体系结构论文(103):AKG Kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
这篇文章的定位很清楚:它想做的是一个 cross-platform kernel synthesis framework,而不是只在某个 benchmark 上生成一个快 kernel。这对于跨平台 kernel synthesis 很关键。这里可以看出一个很重要的事实:AKG kernel agent 的 correctness 成绩很亮眼,但性能上并不是“全面碾压”。这篇文章讨论的是一个很明确
AKG Kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
这篇文章在做什么
这篇文章讨论的是一个很明确的问题:能不能用多 agent 系统,把 AI kernel 的生成、迁移和调优自动化,而且还能跨平台?
作者提出了 `AKG Kernel Agent`,全称 AI-driven Kernel Generator。它想解决的不是单个平台上的 kernel 优化,而是:
- 面向多个 DSL
- 面向多个硬件后端
- 同时兼顾 correctness、performance、portability它支持的 DSL 包括:
- Triton
- TileLang
- CPP
- CUDA-C目标后端则包括 GPU、NPU、CPU 等。
这篇文章的定位很清楚:它想做的是一个 cross-platform kernel synthesis framework,而不是只在某个 benchmark 上生成一个快 kernel。
一、背景
为什么 kernel generation 这件事现在越来越难
今天的 AI 模型越来越复杂:
- LLM
- 多模态模型
- 推荐系统
- 稀疏化 / 量化 / 融合算子
与此同时,硬件也在快速变化:
- GPU 代际更新快
- NPU、Ascend 等新平台不断出现
- 不同平台有完全不同的执行模型和 DSL 生态
这就导致一个核心矛盾:
- 模型和硬件都在快速变化
- 人工 kernel 工程跟不上
作者提到 FlashAttention 等优化在新架构上常常要延后很久才能成熟,这个例子很能说明问题。kernel 优化往往不是“写对就行”,而是要懂 memory hierarchy、thread/block、tiling、指令特性、运行时特征。这本来就非常吃专家经验。
二、方法
如果把它和前面那些工业系统论文对比,这篇文章整体上更像一个比较规范的 academic multi-agent framework。
它的核心思路是把 kernel generation 拆给四个 agent:
- Designer
- Coder
- Verifier
- Conductor
然后再用:
- 文档驱动知识注入
- 层次化检索
- 迭代搜索优化
把整个流程串起来。
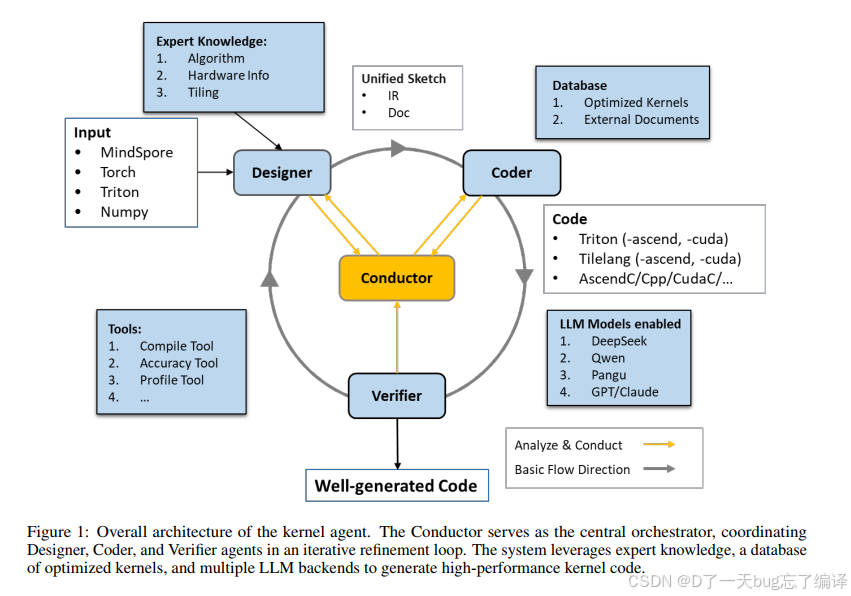
图 1 展示了整体架构。
其中每个 agent 的职责分得很清楚:
1. Designer
负责读 operator specification、目标硬件特征,生成一个叫 Unified Sketch 的中间表示。
2. Coder
把 Unified Sketch 翻译成目标 DSL 代码,比如 Triton / CUDA-C / TileLang / CPP。
3. Verifier
- 编译
- 正确性验证
- 性能 profiling
4. Conductor
负责调度整个工作流,并根据错误类型决定回退给 Designer 还是 Coder。
kernel generation 本来就有两类完全不同的问题:
- “到底该怎么并行、怎么切块、怎么组织 memory”
- “这个策略要怎么用具体 DSL 表达出来”
把这两件事混在一个 prompt 里,确实容易让模型顾此失彼。
Unified Sketch
作者在 3.2.1 节提出的 Unified Sketch,本质上是一个硬件高效但 DSL 无关的中间表示。
它的目标是把高层优化意图表达出来,而不提前绑定具体语法。
作者把 Sketch 形式化成四部分:
- D:declarations
- O:operations
- C:control flow
- H:hints
这里最关键的是 H,也就是 optimization hints。作者把很多复杂优化不是直接写成底层代码,而是用提示表达:
- parallel
- grididx / coreidx
- pipeline
- vectorize
- unroll
这是一种很好的折中。它比纯自然语言更结构化,但又没有过早绑定某个 DSL。

图 2 给了 RMSNorm 的 Unified Sketch 示例。
这张图的价值在于,它让你看到这个中间表示并不是空泛“设计草图”,而是真的包含:
- 符号变量
- tensor 声明
- alloc / load / store / compute
- 显式循环
- 以及 optimization hints
可以把 Unified Sketch 理解成“介于算法思路和可执行代码之间的一张结构化施工图”。
有了这张施工图,Coder agent 不用再从零猜“作者到底想怎么并行”,而是只需要把既定策略翻成对应 DSL。
这个设计是这篇文章最有新意的部分之一,也是它区别于“一个大模型直接写 kernel”的关键。
为什么“把设计和编码拆开”
这篇文章强调 decoupling of strategy and implementation。
- Designer 要考虑的是算法结构、tiling、memory reuse、parallelization strategy
- Coder 要考虑的是 DSL API、语法、目标后端支持、代码组织习惯
这两类认知负担其实很不一样。
把它们拆开以后,Conductor 还可以更精确地做错误回流:
- 如果是设计层的问题,回给 Designer
- 如果是实现层的问题,回给 Coder
这比传统“生成失败了就整段重写”更有工程逻辑。
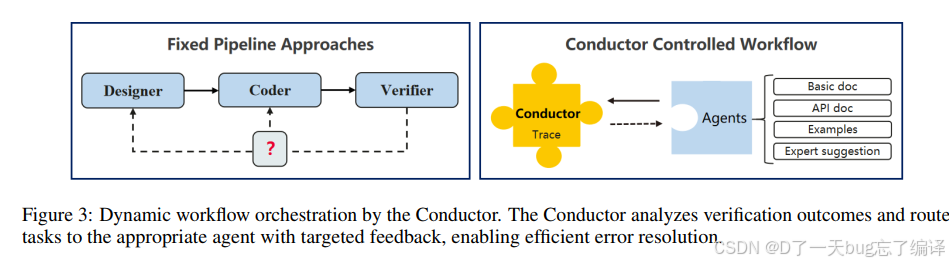
图 3 展示的是 Conductor 如何根据验证结果动态路由。
这说明系统并不是:
Designer -> Coder -> Verifier -> 结束
而是一个闭环:
- 设计有问题,回设计
- 代码有问题,回实现
- 性能不满意,继续进下一轮优化
这点很重要,因为 kernel generation 的错误来源非常不同:
- 可能是 sketch 本身策略错了
- 可能是代码语义翻译错了
- 可能是 correctness 过了,但性能太差
如果不做这种区分,系统很容易在错误空间里盲转。
文档驱动 integration
作者强调 AKG kernel agent 不是把 DSL / 硬件支持写死在系统里,而是通过 structured documents 接入:
- DSL 语法说明
- API references
- 硬件规格
- 优化指南
这意味着:
- 新目标平台不一定要改 agent 逻辑
- 更像是在“喂文档 + 接接口”
这对于跨平台 kernel synthesis 很关键。因为问题不在于 agent 会不会写代码,而在于它是否知道某平台有哪些原语、哪些限制、哪些优化习惯。
从这个角度看,文档在 AKG 里不只是辅助材料,而是第一类系统输入。
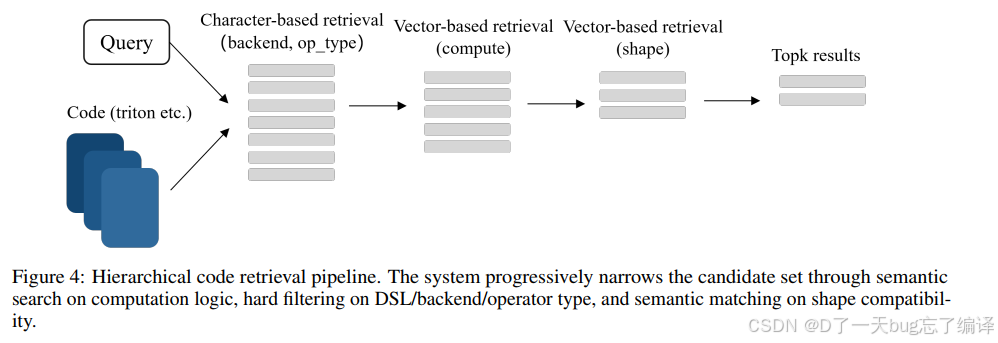
图 4 展示了 hierarchical code retrieval pipeline。
作者的检索流程不是简单 embedding 相似度,而是多阶段筛选:
1. 先让 LLM 提取任务特征
2. 再做 computation logic 的 embedding 匹配
3. 再按 DSL、backend、operator type 做硬过滤
4. 最后再做 shape-based semantic matching
这个设计比“直接语义相似度 top-k”更合理。
因为 kernel 代码的相似性很容易是假的:
- 语法像,不代表 operator 相同
- operator 相同,不代表 backend 相同
- backend 相同,不代表 shape / memory pattern 相同
作者正是想避免这种 superficial code similarity。
搜索优化部分
文章后面引入了 parallel search-based tuning。
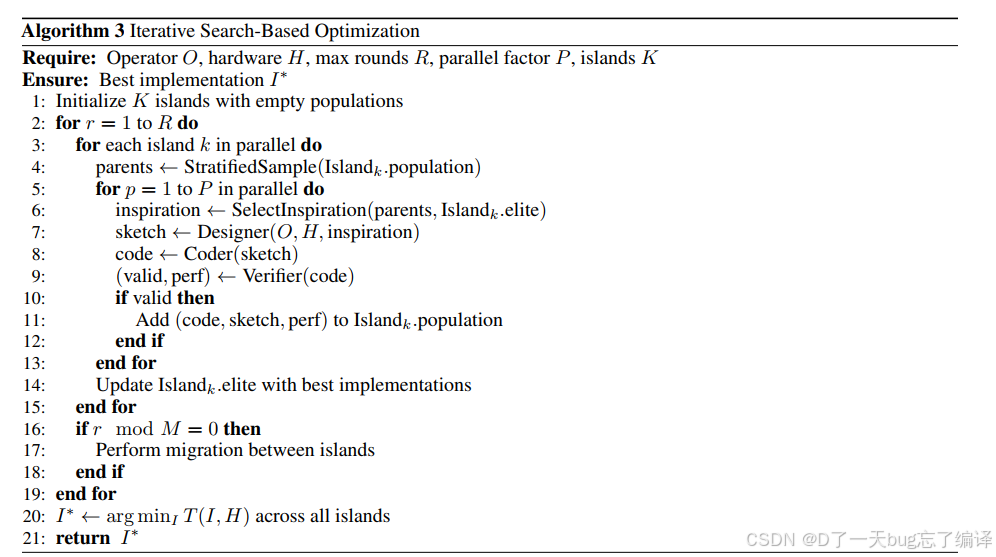
大致做法是:
- 每轮生成多个 candidate kernel
- 并行执行
- 收集性能数据
- 分析哪些方向更有希望
- 以最好候选为基线,进入下一轮
这看起来和很多 search-based codegen 有共性,但这里有个关键不同:
- 搜索的中心不是原始代码,而是围绕 Unified Sketch 进行的
也就是说,它并不只是对最终代码做局部 patch,而是可以让设计意图本身参与迭代。
这使得跨平台适配更自然,因为平台变化时,变的不只是“语法”,往往还包括“策略”。
benchmark
这篇文章不仅做系统,还自己做了 benchmark。
作者认为 prior benchmarks 有两个主要问题:
1. operator 多样性不够
很多 benchmark 过度集中在基础算子,低估了 fused ops 在真实系统中的重要性。
2. 存在 reward-hacking loopholes
一些 benchmark 允许模型通过投机方式过关,而不是真正学会写高质量 kernel。
因此他们构建了一个新的 benchmark:
- dynamic shapes:198 operators
- static shapes:214 operators
- 共分 8 个类别
其中最值得注意的是:它系统性纳入 dynamic shape 测试。
这点非常重要,因为真实生产环境中 kernel 不可能只面对固定形状。
三、实验
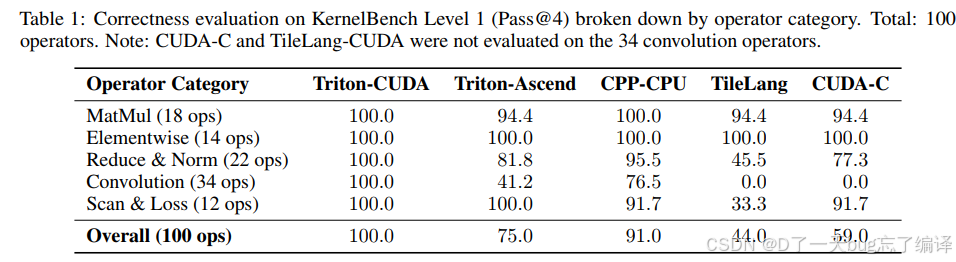
Table 1 给出了 5 种 DSL-backend 组合在 KernelBench Level 1 上的 Pass@4 结果:
- Triton-CUDA
- Triton-Ascend
- CPP-CPU
- TileLang
- CUDA-C
整体结果如下:
- Triton-CUDA:100.0%
- Triton-Ascend:75.0%
- CPP-CPU:91.0%
- TileLang:44.0%
- CUDA-C:59.0%
这里最亮眼的显然是 Triton-CUDA 100%。
但更值得注意的是 breakdown:
- Triton-CUDA 在 MatMul、Elementwise、Reduce&Norm、Convolution、Scan&Loss 上全都是 100%
- Triton-Ascend 在 Convolution 只有 41.2%
- TileLang 在 Reduce&Norm、Convolution、Scan&Loss 上很弱
这说明:
- AKG kernel agent 的多 agent 设计在 Triton-CUDA 这条线上已经非常成熟
- 但“跨平台”这件事并没有被完全解决,不同 DSL / backend 之间差距仍然很大
这点必须客观看待。
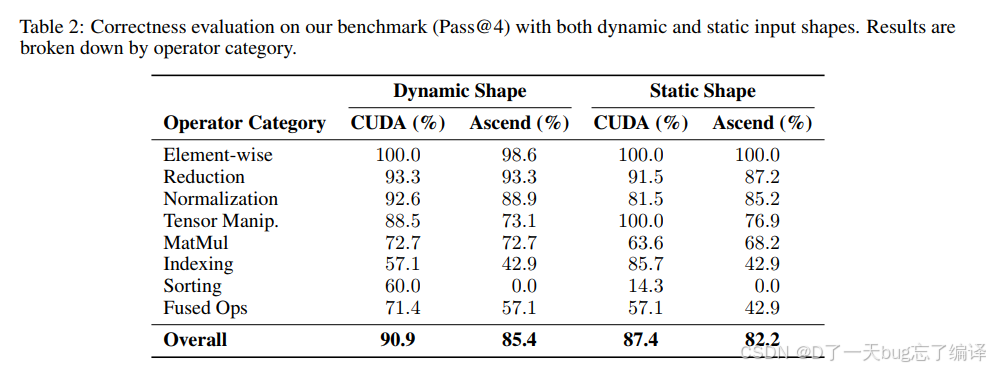
在作者自建 benchmark 上,结果是:
Triton-CUDA:
- dynamic:90.9%
- static:87.4%
Triton-Ascend:
- dynamic:85.4%
- static:82.2%
再看 breakdown,会发现几个关键点:
- Element-wise 基本接近满分
- Reduction / Normalization 也比较强
- MatMul 只有 63.6% 到 72.7% 这一区间
- Indexing 和 Sorting 明显更难
- Fused Ops 仍然比较有挑战
这组结果比 KernelBench Level 1 更有信息量,因为它说明系统真正难的不是基础 elementwise,而是:
- dynamic shape
- complex indexing
- sorting
- fused operations
也就是说,这篇文章的系统在“实用方向”上已经不错,但离全面成熟还有明显距离。
第一,Pass@4 不是 Pass@1。
也就是说系统可以试 4 次。这个指标在 codegen 里很常见,也合理,但不能和“一次生成就对”混为一谈。
第二,不同 backend 的成熟度明显不同。
Triton-CUDA 100% 很强,但 TileLang 和 CUDA-C 的结果明显低很多,这说明 document integration 和 multi-agent framework 并不能自动消除 DSL 生态差异。
所以这篇文章更准确的结论应该是:
- 多 agent + sketch + retrieval 显著提升了 cross-platform kernel synthesis
- 但不同平台的成功率仍 strongly dependent on target DSL/backend
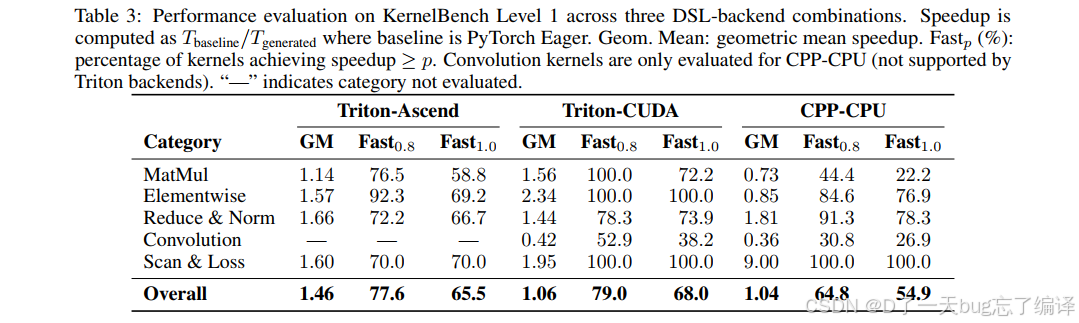
Table 3 给了 KernelBench Level 1 上三个组合的性能结果:
- Triton-Ascend
- Triton-CUDA
- CPP-CPU
overall geometric mean speedup 分别是:
- Triton-Ascend:1.46x
- Triton-CUDA:1.06x
- CPP-CPU:1.04x
这里可以看出一个很重要的事实:AKG kernel agent 的 correctness 成绩很亮眼,但性能上并不是“全面碾压”。
这其实是更可信的结果。
因为如果一篇文章同时在 correctness 和所有性能指标上都极端好,反而要小心。
这里作者给出的情况更符合真实世界:
- 某些类别上融合机会大,会有显著收益
- 某些类别上 baseline 本来就很强,LLM 生成的 kernel 只能接近它
- 某些类别上甚至会低于 baseline
从 Table 3 看:
- Triton-CUDA 在 Elementwise 上有 2.34x
- 在 Scan & Loss 上有 1.95x
- 在 MatMul 上有 1.56x
- Convolution 上只有 0.42x
Triton-Ascend:
- Reduce&Norm 1.66x
- Scan & Loss 1.60x
- MatMul 1.14x
CPP-CPU:
- Scan & Loss 居然能到 9.00x
- 但 MatMul 和 Convolution 明显低于 baseline
这和作者的解释是一致的:
- 对 Reduce&Norm、Scan&Loss 这类由多个小 operator 组成的模式,agent 生成的 fused kernel 很有优势
- 对 MatMul 这类已有高度优化 vendor library 支持的类别,最多做到接近或略超
- 对 Convolution 这类 Triton 先天支持不佳的场景,效果很一般甚至更差
这组结果其实很能说明系统的边界:AKG 更擅长“融合和结构重组”,不一定擅长“干翻成熟 vendor library”。
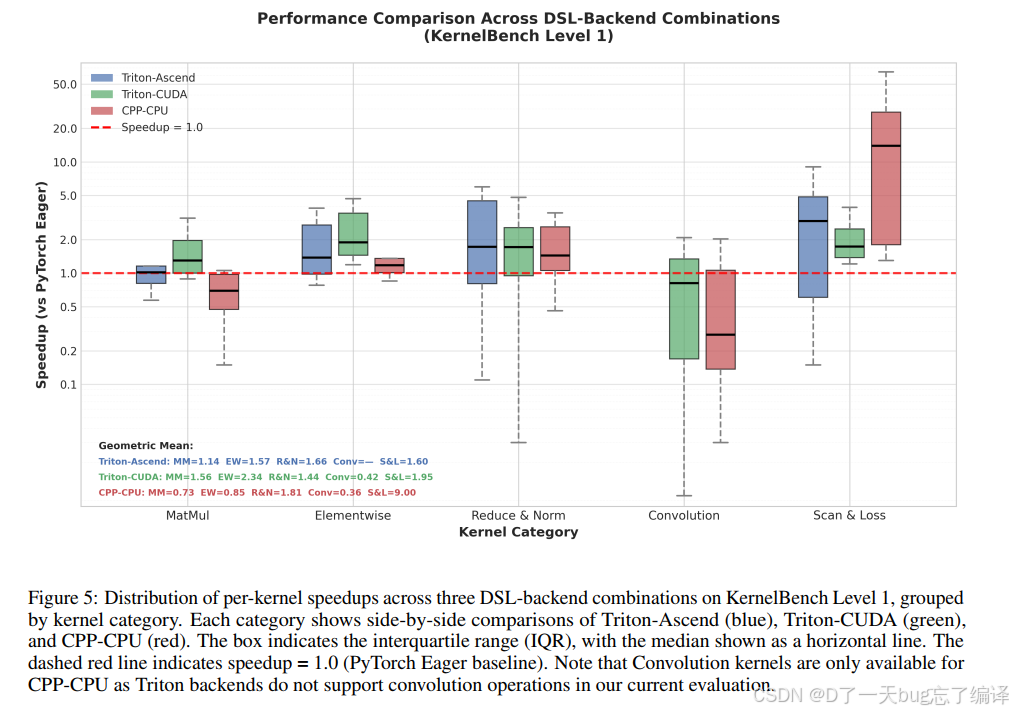
Figure 5 用箱线图展示不同类别 speedup 分布。
这张图的意义是:
- 不同 kernel category 的收益波动很大
- 同一 backend 内部也有明显长尾
这进一步说明 AKG kernel agent 不是一个“所有算子都平均快一倍”的系统,而是一个:
- 对某些模式很有效
- 对某些模式只够正确
- 对某些模式还不成熟

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)