小白程序员必备!收藏这份Hermes大模型学习指南,快速掌握智能体核心机制
Hermes 的内置记忆使用MEMORY.md和USER.md两个小型 Markdown 文件,而非 SQLite;启动新会话时,它们会作为 frozen snapshot 注入系统提示词。Hermes 的 SQLite + FTS5 主要服务,也就是跨会话历史检索。它更像档案室,不是随身备忘录。Hermes 的外部 memory provider,比如 Honcho、Mem0、Hindsight
本文深入解析Hermes Agent的三层学习机制,对比OpenClaw,揭示二者差异关键在于长期资产分层与运行时设计。Hermes通过内置Markdown文件、SQLite+FTS5检索及外部记忆组件,实现事实记忆、会话检索与过程记忆的清晰分离与协同。过程记忆中的技能管理系统,支持创建、修补、编辑与删除,形成完整生命周期治理。OpenClaw需通过工程化改造,将经验沉淀纳入运行时主路径,才能趋同Hermes。文章强调长期信息拆分管理、过程记忆生命周期治理及学习闭环工程化的重要性,为AI智能体设计提供宝贵参考。
1、开篇引入
OpenClaw 与 Hermes 均有 Markdown 记忆文件,长期均依赖 SQLite / FTS 检索,若给 OpenClaw 增加自总结、自动沉淀 skills 的机制,二者是否就无差异?
要解答这一疑问,需先明确二者的核心边界:二者的关键差异不在于“有无长期记忆、有无全文检索、有无 Markdown 记忆文件”,而在于“一个 Agent 系统到底把什么东西当成长期资产,又把这些资产放在运行时的哪一层”——这正是 Hermes Agent 三层学习机制的核心价值所在,也是二者差异的核心边界。为了更清晰地拆解这一逻辑,先呈现原文的“太长不看版”核心摘要,快速把握全文重点。
2、全文核心摘要
-
Hermes 的内置记忆使用
MEMORY.md和USER.md两个小型 Markdown 文件,而非 SQLite;启动新会话时,它们会作为 frozen snapshot 注入系统提示词。 -
Hermes 的 SQLite + FTS5 主要服务
session\_search,也就是跨会话历史检索。它更像档案室,不是随身备忘录。 -
Hermes 的外部 memory provider,比如 Honcho、Mem0、Hindsight、Supermemory,是叠加能力,不会替换内置的
MEMORY.md/USER.md。 -
Hermes 最值得拆的是
skill\_manage。它把“这类任务以后怎么做”写成 skill,并允许后续 patch、edit、delete。这属于 procedural memory,和事实记忆分属两层。 -
这套学习机制没有写成“达到阈值就必然写 skill”的硬规则。源码里更像一套 best-effort review:主任务先完成,后台再判断是否有东西值得保存。
-
OpenClaw 现在也有 Honcho、memory_search 和 experimental dreaming。不建议再把它简单理解成静态 Markdown。
-
如果 OpenClaw 也把自动 skill 沉淀、触发、复用、修补、安全扫描做成系统主路径,它在 learning loop 这一层会非常接近 Hermes。后面的差异,就会从“有没有”变成“这件事被放在运行时的什么位置”。
明确核心摘要后,我们先拆解一个关键前提——很多 Agent 对比陷入误区,核心是将三类不同的“记忆”混为一谈,而 Hermes 则将其明确分层,这是理解其三层学习机制的基础。
3、基础铺垫:三类不同的 Agent 长期资产
Agent 的“记忆”并非单一概念,而是包含三类不同的长期资产,三者各司其职、互不替代,共同构成 Hermes 的 closed learning loop 工程机制,也是区分 Hermes 与其他 Agent 的核心前提:
3.1 事实记忆:长期必备的“基础信息卡”
定义:Agent 需要长期知道的事实、偏好和环境约定,不一定来自完整会话,但下次工作时需持续可见。
示例:用户偏好、项目路径、常用命令、某台服务器的特殊配置、某个项目的测试方式。
核心作用:回答“我是谁、环境是什么”,是 Agent 开展工作的基础前提。
3.2 会话检索:按需调取的“历史档案室”
定义:Agent 过去做过什么、聊过什么、哪里踩过坑,不适合每次都塞进上下文,但需要时可快速检索找回。
示例:“上次我们怎么修的那个 Docker 网络问题”“上个月聊过的报价方案在哪里”“之前那次 code review 改了什么”。
核心作用:解决“上次聊过什么、踩过哪些坑”,避免用户重复描述,提升工作效率。
3.3 过程记忆:可复用的“工作方法论”
定义:Agent 下次遇到同类任务时,可以遵循的方法,记录对象从“偏好和对话”转向“做事流程”。
示例:一个复杂 PR review 的检查流程、一个部署失败后的排查顺序、一个固定格式的数据清洗工作流。
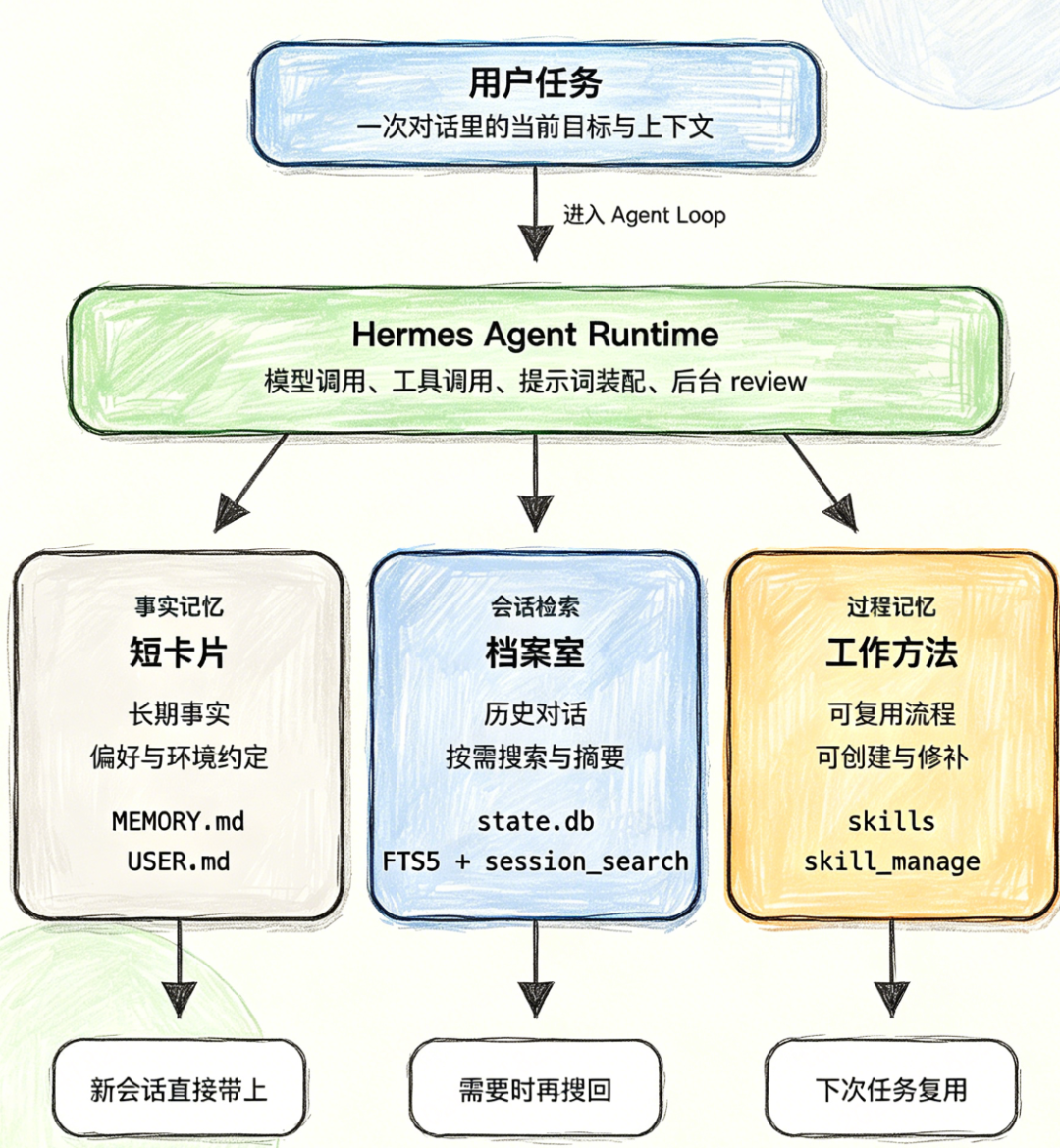
核心作用:明确“这类事下次应该怎么做”,实现经验复用,减少重复试错。
补充说明:OpenClaw 也具备记忆检索、Honcho 接入、实验性 dreaming 能力,但差异在于 Hermes 把“过程记忆”提到核心位置,将其融入工具、提示词和后台 review 流程,形成完整工程链路——这正是我们接下来要详细拆解的 Hermes 三层学习机制。
4、核心拆解:Hermes Agent 三层学习机制
基于前文三类长期资产的铺垫,Hermes 将其落地为三层明确的学习机制,每层均有清晰的载体、功能和工程实现,三者协同形成完整的学习闭环,以下结合源码细节完整拆解:
4.1 第一层:小而硬的事实记忆(随身短卡片)
关键澄清:很多人误以为 Hermes 的内置长期记忆放在 SQLite 中,实则不然。结合官方 memory 文档和源码tools/memory\_tool.py 可知,其 built-in memory 由两个小型 Markdown 文件组成,定位为“随身短卡片”,仅保留最核心的事实信息:
-
~/.hermes/memories/MEMORY.md:主要存放 Agent 的个人笔记,包括环境事实、项目约定、工具 quirks、学到的经验。 -
~/.hermes/memories/USER.md:主要存放用户画像,包括偏好、沟通风格、预期和工作习惯。
默认容量克制(避免占用过多 Token):
-
MEMORY.md:2,200 字符,大约 800 tokens。 -
USER.md:1,375 字符,大约 500 tokens。
核心设计细节(源码级,保障稳定性与安全性):
-
冻结快照机制:
会话开始时,两个文件被加载成 frozen snapshot,
MemoryStore.load*from*disk()方法执行后,内容被捕获到*system*prompt\_snapshot字典;会话中途写入记忆会立即落盘,但不改变当前会话的 system prompt——核心目的是保护 prompt cache,避免频繁修改导致缓存失效、成本和延迟增加,新记忆需等到下一轮会话才进入主上下文。 -
安全扫描:
tools/memory*tool.py定义*MEMORY*THREAT*PATTERNS,写入记忆前,扫描不可见 Unicode 字符和常见 prompt injection / exfiltration 模式(如ignore previous instructions、curl带密钥环境变量、cat .env读取凭据等),因这些记忆后续会进入 system prompt,需严格防护。 -
原子化写入:
MemoryStore.*write*file()不直接用open("w")覆盖文件,而是先写入同目录临时文件(tempfile.mkstemp),调用os.fsync()确保数据落盘,最后用os.replace()做原子替换;读写互斥通过*file*lock()用fcntl.flock获取排他锁,按运行时资产规格保护文件,而非普通日志标准。 -
存储优先级引导:
MEMORY*SCHEMA的 description 明确保存优先级:用户纠正和偏好 > 环境事实 > 程序性知识;同时禁止保存任务进展、会话结果、已完成工作日志,这类内容留在 transcript 中,需用时通过session*search检索——这一边界也为后续第二层“会话检索”的定位埋下伏笔。
4.2 第二层:SQLite + FTS5 是档案室(按需检索,不常驻上下文)
结合第一层事实记忆的边界设计,Hermes 用 SQLite + FTS5 专门承载“历史会话检索”功能,定位为“档案室”,与事实记忆明确区分,既解决历史信息召回问题,又避免占用过多 Token,其源码级实现如下:
核心定位:SQLite + FTS5 不替代 MEMORY.md / USER.md,主要服务于 session\_search(跨会话历史检索),解决“找回历史对话、避免用户重复描述”的问题,类似“档案室”,无需常驻上下文。
源码级实现(hermes*state.py + tools/session*search\_tool.py):
- 数据库配置:
~/.hermes/state.db,使用 WAL 模式支持并发读写,存储 sessions、messages、model config 等信息;创建messages*fts的 FTS5 虚拟表,用于消息内容全文检索;通过 trigger 自动维护 FTS 索引,实现INSERT、DELETE、UPDATEmessages 表时同步更新messages*fts。 - 检索流程:
-
用 FTS5 在历史消息中匹配内容,一次最多拉取 50 条结果;
-
把子会话沿
parent*session*id链解析回根会话,按 session 聚合,排除当前会话; -
读取对应会话完整对话,格式化为可读 transcript;
-
用
*truncate*around\_matches()截断到匹配点附近,默认 100k 字符窗口,截断策略优先全文短语匹配,再多词近邻共现(200 字符内),最后回退到单词位置,选择覆盖匹配位置最多的窗口; -
并行调用快速模型做 focused summary(
asyncio.gather),返回给主 Agent。
- 隐藏模式:不传 query 时,返回最近会话的标题、预览和时间戳,不调用 LLM,零成本;传 query 时,才进入关键词搜索和摘要召回。
- 检索技巧:FTS5 默认更接近 AND 语义,宽泛召回时适合用
OR连接关键词;宽查询无结果时,可将关键词拆分为多个独立搜索并行执行。
补充:Hermes 的 MEMORY*GUIDANCE(prompt*builder.py 中)进一步明确边界:用户偏好、环境事实、稳定约定进 memory;任务进展、临时 TODO、完成记录留在历史 transcript,需用时通过 session\_search 检索;新的做事方法保存为 skill,而非塞进 memory 或 transcript——这一规则自然过渡到第三层“过程记忆”的实现。
4.3 第三层:更值得细看的过程记忆(可复用+可治理,核心学习能力)
事实记忆解决“基础信息”,会话检索解决“历史回顾”,而过程记忆则解决“经验复用与优化”,是 Hermes 学习能力的核心,其载体为 skill\_manage 工具,具备完整的生命周期治理能力,具体实现如下:
核心载体:skill*manage(tools/skill*manager\_tool.py),skills 是 Agent 的 procedural memory,用于保存某类任务的执行方法,区别于 MEMORY.md、USER.md 的宽泛声明式信息,skills 更聚焦、更可执行。
skill 核心内容:捕获某类任务的可复用流程,包括“什么条件下触发 workflow、具体步骤、常见失败模式、结果验证方法、可复用命令/脚本/参考资料”。
skill\_manage 支持的核心操作:
-
create:创建新 skill,需包含 YAML frontmatter(name + description)和 markdown 正文; -
patch:局部修补,用 oldstring / newstring 精确定位替换; -
edit:完整重写 SKILL.md 内容,适合大改; -
delete:删除整个 skill 目录; -
write\_file:给 skill 添加参考文件、模板、脚本或资产,路径需落在references/、templates/、scripts/、assets/四个子目录; -
remove\_file:移除 skill 的支持文件。
核心机制(源码级,保障技能沉淀的合理性与安全性):
- 技能沉淀引导:
agent/prompt*builder.py中的SKILLS*GUIDANCE明确:复杂任务完成后、棘手错误修好后、发现非平凡 workflow 后,需将路径保存为 skill 供下次复用;若 skill 过时、不完整或错误,需立即 patch。其中,创建阈值为“5 次以上工具调用的复杂任务、棘手错误、非平凡工作流”,同时提醒“过时 skill 会误导 Agent”。 - 触发机制:memory 与 skill 的触发机制分离,阈值均通过配置文件可调:
-
Memory review:按用户对话轮次计数(
*turns*since\_memory),默认每 10 轮触发一次; -
Skill review:按单轮内的工具调用迭代次数计数(
*iters*since\_skill),默认累计 10 次迭代后,在本轮主任务结束时触发。
- 后台复盘机制:触发条件满足后,
*spawn*background*review()会 fork 一个独立的 review agent,共享主 agent 的*memory\_store,运行在独立线程,stdout 和 stderr 重定向到/dev/null,最多跑 8 轮迭代;根据触发条件选择 review prompt:
若无值得沉淀的内容,review agent 输出Nothing to save. 后结束;复盘完成后,系统提取成功工具操作(created、updated、added、removed),生成简洁通知反馈用户(如 💾 Memory updated · Skill 'docker-network-fix' created)。
-
仅 memory review:用
*MEMORY*REVIEW\_PROMPT,重点关注用户偏好、人设、工作风格; -
仅 skill review:用
*SKILL*REVIEW\_PROMPT,回看对话判断是否有非平凡方法、试错过程,是否需创建/更新 skill; -
两者同时触发:用
*COMBINED*REVIEW\_PROMPT,一次性评估两件事。
- 安全防护:
skill*manager*tool.py引入tools.skills*guard,每次create、edit、patch、write*file操作后,调用*security*scan*skill()对整个 skill 目录做安全检查;若扫描阻止(should*allow*install返回 False),则回滚操作:create 删除目录、edit/patch 恢复原始内容、write*file 恢复/删除新文件。 - 边界说明:自动生成 skill 不保证质量,可能固化错误经验或过拟合具体项目;因此 schema 强调“简单一次性任务无需保存”“创建/删除需先确认用户”“skill 过时需立即修改”。
以上三层机制构成了 Hermes 核心的学习闭环,而除了内置的三层记忆,Hermes 还支持外部记忆组件作为增强,进一步完善长期资产管理能力,接下来我们拆解外部记忆组件的定位与实现。
5、补充拆解:外部记忆组件(Honcho、Mem0 等)的定位与实现
Hermes 支持多个 external memory provider(Honcho、OpenViking、Mem0 等),但需明确其核心定位——“增强层”,而非内置记忆的替代品,其与内置三层记忆协同工作,进一步提升 Agent 的记忆能力,具体规则及实现如下:
- 核心边界(
agent/memory\_provider.py注释明确):built-in memory(MEMORY.md/USER.md)永远是第一层 provider,不可移除;外部 provider 是 additive(叠加),不禁用内置记忆;同一时间仅运行一个外部 provider,避免工具 schema 膨胀和多记忆后端冲突。 - 接入流程(
agent/memory*manager.py+run*agent.py):
-
tool loop 前,对当前用户消息执行
prefetch\_all(),收集所有 provider 召回结果; -
召回内容经
sanitize*context()清洗(防止</memory-context>等 fence-escape),通过build*memory*context*block()包装成带系统提示的隔离块,注入用户消息旁,不修改 system prompt; -
主响应结束后,调用
sync*all()将本轮问答同步到外部记忆系统,并用queue*prefetch\_all()为下一轮预取排队。
- 生命周期钩子:
MemoryProvider除核心prefetch/sync*turn外,还定义on*turn*start(每轮开始传入运行时信息)、on*session*end(会话结束抽取信息)、on*pre*compress(上下文压缩前抢救消息)、on*memory*write(镜像内置记忆写入)、on*delegation(观察子 agent 任务),可参与 Agent Runtime 多个关键节点。 - 典型示例(Honcho):作为 AI-native memory backend,侧重 dialectic reasoning、user modeling、semantic search 和 persistent conclusions,擅长从长期对话中抽取用户模式、偏好、目标、沟通风格,与内置记忆叠加互补。
总结:四类长期资产的定位的区别(清晰区分,避免混淆):
-
MEMORY.md/USER.md:每次启动必带的短卡片(事实记忆); -
session\_search:需用时调取的历史档案室(会话检索); -
Honcho / Mem0 等:外置增强记忆,做深度用户建模和语义召回(增强层);
-
skills:可复用、可治理的做事方法(过程记忆)。
明确 Hermes 内置三层机制与外部记忆组件的定位后,我们回到开篇的核心疑问——OpenClaw 加自总结 Skills 后,与 Hermes 的差异到底何在?
6、核心答疑:OpenClaw 加自总结 Skills 后,与 Hermes 的差异解析
核心结论:二者的差异关键不在于“有没有自总结能力”,而在于“自总结的经验被放到运行时的哪一层”——若仅做离线经验归档,二者仍有明显差异;若将经验沉淀纳入运行时主路径,二者会高度趋同,具体拆解如下:
6.1 两种改造路径的差异(对应原文图示核心逻辑)
-
路径一:补一个经验归档层(仅做离线总结):会话结束后生成总结文件、判断是否沉淀,仅实现 Markdown 归档,仍需解决“触发、修补、治理”的问题,仅能实现“会总结”,更接近经验归档,与 Hermes 差异明显。
-
路径二:进入 Runtime 主路径(完整工程化):任务完成后后台 review,实现事实/历史/流程分流,通过
skill\_manage完成 skill 的 create/patch/edit/delete,实现“会学习”,可复用且能持续修补,真正接近 Hermes 的 learning loop。
判断标准:不是“能不能写文件”,而是“总结的经验能否被工具、提示词、后台 review 和安全边界持续维护”——这正是 Hermes 与“仅做总结归档”的核心区别。
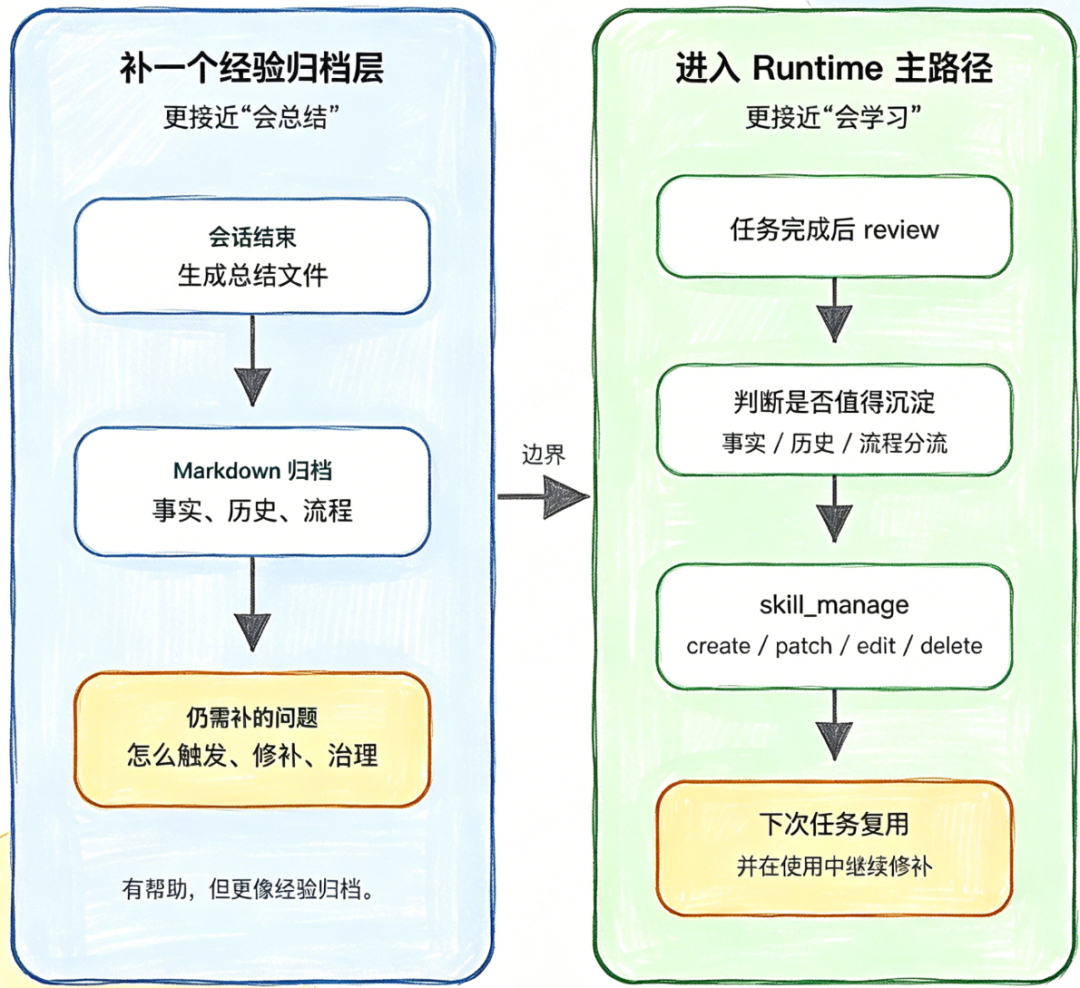
6.2 OpenClaw 与 Hermes 的迁移与趋同基础
值得注意的是,Hermes 已提供 openclaw-migration optional skill 及 hermes claw migrate 迁移路径,这说明二者在长期资产层面有较多可对齐的内容,为趋同提供了基础,具体迁移细节如下:
-
可直接映射的内容:OpenClaw 的
MEMORY.md、USER.md、SOUL.md、命令 allowlist、workspace instructions 及多处 skills 来源,可直接映射到 Hermes 对应位置; -
需人工复核的内容:OpenClaw 的部分 memory backend、skills registry、plugins、hooks、multi-agent list、channel bindings,会被归档到 migration archive,需人工复核后才能适配 Hermes 配置。
6.3 OpenClaw 实现与 Hermes 趋同的关键步骤
OpenClaw 现有 Gateway、workspace、memory_search、Honcho 和 experimental dreaming 已能承接部分长期信息,要实现与 Hermes 在学习 loop 层面的趋同,需补充以下工程化步骤:
- 任务结束后自动判断经验是否值得沉淀;
- 区分事实、历史会话和流程,不将所有内容塞进一个 memory 文件;
- 为 skill 提供 create、patch、edit、delete 的工具面;
- 将“事实进 memory,历史靠 search,流程进 skill”写入 Agent guidance;
- 允许 Agent 在 skill 过时或出错时立即 patch;
- agent-created skills 需经过安全扫描和权限边界校验;
- 同类任务可检索、加载、执行 skill,并持续修正。
6.4 二者核心差异总结(未趋同前)
在 OpenClaw 完成上述工程化改造前,二者的核心差异集中在“系统重心与运行时设计”,具体如下:
-
OpenClaw:强项在 gateway / control / memory plane,侧重多入口、多会话、插件、workspace、memory search、Honcho、experimental dreaming,skills 更偏向离线经验归档;
-
Hermes:强项在 self-improving runtime,将会话检索、curated memory、skill_manage、后台 review、外部 memory provider 组织成明确的学习链路,侧重执行与自优化。
通俗类比:OpenClaw 更像“记性越来越好的总调度”,Hermes 更像“干完活会自己写复盘文档的执行者”,二者的厚度体现在不同的运行层。
拆解完二者的差异与趋同逻辑后,我们进一步提炼 Hermes 三层学习机制带来的核心工程启示,为后续 Agent 设计提供参考。
7、核心启示:Hermes 学习机制的工程化价值
Hermes 的核心价值不在于“用了 SQLite”“接了 Honcho”等可复刻的功能点,而在于其长期资产的分层逻辑和工程化选择,这些选择为 Agent 学习能力的稳定性提供了保障,核心启示如下:
- 长期信息需拆分管理:事实、历史、流程是三类不同资产,事实过多会污染上下文,历史常驻会浪费 token,流程不维护会固化错误 SOP,三者存储、召回、更新频率不同,混管易出问题——这是 Hermes 三层机制的核心设计逻辑。
- 过程记忆需完整生命周期:skill 创建后不能默认永久正确,需支持 patch、替换、删除,同时携带验证步骤和失败模式,这比“自动总结成 Markdown”更重要、更难实现——这是 Hermes 区别于普通“总结归档”的关键。
- 学习闭环需落地工程化:仅靠提示词引导模型“总结经验”,效果不稳定;Hermes 将其落地到工具、配置、nudge、后台 review 和文件结构,从工程设计上保证学习闭环的稳定性(效果仍需长期验证)。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献563条内容
已为社区贡献563条内容

所有评论(0)