【大模型微调02】—— 后训练之大模型微调(Fine Tuning)详解:SFT、FFT核心流程及常见微调方法详解
文章摘要 大模型微调(Fine-Tuning)是适配特定任务或垂直领域的关键环节,成本远低于重新预训练。微调流程分为数据准备、模型调优、评估迭代和部署落地四步。微调方法分为全参数微调(Full FT)和参数高效微调(PEFT),后者因低成本成为主流。本文重点解析了5种PEFT方法:LoRA通过低秩矩阵减少参数量;QLoRA结合量化进一步降低显存;Adapter Tuning模块化插入适配器;Pre
前言
大模型预训练后,想要适配特定任务(如行业问答、文本生成)或垂直领域(医疗、法律),微调(Fine-Tuning) 是核心环节。它能在保留模型通用能力的基础上,定向优化任务适配性,且成本远低于重新预训练。本文将系统拆解大模型微调的完整流程、分类方式,并详细讲解 5 种工业界常用的微调方法,帮你快速选型落地。
一、大模型微调的核心流程(通用范式)
无论采用哪种微调方法,核心流程均遵循 “数据准备→模型调优→评估迭代→部署落地” 四步走,具体细节如下:
1. 数据准备(基础中的基础)
- 数据类型:根据任务目标选择(如 SFT 用 “指令 - 响应对” 数据,领域适配用纯领域语料);
- 数据要求:高质量、去噪去重、符合任务分布(避免数据偏差),量级通常为数千~数万条(视任务复杂度调整);
- 数据格式:统一为模型可识别格式(如 JSONL 的
{"input":"指令","output":"正确响应"})。
2. 模型调优(核心环节)
- 选择微调方法(全参数 / 参数高效微调);
- 配置超参数(学习率、 batch size、训练轮数 epoch,建议小学习率(1e-5~1e-4)避免过拟合);
- 训练过程监控:关注损失值(Loss)下降趋势、验证集准确率 / BLEU 等指标。
3. 评估迭代
- 自动化评测:用任务相关指标(如分类任务看 Accuracy,生成任务看 BLEU/Rouge);
- 人工抽验:重点检查输出的逻辑性、事实性、安全性;
- 迭代优化:根据评估结果调整数据(补充标注)或超参数,重复训练。
4. 部署落地
- 模型压缩(量化、蒸馏):适配部署环境(CPU/GPU/ 边缘设备);
- 推理加速:结合 TensorRT、ONNX 等框架优化推理速度;
- 线上监控:跟踪实际使用效果,必要时二次微调。
二、大模型微调的两大分类(按训练参数范围)
微调本质是 “调整模型参数以适配任务”,按调整参数的多少,可分为两类:
表格
| 分类 | 核心特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 全参数微调(Full FT) | 调整模型所有参数(主干 + 输出层) | 效果上限高,适配性强 | 算力消耗极大(需多卡 GPU)、易灾难性遗忘、训练周期长 | 大厂、超大参模型(如 GPT-3)、核心任务 |
| 参数高效微调(PEFT) | 冻结主干参数,仅训练少量新增参数(1% 以内) | 算力要求低(单卡可跑)、成本低、无遗忘风险 | 效果略低于全参数微调(优质数据下差距极小) | 中小企业、个人开发者、垂直领域任务 |
注:当前工业界主流是 PEFT 方法(如 LoRA、Adapter),兼顾效果与成本,本文重点讲解 PEFT 下的 5 种常用方法。
三、5 种主流微调方法详细解析
1. LoRA(Low-Rank Adaptation)—— 最常用的轻量微调
LoRA 的全称是 “Low-Rank Adaptation”(低秩适应)。它不对原模型做微调,而是在原始模型旁边增加一个旁路,通过学习小参数的低秩矩阵来近似模型权重矩阵的参数更新,训练时只优化低秩矩阵参数,通过降维度再升维度的操作来大量压缩需要训练的参数。论文中的方法如下图所示,在旁路有A矩阵和B矩阵,分别对应了降维矩阵和升维矩阵。由于 r 远小于 d, 因此 LoRA 方法可以极大地减少微调训练的参数量。
假设我们有一个维度为3x3的M矩阵需要微调,但我们没有直接对这个3x3的矩阵进行参数更新,而是对维度为3x1的A矩阵和维度为1x3的B矩阵进行更新,最后用A矩阵乘B矩阵得到了一个3x3的C矩阵,再将C矩阵叠加到M矩阵上,完成对M矩阵的更新。在这个例子中,我们更新的矩阵共6个参数(3个来自A矩阵,3个来自B矩阵),只比直接更新M矩阵的9个参数少了3个。你也许觉得参数量没有少太多,但是如果我们要微调的矩阵维度是1000x1000,那么我们通过LoRA方法能够少调整的参数就有:1000x1000-2x1000=998000,需要更新的参数量减少了非常多。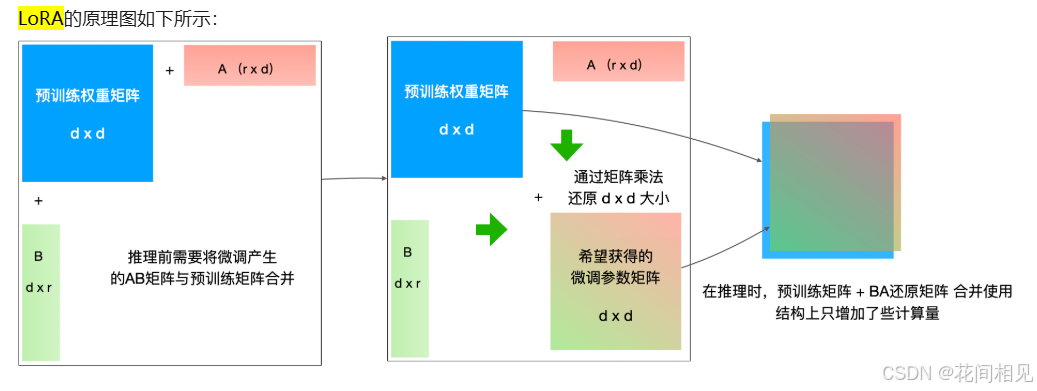
核心原理
在大模型的 Transformer 层(如多头注意力的 Q/K/V 矩阵)中,插入两个低秩矩阵(A 和 B),训练时仅更新这两个小矩阵,主干参数完全冻结。
- 低秩矩阵:维度远小于原矩阵(如原矩阵 1024×1024,低秩矩阵 1024×64 + 64×1024);
- 训练后:将低秩矩阵的乘积(A×B)与原矩阵叠加,不改变模型结构,部署时可合并参数。
关键特点
- 优点:训练参数极少(仅原模型的 0.1%~1%)、算力消耗低(单卡 GPU 可训 7B/13B 模型)、无灾难性遗忘、部署简单(可合并参数或单独加载 LoRA 权重);
- 缺点:依赖低秩假设,对部分复杂任务(如多步推理)效果可能略逊于全参数微调;
- 超参选择:秩(rank)通常设 8~64(秩越大效果越好,但训练成本略增)、α(缩放因子)一般等于 rank。
适用场景
- 通用场景:指令微调(SFT)、领域适配(医疗 / 法律 / 代码);
- 典型工具:Hugging Face PEFT 库、LoRA 库(peft.LoraConfig)、Colossal-AI。
2. QLoRA(Quantized LoRA)—— 极致轻量化微调
核心原理
在 LoRA 基础上,增加模型量化步骤:先将大模型量化为 4bit/8bit(如 GPTQ、AWQ 量化),再插入低秩矩阵进行训练,进一步降低显存占用。
- 量化核心:通过压缩模型权重精度(如 FP16→4bit),减少显存消耗(4bit 量化可节省 75% 显存);
- 关键技术:双量化(Double Quantization)、零冗余优化器(ZeRO),避免量化精度损失。
关键特点
- 优点:显存占用极低(单卡 24GB 可训 13B 模型,48GB 可训 70B 模型)、成本最低、兼容 LoRA 的所有优势;
- 缺点:量化过程需额外配置,对极高精度要求的任务(如医疗诊断)可能不适用;
- 与 LoRA 的区别:QLoRA 是 “量化 + LoRA” 的组合,比 LoRA 更省显存,适用更小显存设备。
适用场景
- 低资源场景:个人开发者(单卡 GPU)、边缘设备、超大参模型(30B+)微调;
- 典型工具:bitsandbytes 库(量化)+ PEFT 库(LoRA)、QLoRA 官方实现。
3. Adapter Tuning(适配器微调)—— 模块化插入式微调
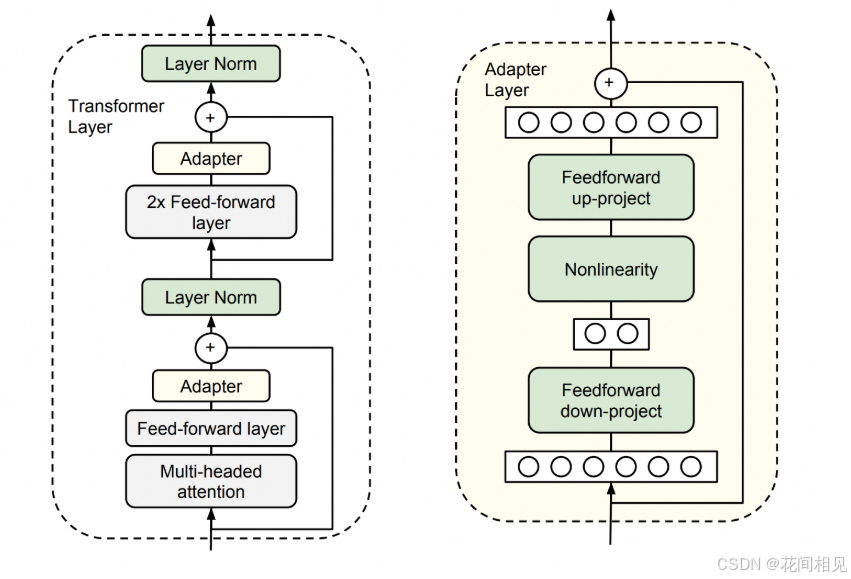
核心原理
在 Transformer 层(如多头注意力层之后、Feed-Forward 层之后)插入独立的 “适配器模块”(Adapter Block),训练时仅更新适配器参数,主干参数冻结。
- 适配器模块结构:通常是 “Down-Projection(降维)→ Activation(激活函数)→ Up-Projection(升维)”;
- 降维逻辑:将高维特征(如 1024 维)压缩到低维(如 64 维)再恢复,减少训练参数。
关键特点
- 优点:模块化设计(可灵活插入 / 移除)、适配性强(支持任意 Transformer 模型)、训练稳定;
- 缺点:会改变模型结构(新增模块),部署时需兼容适配器层,显存占用略高于 LoRA;
- 常见结构:Parallel Adapter(并行插入)、Sequential Adapter(串行插入)。
适用场景
- 多任务微调(如同时适配分类、生成任务)、自定义模型结构场景;
- 典型工具:Hugging Face PEFT 库(AdapterConfig)、AdapterHub。
4. Prefix Tuning(前缀微调)—— 指令感知型微调

核心原理
在输入文本前添加一段 “可学习的前缀向量”(Prefix Embedding),训练时仅更新前缀向量,主干参数和输入文本的嵌入向量均冻结。
- 前缀向量:本质是虚拟的 “指令 tokens”(如 “### 医疗问答:”),模型通过学习前缀来适配特定任务;
- 实现方式:将前缀向量插入 Transformer 的每一层,确保任务信息在所有层传递。
关键特点
- 优点:无需修改模型结构、适配自然语言生成(NLG)任务效果好、可共享主干模型(多个任务共用一个模型,仅替换前缀);
- 缺点:前缀长度需仔细调优(过短效果差,过长成本高)、对分类任务效果不如 LoRA/Adapter;
- 超参选择:前缀长度(通常设 10~100)、前缀隐藏层维度。
适用场景
- 生成类任务:文本摘要、对话生成、指令遵循(SFT);
- 典型工具:Hugging Face PEFT 库(PrefixTuningConfig)、Fairseq 实现。
5. Prompt Tuning(提示微调)—— 分类任务优选
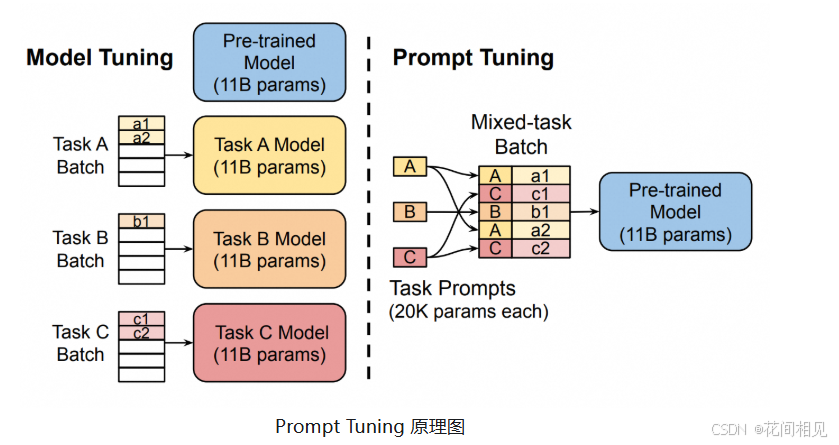
核心原理
与 Prefix Tuning 类似,但 “可学习向量” 不是加在输入前,而是作为 “虚拟提示词” 嵌入到输入中,且仅在输入层添加(不贯穿所有 Transformer 层)。
- 核心区别:Prompt Tuning 的可学习向量是 “任务特定的”(如分类任务的 “情感倾向:”),且参数更少(通常仅数千~数万个);
- 适用任务:更侧重分类任务(如文本分类、情感分析),生成任务效果不如 Prefix Tuning。
关键特点
- 优点:参数最少(训练成本最低)、部署极简单(仅需加载少量提示参数)、适合多任务并行;
- 缺点:生成任务效果一般、对提示设计敏感;
- 与 Prefix Tuning 的区别:Prompt Tuning 仅在输入层添加向量,Prefix Tuning 在所有 Transformer 层添加向量。
适用场景
- 分类任务:情感分析、文本分类、命名实体识别(NER);
- 典型工具:Hugging Face PEFT 库(PromptTuningConfig)、Google 官方实现。
四、5 种微调方法对比与选型建议
表格
| 方法 | 训练参数占比 | 显存占用 | 模型结构改动 | 核心优势 | 推荐场景 |
|---|---|---|---|---|---|
| LoRA | 0.1%~1% | 低 | 无(仅插入矩阵) | 平衡效果与成本,通用性强 | 绝大多数场景(SFT、领域适配) |
| QLoRA | 0.1%~1% | 极低 | 无(量化 + LoRA) | 低显存,超大参模型微调 | 单卡 GPU、30B + 模型、低资源环境 |
| Adapter Tuning | 1%~5% | 中低 | 有(新增模块) | 模块化,多任务适配 | 多任务训练、自定义模型结构 |
| Prefix Tuning | 5%~10% | 中 | 无(添加前缀) | 生成任务效果好 | 文本生成、指令遵循任务 |
| Prompt Tuning | 极低 | 无(添加提示) | 分类任务最优,成本最低 | 文本分类、情感分析等判别式任务 |
选型口诀
- 通用场景选 LoRA,性价比之王;
- 显存不够用 QLoRA,超大模型也能训;
- 分类任务用 Prompt Tuning,参数最少部署快;
- 生成任务试 Prefix Tuning,效果更优;
- 多任务场景选 Adapter,模块化灵活适配。
五、总结
大模型微调的核心是 “用最低成本实现任务适配”,当前PEFT 方法已成为工业界主流,其中 LoRA 以 “效果好、成本低、部署简单” 成为首选。实际选型时,需根据显存资源、任务类型(分类 / 生成)、模型规模灵活选择:
- 个人 / 中小企业:优先 LoRA/QLoRA;
- 分类任务:优先 Prompt Tuning;
- 生成任务:优先 LoRA/Prefix Tuning;
- 多任务场景:优先 Adapter Tuning。
如果需要具体方法的代码实现(如 LoRA 微调 LLaMA-2),或超参数调优技巧,欢迎在评论区留言!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)