我们未曾察觉的 - 快速排序
Kernel” 一词常令人联想到操作系统内核(OS kernel),但此处的kernel 并非指操作系统,而是指大型算法内部被反复调用的、固定尺寸的极小运算单元。2023 年,AI 系统 AlphaDev 所改进的对象,正是这类固定大小的 kernel。具体而言,被优化的是名为sort3sort4sort5的小型排序核函数——它们分别用于对3个、4个、5个元素进行排序。AlphaDev 在这些核中

基础算法,如排序与哈希,每天被调用的次数高达数万亿次。随着计算需求不断增长,确保这些核心例程尽可能高效,变得愈发关键。尽管过去已取得显著进展,但进一步提升此类例程的效率,对人类研究者与计算方法而言,始终是一项艰巨挑战。本研究证明:人工智能有能力超越现有最先进水平,发现此前未知的新型例程。为此,我们将“寻找更优排序例程”的问题形式化为一个单人游戏,并训练了一种新型深度强化学习智能体——AlphaDev 来求解该游戏。AlphaDev 从零开始发现了若干小型排序算法,其性能优于人类专家设计的基准实现;其中部分算法已被整合进 LLVM 标准 C++ 排序库。这意味着:标准库中某一关键组件,已被一个通过强化学习自动发现的算法所取代。此外,本研究还展示了该方法在其他领域的应用成果,证实了其普适性。
--Faster sorting algorithms discovered using deep reinforcement learning. Nature(2023)
在正式展开之前
在算法教科书中,排序通常被视为“已解决的问题”。Timsort、pdqsort、introsort 等混合算法早已历经数十年优化,而标准库中的代码更是经过领域专家反复审校的结晶。
然而,2023 年,谷歌 DeepMind 的 AlphaDev 打破了这一认知前提。它所发现的并非全新的算法,而是在既有的 sort3 内核中——仅删除一条指令所形成的精简指令序列。正是这“一行”改动,已被正式采纳并集成至 LLVM 的 libc++ 库中。
本文旨在阐明:这一发现为何意义非凡。
而要理解这一点,我们必须从快速排序(Quick Sort)讲起。
(快速排序动画示意)
快速排序(Quick Sort)的基本结构
快速排序是一种分治法(divide and conquer)算法,其运作原理非常简洁:
- 从数组中选取一个基准元素(pivot);
- 将小于 pivot 的元素移到左侧,大于 pivot 的元素移到右侧——此步骤称为 partition(分区);
- 对左、右两个子数组递归地重复上述过程。
用代码表示如下:
void quicksort(int* arr, int lo, int hi) {
if (lo >= hi) return;
int pivot_idx = partition(arr, lo, hi);
quicksort(arr, lo, pivot_idx - 1);
quicksort(arr, pivot_idx + 1, hi);
}实现 partition 的方式有多种;以 Lomuto 方案 为例:将 pivot 固定在数组最右端,然后从左向右遍历,将所有小于等于 pivot 的元素依次“前移”至左侧区域。
int partition(int* arr, int lo, int hi) {
int pivot = arr[hi];
int i = lo - 1;
for (int j = lo; j < hi; j++) {
if (arr[j] <= pivot) {
i++;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[hi]);
return i + 1;
}其平均时间复杂度为 O(n log n)。这是因为:若每次分区都能将近似将数组均分为两半,则递归深度为 log n,而每层需 O(n) 时间完成一次分区。
最坏情况与 pivot 选择问题
快速排序的弱点在于 pivot 的选取策略:分区后左右子数组越均衡,性能越好;越偏向一侧,性能越差。
最坏情况发生在每次 pivot 都恰好是当前子数组的最小值或最大值时——此时一侧子数组长度恒为 0,递归深度退化为 n,时间复杂度降至 O(n²)。
典型触发该最坏情形的输入包括:
- 对已排序数组,且始终选取第一个元素作为 pivot;
- 对逆序数组,且始终选取最后一个元素作为 pivot;
- 所有元素完全相同的情况。
在朴素快速排序实现中,“已排序输入反而最慢”这一现象看似违反直觉,但正因如此,标准库绝不能容忍这种脆弱性。
早期的应对方案之一是采用随机 pivot:通过随机选取 pivot,可将最坏情况发生的概率大幅降低。但该方法需额外开销生成随机数,且并未彻底消除最坏情况——仅将其变为“低概率事件”。
median-of-3 策略
int median_of_3(int* arr, int lo, int hi) {
int mid = lo + (hi - lo) / 2; // 避免 lo + hi 溢出 INT_MAX(C++ 中此差异可能导致实际 bug)
if (arr[lo] > arr[mid]) std::swap(arr[lo], arr[mid]);
if (arr[lo] > arr[hi]) std::swap(arr[lo], arr[hi]);
if (arr[mid] > arr[hi]) std::swap(arr[mid], arr[hi]);
return mid;
}(注:此处使用
lo + (hi - lo) / 2而非(lo + hi) / 2,是为了防止lo + hi超出int表示范围导致溢出——在 C++ 中,该细节确曾引发真实 bug。)
一种更实用的替代方案是 median-of-3:取数组首、中、尾三个元素的中位数作为 pivot
该策略显著缓解了对已排序或逆序数组的敏感性——因为三者中的中位数更可能接近整个数组的真实中位数。
更重要的是,它带来了一个关键副作用(side effect):在选出中位数的过程中,这三个元素已被两两比较并调整顺序,从而提前完成了局部排序。当分区完成后,这三个元素通常恰好位于子数组边界处,后续递归调用中无需再处理它们——这实质上降低了分区操作的实际成本。
自 1970 年代 Sedgewick 系统性地提出并分析该策略以来,median-of-3 已成为实用型快速排序实现的事实标准。
彻底消除最坏情况 - IntroSort
即便采用 median-of-3 策略, 也无法完全消除最坏情况。面对极端输入(如重复构造的对抗性数据),仍可能触发 O(n²) 时间复杂度。
为彻底解决该问题,1997 年 David Musser 提出了 IntroSort(内省排序):一种将快速排序与堆排序相结合的混合算法。
其运作机制如下:
- 追踪递归深度,阈值通常设为
2 × log₂(n); - 若当前递归深度 未超阈值,则继续使用快速排序(配合 median-of-3 pivot 选择);
- 若递归深度 超过阈值,则立即切换至堆排序。
由于堆排序始终保证 O(n log n) 时间复杂度, IntroSort 可在检测到快排即将陷入最坏情形时及时“兜底”,从而全局保障最坏时间复杂度为 O(n log n)。
此外,还有一项关键优化:当子数组长度降至某一临界值(通常 ≤16)时,改用插入排序。原因在于:
- 小规模数据下,插入排序的常数因子远小于快排;
- 插入排序具有更好的缓存局部性(cache-friendly)。
static constexpr int THRESHOLD = 16;
void introsort(int* arr, int lo, int hi, int depth_limit) {
if (hi - lo < THRESHOLD) {
insertion_sort(arr, lo, hi);
return;
}
if (depth_limit == 0) {
heap_sort(arr, lo, hi);
return;
}
int pivot_idx = median_of_3(arr, lo, hi); // 先选 pivot(注意:此处应先调用 median_of_3 调整位置,再 partition)
pivot_idx = partition(arr, lo, hi); // 实际分区
introsort(arr, lo, pivot_idx - 1, depth_limit - 1);
introsort(arr, pivot_idx + 1, hi, depth_limit - 1);
}
void sort(int* arr, int n) {
int depth_limit = 2 * static_cast<int>(std::log2(n));
introsort(arr, 0, n - 1, depth_limit);
}注:C++ STL 中的
std::sort即基于 IntroSort 实现;GCC 的 libstdc++ 与 LLVM 的 libc++ 均遵循此架构
那么,作者为何要详述这些背景?
因为——在持续二十余年、看似已“终结”的问题上,AI 于 2023 年给出了全新解法。
要理解 AI 到底发现了什么, 我们需先厘清一个关键概念:
什么是 “Kernel”(核/核心例程)?
“Kernel” 一词常令人联想到操作系统内核(OS kernel),但此处的 kernel 并非指操作系统,而是指大型算法内部被反复调用的、固定尺寸的极小运算单元。
2023 年,AI 系统 AlphaDev 所改进的对象,正是这类固定大小的 kernel。
具体而言,被优化的是名为 sort3、sort4、sort5 的小型排序核函数——它们分别用于对 3个、4个、5个元素进行排序。AlphaDev 在这些核中,找到了比人类专家手写最优实现指令更少、效率更高的指令序列——即:剔除了冗余操作,实现了更精简的实现。
换言之,AI 并非发明了新算法, 而是在已有框架下,挖出了被长期忽略的微小优化空间。
各级排序核的定义与作用
sort1:处理 1 个元素 → 实际无操作;sort2:处理 2 个元素 → 仅需 1 次比较 + 1 次条件交换;sort3:处理 恰好 3 个元素 的固定尺寸核 → 无循环、无递归,仅靠若干次比较与条件交换完成排序。
这些 kernel 既可独立调用, 更常见的是作为大型排序算法(如 std::sort)的内部构建模块被高频复用。
为何聚焦 sort3?
sort3 是一个输入长度严格为 3 的固定尺寸排序例程:
- 不处理任意长度数组;
- 长度在编译期即确定;
- 完全由比较(compare)与条件交换(conditional swap)构成,无分支循环。
它虽小,却至关重要——例如:
- IntroSort 在执行 median-of-3 pivot 选择时,直接调用
sort3对首、中、尾三元素排序; - 当子数组缩小至阈值以下(如 ≤16),进入插入排序阶段时,仍会反复调用
sort2–sort4等小核来处理局部 2~4 元素块。
因此,sort3 绝非“玩具级小排序”,而是大型排序算法反复依赖的核心原子操作。
因其调用频次极高(每秒可达数十亿次),哪怕仅节省 1 条汇编指令,在系统级累积效应下也能带来显著性能提升——这正是 AlphaDev 的突破所在。

(a)用于对最多包含两个元素的输入序列进行排序的可变长度排序函数的 C++ 实现。
(b)上述 C++ 代码会被编译为如下低级汇编表示形式。
- 那么,这与快速排序有何关联?
我们先回顾快速排序的实现逻辑:
在 IntroSort 的两个关键环节中,都需要对小规模数组执行排序操作:
- median-of-3 pivot 选择阶段:需对首、中、尾三个元素排序 → 这正是
sort3; - 递归底层切换至插入排序时:插入排序本身在内部会反复对 2~4 个元素进行比较与局部排序。
若用生活化类比:就像在班级里排队——两人比较身高,矮者前移、高者后退,反复迭代直至排好序。
那么,人类程序员是如何编写这类小规模排序逻辑的呢?
要理解这一点,我们需先掌握一点汇编语言基础。
汇编语言基础:阅读代码前的必备知识
汇编语言是 CPU 直接执行的指令级语言。它没有 C 或 Python 中的变量、函数调用等抽象结构,而是通过寄存器(register)与指令直接操作数据。
- 寄存器是 CPU 内部的极小临时存储单元,数量有限(如 x86-64 中有
rax,rbx,rcx等),所有运算必须经由寄存器完成。
为简化说明,本文将通用寄存器为 P, Q, R, S。
以下为本文涉及的四条核心指令:
|
指令 |
含义 |
示例 |
|---|---|---|
|
|
将 B 的值复制到 A |
|
|
|
比较 A 与 B,结果写入标志位(flags),不修改原值 |
|
|
|
若上一 |
|
|
|
若上一 |
|
其中 cmovg(conditional move if greater)与 cmovl(conditional move if less)属于条件移动指令:它们可在无分支跳转(no branch)的前提下完成“if-else”逻辑,从而避免因分支预测失败(branch misprediction)带来的性能损耗——这对高频比较的排序算法尤为重要。
举例说明标志位如何工作:
cmp P, R ; 比较 P 与 R,设置 flags
cmovg P, R ; 若 P > R,则 P = R → 此时 P = min(P, R)
cmovl R, S ; 若 P < R,则 R = S → 此时 R = max(P, R)这两行实际实现了:
P = min(A, C),R = max(A, C)(假设初始 P=A, R=C)
掌握以上机制后,我们便能逐行解读下方 sort3 的汇编实现。
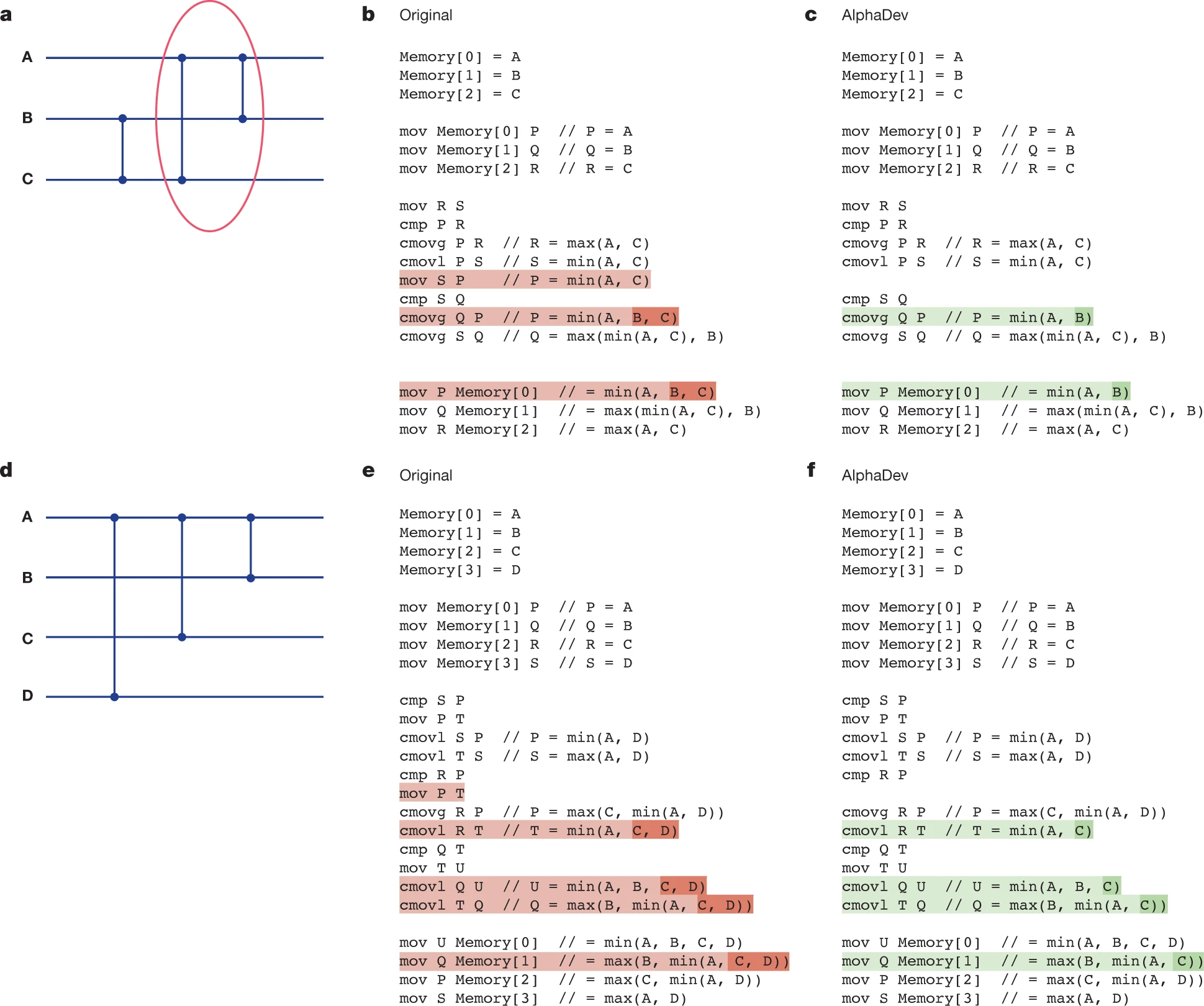
人类编写的 sort3(3 元素排序)
以 x86 架构为例,对三个元素 A、B、C 排序的汇编流程如下(使用寄存器 P, Q, R, S):
; 初始状态:P = A, Q = B, R = C
mov R, S ; S ← C (保存原始 C)
cmp P, R ; 比较 A 与 C
cmovg P, R ; P ← min(A, C)
cmovl R, S ; R ← max(A, C)
mov S, P ; S ← min(A, C) ← 关键步骤!
cmp S, Q ; 比较 min(A,C) 与 B
cmovg Q, P ; 若 min(A,C) > B,则 Q ← P → 即 Q = min(A,B,C)
cmovg S, Q ; 若 min(A,C) > B,则 S ← Q → 即 S = 中间值其中 mov S, P 的作用非常明确:
前一步已将 min(A, C) 存入 P,但下一步需将其与 B 比较——为避免覆盖 P 导致信息丢失,人类习惯显式地将中间结果暂存到 S,再继续后续计算。
这种风格体现了人类编程的典型思维:
- 显式保存中间状态
- 分步清晰、便于调试与验证
- 局部逻辑易于理解
虽稍显冗余,却极大提升了代码的可读性与可靠性
(为便于理解,下文将通过具体数值示例进一步说明该流程)
示例:全班按身高排队
老师指定一名学生作为基准(pivot);
其余学生中,比该基准矮的站到左边,高的站到右边。
一轮排序结束后,被指定为 pivot 的学生位置即固定下来。
接着,在左组与右组中重复相同过程——直到每组仅剩一人。
这正是快速排序的核心思想:
每轮确定一人位置; 剩余人员不断被划分为更小的子组,直至完成全部排序。
而在快速排序内部:
当老师选择 pivot 时,候选者仅有三人——队首、队中、队尾。
老师需从中选出身高居中者作为 pivot。
为此,必须先将这三人按身高排好序——这一操作,就是 sort3
老师将三人排好后,会在黑板上记录:“中间那位是 pivot;且三人顺序已确定。”
这条记录成为后续全局排序的前提条件
当子组缩小至三人或更少时,sort3 会被再次调用。
在整个全班排序过程中,sort3 实际上在递归树的几乎所有层级都会被执行。
那么 AI 是如何做的呢?
AlphaDev 发现的代码
AlphaDev 的优化结果如下:
; 初始状态:P = A, Q = B, R = C
mov R, S ; S ← C
cmp P, R ; 比较 A 与 C
cmovg P, R ; P ← min(A, C)
cmovl R, S ; R ← max(A, C)
; mov S, P ← 此行被删除!
cmp S, Q ; S 仍为原始 C,与 B 比较
cmovg Q, P ; 条件移动
cmovg S, Q ; 条件移动关键变化:mov S, P 被彻底移除。
此时 S 仍保存着原始的 C,而非 min(A, C)——从局部看,这似乎是个错误,逻辑难以理解。
(原文论文中出现的代码与图像)
为何删掉它依然正确?
因为这段代码并非独立运行的完整函数; 它是嵌入在 Sorting Network(排序网络)中的一个片段。
排序网络由一系列比较器(comparator)按固定顺序连接而成。每个比较器接收两个输入,输出较小值与较大值。其关键特性在于:前序比较器的输出会约束后续比较器的输入条件——即存在隐含的“不变式”(invariant)。
AlphaDev 的代码所处上下文中, 前序比较器已保证 B ≤ C 成立。
在此前提下,分析将完全不同:
- 删除
mov S, P后,S仍为C; - 由于
B ≤ C已成立,cmp S, Q(即C与B比较)的结果方向早已确定; - 在此约束下, 后续两条
cmovg所生成的最终三值输出,与保留mov S, P时完全一致。
逐阶段追踪寄存器状态如下:
|
步骤 |
P |
Q |
R |
S |
前提条件 |
|---|---|---|---|---|---|
|
初始 |
A |
B |
C |
– |
B ≤ C |
|
|
A |
B |
C |
C |
|
|
|
min(A,C) |
B |
C |
C |
|
|
|
min(A,C) |
B |
max(A,C) |
C |
|
|
|
— |
— |
— |
— |
C ≥ B 已成立 |
|
|
min(A,B,C) |
B |
max(A,C) |
C |
|
|
|
min(A,B,C) |
中间值 |
max(A,C) |
中间值 |
→ 最终输出:P = min, Q = median, R = max,与原实现完全等价。
表面上看,局部代码“出错”了;但若将整个排序网络的不变式纳入考量,它反而是正确的。
《Nature》论文将此类优化命名为 AlphaDev swap-move。
如何用前面的“班级排队”类比理解?
这次我们只考虑三人排队:A、B、C。
- 人类做法:
先比较 A 与 C,排好顺序,并在黑板上写下:“当前最前者 = min(A,C)”。
然后依据这条笔记,再让 B 与该“最前者”比较,最终确定三人顺序.
→ 必须显式记录中间结果,才能安全推进下一步. - AI(AlphaDev)的做法:
但在这个班级里,上课前老师已在黑板上写明:“B 比 C 矮”(即B ≤ C已为公理)。
教师知晓此事实,因此在比较完 A 与 C 后,无需再抄写“min(A,C)”——可直接利用黑板上的既有信息,跳过记录步骤,立即进入下一比较。
最终排队结果丝毫不差。
AlphaDev 删除的那一行 mov S, P,正是那块多余的黑板笔记。
人类程序员习惯性地“为保险起见”写下中间状态;
而 AlphaDev 则精准识别出:前序步骤已隐含保障了所需前提,因而果断省去冗余操作——以极简指令达成同等正确性。
这正是 AI 在底层优化中展现的、超越人类直觉的“系统级洞察力”。

《自然》(Nature)论文指出,这些例程每天被执行数万亿次(trillions of times -这绝非夸张。全球服务器上运行的 C++ 程序、数据库引擎、网络协议栈、文件系统等,无一例外都会调用 std::sort。
换言之:
每次调用 std::sort 时,sort3 都会在递归树的几乎所有内部节点中被触发。对一个含 n 个元素的数组排序,其递归树的内部节点数量为 O(n);而每个内部节点均会调用一次 sort3,因此整个排序过程中 sort3 的执行次数也与 O(n) 成正比。
由此看来,“每天数万亿次”的说法 - 确凿无疑
为何人类始终未能发现这一优化?
因为人类习惯局部地验证代码:
- “若跳过某次比较,后续步骤将失去安全保障”;
- “必须先显式整理中间状态,才能安全进入下一步”。
这种思维模式极大提升了代码的可读性与可验证性,也使我们能轻松理解局部逻辑。
但 AlphaDev 不受此限制。
它将整个寄存器状态的转移过程视为搜索空间,仅以两个条件作为判断依据:
- 最终输出的三个值是否构成有效排序;
- 所用指令总数是否最小。
通过将每条汇编指令建模为一个“动作”(action),并将排序正确性与指令数量设为强化学习的奖励函数(reward),AlphaDev 实现了对该空间的高效探索
利用整个算法所保障的全局不变式(global invariant),剔除仅用于“局部整理”的冗余复制操作——这一优化,在该搜索框架下实属水到渠成。
人类数十年来习以为常的那一行代码之所以被删除,根本原因在于:搜索粒度的不同

(哥伦布的鸡蛋)
结语
此项发现的核心意义,并不在于 AI 比人类“更聪明”。
真正关键的是:搜索单元的差异。
- 人类思维是局部的:依赖中间状态显式记录,逐层安全验证;
- AlphaDev 的搜索是全局的:只关心最终输出是否满足排序约束、指令数是否最少。
正是这一差异, 导致人类数十年来视作理所当然的那一行代码,最终被抹去.
换言之,我们曾深信不疑的某些“标准代码模式”,未必源于问题本质,而更可能是为适配人类认知与验证习惯而固化下来的惯性。
AlphaDev 用一个微小案例,有力证实了这一点。
这恰如“哥伦布的鸡蛋”——
答案揭晓后,人人皆言“不过如此”;
但真正艰难的,是从无人质疑的前提中,首次敢于将其打破。
AlphaDev 所展现的,并非更高超的“手艺”,而是这样一种可能性:
我们习以为常的结构,可以用全新的搜索方式重新审视。
如今,我们不仅拥有基于人类认知习惯的思维方式, 更获得了一种全新的搜索工具——AI.
至于是否应将此称为“智能”,我个人仍持审慎态度。
但有一点毋庸置疑:
当那些我们早已视为“天经地义”的惯例,开始被如此方式逐一瓦解时——
它带给我们的,是一种真切而深刻的智性震撼。
参考文献:
Mankowitz, D. J., Michi, A., Zhernov, A., Gelmi, M., Selvi, M., Paduraru, C., Leurent, E., Iqbal, S., Lespiau, J.-B., Ahern, A., Köppe, T., Millikin, K., Gaffney, S., Elster, S., Broshear, J., Tsing, A., Polosukhin, I., Pikhtin, A., Sifre, L., Singh, S., … Silver, D. (2023). Faster sorting algorithms discovered using deep reinforcement learning. Nature, 618(7964), 257–263. https://doi.org/10.1038/s41586-023-06004-9

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)