LLM到Agent&RAG——AI概念概述 第一章:大模型
认识大模型
什么是大模型
从硬性规则到模型自己“学习”
传统业务当中,我们通过if-else将所有规则硬性写好,所有情况、出发的回答都是固定的。
很容易就能写出一个简单的客服回复:
if (question.contains("退货")) {
return "请在订单详情页点击申请退货";
} else if (question.contains("发货")) {
return "下单后 48 小时内发货";
} else {
return "请联系人工客服";
}缺陷显而易见:
用户的表达千变万化。我想退货、东西不喜欢、东西不想要了、买错了能退吗、这个怎么退货啊——实际上这些都是同样一件事情,但是我们的if-else只能匹配包含一定关键字的那些,想要包含所有的情况,规则会很长,这是很不实际的。
应对这种情况出现的NLP(自然语言处理)计数,例如关键字匹配等。这些方法比if-else聪明些,能够执行一定层面的文本分析,但是还是不能真正理解语句的含义。
用户说“我不喜欢这个东西”,潜台词是我想要退货,但是机器客服可能匹配到的是商品推荐而不是退货。
LLM——大语言模型出现改变了这个局面。
LLM的训练方式可以简单理解为:让机器浏览海量文本数据(书籍、网页、代码、论坛、百科),从中学习语言规律、知识。靠自己的阅读足够文本、知识之后,对语言有理解,知道文本如何编写。
通过训练之后,大模型能够理解“我不喜欢这件商品”的意思是我想要退货,是因为在训练数据当中见到了类似表达,直到这句话在客服场景下就是代表着退货的意思。
大模型大在哪里
大模型不仅仅是训练的量大,模型的参数量也大
参数单位:B——Billion 十亿的缩写。
参数是什么:
可以理解为模型大脑当中的连接数。人类大脑当中由约100万亿突触连接构成,这些连接存储了我们的记忆、知识、思维能力。大模型的参数类似,每个参数都是数字,所有参数组合在一起构成了模型对语言的理解能力。
参数越多,模型能记住的知识就越多,能处理的语言现象就越复杂,回答的质量就越高,代价也很明显——更多的计算资源(显存、算力)运行。
常见的误区:“参数越大越好”
实际上,对于很多应用场景(RAG系统当中的问答),14B/32B模型就够用了。参数量大的模型能力强,但是推理能力更慢、成本更高(例如Qwen-Flash和Qwen-Max-Thinking的区别,自己使用两个模型问相同的问题就能感受出来)
LLM核心概念
Token:大模型计量单位
大模型处理文本并不完全是按照字、词或者句的量来进行计算的,而是按照Token。
Token——模型内部最小处理单元。可以理解为模型将文本切碎后的小片段。不同语言对应的切法也不同。
-
英文:大致 1 个单词 ≈ 1~1.5 个 Token。比如 "hello" 是 1 个 Token,"unbelievable" 可能被切成 "un" + "believ" + "able" 共 3 个 Token
-
中文:大致 1 个汉字 ≈ 1~2 个 Token。比如“你好”可能是 2 个 Token,“人工智能”可能是 2~3 个 Token
为什么需要知道这个?
-
api使用按照Token计费。发给模型的文本(输入)和模型返回的文本(输出)都会消耗Token,Token用的越多,花的钱越多
-
上下文窗口按照Token计算的。能够给予模型的信息量基于Token数量而不是字数。
上下文窗口Context Window
上下文窗口是模型一次对话中能够看到的文本总量上限,单位是Token
打个比方:和一个人聊天,这个人的记忆力有限,只能记住最近说过的N句话。对话超过了N句他就会忘记最早的几句话。大模型上下文窗口就是这个N,单位从句子变成了Token。
上下文窗口包含了发给模型的所有内容(提示词、历史对话、当前问题)和模型的回答。总量超过窗口大小就会导致最早内容被截断,模型就“看不到”了。
这个概念在RAG当中非常重要。我们都可能想过:既然大模型这么聪明,我们直接把整个项目都喂给大模型进行分析,让他自己分析改进不就行了?问题是:一个项目有着数万行的代码(再加上注释、日志、yaml配置文件、前端模板等),导致大小远远超过大多数模型上下文窗口。就算窗口足够大,太多内容给予模型分析也会导致模型迷失在海量的信息当中,找不到重点,甚至频频出错。这就是为什么RAG系统需要先检索出最相关的片段,之把这些关键信息提供给模型——不超出窗口限制又让模型聚焦在关键信息上。
Temperature:控制回答的创造力
Temperature(温度)是调用大模型时一个重要参数,用于控制回答的随机性。
-
Temperature = 0:模型每次都会选择概率最高的那个词,回答最确定、最稳定,但可能比较死板
-
Temperature = 0.7:模型会在高概率的词里随机选择,回答更自然、更有变化
-
Temperature = 1.0 或更高:模型的选择更加随机,回答更有创意,但也更容易胡说八道
用考试来类比:Temperature = 0 就像一个学霸,每道题都写标准答案,稳定但没有惊喜;Temperature = 1.0 就像一个有创意的学生,有时候能写出精彩的答案,有时候也会跑偏。
MoE混合专家架构
后面模型对比表当中,会频繁看到MoE这个词,例如“671B(37B激活,MoE)”。简单解释它是什么:
MoE全称Mixture of Experts(混合专家),是一种模型架构设计。传统大模型(Dense Model稠密模型)在处理每个输入的时候,所有参数都会参与计算。而MoE模型内部被拆分为多个专家子网略,每次推理只激活其中一部分专家处理当前输入,其余专家不参与计算。
EX:
DeepSeek-V3总参数量是671B,但是每次推理只激活37B参数。意味着其拥有671B参数量级的知识容量,实际推理的时候计算开销相当于一个37B模型。
MoE好处很直观:通过更低计算成本获得更加强的模型能力。
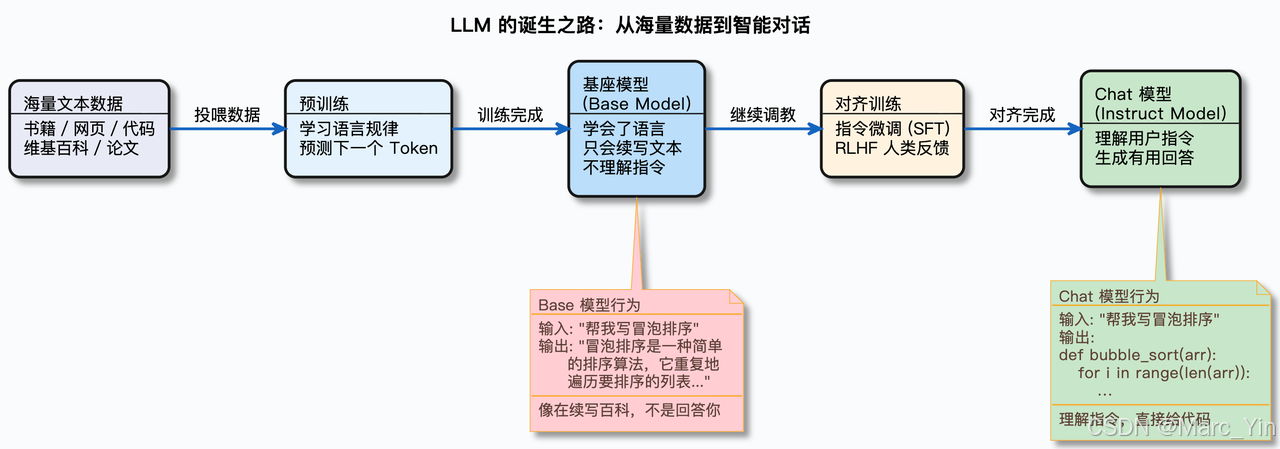
chat模型&基座模型
网页端使用的ChatGPT、Qwen、DeepSeek或者通过api调用大模型,实际上都是一种特定的大模型——Chat模型。但是大模型并不是天生就会聊天,需要专门训练才能成为合格的对话助手。
大模型训练分成两个阶段:
-
第一阶段:预训练(Pre-training)
-
模型阅读海量文本数据,学习语言的规律。训练完成后得到的就是基座模型(Base Model)。基座模型有一个特点:它只会续写。你给它一句话,它会接着往下写,但它不会回答问题。
-
举个例子,你给基座模型输入:中国的首都是,它可能会续写出:北京,是中华人民共和国的政治中心、文化中心……——看起来像是在回答问题,但其实它只是在做文本续写,因为训练数据里“中国的首都是北京”这种句式出现过很多次。但如果你对它说:请根据以下用户反馈,判断用户的情绪是正面、负面还是中性,只输出情绪类别,不要输出其他内容。用户反馈:物流太慢了,等了一周才到。基座模型不会乖乖输出“负面”两个字,它更可能接着你的文本继续写下去——比如再编几条用户反馈,或者写一段关于情绪分析的介绍文章。因为它不理解“只输出情绪类别”是一个指令,它只是在预测下一个最可能出现的词。
-
-
第二阶段:对齐训练(Alignment)
-
在基座模型的基础上,通过指令微调(Instruction Tuning)和人类反馈强化学习(RLHF)等技术,教会模型理解人类的指令,并按照指令给出有用、安全的回答。训练完成后得到的就是 Chat 模型(也叫 Instruct 模型)。
-
简单说:基座模型是读了很多书的学生,Chat 模型是读了很多书,又经过面试培训,学会了怎么和人沟通的员工。
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)