▲D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真
本文提出了一种基于Q学习的分布式算法来解决D2D通信中的资源分配与功率控制问题。该算法将每个D2D用户对视为独立智能体,通过与环境交互学习最优策略,无需全局信道状态信息。系统模型包含蜂窝用户和D2D用户共享频谱的场景,定义了信号干扰模型和优化目标(在保证蜂窝用户QoS前提下最大化系统吞吐量)。Q学习框架设计了状态空间、动作空间(联合选择资源块和功率等级)和奖励函数,通过惩罚机制保护蜂窝用户通信质量
目录
📶1.引言
D2D(Device-to-Device)通信允许距离相近的用户设备在蜂窝网络的频谱资源上直接通信,无需经过基站中转,从而有效提升系统吞吐量、频谱效率和能量效率。然而,当D2D链路与蜂窝用户(Cellular User, CU)共享相同的频谱资源时,两者之间会产生严重的层间干扰(Cross-tier Interference)。传统的集中式资源分配方法需要精确的信道状态信息(CSI),在动态环境中开销巨大且难以实时获取。因此,提出一种基于Q学习的分布式联合资源分配与功率控制算法,将每个D2D用户对视为独立的智能体,通过与环境的交互学习,在不需要精确CSI的条件下,自主选择信道和发射功率,在保证蜂窝用户服务质量(QoS)的前提下最大化系统总吞吐量。
🧠2.系统模型
2.1 网络拓扑
考虑单小区下行场景,小区内有一个基站(BS),M个蜂窝用户(CU)和N个D2D用户对。每个蜂窝用户占用一个正交的资源块(Resource Block, RB),D2D用户对可以复用任意一个蜂窝用户的资源块进行通信。设蜂窝用户集合为M={1,2,...,M},D2D用户对集合为N={1,2,...,N}。
2.2 信号与干扰模型
当第n个D2D用户对复用第mm个蜂窝用户的资源块时,蜂窝用户m在基站处的信干噪比(SINR)为:

其中,PB为基站发射功率,gB,m为基站到蜂窝用户m的信道增益,PnD2D为第n个D2D发射端的发射功率,gn,B为第n个D2D发射端到基站的干扰信道增益,Sm为复用资源块m的D2D用户对集合,σ2为高斯白噪声功率。
第n个D2D用户对(复用资源块m)的信干噪比为:
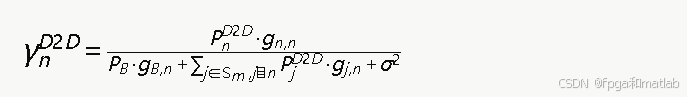
其中,gn,n为D2D对n内部的信道增益,gB,n为基站对D2D接收端n的干扰信道增益,gj,n为其他D2D发射端jj对D2D接收端n的干扰信道增益。
2.3 容量与吞吐量

2.4 优化目标
优化目标是最大化系统总吞吐量,同时保证蜂窝用户的QoS需求:

✅3.基于Q学习的联合资源分配与功率控制算法原理
将每个D2D用户对视为一个独立的Q学习智能体。每个智能体通过观察环境状态,选择动作(包括信道选择和功率等级),获得奖励反馈,逐步更新Q值表,最终学习到最优策略。该框架的核心优势在于:每个D2D用户对仅利用自身的历史状态信息(历史吞吐量和功率值)进行决策,无需获取全局CSI或精确的干扰信息。
3.1 状态空间定义

3.2 动作空间定义
每个智能体的动作为联合选择一个资源块和一个功率等级:
an(t)=(mn(t),ln(t)
动作空间大小为∣A∣=M×K。这意味着智能体在每个决策时刻同时决定复用哪个蜂窝用户的频谱以及使用多大的发射功率。
3.3 奖励函数设计
奖励函数是Q学习算法的关键,需要同时反映D2D吞吐量最大化目标和蜂窝用户QoS保护约束。第n个D2D智能体在时隙tt执行动作an(t)an(t)后获得的奖励定义为:
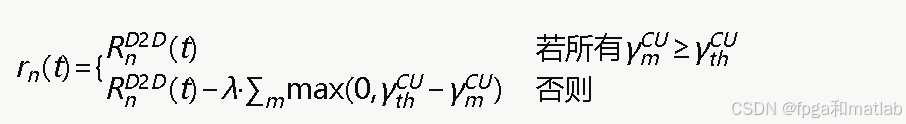
其中λ>0惩罚因子,当D2D通信导致蜂窝用户SINR低于门限时,给予负向惩罚。
3.4 Q值更新规则
每个D2D智能体n维护一个Q值表Qn(s,a),在每个时隙根据以下规则更新:
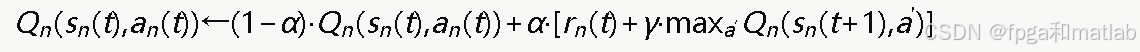
其中α∈(0,1]为学习率,控制新经验对Q值的影响程度;γ∈[0,1)为折扣因子,衡量未来奖励的重要性。学习率过大会导致收敛不稳定,过小则学习速度缓慢;折扣因子越接近1,智能体越重视长期累计回报。
📚4.MATLAB程序
% 网络参数
cellRadius = 500; % 小区半径(m)
numCU = 4; % 蜂窝用户数(即资源块数M)
numD2D = 6; % D2D用户对数N
d2dMaxDist = 50; % D2D对内最大距离(m)
bandwidth = 180e3; % 每个RB带宽(Hz)
noisePower_dBm = -114; % 噪声功率(dBm)
noisePower = 10^(noisePower_dBm/10) * 1e-3; % 转换为W
% 功率参数
P_BS_dBm = 46; % 基站发射功率(dBm)
P_BS = 10^(P_BS_dBm/10) * 1e-3; % W
P_D2D_max_dBm = 20; % D2D最大发射功率(dBm)
P_D2D_max = 10^(P_D2D_max_dBm/10) * 1e-3; % W
numPowerLevels = 5; % 功率离散等级数K
powerLevels = linspace(P_D2D_max/numPowerLevels, P_D2D_max, numPowerLevels);
% QoS参数
SINR_th_dB = 5; % 蜂窝用户最低SINR门限(dB)
SINR_th = 10^(SINR_th_dB/10);
penaltyFactor = 5; % 惩罚因子(Mbps)
% 路径损耗参数
pathLossExp_CU = 3.5; % 蜂窝链路路径损耗指数
pathLossExp_D2D = 3.0; % D2D链路路径损耗指数
refLoss_dB = 30; % 参考距离1m处路径损耗(dB)
%% ===================== Q学习参数 =====================
numEpisodes = 2000; % 训练回合数
stepsPerEpisode = 200; % 每回合步数
alpha = 0.3; % 学习率
gammaQ = 0.9; % 折扣因子
epsilon_init = 1.0; % 初始探索率
epsilon_min = 0.01; % 最小探索率
epsilon_decay = 0.997; % 探索率衰减因子
% 状态空间: (资源块, 功率等级) -> M*K个状态
numStates = numCU * numPowerLevels;
% 动作空间: (资源块, 功率等级) -> M*K个动作
numActions = numCU * numPowerLevels;
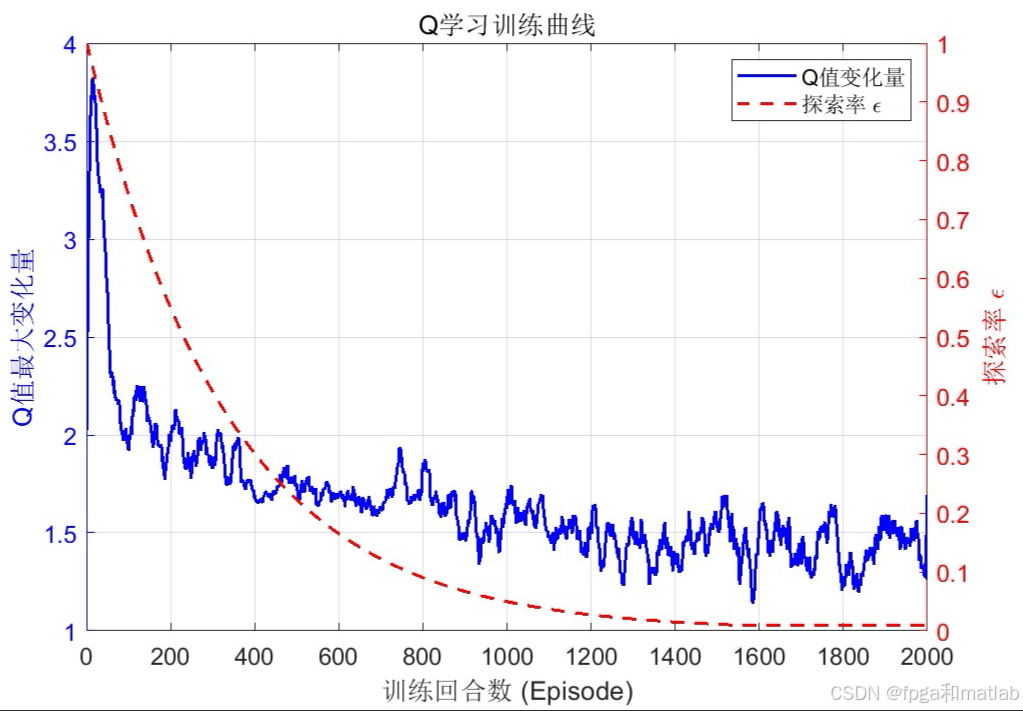
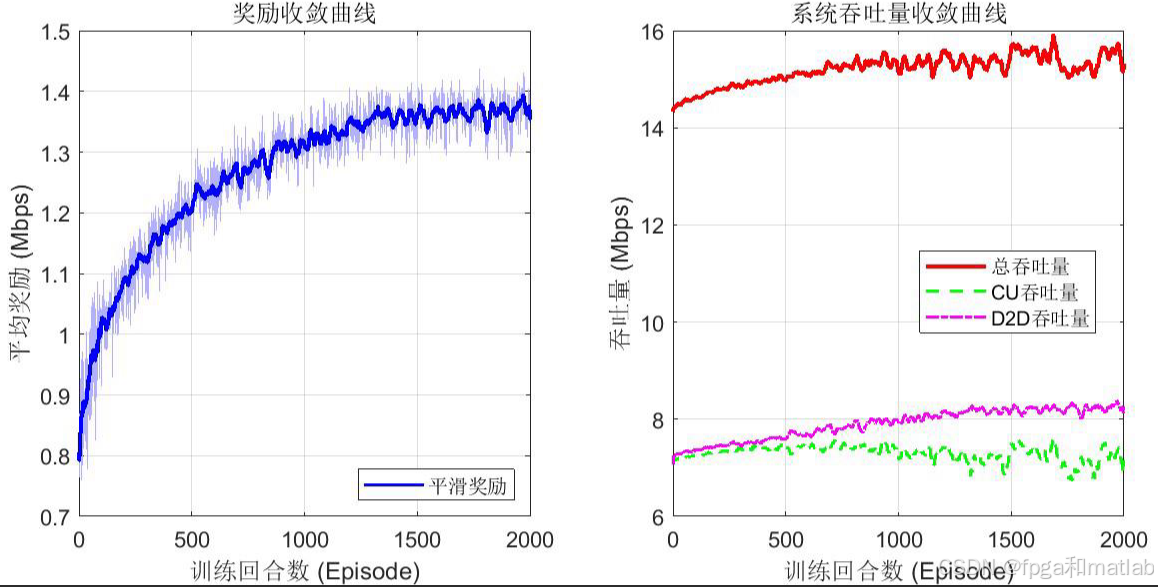
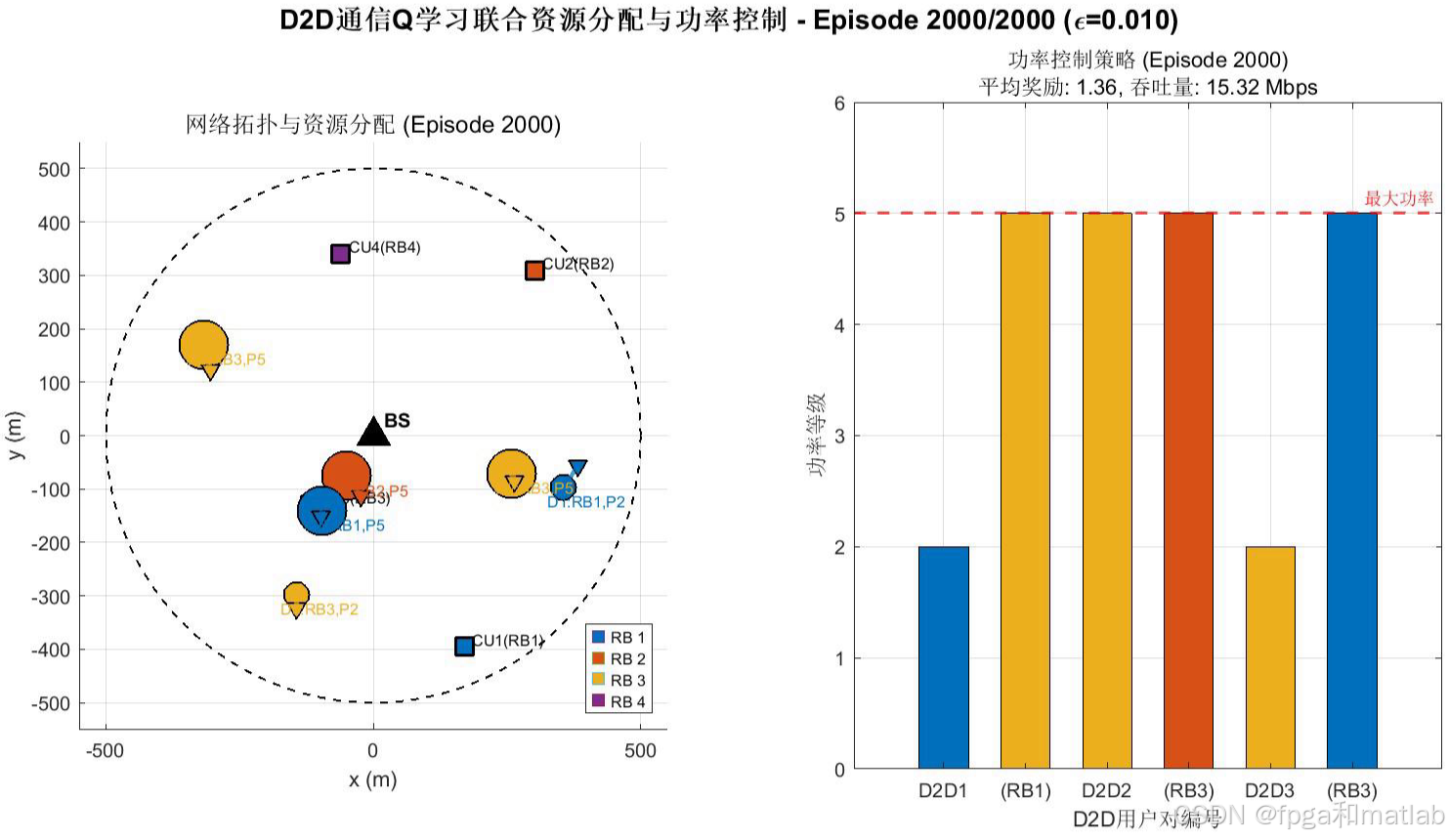
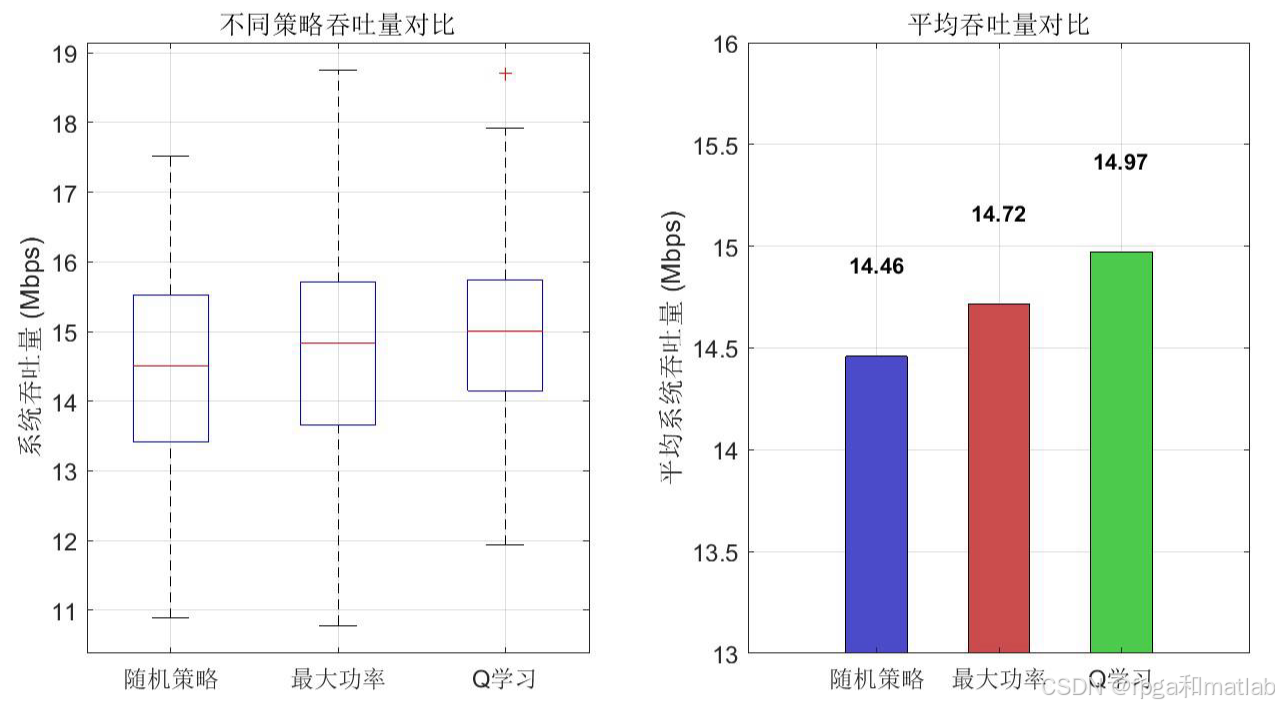
📊5.仿真结果分析
✨6.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真【包括程序,中文注释,程序操作和讲解视频】资源-CSDN下载

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)