IsaacLab入门(1) | Cartpole实践
实践文档介绍中先提到了MDP,这个系统概念对我们后面理解整体很关键。MDP (Markov Decision Process, 马尔可夫决策过程)就是用来描述和解决强化学习问题的数学模型,在Isaaclab里,马尔可夫决策过程(MDP)用于建模决策,其中Agent通过与env交互来学习做出决策,其中env部分由agent控制。查看了源码,MDP关键要素和在案例中的解释对应含义如下。要素英文在 Is
最近在入门Isaaclab,扒了官方文档之后,把一些思考和笔记放在这里,希望能和大家多多交流。
1. Introduction
Isaac lab 和isaac sim的关系及任务:
通过结合NVIDIA以往机器人工具和环境的优势,我们可以解决机器人学习的三个关键组成部分:
- 数据生成和渲染。您可以使用机器人模拟器或真正的机器人来完成这项工作。Isaac Sim 就是模拟器。
- 任务和环境。您可以通过 Isaac Lab 中的 Python API 定义您的环境。
- 训练库(RSL-RL、RL-GAMES、SKRL、Stablebaselines 等)。准备好环境和机器人后,就可以开始训练了。Isaac Lab 提供了多种训练算法,可用于训练机器人完成特定任务。
Isaac Lab 是一个任务设计框架,或者说是一个机器人学习框架,它使用 Python 文件来处理仿真状态。它通过状态(从仿真器捕获原始数据)、噪声添加(应用随机化和扰动以实现从仿真到实际的迁移)和观测(将带噪声的状态处理成可用的观测值)来管理学习流程。
2. Task Design Workflows
Isaac对于任务有两种管理方法:based-on manager; direct,文档里写的很清楚。
- 基于管理器的架构:环境被分解为多个独立的组件(或管理器),分别处理环境的不同方面(例如计算观测值、执行操作和应用随机化)。用户为每个组件定义配置类,环境负责协调各个管理器并调用它们的功能。
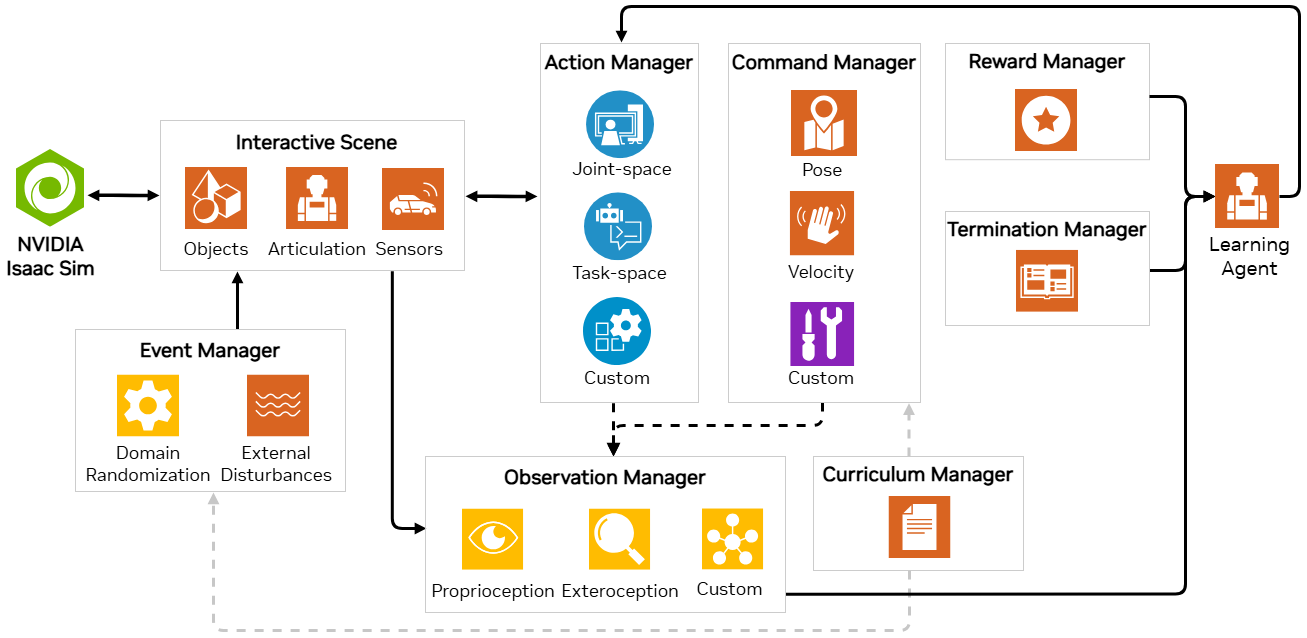
- 直接模式:用户定义一个类,该类直接实现整个环境,无需单独的管理器。该类负责计算观测值、执行动作和计算奖励。
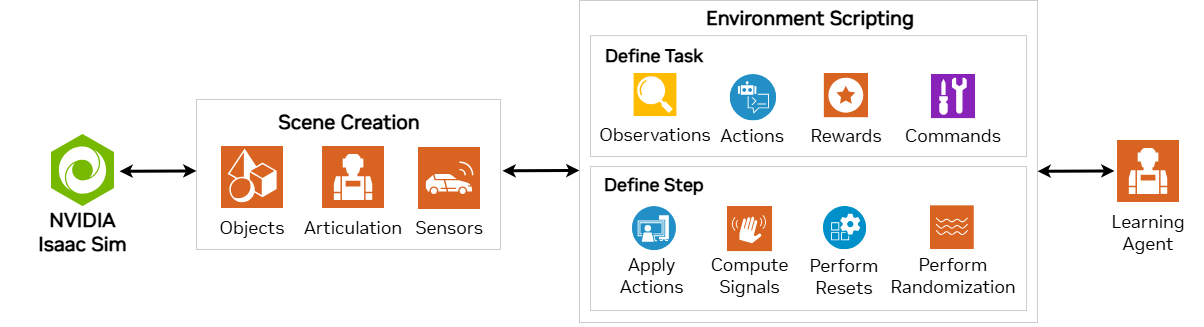
3. Cartpole实践(在Isaac里开始第一个机器人)
- MDP介绍
实践文档介绍中先提到了MDP,这个系统概念对我们后面理解整体很关键。
MDP (Markov Decision Process, 马尔可夫决策过程) 就是用来描述和解决强化学习问题的数学模型,在Isaaclab里,马尔可夫决策过程(MDP)用于建模决策,其中Agent通过与env交互来学习做出决策,其中env部分由agent控制。
查看了源码,MDP关键要素和在案例中的解释对应含义如下。
| 要素 | 英文 | 在 Isaac Lab/skrl 中的含义 | CartPole 例子中的具体实现 |
|---|---|---|---|
| 状态/观测 | State / Observation | 智能体从仿真环境中获取的信息,是它做决策的依据。 | 小车的位置和速度,杆子的角度和角速度。 |
| 动作 | Action | 智能体发出的指令,用于控制仿真环境中的机器人。 | 对小车施加的力,可以是“向左推”或“向右推”。 |
| 奖励 | Reward | 一个标量信号,用于告诉智能体当前动作的好坏。目的是鼓励期望的行为。 | 杆子保持直立时,每步给予小额正奖励;倒下则给予负奖励(惩罚)。 |
| 终止条件 | Termination | 定义一次尝试(一个episode)何时结束。 | 杆子倾斜角度超过90度,或者小车移出边界(如±3米),或达到最大步数。 |
这些设置在源码中都用@configclass装饰器定义。
configclass 是 Isaac Lab 框架中用于创建结构化配置类的装饰器,它通过提供清晰的配置定义方式、支持嵌套配置、继承和后初始化处理等特性,使得配置管理更加方便和高效。
- Carpole任务下,各setting定义
Action:
给小车的力矩。
Observation:
嵌套policycfg,策略观测组。杆的位置和速度。
Event: reset()
Rewards:
Tip:这里,奖励是所有环境的奖励, Isaac里也提供一些通用的奖励函数【APIenvs.mdp】 )
本任务中定义了许多类,包括持续运行奖励、首要任务(杆位置)奖励、失败惩罚、车速奖励、杆速奖励。
其中,计算杆位置偏差逻辑如下:
计算关节位置与目标值的差:joint_pos - target
对差值进行平方:torch.square(joint_pos - target)
沿指定维度求和:torch.sum(..., dim=1)
这实际上是计算了关节位置与目标值之间的 L2 范数(平方和).
这里补充范数的定义:
L1: 绝对误差,求每个元素的绝对差值并对其求和。对于一个向量x = [x1,x2,…,xn],和另一个向量y = [y1,y2,…,yn],其L1范数定义为:|| Error || = |x1 - y1|+|x2 - y2|+…+|xn - yn|。、
L2:欧式距离
L3:三次方,开立方根。
切比雪夫距离:所有坐标方向上差值最大值。
综上,在 cartpole/cartpole_env_cfg.py中,MDP settings:
class CartpoleEnvCfg(ManagerBasedRLEnvCfg):
# Scene settings
scene: CartpoleSceneCfg = CartpoleSceneCfg(num_envs=4096, env_spacing=4.0)
# Basic settings
observations: ObservationsCfg = ObservationsCfg()
actions: ActionsCfg = ActionsCfg()
events: EventCfg = EventCfg()
# MDP settings
rewards: RewardsCfg = RewardsCfg()
terminations: TerminationsCfg = TerminationsCfg()
4. Cartpole实践中报错点订正
问题
按照官方文档执行推理时,出现了一些问题,现记录更正方法。主要针对 scripts/skrl/play.py 脚本。
一开始报错 AttributeError: 'PPO' object has no attribute 'set_running_mode'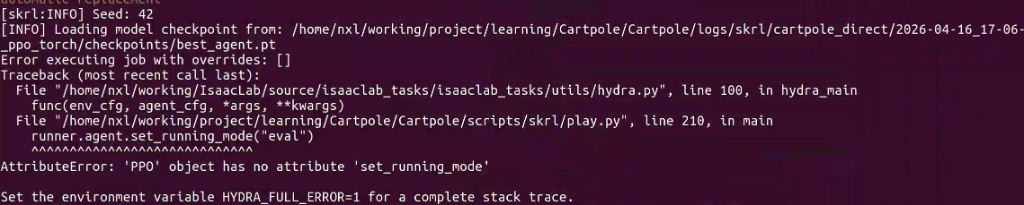
AI推荐用runner.agent.eval(),但也说没有这个attribute。以及几行后的act方法也缺参数。
按理说我的skrl版本已经升级到了最新,不应该有这个问题,但检索了一下没发现好的解决方法,直接手动修改了代码文件里的函数调用方法。
方法
因此查询官方文档,【skrl库查询手册】https://skrl.readthedocs.io/en/latest/api/agents.html。
eval需要用【Set the training mode of the agent: enabled (training) or disabled (evaluation).】 更新。
act()方法需要加入states参数,使用的states用env.state() 或者info中的信息更新。
更改后代码如下,大约在208行开始:
# 注释掉之前的写法
# runner.agent.set_running_mode("eval")
# 更改为:
if hasattr(runner.agent, "set_running_mode"):
runner.agent.set_running_mode("eval")
elif hasattr(runner.agent, "eval"):
runner.agent.eval()
else:
runner.agent.enable_training_mode(False)
# reset environment
obs, info = env.reset()
# 加入state更新逻辑
state = info.get("state", env.state()) if hasattr(env, "state") else None
timestep = 0
# simulate environment
while simulation_app.is_running():
start_time = time.time()
# run everything in inference mode
with torch.inference_mode():
# agent stepping
# 此处加入state变量
outputs = runner.agent.act(obs, states=state, timestep=0, timesteps=0)
# - multi-agent (deterministic) actions
if hasattr(env, "possible_agents"):
actions = {a: outputs[-1][a].get("mean_actions", outputs[0][a]) for a in env.possible_agents}
# - single-agent (deterministic) actions
else:
actions = outputs[-1].get("mean_actions", outputs[0])
# env stepping
# 加入来自info的state更新信息
obs, _, _, _, info = env.step(actions)
state = info.get("state", env.state()) if hasattr(env, "state") else None
if args_cli.video:
timestep += 1
# exit the play loop after recording one video
if timestep == args_cli.video_length:
break
# time delay for real-time evaluation
sleep_time = dt - (time.time() - start_time)
if args_cli.real_time and sleep_time > 0:
time.sleep(sleep_time)
# close the simulator
env.close()在这里记录一些好用的调试技巧:
print(dir(runner.agent)) # 在报错那行之前运行,看看有没有 'eval', 'set_mode' 或类似字眼

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)