和推理能力的突破,这条路线走得很扎实。下一步多模态能力如果补齐,整个 AI 应用生态的格局可能又要变了。
技术改变世界。Diving into the Unknown。
开源地址:HuggingFace / ModelScope 搜 DeepSeek-V4

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)