第三章 LangChain进阶组件实操(4.18学习笔记)
它是最“聪明”但也最花钱的记忆方式。它不是直接存对话,而是每隔几轮就让大模型对之前的对话进行一次总结(Summary)。下次对话时,只发送这个简短的总结。超长周期的复杂项目调研、需要跨越几百轮对话保持核心逻辑连贯的场景。能够以极小的篇幅保留核心信息。为了生成摘要,需要额外调用一次大模型,会产生额外的 API 费用和响应延迟。特性全量记忆 (Full)窗口记忆 (Window)摘要记忆 (Summa
三种基础Memory组件实操
一、 核心架构认知:从传统组件到 LCEL 时代
在 LangChain 的新标准中,官方不再推荐使用早期的 ConversationChain,而是全面转向 LCEL(LangChain Expression Language) 架构。
1. 为什么要用 LCEL 架构?
传统的记忆组件(如单独的 ConversationBufferMemory 对象)往往难以处理多用户并发和会话隔离。LCEL 架构通过 RunnableWithMessageHistory 提供了一套标准化的流水线:
-
解耦: 逻辑归逻辑(如何处理数据),存储归存储(数据存在哪)。
-
自动注入: 你只需要定义好
session_id,框架会自动根据 ID 找回记忆,并把它精准地塞进 Prompt 的对应位置。
2. 理解 session_id(会话隔离)
在实际的科研助手应用中,你可能同时在处理“论文 A 的润色”和“论文 B 的数据分析”。session_id 就像是微信的聊天窗口 ID:
-
session_id="paper_A":只包含论文 A 的讨论记录。 -
session_id="paper_B":记录完全独立,互不干扰。 这保证了多任务并行时,大模型的逻辑不会发生串线。
二、 三大基础记忆组件详述
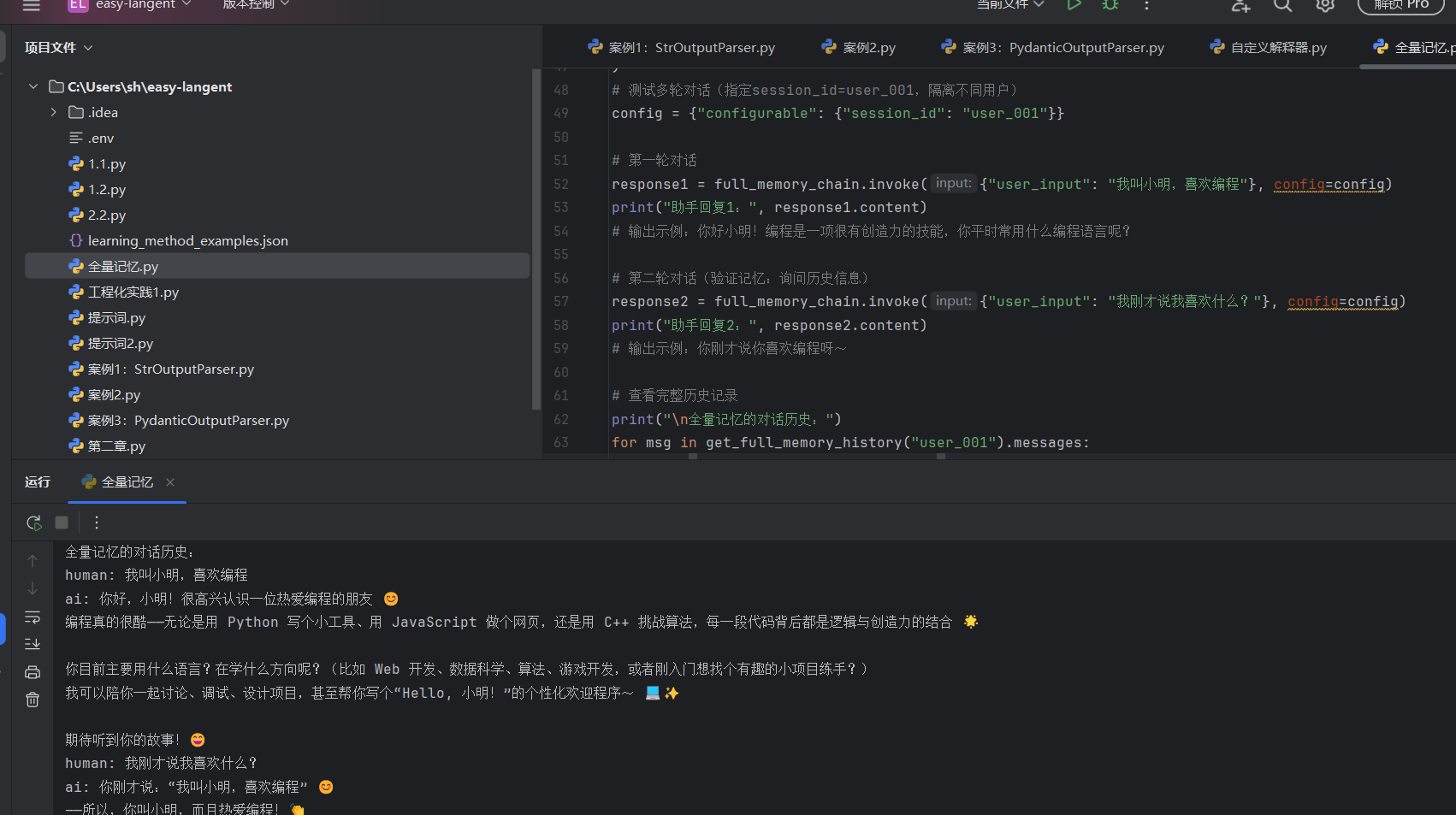
1. 全量记忆 (ConversationBufferMemory)
-
工作逻辑: 它是最直观的“复印机”。每产生一轮对话,就原封不动地把文本存入列表。下次对话时,把这个列表全部发给模型。
-
适用场景: 短对话、极其重视上下文细节的精确任务(如法律条文咨询、代码逻辑纠错)。
-
隐患: 随着对话轮数增加,Token 消耗会指数级增长,最终可能撑破模型的上下文窗口(Context Window)导致报错。
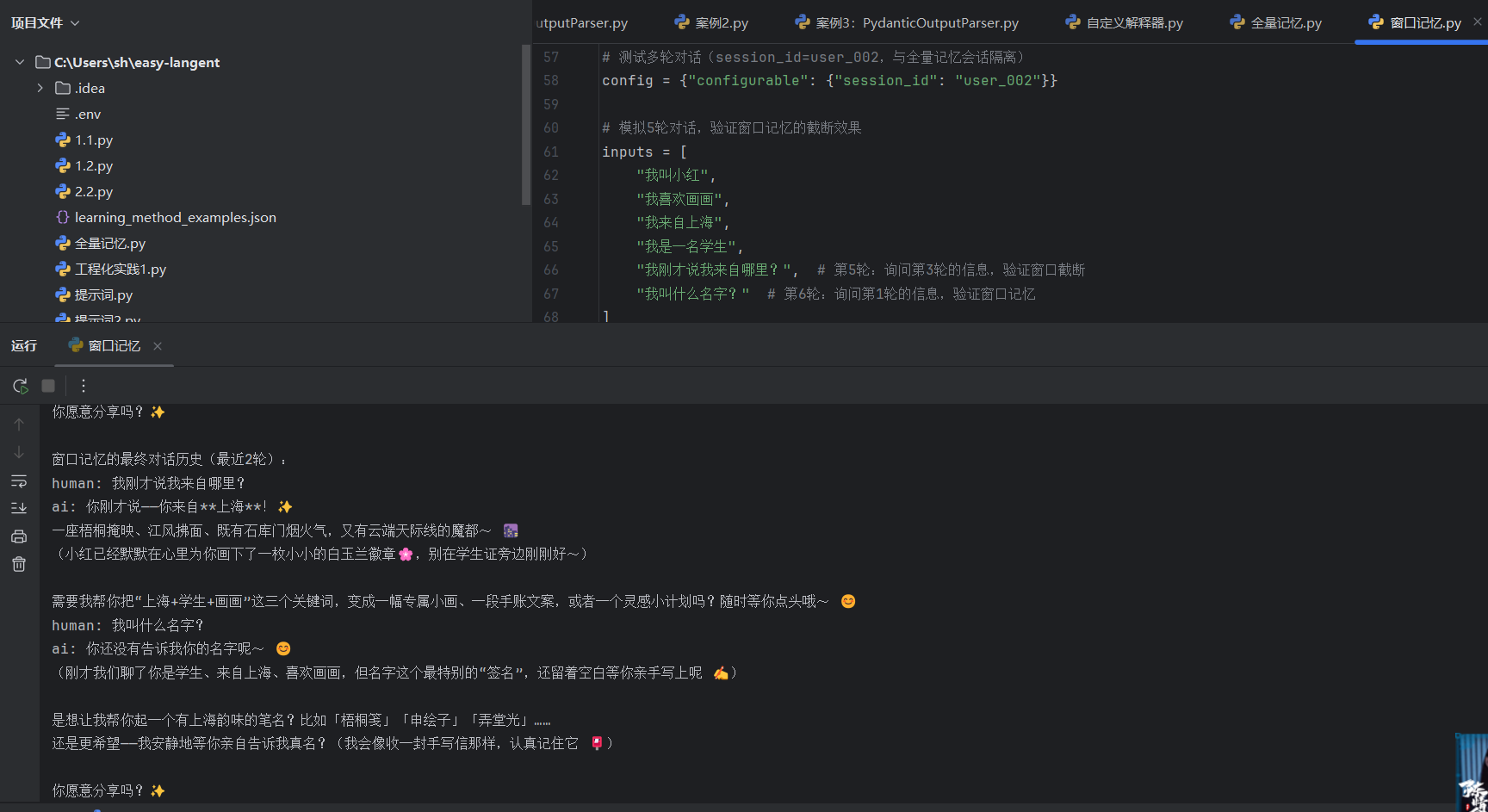
2. 窗口记忆 (ConversationBufferWindowMemory)
-
工作逻辑: 它是一个“有容量限制的滑块”。你可以设置
k=5,意味着它只记得最近的 5 轮对话。一旦有了第 6 轮,最早的那一轮就会被彻底“遗忘”。 -
适用场景: 长时间的日常咨询、对早期对话依赖不强的任务。
-
优势: 极大地稳定了 Token 消耗,保护了预算,防止程序崩溃。
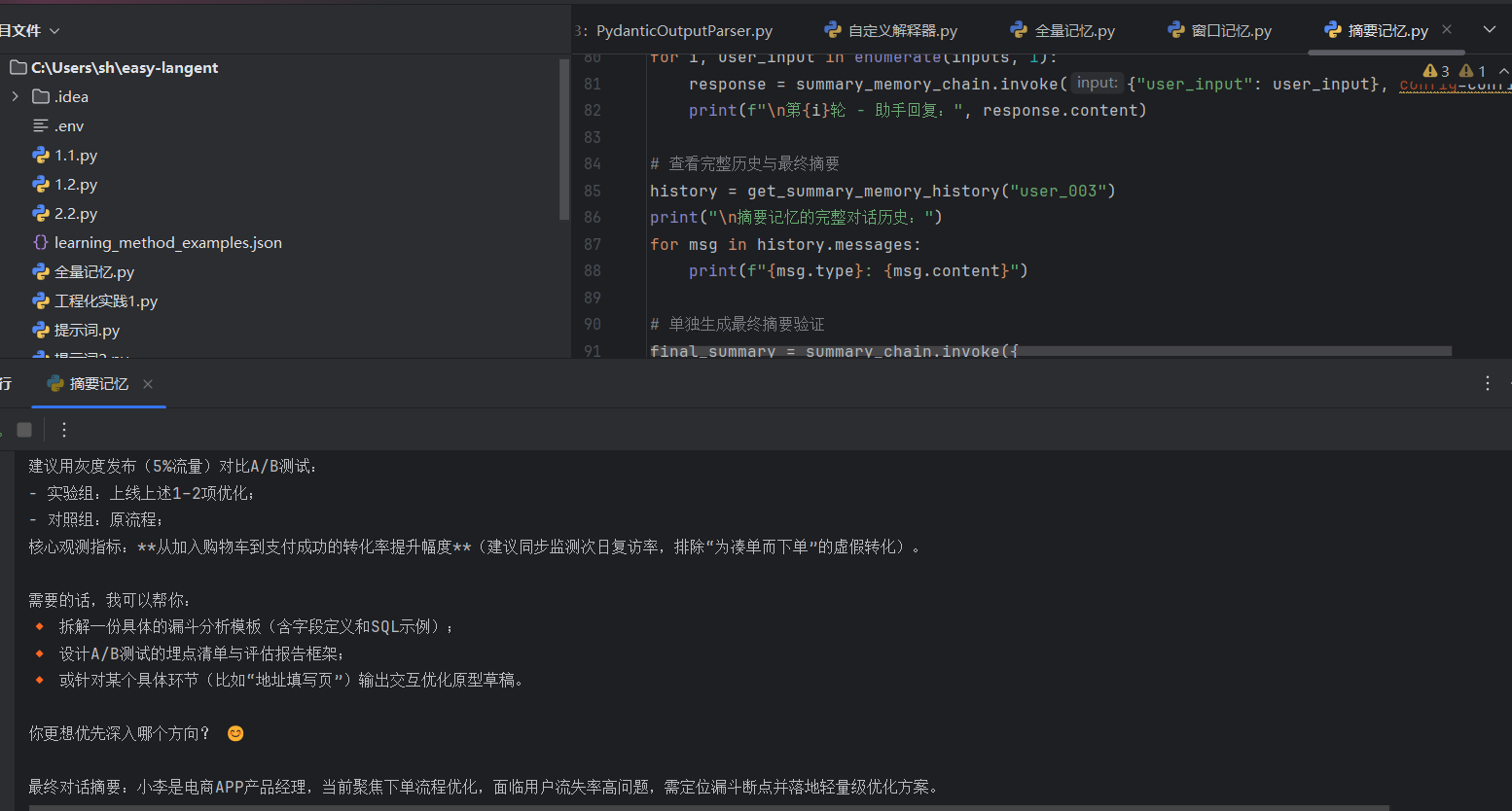
3. 摘要记忆 (ConversationSummaryMemory)
-
工作逻辑: 它是最“聪明”但也最花钱的记忆方式。它不是直接存对话,而是每隔几轮就让大模型对之前的对话进行一次总结(Summary)。下次对话时,只发送这个简短的总结。
-
适用场景: 超长周期的复杂项目调研、需要跨越几百轮对话保持核心逻辑连贯的场景。
-
优势: 能够以极小的篇幅保留核心信息。
-
代价: 为了生成摘要,需要额外调用一次大模型,会产生额外的 API 费用和响应延迟。
| 特性 | 全量记忆 (Full) | 窗口记忆 (Window) | 摘要记忆 (Summary) |
| 存储内容 | 所有的原始对话文本 | 最近 K 轮的原始对话文本 | 对话历史的精简综述 |
| Token 消耗 | 极高(随对话线性增长) | 恒定(取决于 K 值大小) | 较低且平稳 |
| 信息准确度 | 100%(不丢失细节) | 近期准确,远期为零 | 逻辑连贯,但会丢失技术细节 |
| 计算开销 | 无额外调用 | 无额外调用 | 高(需额外调用 LLM 生成摘要) |
| 推荐科研场景 | 单篇论文的深度纠错 | 连续的学术搜索与问答 | 跨季度的课题研究规划 |
实操:
全量记忆
窗口记忆
窗口记忆
工程:
存储优化:
在之前的实操中,使用了 InMemoryChatMessageHistory。这是一种极其脆弱的存储方式,它的本质是在电脑内存(RAM)里建了一个字典。这意味着,只要 PyCharm 一关,或者服务器稍微闪退重启,所有用户的对话历史将瞬间灰飞烟灭。
在真正的工业级系统中,我们必须引入持久化数据库来接管这些记忆。对于高频的对话系统,行业内最主流的选择是 Redis。因为它同样基于内存读写,速度极快,不会让大模型因为等待读取历史记录而产生延迟,同时它支持将数据落盘保存。如果需要对历史对话进行长期的数据挖掘和合规审计,则会同步持久化到 PostgreSQL 或 MongoDB 这样的关系型/文档型数据库中。
LangChain 极其优秀的解耦设计在这里体现得淋漓尽致。你不需要去修改那些复杂的 LCEL 链式代码,只需要自己写一个类继承 BaseChatMessageHistory,在里面重写 add_message(存入数据库)和 messages(从数据库读取)这两个方法。完成替换后,外层的对话系统甚至毫无察觉,但底层已经完成了从单机到分布式的蜕变。
性能优化:
记忆组件如果管理不当,会迅速成为消耗时间和金钱的“黑洞”。
以摘要记忆为例,如果用户每一句话,系统都在后台立刻唤醒一次大模型去重新生成完整摘要,这不仅会带来几秒钟的额外延迟,还会让 API 账单直接翻倍。工程上的最优解是引入“节流阀”机制,比如设置一个缓冲池,积累满 5 轮对话后,再在后台静默触发一次摘要更新,期间直接读取上一次缓存的结果。
对于窗口记忆,只限制“保留最近 N 轮对话”其实存在巨大的隐患。假设设置了保留最近两轮,但用户在上一轮直接粘贴了一份长达 50 页的技术文档,这一轮的 Token 数量依然会瞬间撑爆大模型的上下文上限,导致程序崩溃。因此,严谨的工程实践会引入类似 tiktoken 这样的分词工具。在每次将历史记录发送给模型之前,先在本地精算确切的 Token 长度,一旦逼近红线,系统会动态地切断更早的语句,实现基于真实 Token 容量的绝对安全控制。
多模型适配:平衡成本与隐私的利器
商业化的大模型(如 GPT-4、千问-Max)虽然极其聪明,但它们通常按交互的 Token 数量计费。当系统面临海量并发访问时,每一轮带着长长记忆的对话都是真金白银的燃烧。
此外,在处理某些涉密的企业内部文档或供应链数据时,将原文发送给云端商业 API 存在不可接受的数据泄露风险。通过 LangChain 统一的调用接口,我们可以在业务代码一行不改的前提下,随时将底层模型切换为部署在企业本地局域网内的开源模型(如 Llama 3 或 Qwen 的开源版本)。这种“随意插拔”的能力,让系统可以在日常闲聊或低密级任务中使用低成本的开源模型,而在遇到复杂推理任务时,再动态路由给昂贵的云端大模型,实现成本与安全的最优解。
错误处理:
大模型本质上是一个极度依赖网络的外部服务,网络抖动、服务器宕机或并发限流是家常便饭。如果不对这些异常进行兜底,用户的体验将是灾难性的。
一个健壮的系统会在调用大模型的节点周围包裹一层异常重试逻辑(例如遇到网络超时自动等两秒再试,最多试三次)。同时,长年累月的对话会产生海量的废弃会话。工程上通常会为 Redis 中的 session_id 设置一个 TTL(存活时间,如 7 天)。如果用户 7 天没有再来对话,系统会自动清理这些历史记忆,防止服务器硬盘被撑爆。
记忆是怎么注入到对话里的?
手搓:
外部行动层(Tool):
工具调用的核心逻辑:“思考→行动→反馈”循环:ReAct (Reason + Act) 范式
三个关键组件:
| 核心组件 | 英文术语 | 形象比喻 | 核心定义与功能 | 决定成败的关键工程要素 | 典型案例 |
| 工具 | Tool |
“手脚”与“专有设备” (如:单把螺丝刀) |
最小的执行单元。大模型通过它来突破原本的“结界”,去执行特定的、原子化的现实世界任务(如获取实时数据、操作本地文件)。 |
名称 (Name) 与 描述 (Description): 大模型看不懂底层代码,完全依赖你写的工具描述来决定是否调用。描述写得越精准(本质是 Prompt),大模型的调用准确率就越高。 |
|
| 工具包 | Toolkit |
“瑞士军刀”与“专业工具箱” (如:电工专用工具箱) |
特定场景下工具的集合。将功能高度相关的多个原子工具打包在一起,方便开发者一次性挂载到系统上。 |
场景的高内聚性: 避免一次性给大模型塞入上百个毫无关联的零散工具(会导致 Token 浪费和注意力分散)。按专业领域打包能大幅提升运行效率。 |
文件操作包 (含读、写、列目录) 供应商审核包 (含营业执照识别、黑名单查询) |
| 智能体 | Agent |
“指挥官”与“项目经理” (如:拿着对讲机调度的大脑) |
控制中枢与循环引擎。基于 ReAct(思考-行动-反馈)范式,负责自主决策:是否需要调用工具?调用哪个?参数怎么填?如何处理工具返回的报错并重试? |
底层大模型的推理能力 (Reasoning): Agent 本身是一套动态的 |
接收用户模糊需求后,自主决定先调搜索工具,再调总结工具,最后输出成篇报告的 学术调研 Agent。 |
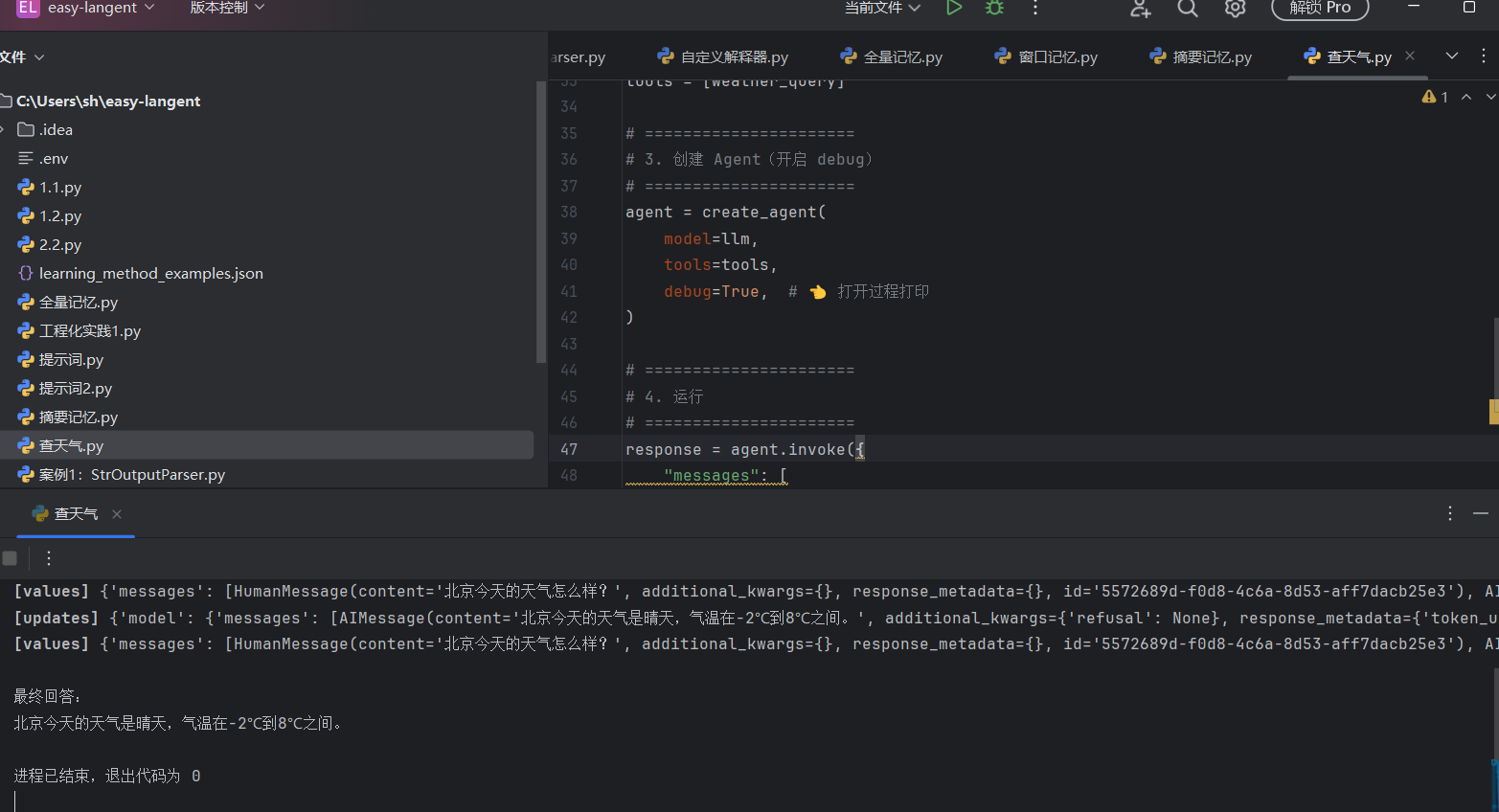
学习案例:查天气
自定义工具(@tool装饰器):
| 对比维度 | 传统的 Python 函数 | Agent 专属工具函数 (@tool) | 带来的底层工程影响 |
| 定义形态 | def check_weather(city): |
|
挂载了 @tool 后,函数被自动封装成了 LangChain 的 BaseTool 类,具备了被 Agent 调度的接口。 |
| 注释 (Docstring) |
可有可无,甚至可以写废话。 如: |
必须极度清晰严谨。 如: |
决定了 Agent 的规划能力 (Reasoning)。写得好,AI 就聪明;写得差,AI 就如同梦游,乱调工具。 |
| 类型声明 | 动态类型,不声明也能跑。 | 强制类型注解 (str, int, list 等)。 |
触发底层 Pydantic 的强类型校验,强制大模型按标准格式输出参数,防止代码执行崩溃。 |
| 返回值设计 | 返回一切原始数据对象(如庞大的 requests response 对象)。 | 返回经过清洗的纯文本或结构化简明数据。 | 保护大模型的上下文窗口 (Context Window),降低 Token 消耗,提高反馈后的总结准确率。 |
案例:温度单位转换
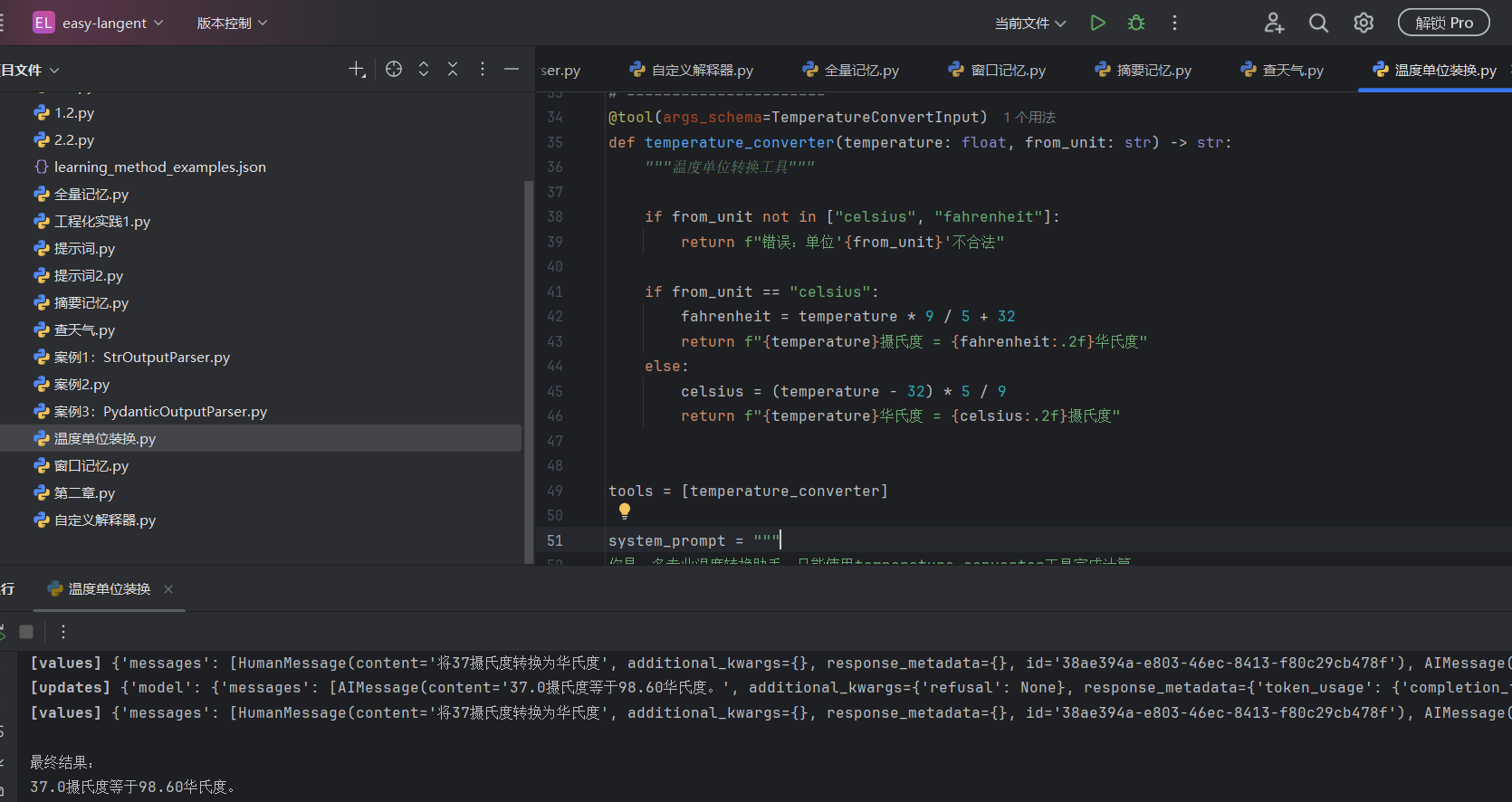
@tool工具的源码 介绍:
| 参数名 (Parameter) | 默认值 | 核心功能与运行机制 | 💡 工程实践与适用场景 |
|
(工具描述) |
None |
Agent 的“调用指南”。明确告诉大模型这个工具是干嘛的、什么时候该用。如果不传,系统会尝试猜(从函数名或 docstring 里提取)。 | 强烈建议手动编写或写好 docstring。特别是当函数名不足以解释复杂业务时,必须在这里写明。 |
|
(直接返回) |
False |
控制数据流向。 • • |
数据导出 / 绘图 / 核心机密场景。比如工具是生成一张 Excel 表,选 True 直接返回文件链接,防止 LLM 把表格读出来说一堆废话。 |
|
(参数强校验) |
None |
参数的“安检机”。允许你传入一个 Pydantic 类,强制定义参数的取值范围、长度限制或枚举值。 | 生产环境高危操作。比如操作数据库的工具,必须用它限制传入的 user_id 必须是 10 位数字,防止 AI 瞎传参数删库。 |
|
(自动推导) |
True |
快捷安检。自动扫描你写的 Python 代码(如 city: str),并把它转成给 AI 看的格式要求(JSON Schema)。 |
默认开启即可。这是 LangChain 最贴心的功能,让你不用每次都手动写冗长的 args_schema。 |
|
(解析注释) |
False |
提取说明书。开启后,框架会把你写在函数里的多行注释 """...""" 拆解开,自动提取出工具的描述和每个参数的具体含义。 |
大型项目团队协作。开启它,强制要求开发者写出规范的 Python docstring,一处编写,代码阅读和 AI 调用双收益。 |
|
(注释报错) |
True |
注释质检员。配合上一个参数使用,如果你开启了提取注释,但注释写得乱七八糟(格式不合规),程序会直接罢工报错。 | 严谨的工程环境。保持开启,强迫自己和团队写出符合标准规范的代码注释。 |
|
(返回格式) |
"content" |
携带附加信息。 • • |
性能监控 / 复杂调试。当你需要记录工具调用的日志、排查延迟,或者在界面上展示“本次查询耗时 0.5 秒”时使用。 |
其他常用内置工具:
| 工具名称 | 对应的内置组件 | 核心功能与机制 | ⚠️ 核心工程风险与安全建议 | 典型应用场景 |
| 读取文件 | ReadFileTool |
赋予 AI “视觉”。 读取指定路径的文本文件(如 .txt, .py, .md),并将内容以纯文本形式返回给大模型。 |
风险:Token 爆炸。 如果 AI 试图读取一个 500MB 的系统日志文件,程序会瞬间崩溃或大量扣费。 建议: 在实例化时严格限制文件大小,或配合文档切分(Text Splitter)使用。 |
让 AI 阅读某篇特定的学术论文草稿、读取本地配置文件、代码 Review。 |
| 写入文件 | WriteFileTool |
赋予 AI “执笔权”。 将大模型生成的内容(如总结报告、代码)自动保存到本地指定的路径中。 |
风险:覆盖与幻觉。 大模型可能会编造一个错误的文件路径,或者不小心覆盖掉你原本重要的同名代码文件。 建议: 必须在底层代码死死锁住工作目录(如限定只能写在 |
自动化生成并保存调研报告、让 AI 把修改好的代码直接覆盖写入源文件。 |
| 查看目录 | ListDirectoryTool |
赋予 AI “寻路能力”。 列出指定文件夹下的所有文件和子文件夹名称。这是 AI 了解当前环境的前置动作。 |
风险:系统路径泄露。 如果不加限制,AI 可能会顺藤摸瓜去遍历你的系统盘(如 建议: 设定沙盒机制,强制锁定 |
当用户问“帮我总结一下资料夹里的所有文档”时,AI 需先调用此工具获取文档列表。 |
| 删除文件 | DeleteFileTool |
赋予 AI “销毁权”。 永久删除本地的特定文件。 |
风险:极其危险的灾难性操作。 大模型如果发生逻辑混乱,可能会把你的项目源码甚至系统文件删掉。 建议: 在生产环境中强烈不建议直接开放给 Agent 自主决定。若必须使用,必须接入“人类确认机制(Human-in-the-loop)”,弹窗让用户点击确认后才真正执行删除。 |
清理数据处理过程产生的临时冗余文件、清空旧的日志缓存。 |
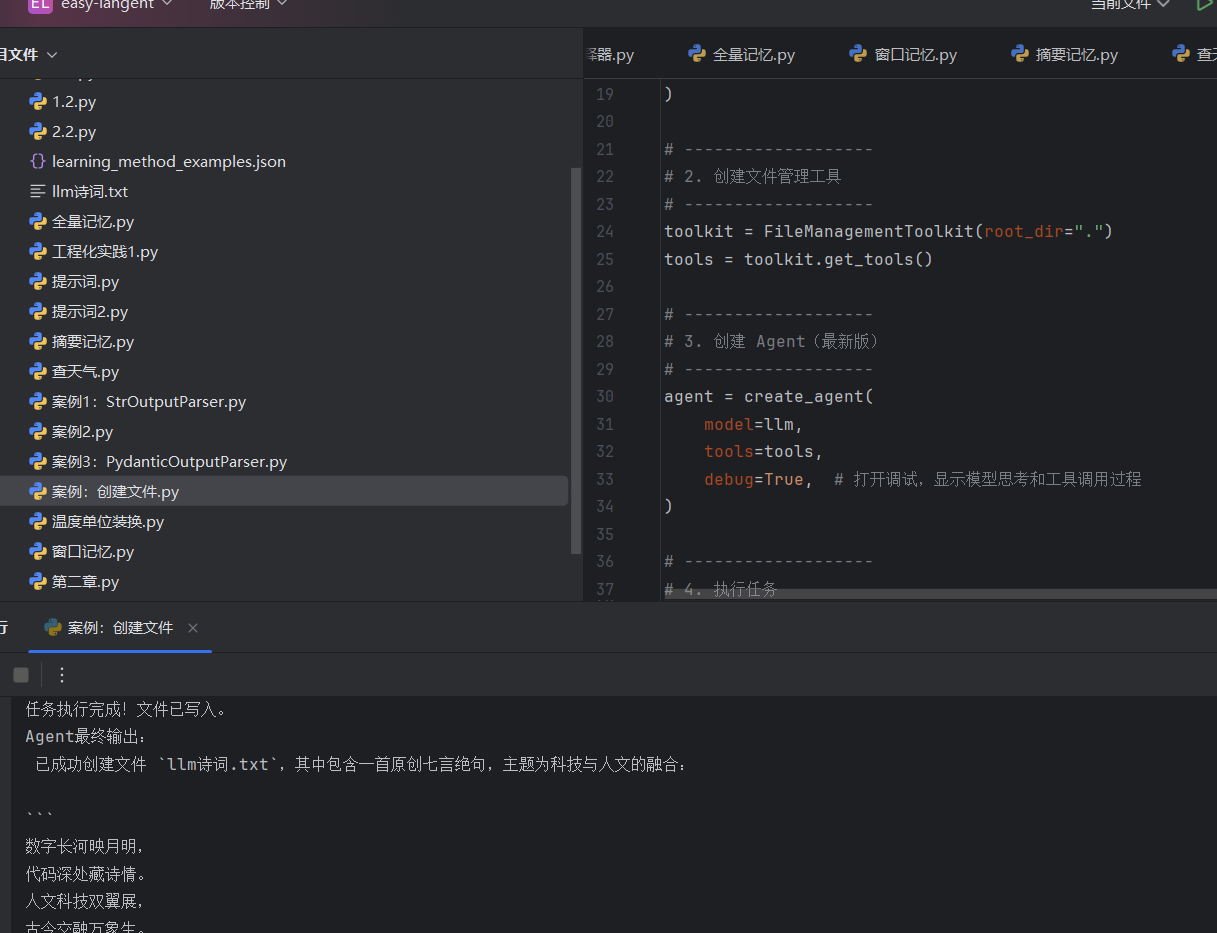
案例:创建文件:
把Memory和Tool组合起来:
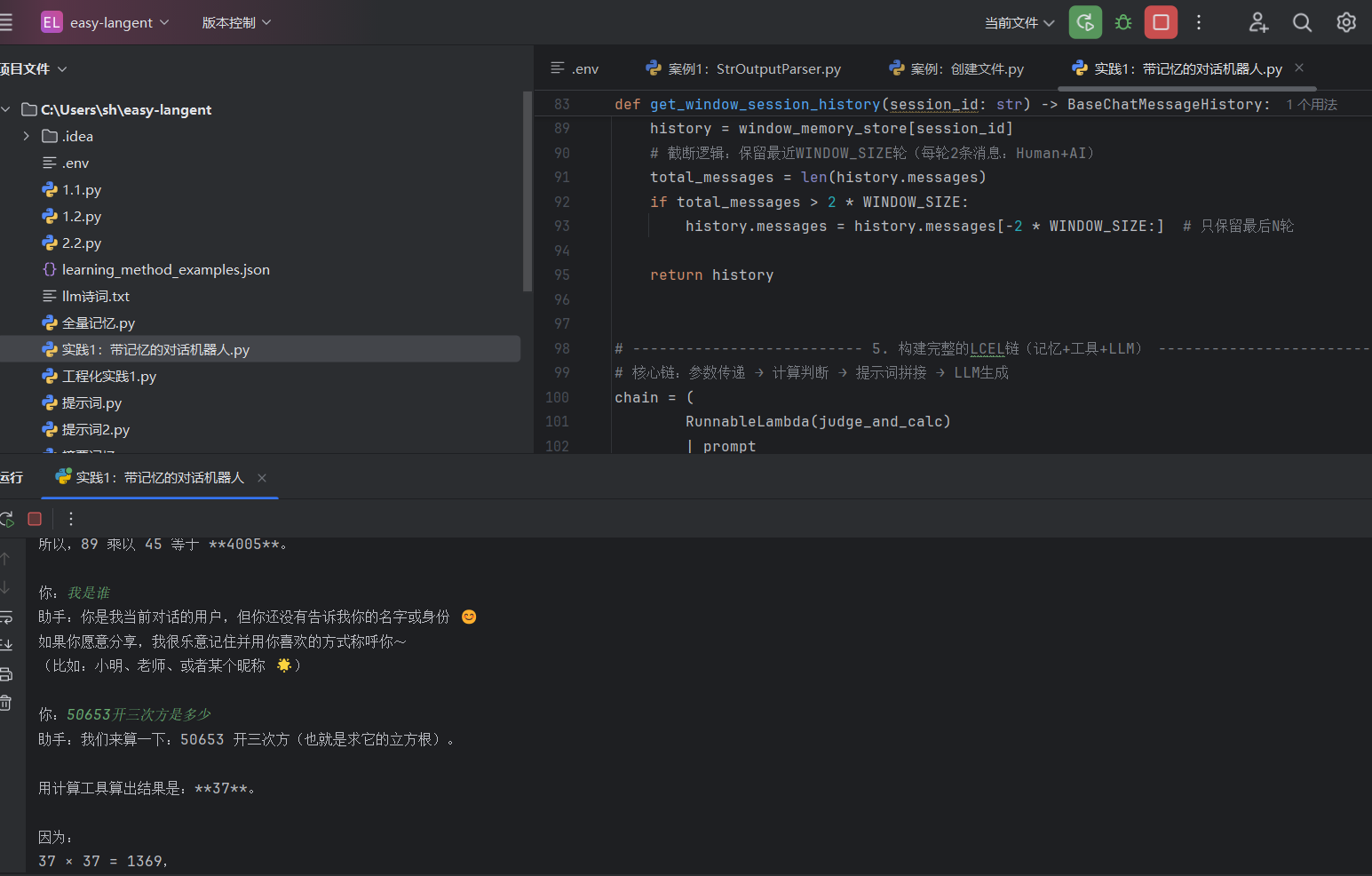
实践1:带记忆的对话机器人:
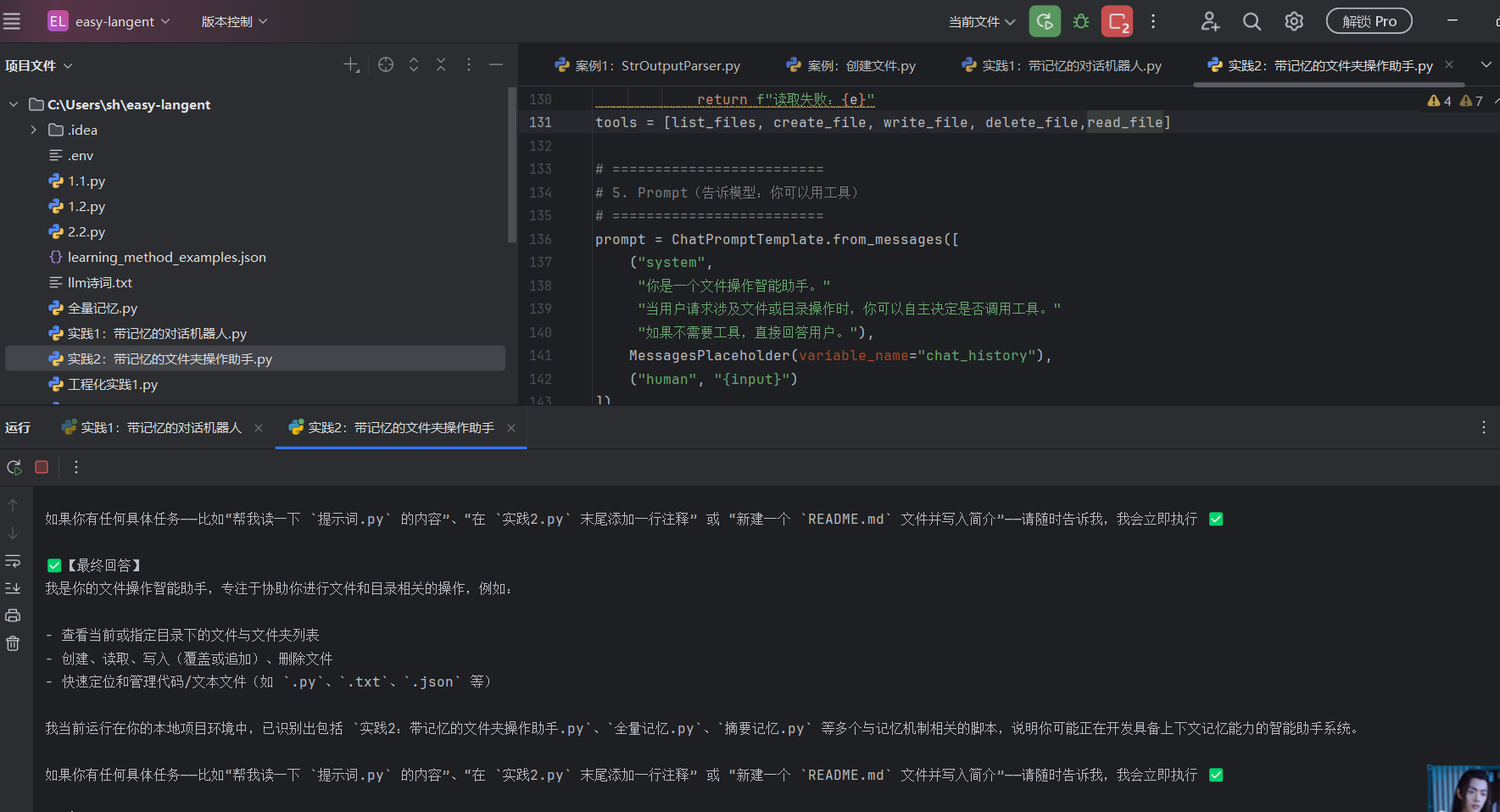
实践2:带记忆的文件夹操作助手:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)