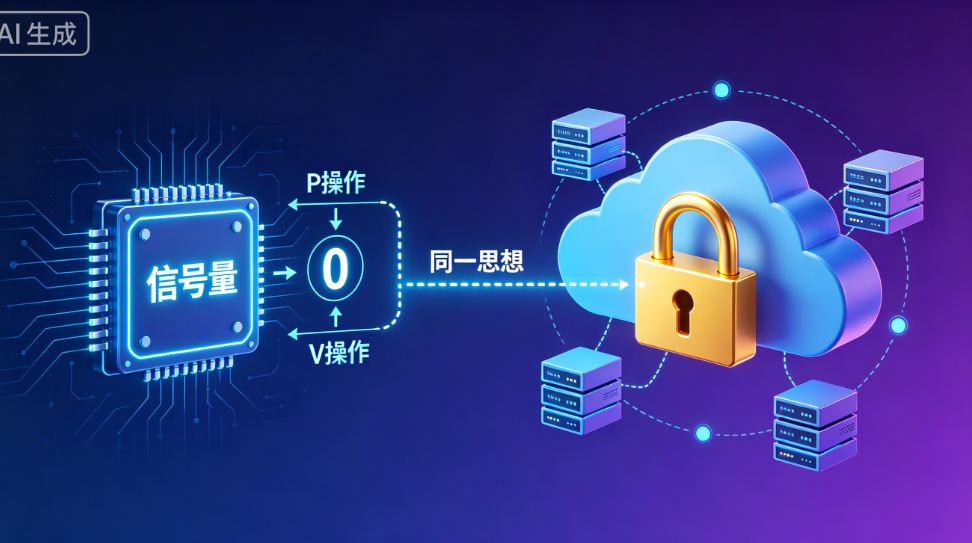
从 PV 操作到分布式锁:操作系统的“信号量”和 Java 里的“抢锁”竟然是同一套思想?
这篇文章从Java开发者的视角解读操作系统中的PV操作(信号量)概念,揭示了它与现代编程技术的本质联系。作者通过对比单机环境和分布式环境下的同步机制,指出PV操作实质上是锁机制的原型:synchronized对应二进制信号量,Semaphore实现计数信号量,而分布式锁则是PV操作在网络环境中的延伸。文章用代码示例展示了PV操作与Java锁、限流器、分布式锁的对应关系,并分享了在实际AI项目中应用
今天学习操作系统——信号量、PV 操作、临界区。
看那个 P 操作和 V 操作的流程图,我忽然愣住了:
这不就是我 Java 代码里的synchronized和ReentrantLock吗?
再一想,分布式场景下的 Redis 锁、ZooKeeper 锁,不也是 PV 操作的“网络版”?
我是Evan,一个刚啃完 PV 操作的 Java+AI 学生。
今天这篇博客,我不想背概念,而是从 Java 开发的视角,把操作系统的信号量和我们天天写的锁、分布式互斥对应起来。你会发现:PV 操作是单机版的“锁原型”,而分布式锁只是把它搬到了网络世界。
一、先搞懂三个词:临界区、P 操作、V 操作
1.1 临界区(Critical Section)
就是一段 同一时刻只允许一个线程执行的代码。比如:
// 这段代码就是临界区
synchronized (this) {
count++; // 多线程环境下必须互斥
}1.2 P 操作(Proberen,荷兰语“尝试”)
-
作用:进入临界区之前检查资源是否可用。
-
如果资源计数 > 0,则减 1,继续执行;
-
如果资源计数 = 0,则当前线程阻塞,进入等待队列。
1.3 V 操作(Verhogen,“增加”)
-
作用:退出临界区后释放资源。
-
把资源计数加 1,并唤醒一个等待的线程。
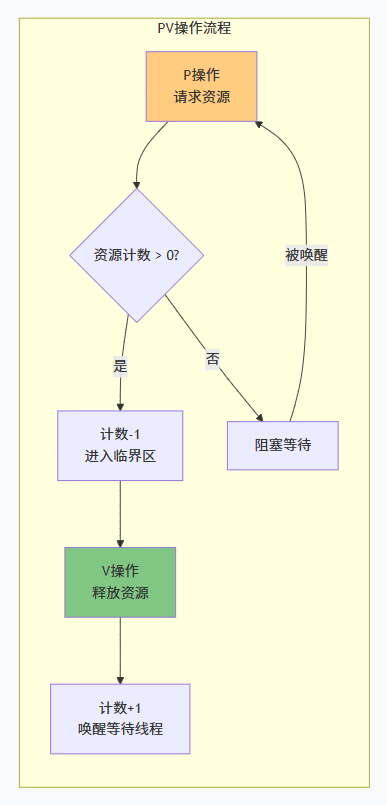
一句话:P 是“拿锁”,V 是“放锁”。
二、PV 操作和 Java 锁的惊人相似
2.1 二进制信号量 → synchronized
二进制信号量只有 0 和 1,就是一把互斥锁。
它的 P/V 操作完美对应 synchronized 的底层实现:
// 信号量版(Java 中的 Semaphore)
Semaphore mutex = new Semaphore(1);
mutex.acquire(); // P 操作
try {
// 临界区
count++;
} finally {
mutex.release(); // V 操作
}
// synchronized 版
synchronized (this) {
count++;
}本质上,synchronized 就是 JVM 帮你管理的二进制信号量。
2.2 计数信号量 → 限流器 / 连接池
计数信号量允许 N 个线程同时进入。这在 Java 开发中太常见了:
// 最多允许 10 个线程同时访问
Semaphore sem = new Semaphore(10);
sem.acquire(); // P 操作
try {
// 调用第三方 API,限制并发数
} finally {
sem.release(); // V 操作
} 这就是限流的雏形。在知识汇秒杀系统中,我们用 Semaphore 控制同时处理订单的线程数,防止数据库被打垮。
三、PV 操作和分布式锁:只是从“单机内存”搬到了“网络”
PV 操作依赖的是共享内存(信号量对象在内核中)。
分布式环境下,没有共享内存了,怎么办?把“信号量”放到一个外部服务里。
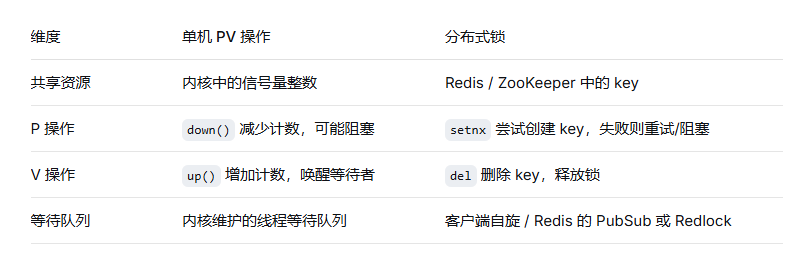
一个 Redis 分布式锁的 PV 映射:
// P 操作(获取锁)
while (!redis.setnx("lock_key", "thread_id")) {
Thread.sleep(10); // 自旋等待
}
// 临界区
transferMoney();
// V 操作(释放锁)
redis.del("lock_key"); 这不就是网络版的 PV 吗?
区别在于:单机 PV 的阻塞是高效的内核挂起;而分布式锁的阻塞往往是用户态自旋或轮询,开销更大。
四、一个让你印象深刻的对比表格

五、我在 AI 项目中用“PV 思想”解决过的实际问题
在智答知识库系统中,我们需要同时处理多个用户的文档上传 + 向量化。
Python 的 FastAPI 服务用到了 asyncio.Semaphore 控制同时进行的 Embedding 请求数(防止显卡 OOM)。
# Python 版信号量(和 PV 完全一致)
sem = asyncio.Semaphore(5)
async def embed_doc(text):
async with sem: # 相当于 P 操作
result = await call_ollama(text) # 临界区
# V 操作自动执行而在 Java 端,我们用 Redisson 的分布式锁来保证同一个文档不会被两个线程同时解析:
RLock lock = redisson.getLock("doc_lock_" + docId);
lock.lock(); // 分布式 P 操作
try {
parseDocument(doc);
} finally {
lock.unlock(); // 分布式 V 操作
}看到没?从 Dijkstra 的信号量,到 Redis 的分布式锁,五十年来,互斥的思想从来没变过,只是实现的地点和形式变了。
我们知道 PV 操作中的 P 操作在资源不足时会让当前进程阻塞(进入等待队列,不消耗 CPU)。但是在分布式锁的实现中(比如 Redis 的 setnx),如果锁被占用,我们通常会让线程自旋重试或定时轮询,这会造成 CPU 空转。
问题:为什么分布式锁很难实现像单机 PV 那样高效的“阻塞等待”?如果让你设计一个理想的分布式阻塞锁,你会怎么做?
欢迎在评论区分享你的设计思路 —— 下一篇我会聊聊 “分布式锁的阻塞实现:基于 ZooKeeper 的临时顺序节点与 watch 机制”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)