Obsidian-Graphify-让你的笔记库自己长出知识图谱
AI知识管理新工具Graphify:让LLM帮你构建持续更新的知识图谱 AI大神Andrej Karpathy提出的LLM Wiki理念,通过开源工具Graphify实现自动构建知识图谱。Graphify能将各类文件转化为结构化知识库,通过两轮提取(结构+语义)生成可交互的知识图谱,显著降低查询token消耗。它支持增量更新,自动发现隐藏关联,配合Obsidian Web Clipper形成闭环工
前言
“你的笔记不是太少,是太散了。”
最近,AI 大神 Andrej Karpathy 发了一个 Gist,提出了一个让我拍大腿的想法——LLM Wiki。简单说就是:别再让 AI 每次从零开始检索文档了,让它帮你维护一个持续积累、自动更新的知识库。
卡帕西原文:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
想法很好,但卡帕西只给了理念,没给工具。结果没过几天,开源社区就有人把它做出来了——Graphify,一个 Claude Code 技能,一条命令就能把任何文件夹变成可交互的知识图谱。
Graphify 项目地址:
https://github.com/safishamsi/graphify/tree/v4
我用它把仓库里 65 篇文章跑了一遍,效果惊艳。今天就带你从原理到实操,完整走一遍。
🔥 卡帕西说了什么?
大多数人用 AI 管理知识的方式是 RAG:上传一堆文件,AI 在提问时检索相关片段,然后生成回答。
问题是:每次提问,AI 都在从零开始。
你问一个需要综合 5 篇文档的问题,AI 就得重新找、重新拼。知识没有被积累,也没有被结构化。
卡帕西提出了一种完全不同的思路:
让 LLM 持续地、增量地构建和维护一个 wiki——一组结构化的、相互链接的 Markdown 文件。每次你加入新资料,LLM 不只是索引它,而是读取、提取关键信息、整合到已有的 wiki 中。
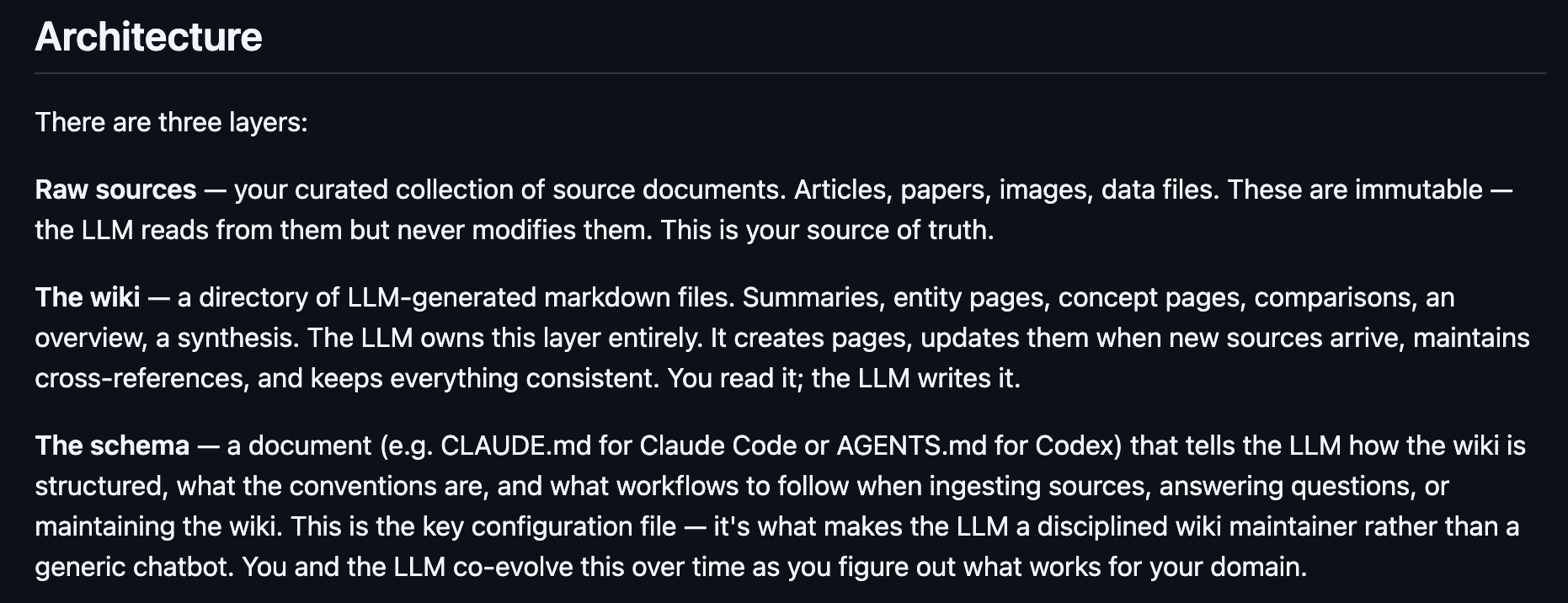
核心架构分三层:
- Raw(原始资料):你的文章、论文、截图,不可变,AI 只读
- Wiki(知识图谱):AI 生成的概念页、实体页、对比页,相互链接
- Schema(规则文件):告诉 AI 怎么维护这个 wiki
用卡帕西自己的话说:“Obsidian 是 IDE,LLM 是程序员,wiki 是代码库。”
🛠️ Graphify:从理念到成品
Graphify 就是卡帕西理念的完整实现。
它是一个 Claude Code 技能(Skill),一条命令就能把你的文件夹变成知识图谱。支持的不只是 Markdown——代码、PDF、截图、流程图、白板照片,统统可以丢进去。
它做了什么?
Graphify 分两轮提取:
第一轮:结构提取(免费,不需要 LLM)
用 tree-sitter 对代码文件做 AST 分析,提取类、函数、导入关系。这一步完全在本地运行,零 token 消耗。
第二轮:语义提取(需要 LLM)
并行调度 Claude 子代理处理文档、PDF 和图片,提取概念、关系和设计动机(不只是"做了什么",还有"为什么这么做")。
两轮结果合并后,用 Leiden 社区发现算法 做聚类,最终输出三样东西:
| 输出文件 | 说明 |
|---|---|
graph.html |
可交互的知识图谱可视化,节点按社区着色 |
GRAPH_REPORT.md |
分析报告:God Nodes、意外连接、建议提问 |
graph.json |
持久化图谱数据,跨会话可用 |

关键亮点
- 诚实审计:每条关系都标注了
EXTRACTED(源文件中明确存在的)、INFERRED(合理推断,附带置信度分数)或AMBIGUOUS(有歧义)。你始终知道哪些是真发现的,哪些是 AI 猜的 - Token 压缩:官方测试数据,52 个文件(代码+论文+图片)的知识库,每次查询 token 消耗降低 71.5 倍
- 增量更新:SHA256 缓存机制,重复运行只处理变更过的文件
📦 5 分钟安装 Graphify
前提条件:Python 3.10+、Claude Code
Step 1:安装 Graphify
pip install graphifyy && graphify install
PyPI 包名暂时叫
graphifyy(因为graphify这个名字还在回收),但 CLI 和 Skill 命令都是graphify。
Step 2:运行全量构建
在 Claude Code 里输入:
/graphify .
就这么一条命令。Graphify 会自动检测文件类型,分派子代理并行处理,最终生成完整的知识图谱。
我的仓库跑了大约 5 分钟,结果:
Corpus: 89 files · ~51,110 words
316 nodes · 277 edges · 66 communities
Top God Nodes: MCP (16 edges), Skills (8), CLAUDE.md (8)
Step 3:配置常驻模式(推荐)
图构建完成后,在项目目录运行:
graphify claude install
这会做两件事:
- 在
CLAUDE.md里写入规则,告诉 Claude 回答问题前先读GRAPH_REPORT.md - 安装 PreToolUse hook,每次搜索文件时自动注入图谱上下文
配置完成后,即使你不手动输入 /graphify,Claude Code 也会自动参考知识图谱来回答问题。
🔍 实战效果:我的 65 篇文章变成了什么?
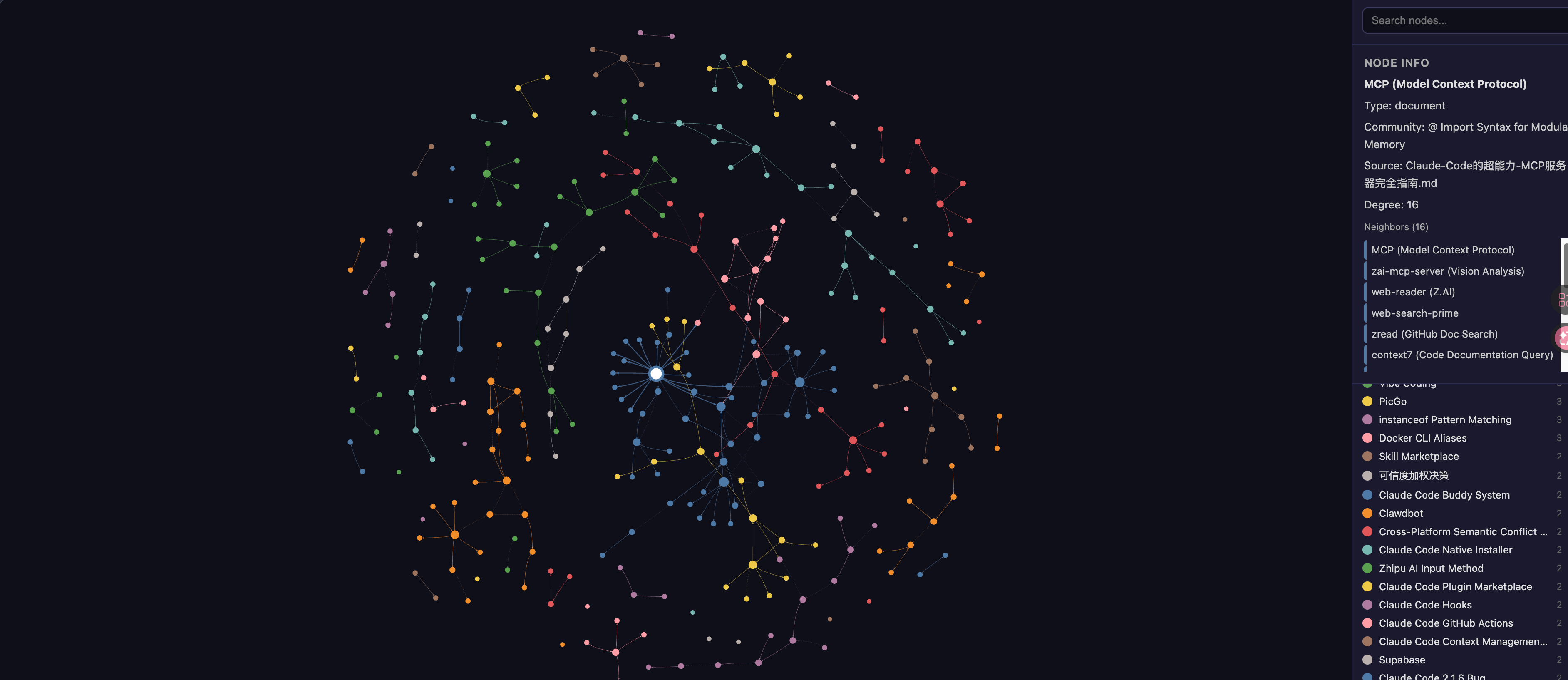
跑完之后,我得到了一张可交互的知识图谱,66 个社区,每个社区用不同颜色标注。
打开 graph.html,最直观的感受是:
原来我的文章之间有这么多隐藏连接!
God Nodes(核心枢纽)
图谱告诉我,我的知识库最核心的概念是:
- MCP(Model Context Protocol)— 16 条连接,当之无愧的枢纽之王
- Skills(AI Agent 技能系统)— 8 条连接
- CLAUDE.md 持久记忆 — 8 条连接
- Claude Code — 7 条连接
这说明我的写作重心一直在 AI 工具链上,MCP 是贯穿所有文章的核心线索。
意外连接(Surprising Connections)
最让我惊喜的是"意外连接"部分。Graphify 发现了一些我自己都没注意到的关联:
Google 翻译实时对话和Transformer 自注意力机制居然被连在了一起——确实,实时翻译的底层就是 Transformernvm(Node 版本管理器)和SDKMAN(Java 版本管理器)被识别为语义相似——都是 macOS 上的版本管理工具WSL2 Backend for Docker和WSL2 Networking跨文件建立了连接——两篇不同文章里的 WSL2 知识被自动关联
这些连接是你在手动管理笔记时永远不会发现的。
🌐 配合 Obsidian Web Clipper:闭环工作流
知识库不是一次性工程,需要持续维护。这里推荐一个完美搭配:Obsidian Web Clipper。
它是什么?
Obsidian 官方出品的免费浏览器插件,支持 Chrome、Edge、Firefox。看到好文章,一键剪藏到你的 Obsidian vault。
配置方法
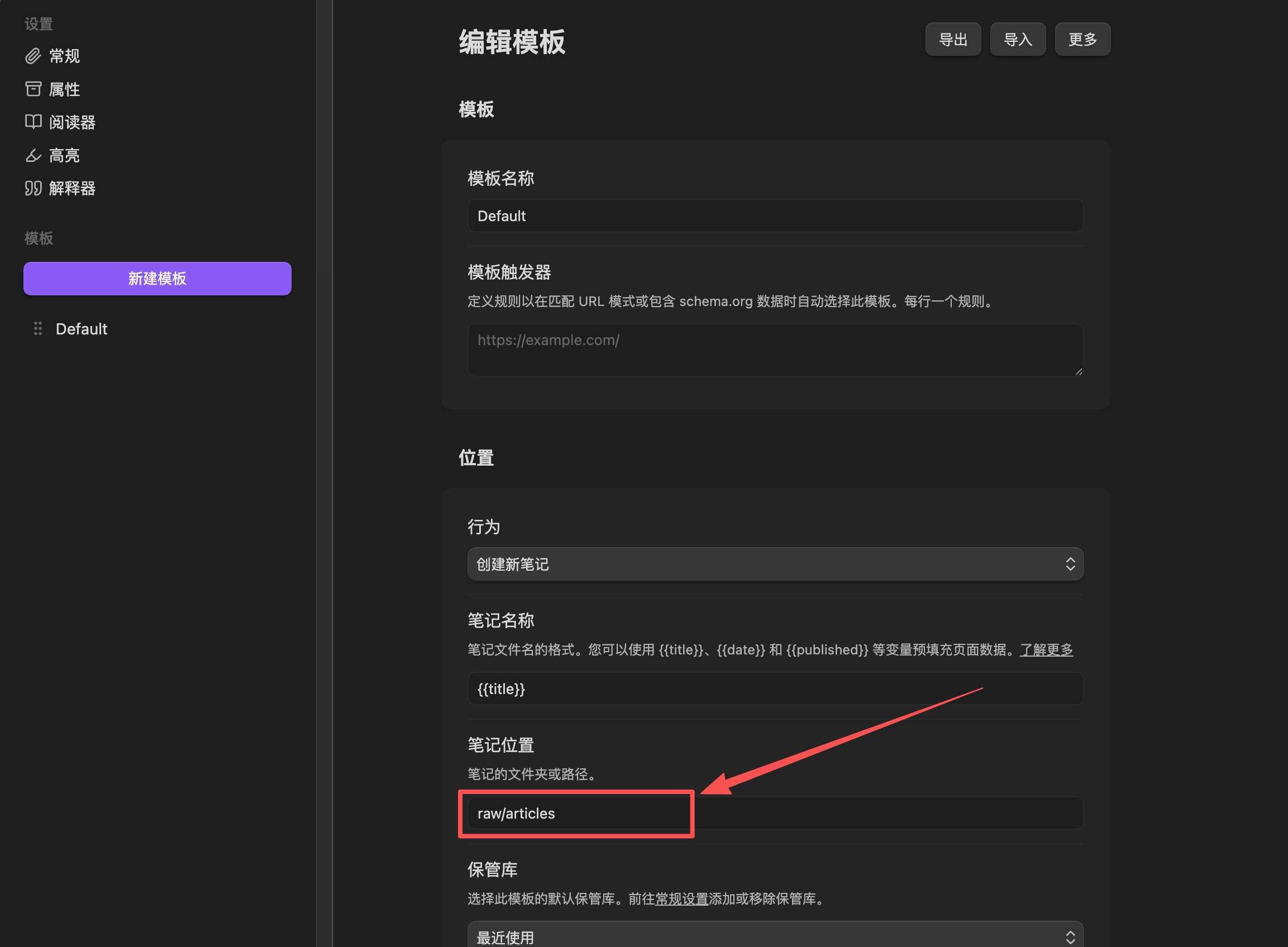
- 浏览器安装 Obsidian Web Clipper 插件
- 打开插件设置,点击左侧 “Default” 模板
- 把 “笔记位置”(Note Location) 改成
raw/articles - 如果你有多个 vault,在"常规"设置里添加保管库名称,然后在模板里选择对应的 vault
这样,每次剪藏的内容都会自动存到 raw/articles/ 目录。
我的日常维护工作流
浏览器浏览 → 发现好文章 → Web Clipper 一键剪藏 → 存入 raw/articles/
↓(积累 2-3 天)
打开 Claude Code → "检查新素材,更新知识库"
↓(自动执行)
读取新文件 → 更新 wiki 概念页 → 更新图谱 → 完成
完全不需要记命令,用自然语言跟 Claude Code 说就行。
📊 Graphify 常用命令速查
| 命令 | 说明 |
|---|---|
/graphify . |
全量构建知识图谱 |
/graphify . --update |
增量更新(只处理变更文件) |
/graphify query "你的问题" |
查询知识图谱 |
/graphify path "概念A" "概念B" |
查找两个概念之间的路径 |
/graphify explain "概念名" |
用自然语言解释某个节点 |
/graphify add <url> |
抓取网页并加入图谱 |
日常使用中,你只需要记住两条:
- 加了新素材 →
/graphify . --update - 想查知识 →
/graphify query "你的问题"
💡 为什么这套方案值得试?
回过头看,Graphify 解决的核心问题是:
知识管理的痛点不在阅读和思考,而在整理和维护。
人为什么放弃维护 wiki?因为交叉引用、同步更新、发现矛盾这些"体力活"太枯燥了。LLM 不会厌倦,不会忘记更新一个交叉引用,一次可以修改 15 个文件。
人的工作是筛选素材、引导分析、提出好问题。AI 的工作是其他所有事情。
就像卡帕西说的,这个想法和 1945 年 Vannevar Bush 提出的 Memex 一脉相承——一个私人的、精心策展的知识库,文档之间的连接和文档本身一样有价值。Bush 没能解决的问题是:谁来做维护?现在,LLM 来了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)