CVPR 2026 | 中科院提出LTS-FS:精准打击LVLM幻觉,层级稀疏引导让模型更清醒

大语言模型(LLM)的火爆带飞了多模态大模型(Large Vision-Language Models, LVLMs),但“幻觉”问题始终是挥之不去的阴影。简单来说,就是模型对着图片“睁眼说瞎话”,比如图中明明没有猫,它却能描述得绘声绘色。为了解决这个问题,研究者们尝试了微调、对比解码等各种招数。最近,一种名为“特征引导(Feature Steering)”的方法因其不增加推理成本而备受关注。
然而,现有的特征引导方法往往采用“一刀切”的策略,对模型的所有层进行均匀调整。这就像是治病时不管哪里疼都全身用药,结果虽然压制了幻觉,却也误伤了模型的通用能力。
针对这一痛点,来自中国科学院大学、中国科学院计算技术研究所的研究团队提出了一种名为 LTS-FS 的新框架,Locate-Then-Sparsify for Feature Steering,意为“先定位、再稀疏化”的特征引导策略。它的核心思想非常直观:先找出模型中哪些层是产生幻觉的“罪魁祸首”,然后精准地只对这些层进行稀疏化的特征引导。

-
论文地址: https://arxiv.org/abs/2603.16284
-
录用会议: CVPR 2026
为什么“均匀引导”行不通?
在深入 LTS-FS 之前,我们先来看看传统方法的问题。目前的特征引导方法(如 Nullu)通常假设所有层对幻觉的贡献是均等的。但通过图 1 的可视化分析,我们可以清晰地看到这种做法的副作用。
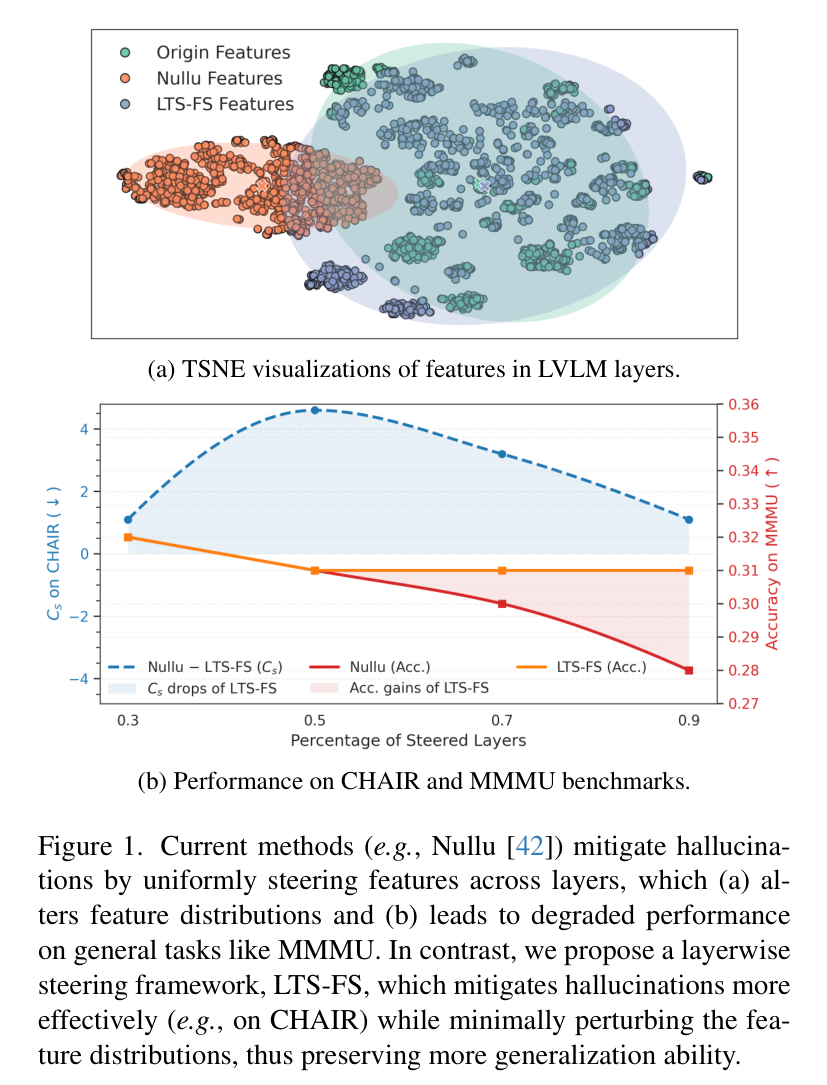
图 1 展示了传统方法与 LTS-FS 的对比。左侧 (a) 的 TSNE 可视化显示,传统方法(Nullu)显著改变了特征分布,而 LTS-FS 保持得更好;右侧 (b) 则显示 LTS-FS 在抑制幻觉的同时,在 MMMU 等通用任务上性能损失更小。
这种“过度干预”会导致模型在处理通用任务(如 MMMU 榜单)时表现大幅下滑。说白了,模型变“笨”了。研究者发现,均匀引导会剧烈扰动预训练模型的特征分布,导致模型在缓解幻觉的同时,丢失了原本强大的常识推理和细节感知能力。因此,如何实现精准的“靶向治疗”成了抑制幻觉的关键。
LTS-FS:三步走实现精准抑制
LTS-FS 框架的设计主要分为三个阶段:构建双粒度数据集、定位幻觉相关层、实施层级稀疏引导。
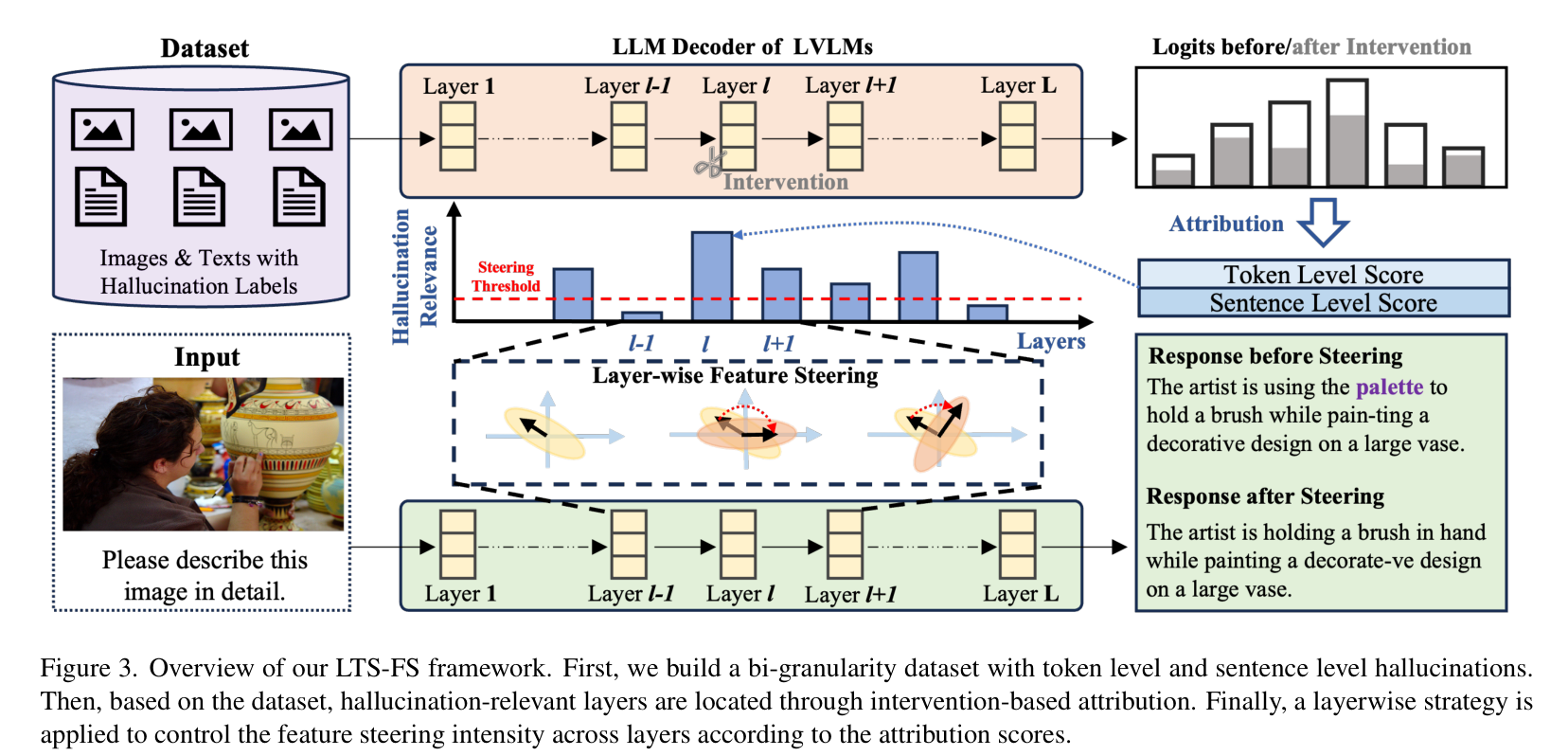
图 3 展示了 LTS-FS 框架的整体流程。
1. 构建双粒度数据集
研究者发现,幻觉在不同长度的文本中表现不同。在短句中,幻觉通常表现为某个错误的词(Token 级);而在长文本描述中,则可能出现整句的捏造(句子级)。
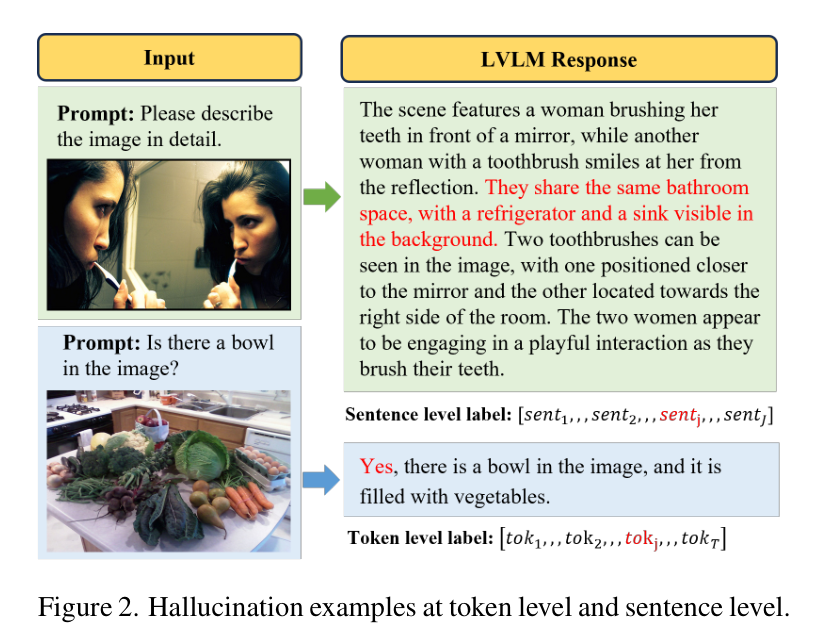
图 2 展示了 Token 级和句子级幻觉的示例。
为了覆盖这些情况,作者构建了一个包含这两种粒度幻觉样本的数据集。这些数据并不是用来微调模型的,而是作为“探针”,用来观察模型内部的反应。
2. 寻找“幻觉层”:因果归因分析
这是 LTS-FS 最核心的步骤,其输入是带有幻觉标记的图像-文本对,输出是每一层对幻觉贡献的归因得分。作者引入了一种基于因果干预(Causal Intervention)的归因方法。
具体来说,对于模型中的每一层 ,研究者会依次“遮蔽(Mask)”掉其多头注意力(Multi-Head Attention, MHA)的输出,观察模型输出幻觉词概率的变化。如果遮蔽掉某一层后,模型输出幻觉的概率显著下降,那么这一层就被认为是“幻觉相关层”。
归因得分 的计算公式如下:
其中 是针对第
个注意力头的掩码。对于句子级幻觉,作者还设计了三种加权指示器:
-
提示词指示器(Cue indicator):关注如“此外(additional)”或句号等容易触发幻觉的总结性词汇。
-
位置指示器(Position indicator):考虑到句子越往后,模型越容易受先前生成内容的干扰而产生幻觉。
-
幻觉指示器(Hallucination indicator):直接对已识别的错误词汇赋予更高权重。
通过这种加权聚合,LTS-FS 能够精准定位到那些真正诱发错误信息的隐层。
3. 层级稀疏引导策略
找到了关键层后,接下来就是如何“用药”了。LTS-FS 并没有采用全层一致的引导强度,而是提出了一个“硬掩码 + 软加权”的策略:
-
硬掩码(Hard Sparsification):设定一个阈值
,只有归因得分高于这个值的层才会被调整,其余层保持原样。这确保了 只有幻觉相关层 会受到干预。
-
软加权(Soft Weighting):在选中的层中,根据得分的高低动态调整引导强度
。得分越高,说明该层对幻觉的贡献越大,引导强度也就越强。
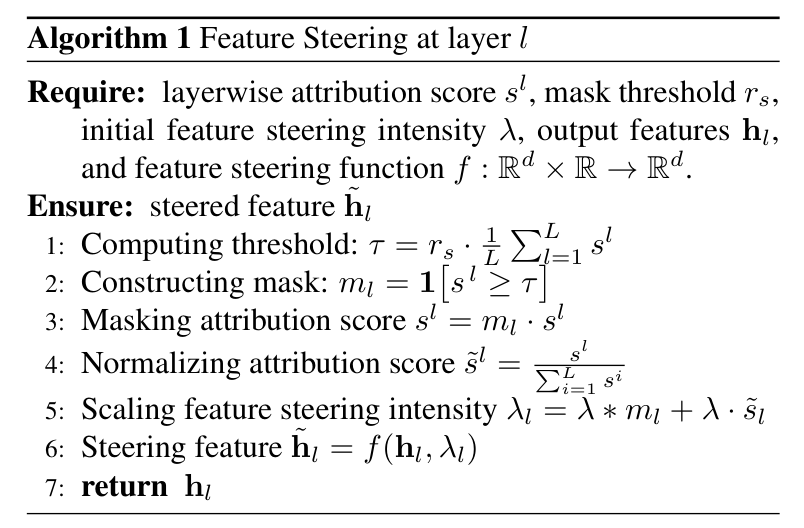
算法 1 详细描述了层级特征引导的计算流程。
这种做法最大限度地保护了那些与幻觉无关、但对通用认知至关重要的模型层。
实验结果:既要“清醒”也要“聪明”
研究团队在 LLaVA-v1.5 和 Qwen-VL2.5 等主流模型上进行了广泛测试。
1. 幻觉抑制性能
在衡量物体幻觉的经典指标 CHAIR 上,LTS-FS 表现惊人。
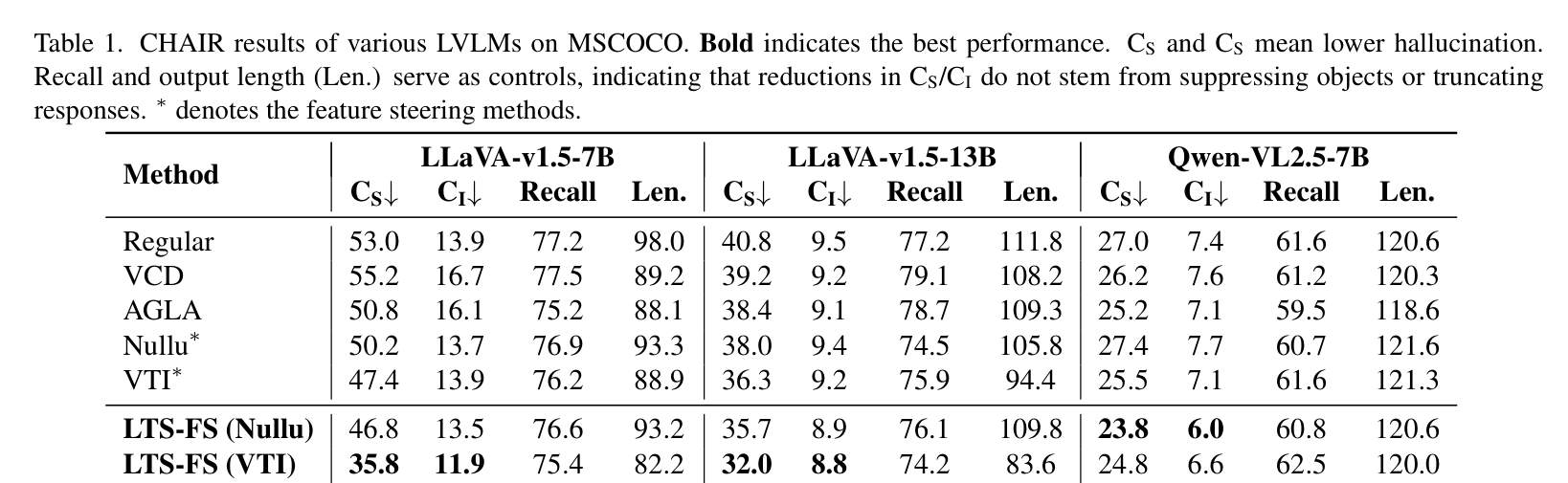
表 1 显示,在 LLaVA-v1.5-7B 上,结合了 VTI 的 LTS-FS 将 指标从 53.0 降低到了 35.8,远优于原始方法。
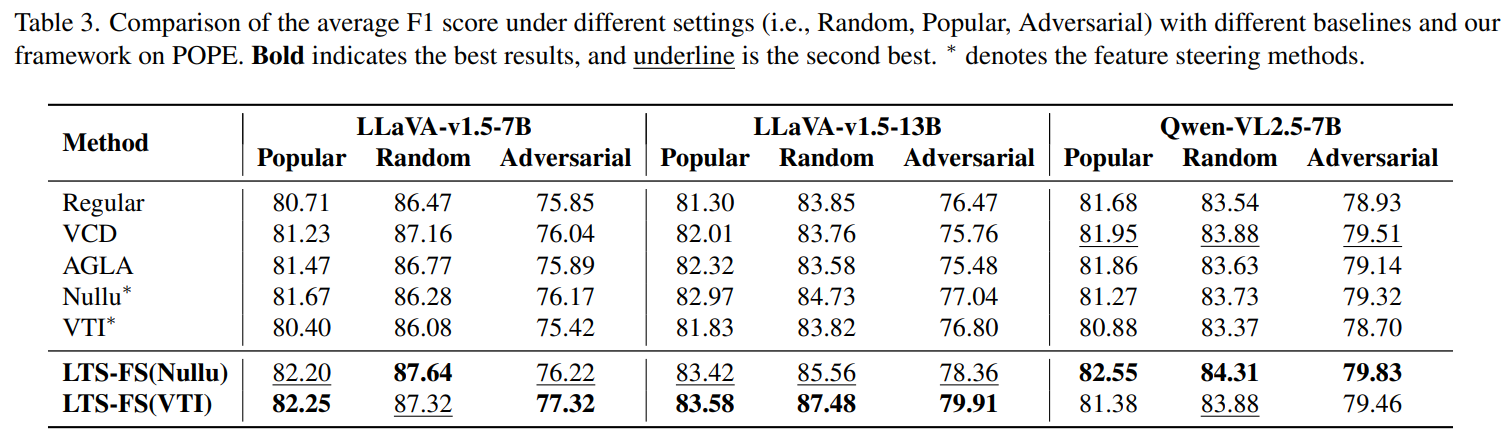
在 POPE 问答基准测试中,LTS-FS 同样在准确率(Accuracy)和 F1 分数上全面超越了现有的 SOTA 方法。例如在 LLaVA-v1.5-13B 上,准确率提升了约 2%到5%。
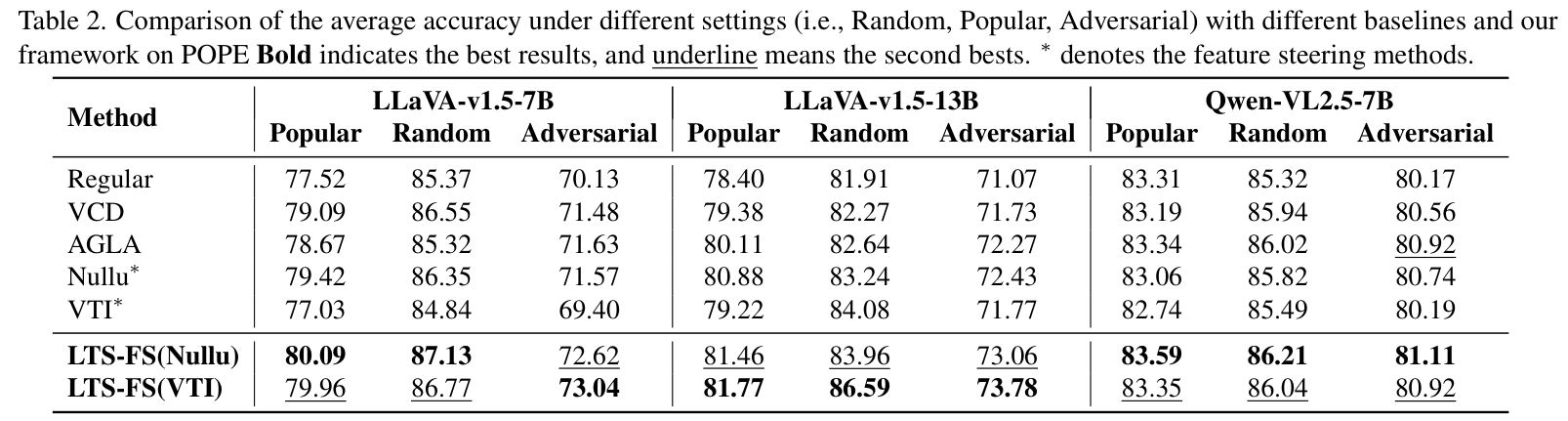
表 2 和表 3 展示了在 POPE 上的优异表现。
2. 通用能力保持
最令人欣慰的是,LTS-FS 真的做到了“不伤身”。在 MME 综合能力评估中,LTS-FS 不仅在感知任务上表现更好,在认知任务上也保持了极高的水准。
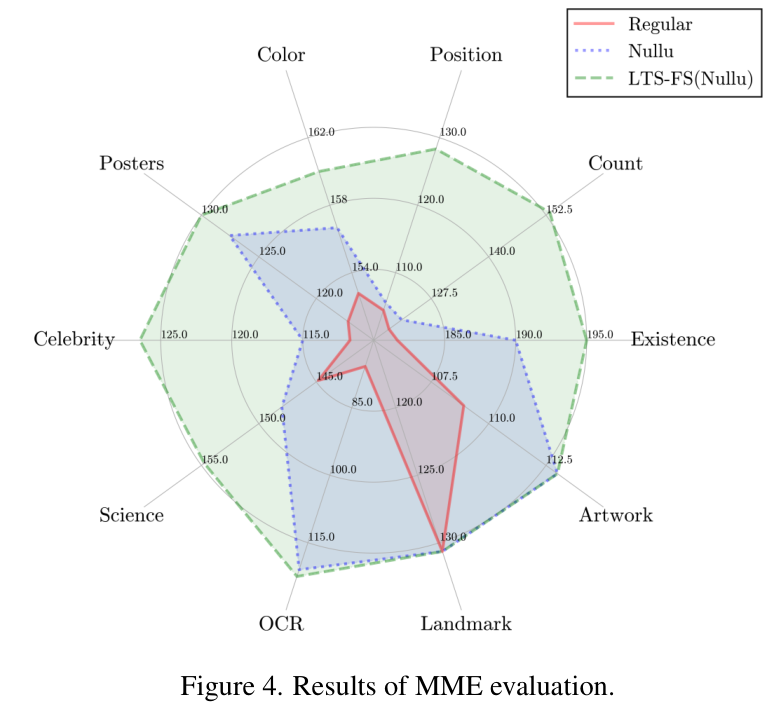
图 4 显示 LTS-FS 在 MME 上的总分显著高于 Nullu 等对比方法。
3. 直观对比
从图 5 的案例对比中可以直观感受到 LTS-FS 的威力。面对“三明治”和“船上的情侣”等场景,传统方法可能会臆造出“海盗船”、“海盗帽”等不存在的细节,而 LTS-FS 的描述则非常忠实于原图,且细节丰富。

图 5 展示了 LLaVA-Bench 上的定性对比结果。
写在最后
LTS-FS 的成功向我们展示了一个深刻的洞察:在大模型中,并非所有层都是平等的。针对特定缺陷(如幻觉)进行治理时,这种“先定位、再稀疏化”的思路比盲目的全局调整要高效得多。
这种方法不仅是即插即用的(可以配合 Nullu 或 VTI 使用),而且推理成本几乎没有增加。虽然前期定位层需要一定的离线计算开销(约 1.5 小时),但这是一次性的投入,换来的是模型在推理阶段 零额外延迟 的可靠性。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)