AutoDL 环境搭建与项目基础准备工作
在StoryVerse:基于 LLM 的多智能体小说情节角色扮演平台 项目的开发中,我所负责的工作为ActionParser模型微调,角色大模型API调用与Prompt结构设计,在考虑到模型微调需要性能较高的gpu支持,经过团队讨论决定通过AutoDL进行租用以完成模型微调,针对gpu、数据集、模型部署的问题,我开展了前期调研以及基础部署工作如下。
首先完成了服务器环境的租用、实例创建、项目目录规划、运行环境配置、基础模型部署以及数据集整理等一系列准备工作。虽然这一阶段尚未进入模型训练和系统联调,但它实际上是整个项目后续开发能否顺利推进的关键基础。只有先把运行环境、文件结构、模型资源和数据资源管理好,后续的训练、微调、评估和部署工作才能稳定开展。
本阶段我选择使用 AutoDL 租用算力卡进行开发,选择了性能较高的RTX 5090,部署基础镜像为PyTorch 2.8.0 / Python 3.12(ubuntu22.04) / CUDA 12.8,按量计费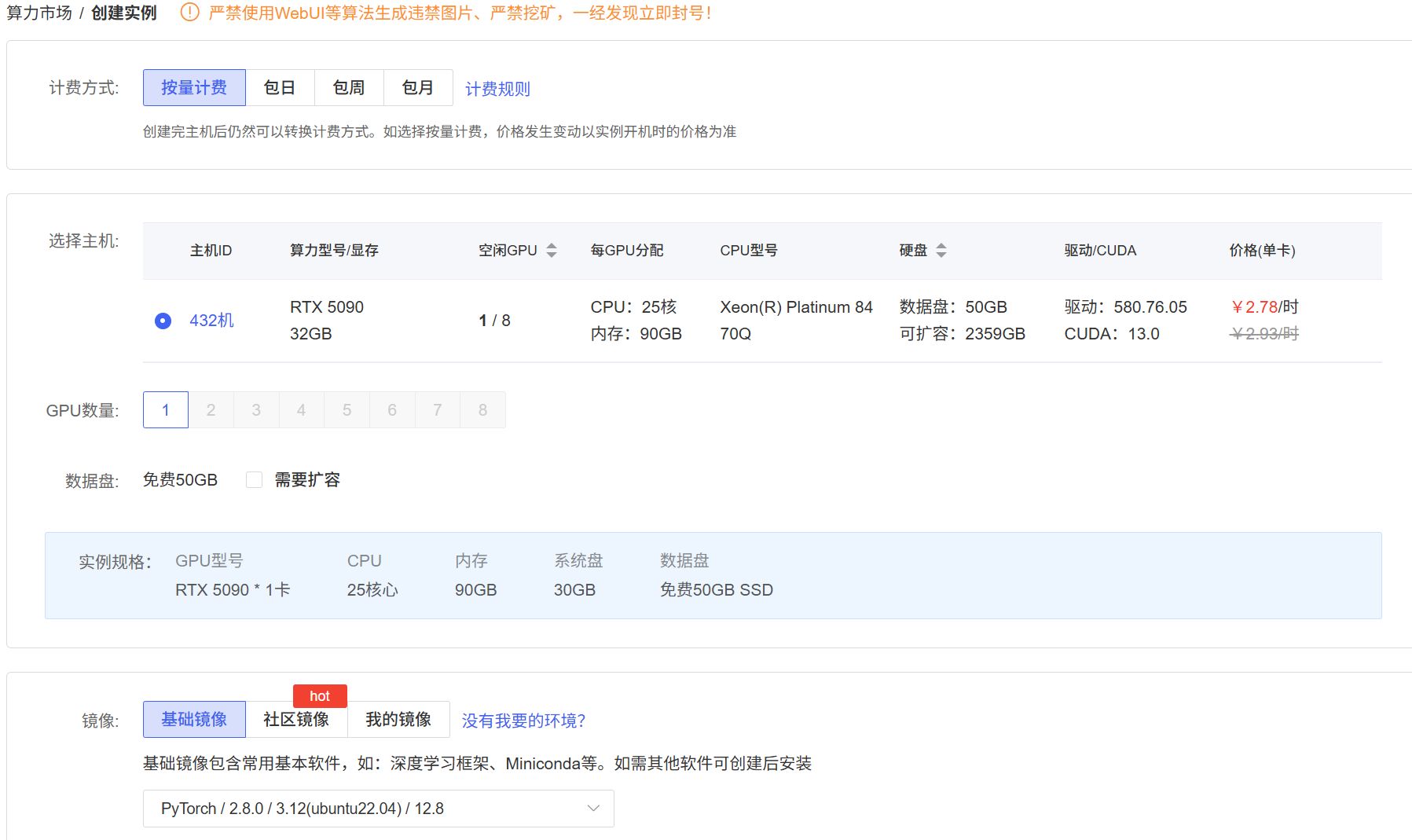
完成租卡后,我创建了对应的实例,并在实例内部开始搭建项目运行环境。与常见的将数据和项目内容放在数据盘的方式不同,这次我将项目的全部文件、代码、模型和数据统一放置在 /root/storyverse 路径下。这样做的主要考虑是便于后续保存镜像:当实例环境配置完成后,我可以直接将当前系统状态打包为镜像,从而把项目文件和环境一并保留下来,避免后续重复配置,也减少因路径分散导致的管理成本。这一调整实际上是从项目长期维护和环境复用的角度做出的设计决策,为后续实验复现和团队协作提供了便利。
在项目目录管理方面,我已经按照前期规划,在 /root/storyverse 下完成了相应目录结构的创建。
mkdir -p /root/storyverse/{code,data/raw,data/interim,data/processed,data/eval,models/base,models/adapters,models/merged,outputs/logs,outputs/checkpoints,outputs/reports,env_backup,tmp}所创建的目录结构如下,提前搭建好项目所需的模型目录、数据目录、训练输出目录、配置目录等基础结构
/root/autodl-tmp/storyverse/
├── code/ # 项目代码
│ ├── scripts/ # 下载、预处理、训练、评估、合并脚本
│ ├── src/
│ ├── configs/
│ └── notebooks/
├── data/
│ ├── raw/
│ │ ├── hermes/
│ │ ├── sgd/
│ │ └── custom_eval/
│ ├── interim/ # 中间解析文件
│ ├── processed/ # 训练/验证 jsonl
│ └── eval/ # 100条人工测试样本与标注
├── models/
│ ├── base/
│ │ └── Qwen2.5-1.5B-Instruct/
│ ├── adapters/
│ │ └── actionparser-lora/
│ └── merged/
│ └── actionparser-merged/
├── outputs/
│ ├── logs/
│ ├── checkpoints/
│ └── reports/
├── env_backup/
│ ├── requirements.txt
│ ├── environment.yml
│ └── pip_freeze.txt
└── tmp/ 在 Python 运行环境方面,我创建了专门用于 StoryVerse 项目的 conda 环境 storyverse
conda create -n storyverse python=3.12 -y
conda activate storyverse
python -V并在该环境中安装了现阶段所需的训练与评估依赖
pip install -U pip setuptools wheel
pip install \
torch torchvision torchaudio \
transformers peft accelerate datasets trl \
sentencepiece safetensors huggingface_hub \
scikit-learn scipy pandas numpy matplotlib \
tqdm pyyaml orjson ujson pydantic \
tensorboard evaluate jsonschema完成依赖安装后,我还对当前环境进行了备份,目的是在已有可用状态下形成一个稳定基线。这样一来,即便后续安装新依赖或调整配置出现问题,也能快速回退到当前的可用版本,减少排错成本。
pip freeze > /root/autodl-tmp/storyverse/env_backup/pip_freeze.txt
conda env export > /root/autodl-tmp/storyverse/env_backup/environment.yml在环境配置完成后,我进行了基础运行检查,以验证 conda 环境、依赖安装以及项目整体运行条件是否正常。从当前结果来看,基础运行检查没有问题,说明现阶段的环境配置是成功的。这一步虽然看起来比较常规,但它实际上非常重要。
python - <<'PY'
import torch
print("torch:", torch.__version__)
print("cuda available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("gpu:", torch.cuda.get_device_name(0))
print("bf16:", torch.cuda.is_bf16_supported())
PY很多项目的开发问题并不是出在算法本身,而是出在早期环境配置不完整、依赖版本冲突或路径设置错误上。因此,在正式引入模型和数据之前先完成环境可用性验证,是后续减少隐性问题的必要步骤。
在模型资源准备方面,我已经将本机中的基座模型复制到服务器路径 /root/storyverse/models/base 下,并完成了解压。考虑到大模型文件体积较大、下载耗时较长,如果在每次新实例中重复拉取模型,效率会比较低,因此直接将本地已有模型迁移到服务器是一种更高效的资源准备方式。模型复制完成后,我进一步进行了加载测试,结果显示模型可以被正常加载,没有出现模型文件损坏、权重缺失或路径配置错误等问题。这意味着当前的基座模型已经具备后续训练、微调或推理测试的基础条件,也说明服务器端的模型资源部署已经初步完成。
python - <<'PY'
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_dir = "/root/autodl-tmp/storyverse/models/base/Qwen2.5-1.5B-Instruct"
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
device_map="auto"
)
print("Tokenizer vocab loaded:", tok.vocab_size)
print("Model loaded successfully")
PY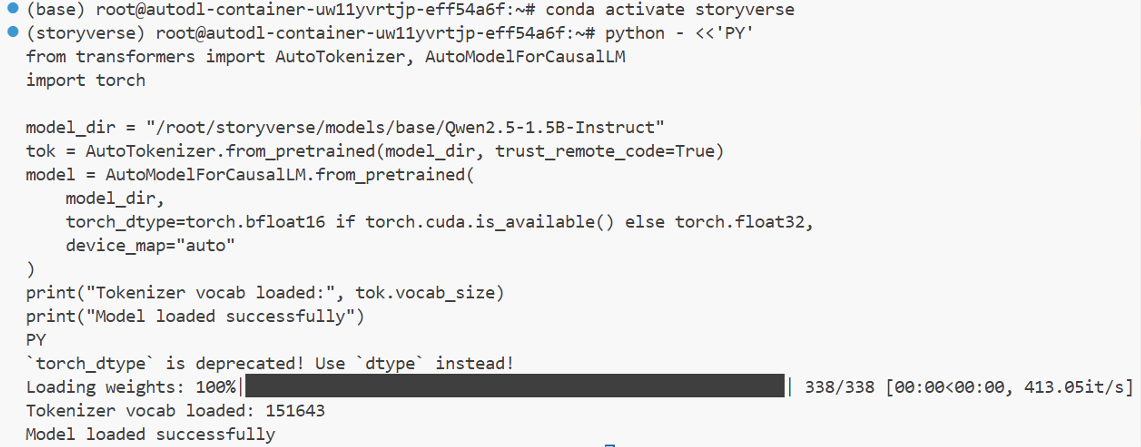
在数据资源准备方面,我已经将项目当前要使用的两个数据集分别整理并放置到了规定目录下。其中,Hermes 数据集被放在 /root/storyverse/data/raw/hermes,SGD 数据集被放在 /root/storyverse/data/raw/sgd。这一阶段的重点还不是数据清洗和预处理,而是先完成原始数据的集中存放与规范管理,使后续的数据解析、样本构建、训练集生成和评估流程能够直接基于统一的数据入口展开。对于后续可能涉及的数据转换脚本、微调格式构造和实验版本管理来说,这一步也是非常必要的准备工作。
关机之后,保存当前已经配置好的镜像资源,防止出现抢卡的问题,以便节省重复拉取数据配置环境的时间,增质提效。

综合来看,目前我已经完成了 StoryVerse 项目前期最核心的一轮基础建设工作,包括算力资源准备、实例创建、项目主目录规划、conda 环境创建、训练评估依赖安装、环境备份、基础运行验证、基座模型迁移与加载测试,以及 Hermes 和 SGD 两套原始数据集的整理入库。这些工作虽然不直接体现在最终系统界面上,但它们构成了整个项目后续开发的底层支撑。可以说,到目前为止,项目已经从“纯方案设计阶段”进入到了“具备实际开发与实验条件的实施阶段”。
接下来,我将继续推进数据预处理、训练脚本适配、微调流程打通以及模型实验验证等工作。在完成基础设施搭建之后,后续开发重点会逐步从“环境是否可用”转向“训练流程是否可跑通”“数据是否能够正确支撑任务”“模型输出是否满足系统需求”等更具体的技术问题。第一阶段的目标已经基本达成,也为 StoryVerse 后续的模型开发和平台实现奠定了稳定基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)