AI Agent 工程师必看:掌握提示词,你的智能体才能“听懂”人话
提示词工程是通过设计、优化和完善输入文本(提示词),引导大语言模型精准、高效、符合预期地完成任务的技术体系。上下文信息:背景、定义、约束条件任务说明:目标、格式、限制输出要求:结构、风格、语言。
Prompt Engineering 从入门到精通,这一篇就够了
文章目录
一、你和大佬之间,只差一个“好问题”
不知道你有没有这样的困惑:同样是用ChatGPT、DeepSeek、Claude,大佬们总能精准拿到高质量的输出,而你反复修改、来回拉扯,得到的却总是“听君一席话,如听一席话”。
问题出在哪儿?不是AI不行,是你的提问方式错了。
一个模糊的提示词(比如“写个线程池”),AI只能凭感觉猜你的真实意图,输出的结果自然是泛泛而谈。而经过精心设计的提示词,能引导AI像一位经验丰富的专家一样思考,输出精准、可靠、结构化的内容。
这就是提示词工程(Prompt Engineering) 的核心价值——它不只是在“问问题”,而是在“下指令”。OpenAI的研究表明,经过优化的提示词可使模型输出质量提升300%-500%,而错误提示导致的无效输出占比高达42%。
接下来,我将用一篇文章带你彻底搞懂提示词工程的底层逻辑和实战技巧。
二、什么是提示词工程?不只是“会提问”那么简单
2.1 提示词定义
提示词工程是通过设计、优化和完善输入文本(提示词),引导大语言模型精准、高效、符合预期地完成任务的技术体系。
提示词不只是一句话,它本质上包含三个核心组成部分:
上下文信息:背景、定义、约束条件
任务说明:目标、格式、限制
输出要求:结构、风格、语言
2.2 底层原理:AI不是“读心者”
大语言模型的生成本质是基于上下文的Token概率预测——它根据你的提示词,预测最有可能出现的下一个词,如此反复生成整个回答。
这意味着:你给的上下文越清晰,模型输出的概率分布就越接近你的预期。反之,如果你只给一句模糊的“帮我写个方案”,模型的概率空间几乎是无限的,输出自然不稳定。
因此,提示工程的核心就是通过清晰的指令、充分的上下文、必要的约束和明确的输出格式来压缩模型的概率空间,让它精准命中你的需求。
2.3 提示词的四个基本要素
一个好的提示词至少包含以下四个要素:
清晰指令:明确说出你要什么。不要说“做个待办事项”,要说“做一个支持拖拽排序、本地存储的待办事项Web应用”。
充分上下文:给模型执行任务所需的信息。例如,“用户是一名从事分布式系统工作的高级后端工程师”这句话,会改变输出的语调、词汇和专业深度。
必要约束:通过边界条件收窄可能性。例如,“不要使用第三方库”“代码需符合阿里巴巴规范”。
明确输出格式:提前指定JSON、Markdown、表格等格式,确保输出可解析、可复用。
三、五大核心原则:让AI听话的底层逻辑
3.1 指令清晰明确
这是最基础也最重要的一条。杜绝模糊表述,让模型无歧义地理解你的任务目标。不说“写个文案”,要说“写一篇300字面向宝妈的婴儿辅食机种草文案,突出安全无异味、一键操作2个核心卖点,语气亲切真诚”。
3.2 上下文完整充分
给足任务依赖的所有背景信息——原文、数据、规则必须完整放入提示词,避免模型依赖预训练知识或凭空编造。
3.3 输出格式结构化
提前指定输出的范式,明确要求Markdown、JSON、分点列表、表格等固定格式。复杂输出还需提前定义层级结构。
3.4 正向指令优先
以肯定性表述定义输出要求,规避否定性指令。用“口语化、朋友聊天的语气”替代“不要太官方”。LLM对正向描述的权重远高于否定表述,过多使用“不要”“禁止”反而会强化模型对违规内容的记忆。
3.5 复杂任务拆分为简单子任务
任务拆解分层——复杂任务要拆解为多个可执行的子任务,分步执行,而非在一条提示词中堆砌多个不相关的任务。
四、六大进阶策略:从“能问”到“会问”
掌握了基本原则后,我们来看看当前最主流的进阶技巧。
4.1 角色扮演(Role Prompting)
这是最实用、上手最快的技巧之一。通过给AI分配明确的身份、专业背景和能力边界,让它以特定视角输出内容。
❌ 普通提问:“帮我写个产品介绍”
✅ 角色扮演:“你是一位拥有10年经验的护肤品产品经理。请面向25-35岁敏感肌用户,撰写一段新品修护精华的产品介绍,突出成分安全、舒缓修复的核心卖点。”
角色扮演之所以有效,是因为它能激活模型预训练中对应身份的专业语料分布,让输出快速贴合预期。
4.2 思维链(Chain of Thought)
思维链(CoT)是2022年由Google Research在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中正式提出的突破性技术。其核心思想是:当要求模型“展示思考过程”而非直接给出答案时,模型在算术、常识推理等任务上的准确率会显著提升——GSM8K数学数据集上的准确率从17%跃升至58%。
简单来说:逼AI像人一样一步步推理,而非“凭直觉猜答案”。
❌ 普通提问:“这篇文章怎么优化?”
✅ 思维链提问:“请先指出文章前三段的逻辑漏洞,再针对每段给出改写建议,最后总结三个提升吸引力的标题。”
在实际应用中,你可以使用“请先分析……再给出……最后总结……”的固定框架来触发模型的推理能力。
4.3 少样本学习(Few-Shot Prompting)
通过在提示词中提供2-5个高质量的输入-输出示例,帮助模型理解你期望的模式、风格和结构。
示例1:输入“这款手机续航很棒”→输出“正面”
示例2:输入“客服响应太慢了”→输出“负面”
新输入:“产品包装有破损”→输出:______
少样本学习的核心在于示例的质量而非数量——2-3个精心挑选的典型示例,效果往往优于10个粗糙示例。
4.4 结构化输出约束
无论你用哪种技巧,最后一定要加上明确的输出格式要求。这是最容易被忽略却至关重要的一步。
如果你在写代码,要求输出“完整的Python类+类型注解+docstring”
如果你在写文档,要求输出“Markdown格式,包含标题层级和代码块”
如果你在做数据分析,要求输出“三列表格,包含指标名称、数值、变化趋势”
结构化输出不仅让内容更易阅读,更重要的是让输出可解析、可复用、可自动化处理。
五、RBTRO框架:一套“万能公式”搞定90%的提示词
理论说了很多,你可能需要一个“开箱即用”的模板。这里分享一套经过大量实践验证的RBTRO框架:
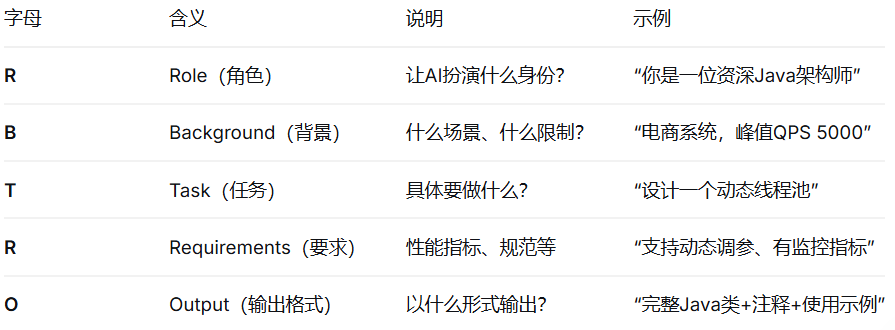
实战案例对比
❌ 改造前:“帮我推荐一下杭州周末去哪玩?”
→ AI大概率会丢给你一个“西湖、灵隐寺、雷峰塔”的标准游客三件套。问完你还得继续追问吃什么、住哪里、路线怎么安排,来回拉扯七八次,攻略依然不省心。
✅ 改造后(套用RBTRO框架):
R(角色):你是一位土生土长、热爱生活的杭州本地资深导游
B(背景):周末带爸妈去杭州玩两天,爸妈60岁左右,腿脚不能走太久,喜欢清净、有历史感的地方,不爱网红店
T(任务):策划一份松弛感满满的杭州两日游行程规划
R(要求):
- 每天步行不超过1万步,景点之间打车或公共交通方便
- 吃饭避开排队严重的连锁店,推荐本地人吃的杭帮菜小馆
- 必须包含一处小众、人少、能喝茶看风景的地方
- 给出雨天室内游玩的备选方案
O(输出):一份Markdown格式的完整行程表,包含时间轴、地点、交通建议、美食推荐及注意事项
这个框架的本质,是把我们平时写需求文档的思路搬到了AI对话中——把AI当成需要详细需求文档的高级工程师,而不是一个会读心术的神仙。
六、常见误区与避坑指南
6.1 误区一:提示词越长越好
真相:长度不等于质量。过长的提示词会引入噪声,反而分散模型的注意力。IBM指南指出,上下文工程的核心是“信息密度”而非“信息总量”——不必要的上下文会增加噪音,太少则导致输出过于通用。
建议:宁可精炼地写200个高价值字,也不要堆砌1000字的冗余信息。
6.2 误区二:一次写完美,不再迭代
真相:提示工程是闭环过程,需要基于模型输出的反馈持续调整。第一次就能写出完美提示词的概率极低,迭代才是常态。
建议:建立“写→测→改→再测”的循环习惯,逐步收敛到最优效果。
6.3 误区三:忽视输出格式
真相:这可能是最被低估的错误。不指定格式的后果是——即使内容正确,你也无法解析、无法复用、无法自动化。
建议:每条提示词最后一定要加上输出格式要求。形成肌肉记忆。
6.4 误区四:过度依赖否定性约束
真相:“不要写得太官方”“不要使用专业术语”——这类否定性指令往往适得其反。LLM对正向描述的响应效果远优于否定表述。
建议:用“口语化、朋友聊天的语气”替代“不要太官方”,用“通俗易懂的语言”替代“不要用专业术语”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)