企业级项目三:基于 Paimon 湖仓的 AI 数据分析平台
如果你刚刚看完上面的项目演示,应该已经有一个直观感受:用户不需要写 SQL,直接用自然语言提问,系统自动返回「分析结论 + 可视化图表」
0.前言
如果你刚刚看完上面的项目演示,应该已经有一个直观感受:用户不需要写 SQL,直接用自然语言提问,系统自动返回「分析结论 + 可视化图表」
这其实就是一个典型的 AI + 大数据结合的落地形态。
但很多人看到这里,第一反应往往是:这个不就是套个大模型做 NL2SQL 吗?
说实话,如果只是做到能问能答,这个项目的价值其实并不高。
真正难的,从来不是将自然语言翻译成一条 SQL,而是下面这些问题:
- 数据从哪里来?如何保证实时与离线一致?
- 大模型生成的 SQL,怎么保证可控、可执行、可权限隔离?
- 查询性能如何保障?面对大规模数据还能不能秒级响应?
- 业务真的能用起来吗,而不是 demo 好看、上线就废?
这些,才是一个 AI 数据分析平台真正的工程难点!
本项目并不是一个简单的 AI 问数Demo,而是从数据底座 → 计算引擎 → AI 应用 → 权限体系完整打通的一套方案:
- 基于 Paimon 湖仓,实现流批一体的数据存储与更新
- 使用 Flink 统一实时与离线数据加工链路
- 通过 Doris 提供高性能 OLAP 查询能力
- 借助 LLM + 工作流编排,实现自然语言到 SQL 的智能转换
- 配合 Flask 微服务 + 权限体系,保证查询安全与可控
最终实现的效果是:
- 业务人员"开口即查"
- 数据分析"即问即答"
- 查询结果"直接可视化"
为了让你更清晰地理解整个项目的设计与实现,我在下面整理了完整的项目目录结构,你可以先快速浏览整体框架,再按需深入具体模块。
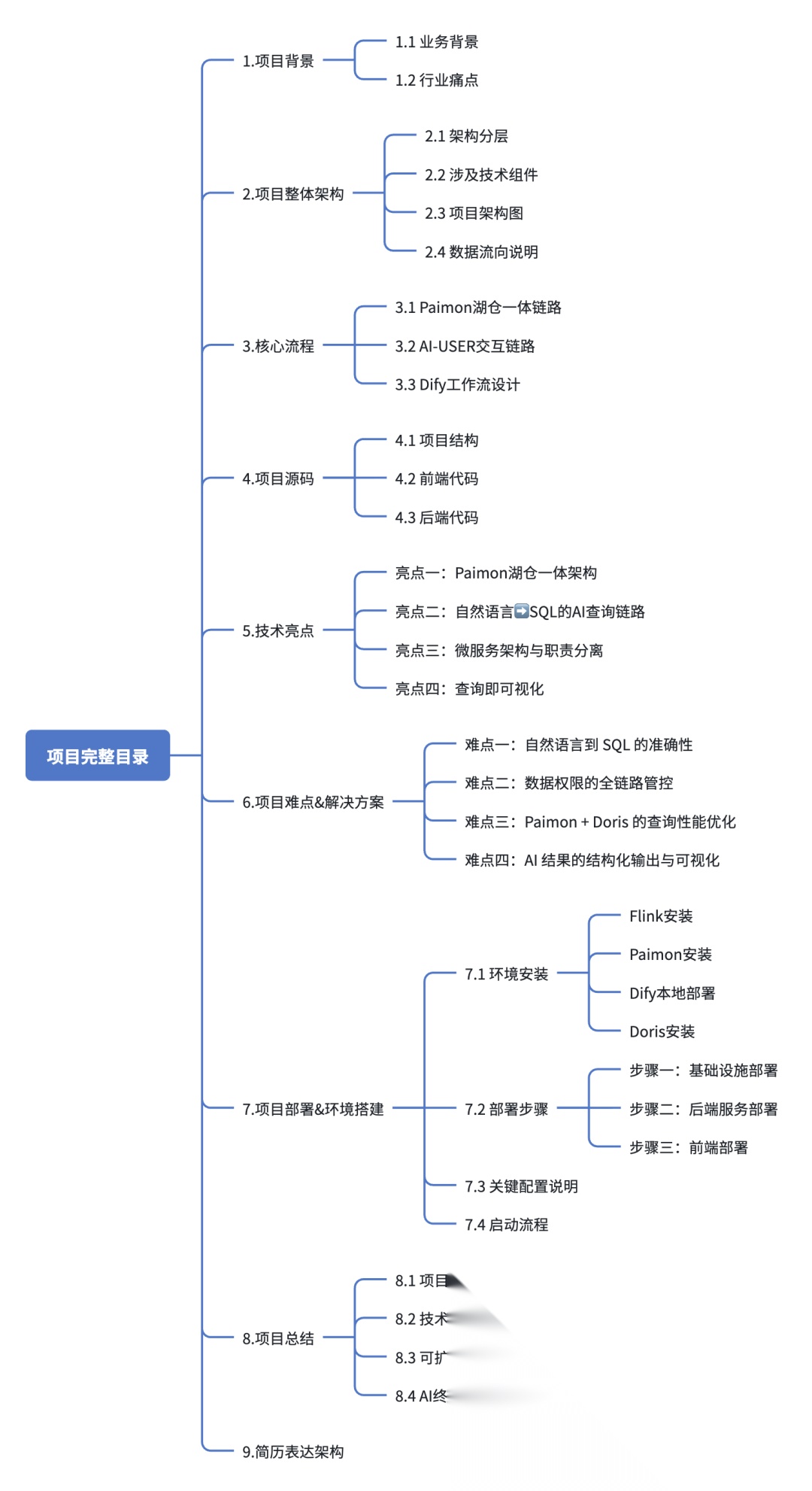
接下来,我会从架构设计、数据建模、AI 问数链路到核心代码实现,逐步拆解这个项目的关键细节。
下面,正式进入项目文档试读部分。
1.项目背景
在电商、零售等行业中,数据驱动决策已成为核心竞争力。业务团队需要频繁分析交易概览、渠道转化、区域 GMV、商品排行、用户增长等多维数据。然而,传统的分析流程往往需要经过提需求 → 排期 → SQL 开发 → 出报表的漫长链路,数据工程师和业务人员之间存在巨大的沟通壁垒。
本项目旨在构建一个 AI 数据分析平台,让业务人员通过自然语直接与数据对话,实现开口即查、一问即答的智能分析体验。
2.项目整体架构
本项目涉及到的核心技术栈:Paimon + Flink + Doris + Dify + Python + Flask + React 18 + Vite + ECharts + MySQL + Kafka
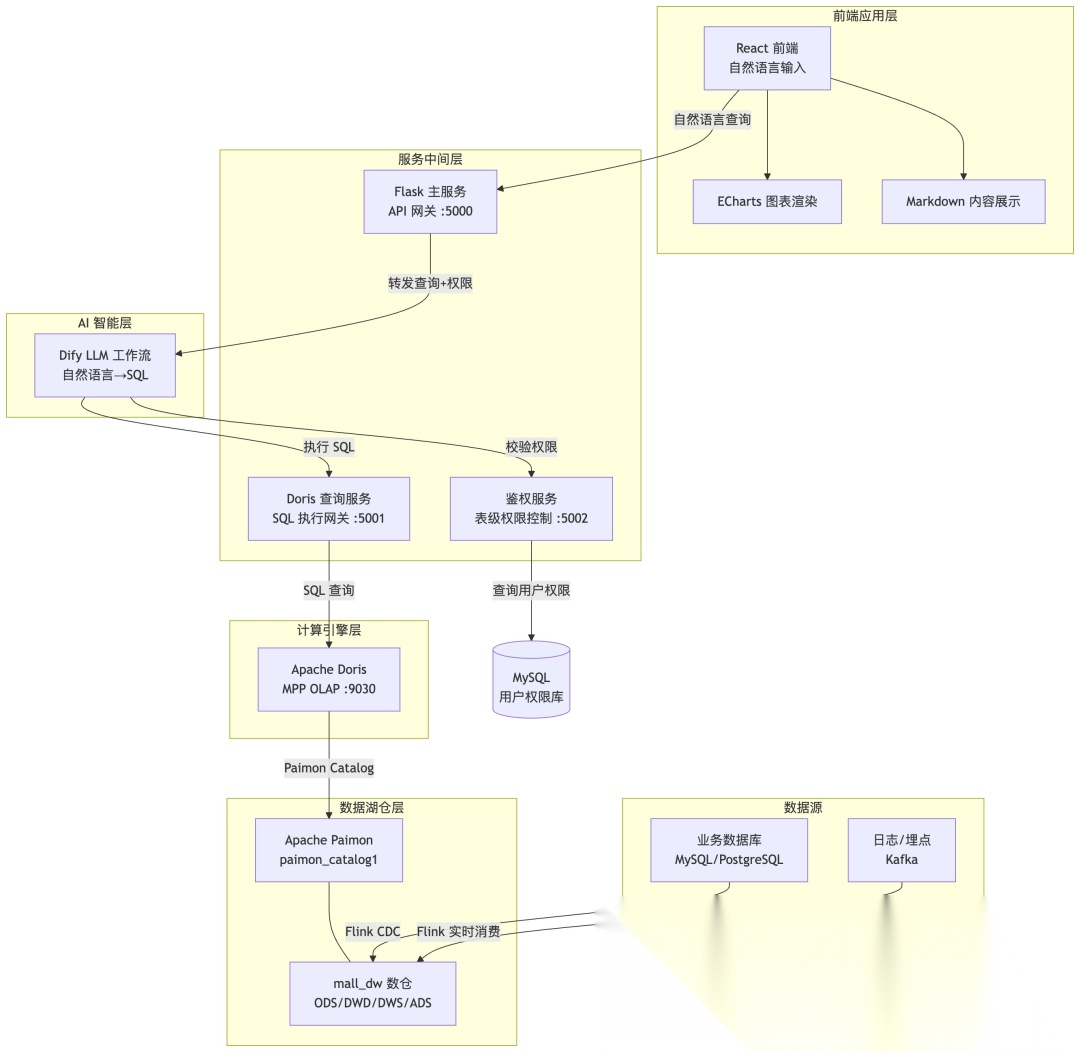
3.核心流程
3.1 Paimon湖仓一体链路
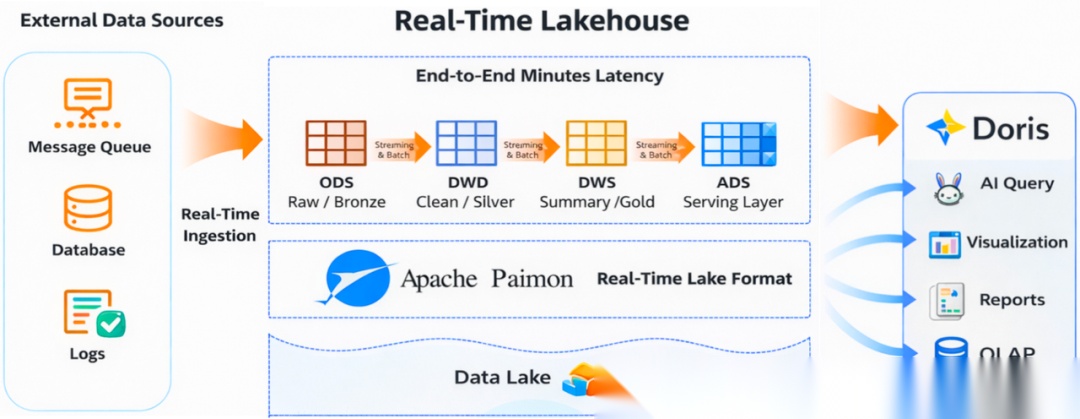
本项目的核心设计是 Flink + Paimon 的湖仓一体:Flink 作为唯一计算引擎,通过 Streaming 模式处理实时数据、Batch 模式处理离线数据,统一写入 Paimon 湖仓。
采用经典的分层数仓模型,数据存储在 paimon_catalog1.mall_dw 中:

3.1.1 OSS存储 & 创建Catalog
 ```plaintext
```plaintext
– 创建paimon catalogCREATECATALOG paimon_catalog1 WITH (‘type’ = ‘paimon’,‘warehouse’ = ‘oss://mall-dw1/’,‘fs.oss.endpoint’ = ‘oss-cn-hangzhou.aliyuncs.com’,‘fs.oss.accessKeyId’ = ‘xxx’,‘fs.oss.accessKeySecret’ = ‘xxx’);-- 切换catalogUSECATALOG paimon_catalog1;-- 创建数据库CREATEDATABASEIFNOTEXISTS mall_dw;-- 使用数据库USE mall_dw;-- 设置结果显示格式SET’sql-client.execution.result-mode’ = ‘tableau’;
### 3.1.2 ODS层
#### 3.1.2.1 用户表
```plaintext
CREATE TABLE ods_user_info ( user_id BIGINTCOMMENT'用户ID', user_name STRINGCOMMENT'用户名', gender STRINGCOMMENT'性别', age INTCOMMENT'年龄', province STRINGCOMMENT'省份', city STRINGCOMMENT'城市', register_time TIMESTAMP(3) COMMENT'注册时间', register_channel STRINGCOMMENT'注册渠道', user_status STRINGCOMMENT'用户状态', dt STRINGCOMMENT'分区日期yyyyMMdd', PRIMARY KEY (user_id, dt) NOTENFORCED) PARTITIONED BY (dt) WITH ( 'bucket' = '4');CREATETABLE mysql_user_info ( user_id BIGINT, user_name STRING, gender STRING, age INT, province STRING, city STRING, register_time TIMESTAMP(3), register_channel STRING, user_status STRING, PRIMARY KEY (user_id) NOTENFORCED) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mall', 'table-name' = 'user_info');INSERTINTO ods_user_infoSELECT user_id, user_name, gender, age, province, city, register_time, register_channel, user_status, DATE_FORMAT(register_time, 'yyyyMMdd') AS dtFROM mysql_user_info;
3.1.3 DWD层
3.1.4 DWS层
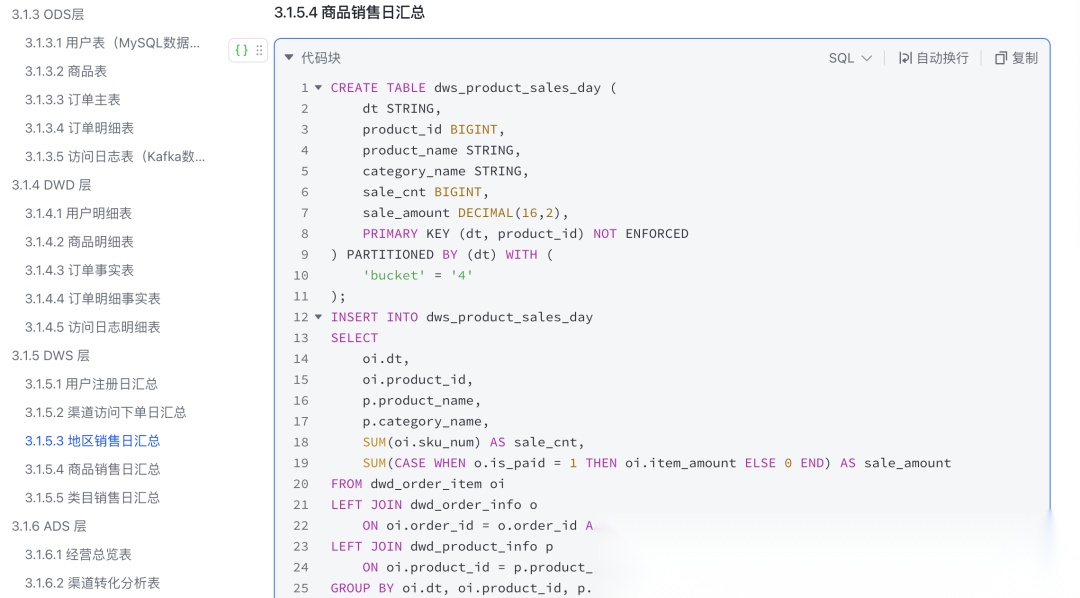
3.1.5 ADS层
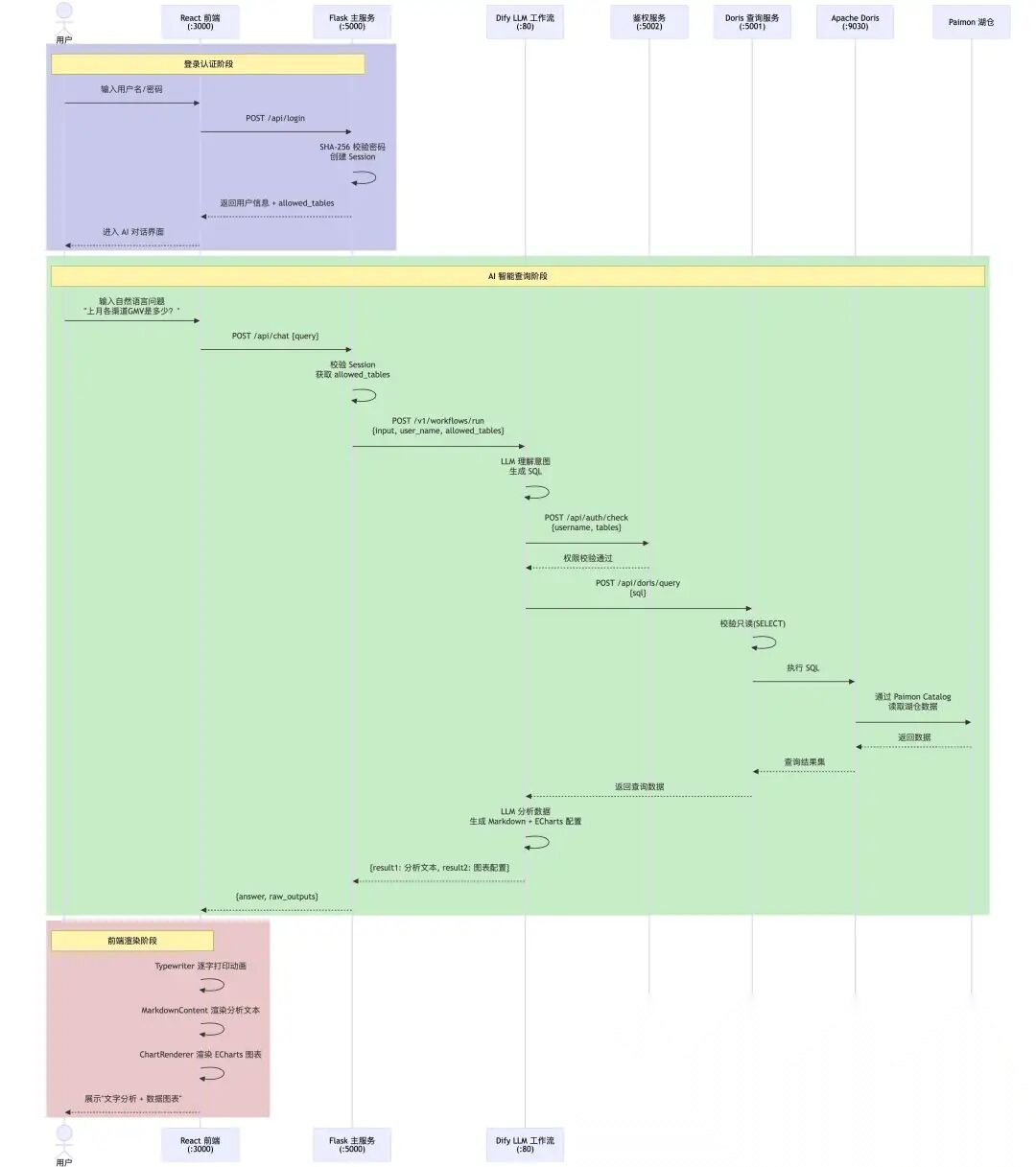
3.2 AI-USER交互流程
3.3. Dify工作流设计
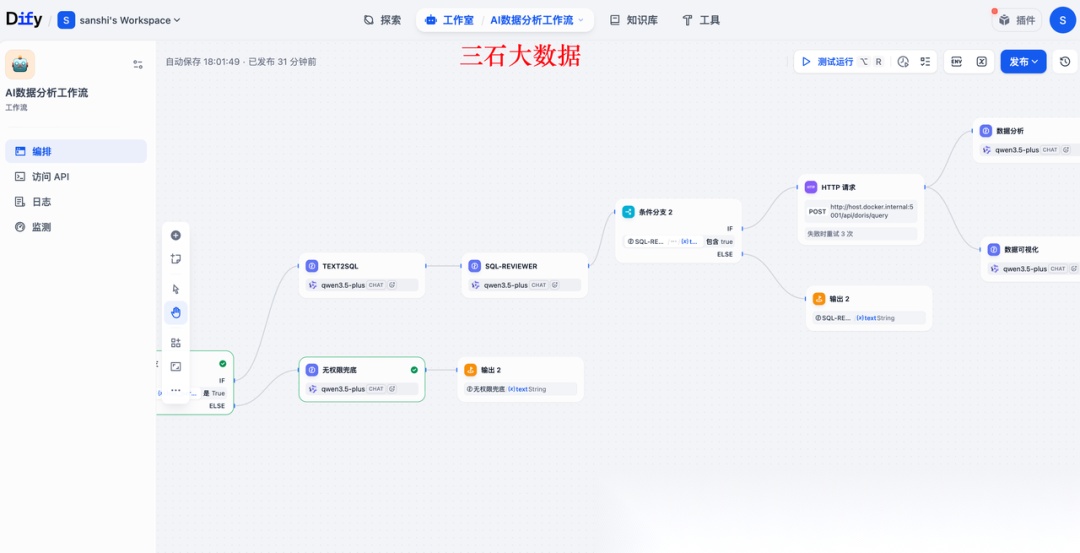
SQL审核提示词如下:
你是 Doris SQL 审核助手。请检查以下SQL是否符合安全与可执行要求。规则:1. 只能是 SELECT 语句;2. 不允许包含 INSERT、UPDATE、DELETE、DROP、TRUNCATE、ALTER、CREATE;3. 只能使用本次 authorized_tables 中的表;4. 不允许使用不存在字段;5. 不允许 join 未授权表;6. 明细查询必须有限制行数;7. 若合法,返回 valid=true;8. 若不合法,给出 issues 和 fixed_sql。本次可用表:${authorized_tables}待审核SQL:${text}输出valid即可
4.项目源码
4.1 项目结构

4.2 前端代码
index.html如下:
<!DOCTYPE html><html lang="zh-CN"><head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>AI 问数与智能分析平台</title></head><body> <div id="root"></div> <script type="module" src="/src/main.jsx"></script></body></html>
package.json如下:
{ "name": "ai-chat-frontend","private": true,"version": "1.0.0","type": "module","scripts": { "dev": "vite", "build": "vite build", "preview": "vite preview" },"dependencies": { "echarts": "^5.4.3", "react": "^18.2.0", "react-dom": "^18.2.0", "react-markdown": "^9.0.1", "react-router-dom": "^7.13.1", "remark-gfm": "^4.0.0" },"devDependencies": { "@types/react": "^18.2.43", "@types/react-dom": "^18.2.17", "@vitejs/plugin-react": "^4.2.1", "vite": "^5.0.8" }}
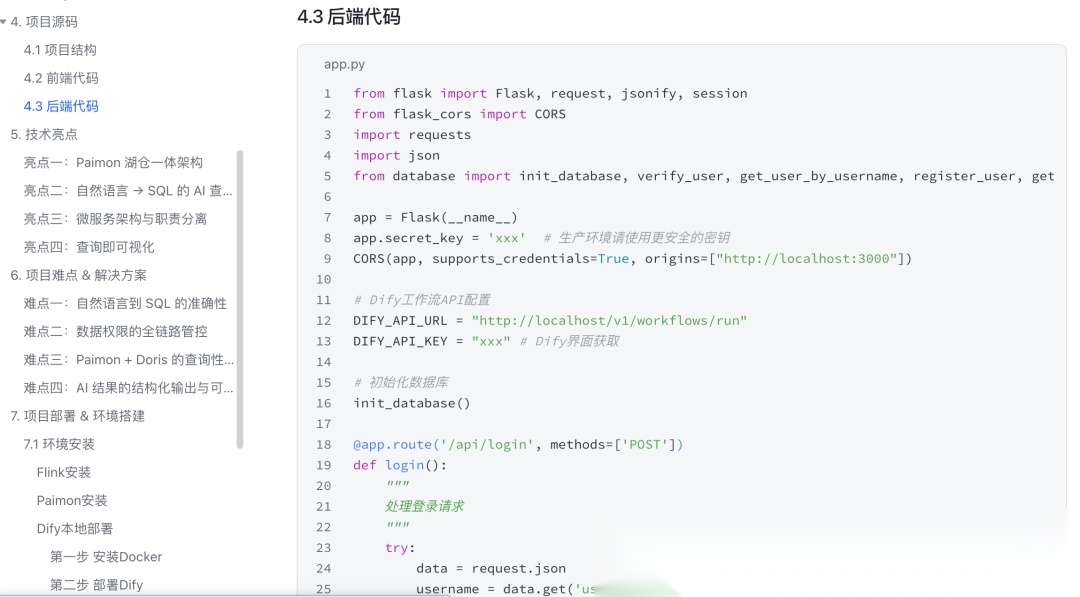
4.3 后端代码
5.技术亮点
亮点一:Paimon 湖仓一体架构
亮点二:自然语言 → SQL 的 AI 查询链路
亮点三:微服务架构与职责分离
亮点四:查询即可视化
6.项目难点 & 解决方案
难点一:自然语言到 SQL 的准确性
问题描述:用户的自然语言表述千变万化(上个月的 GMV 是多少、各渠道的转化率对比),如何确保 LLM 生成正确的 SQL?
为什么难:
- 表名和字段名需要精确匹配
- 聚合逻辑
(SUM/COUNT/AVG)、时间范围需要准确推断 - 不同表之间的关联关系,LLM 可能不清楚
解决方案:
- 通过 Dify 工作流,将 表结构元信息(Schema) 注入 Prompt,让 LLM 了解可用的表和字段
- 用户的
allowed_tables列表作为约束条件传入,限制 SQL 生成范围 - Doris 查询服务增加 只读保护:仅允许
SELECT/SHOW/DESC/EXPLAIN,拒绝一切写操作 - 在 Dify 工作流中增加 SQL 校验节点,对生成的 SQL 进行基础检查
最终效果:针对已建模的 ADS 层数据表,自然语言查询准确率达到90%以上,且通过权限控制杜绝了越权查询和误操作风险。
难点二:数据权限的全链路管控
难点三:Paimon + Doris 的查询性能优化
难点四:AI 结果的结构化输出与可视化
7.项目截图
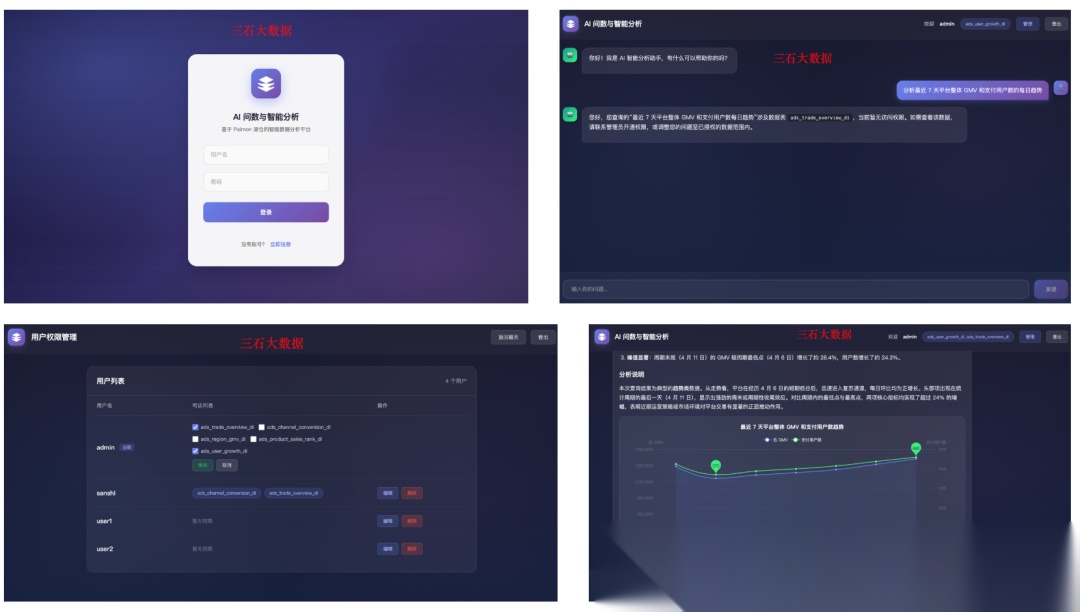
8.写在最后
如果你只是想系统学习一个真正能落地的 AI 企业级实战项目,完整掌握:
- Flink + Paimon 湖仓一体架构(从设计到实现)
- AI 数据查询分析链路(含可运行源码)
- 微服务架构设计 + 权限控制(企业级方案)
- 项目亮点拆解 + 简历表达
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献690条内容
已为社区贡献690条内容

所有评论(0)