AI核心知识119—大语言模型之 监督微调 (简洁且通俗易懂版)
监督微调 (Supervised Fine-Tuning, 简称 SFT) 是把大语言模型从一个“野生学霸” 变成“全能助理” 的第一道关键工序。
这也是我们上一条提到的 Software 2.0 时代 最典型的一种“编程”方式。
如果说之前的预训练 (Pre-training / 自监督学习) 是让 AI 读完了人类所有的书,获得了海量的知识;那么 SFT 就是送这个 AI 去上“礼仪培训班” ,教它如何用人类喜欢的方式来交流。
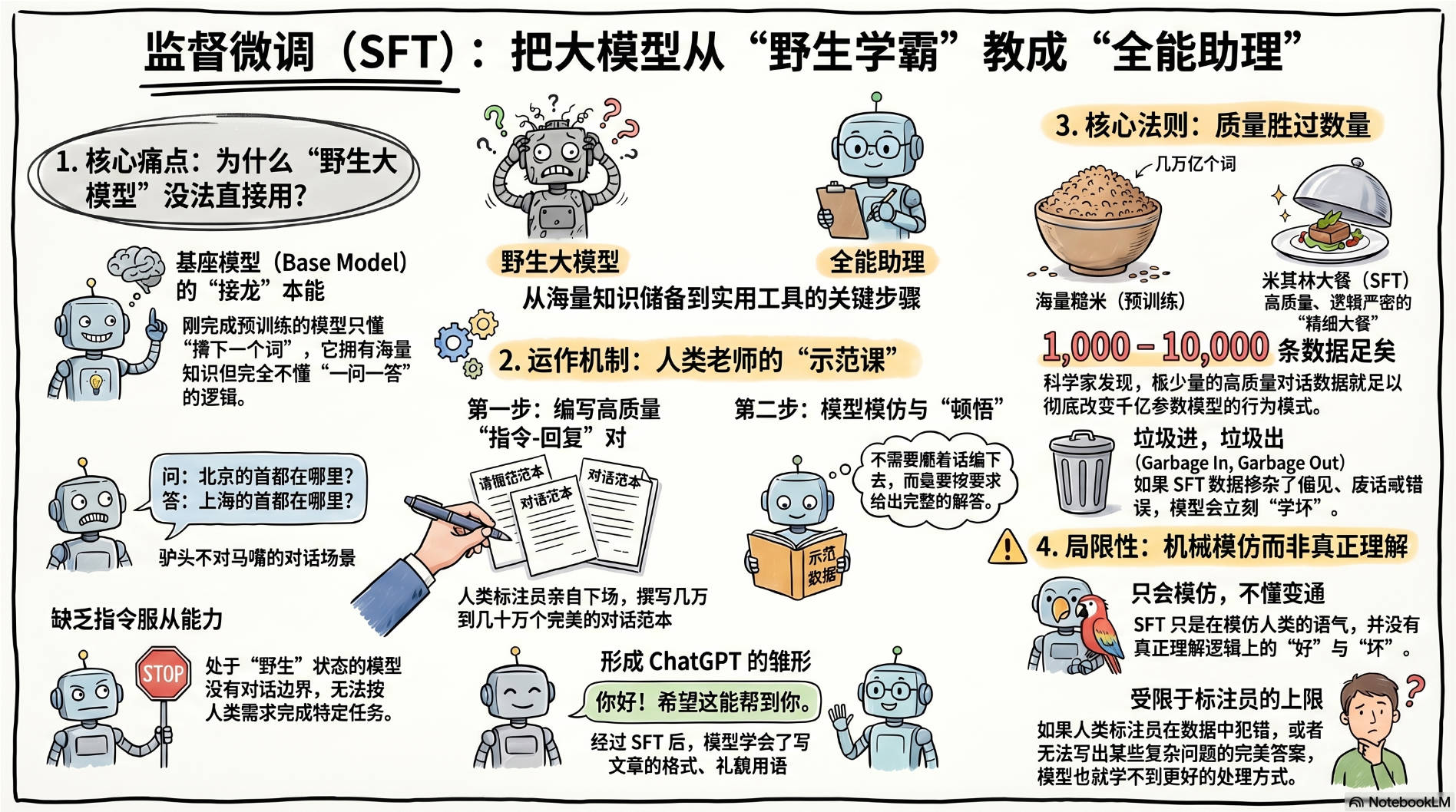
1.🎓 核心痛点:为什么“野生大模型”没法直接用?
刚刚完成预训练的基座模型 (Base Model) 脑子里充满了知识,但它唯一的本能就是“文本接龙 (猜下一个词)” 。它根本不懂什么是“一问一答”。
-
场景还原:
-
你问它:“北京的首都在哪里?”
-
野生大模型可能会接:“上海的首都在哪里?广州的首都在哪里?”(因为它在网上看过太多这种考试题库的排版,它以为你想继续出题)。
-
或者它会接:“这是一道小学地理题,出自《人教版地理》第X页。”
-
野生大模型缺乏“对话能力” 和“服从指令的能力” 。SFT 的出现,就是为了打破这种接龙惯性。
2.🛠️ SFT 是怎么运作的?(人工示范)
SFT 的全称里有“监督 (Supervised)”两个字,正如我们之前聊过的,这意味着人类老师必须亲自下场,提供带有“标准答案”的试卷。
它的核心做法是投喂高质量的“指令-回复”数据对 (Prompt-Response Pairs) 。
-
人工撰写数据:人类标注员会辛辛苦苦地写下几万到几十万个完美的对话例子。
-
输入 (Prompt):“帮我写一封请假信,因为我感冒了。”
-
输出 (Response):“尊敬的领导:您好!我因近日不慎感染风寒,身体不适……”
-
-
模型模仿:把这些数据喂给基座模型。模型通过这些例子,突然顿悟了:“哦!原来人类输入一句话之后,我不需要顺着他的话继续编,而是应该按照他的要求,给出一个完整的解答!”
-
结果:经过 SFT 的洗礼,模型学会了写文章的格式、懂得了礼貌用语(比如开头加“你好”,结尾加“希望这能帮到你”),真正具备了 ChatGPT 的雏形。
3.💎 核心法则:质量大于数量 (Quality is all you need)
在预训练阶段,模型吃的是互联网上的“海量糙米”(几万亿个词,数据脏点也没关系)。 但在 SFT 阶段,模型吃的是“米其林大餐” 。
-
科学家发现,SFT 不需要海量的数据。只要有 1000 到 10000 条极高质量、逻辑严密、排版精美的对话数据,就足以彻底改变一个拥有千亿参数的大模型的行为模式。
-
如果 SFT 的数据里掺杂了低质量的回答、偏见或者废话,模型也会立刻学坏(这在业界被称为“Garbage in, garbage out”)。
4.🚧 SFT 的局限性:只会模仿,不懂变通
虽然 SFT 让模型学会了好好说话,但它依然有致命的弱点:它只是在机械地模仿人类的语气,并没有真正理解“什么是好,什么是坏”。
-
如果人类标注员在训练数据里犯了逻辑错误,模型也会照单全收。
-
面对一些极其复杂、没有标准答案的问题(比如写一首关于量子力学的十四行诗),人类标注员自己都写不出来完美的示范,那模型也就学不到上限在哪里。
总结
监督微调 (SFT) 就是给大模型“立规矩” 和“定格式” 的过程。
它通过人类的高质量示范,硬生生地把一个只会疯狂往下续写文字的“文本生成器”,掰成了一个听得懂指令的“问答机器人”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)