有序Logit怎么做:SPSSAU软件操作步骤与结果指标解读
若检验不通过,或者结果出现异常,通常说明该数据未必适合继续采用有序Logit,这时更适合转向多分类Logit思路。该表是核心结果表,用于查看阈值项与各自变量的具体影响方向和显著性,包含回归系数、标准误、z值、Wald检验、p值、OR值、OR值95%区间,以及模型拟合相关指标。该表仅在选择进行平行性检验时输出,用于判断有序Logit的关键前提是否成立,包含-2倍对数似然值、卡方值、df和p值。该表用
一、有序Logit方法所属模块
有序Logit位于【进阶方法】模块。
二、方法概述
有序Logit主要用于分析因变量本身带有顺序等级的数据,例如满意度高低、风险等级、购买意愿强弱这类结果。它适合用来判断多个影响因素会如何推动结果向更高等级或更低等级变化,尤其适合问卷研究、用户分层和行为倾向分析场景。
三、变量设置规则
该方法需要设置1个因变量和1至100个自变量,两类变量都需要填写后才能完成分析。
1. 因变量设置
(1)Y变量:只能放入1个,属于必填项。
(2)变量类型要求:Y变量需为定类变量,并且各类别之间应具有明确顺序,例如低、中、高。若类别只有名称差异但没有先后等级,不适合使用该方法。
2. 自变量设置
(1)X变量:可放入1至100个,属于必填项。
(2)变量类型要求:X变量既可以是定量变量,也可以是定类变量,因此在实际研究里既能放连续指标,也能放分组类因素。
四、参数设置及解释说明
1. 连接函数
(1)默认Logit:这是系统默认选项,也是最常见的设置。大多数常规场景下直接使用默认值即可。
(2)Probit、补充log-log、负log-log、Cauchit:这些都是不同的连接方式,适合在数据分布特点不同或研究者有明确模型偏好时进行尝试。若只是日常实操,优先使用默认设置更稳妥。
2. 平行性检验
(1)不进行(默认):适合先快速完成模型估计,查看整体结果。
(2)进行检验:用于判断各回归方程是否满足平行性要求。若检验不通过,或者结果出现异常,通常说明该数据未必适合继续采用有序Logit,这时更适合转向多分类Logit思路。
五、分析结果表格及其解读
有序Logit分析完成后,常见会输出因变量频数分布、模型检验、参数估计、预测准确率以及简化结果等表格;在特定设置或数据情况下,还会额外输出平行性检验表和样本缺失情况汇总表。
1. 表1:有序Logistic回归分析因变量频数分布
该表用于先看因变量各等级的样本分布是否均衡,包含名称、选项、频数、百分比等信息。
• 频数:表示每个等级实际有多少样本,作用是判断各类别样本量是否过少。若某些等级样本过少,模型结果通常会不稳定。
• 百分比:表示各等级所占样本比重,作用是辅助判断分布是否过度偏斜。若某一等级占比过高、其余等级很少,模型区分能力通常会受到影响。

2. 表2:有序Logistic回归模型平行性检验
该表仅在选择进行平行性检验时输出,用于判断有序Logit的关键前提是否成立,包含-2倍对数似然值、卡方值、df和p值。
• p值:是判断平行性是否成立的核心指标。一般来看,p值大于0.05,说明平行性要求可以接受;若p值小于或等于0.05,说明平行性可能不满足,继续使用有序Logit要谨慎。
• 卡方值:用于配合p值完成检验,本身不单独下结论,重点仍然看显著性结果。
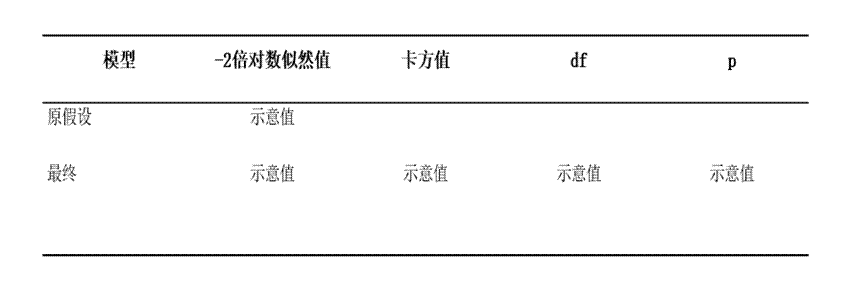
3. 表3:有序Logistic回归模型似然比检验
该表用于比较最终模型是否明显优于只有截距项的基础模型,包含-2倍对数似然值、卡方值、df、p值、AIC值和BIC值。
• p值:是判断模型整体是否有效的关键指标。通常p值小于0.05,说明自变量加入后模型有统计意义。
• AIC值、BIC值:主要用于不同模型之间做优劣比较。在同一批数据、同一分析目标下,这两个值通常越小越好。

4. 表4:有序Logistic回归模型分析结果汇总
该表是核心结果表,用于查看阈值项与各自变量的具体影响方向和显著性,包含回归系数、标准误、z值、Wald检验、p值、OR值、OR值95%区间,以及模型拟合相关指标。
• 回归系数:用于判断影响方向。系数为正,通常表示变量增大时更容易进入较高等级;系数为负,通常表示更容易落在较低等级。
• p值:用于判断某个自变量是否真的产生影响。通常p值小于0.05,说明该变量影响显著;若大于0.05,则说明影响证据不足。
• OR值:用于看影响强弱和方向。OR值大于1,通常表示变量增加会提升进入更高等级的可能性;OR值小于1,通常表示这种可能性下降;越远离1,影响往往越明显。
• OR值95%区间:用于辅助判断OR值是否稳定。若整个区间都在1的一侧,说明结果更稳;若区间跨过1,通常说明该变量作用不够明确。
• McFadden R方、Cox和Snell R²、Nagelkerke R²:这些指标用于描述模型拟合表现,一般数值越大,说明模型解释能力越强,但更适合做相对比较,不建议孤立解读。

5. 表5:有序Logistic回归模型预测准确率
该表用于评估模型对各等级结果的识别能力,包含实际频数、预测准确频数和预测准确率。
• 预测准确率:是判断模型分类表现最直观的指标。整体准确率越高,说明模型预测能力越好;同时也要比较各等级的准确率是否相差过大,避免模型只擅长识别某一类。
• 预测准确频数:用于查看每个等级究竟有多少样本被正确识别,可辅助判断模型是否存在偏向。

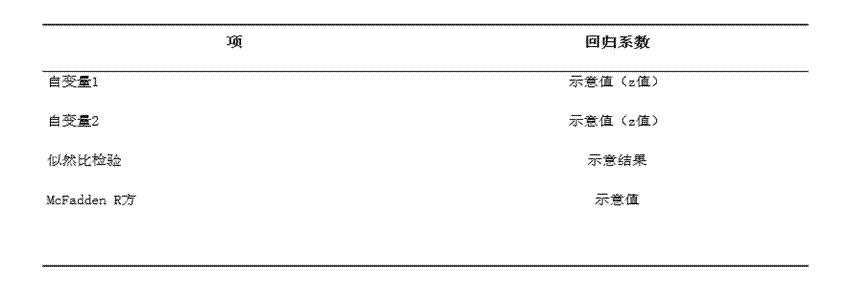
6. 表6:有序Logit回归分析结果-简化格式
该表用于快速汇总核心结论,适合写报告或整理研究结果,主要呈现各自变量回归系数、似然比检验结果、McFadden R方、因变量名称和样本量等信息。
• 回归系数:便于快速判断哪些变量影响方向为正、哪些为负。
• 似然比检验结果:用于快速判断模型整体是否成立,通常重点看p值是否小于0.05。
• 样本量:用于辅助判断分析结论的稳定性,样本量过小会影响结果可靠性。
7. 表7:样本缺失情况汇总
该表会在存在原始样本总量信息时输出,用于查看有效样本和被排除样本的数量及占比。
• 有效样本:表示真正进入模型分析的数据量,占比越高,通常说明数据可用性越好。
• 排除无效样本:用于判断缺失、异常或不符合分析条件的数据比例。若占比过高,需要先回头检查原始数据质量。

六、分析结果图表及其解读
该方法还会输出模型结果图和OR值95%区间图,帮助更直观地查看变量影响方向、强弱以及结果稳定性。
1. 模型结果图
该图会把各自变量与因变量之间的关系可视化展示出来,并直接标注对应结果值。阅读时可重点看连线上的数值和正负方向:若数值为正,通常表示更容易走向更高等级;若数值为负,则通常表示更容易走向较低等级。数值绝对值越大,说明影响通常越明显。
2. OR值95%CI图
该图用于同时查看各自变量的OR值及其区间范围。若某变量的区间整体位于1以上,通常说明它会提高进入更高等级的可能性;若整体位于1以下,通常说明它会降低这种可能性;若区间跨过1,则说明该变量的作用不够稳定,解读时要保守。
以上就是SPSSAU有序Logit方法的相关内容,更深入教程可查看SPSSAU帮助手册、教学视频、疑难解惑等资料。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)