论文解读:Adam定律揭示大模型最爱高频词
先把最基础的问题回答清楚:句子频率是什么,怎么算?直觉上,你能感受到"The cat sat on the mat"和"The feline reposed upon the textile floor covering"之间的差距——前者用的全是高频常见词,后者像在写学术论文。句子频率 = 句子中每个词频率的几何平均。公式写出来是:其中 wfreq 是词级频率,K 是句子的词数,D 是参考语料。
AI性能的天花板,是由数据决定的。
这句话,每个人都知道。但"好数据"的定义,长期以来只有三个维度:准确、丰富、无噪声。
没有人认真追问过第四个维度——当数据语义完全相同,只是措辞不同时,哪个更好?
这个问题,被整个社区沉默地忽视了好几年。直到一支来自FaceMind Corporation和香港中文大学的团队,把它做成了一篇有理论、有实验、有完整系统的工作,命名为"Adam's Law"——亚当定律。
他们的核心发现,用一句话说完就是:把同一道数学题换成更常见的说法,LlaMA3.3-70B的准确率从80.49%涨到了88.75%。
不改模型,不改题目,只改措辞。
1. 数据质量的一个盲区
你有没有想过,Prompt的措辞,会影响大模型的推理结果?
不是指令是否清晰的问题——是在指令语义完全一致的前提下,用"常见词汇"写成的提示,和用"生僻词汇"写成的提示,会让模型产生不同的输出。
这件事,Cao等人(2024)在NeurIPS上发过一篇关于"最差提示性能"的研究,证明了它真实存在。但那篇工作揭示的是现象,没有给出为什么,更没有给出怎么系统性地解决它。
同样,Oh等人(2024)发现大模型更擅长预测常见词——罕见词对模型来说是更难的预测任务。但这个发现,停留在词级别,没有延伸到句子级别,更没有变成可操作的方法论。
这就是这篇研究要填补的缺口。
它提出的框架由三个组件构成:
-
TFL(文本频率定律):语义相同时,高频表达的文本应该优先选用
-
TFD(文本频率蒸馏):用目标LLM自身来校准频率估计
-
CTFT(课程式文本频率训练):按频率从低到高的顺序对数据排序微调
三个缩写,一个核心命题是AI更喜欢、熟悉的语言。
研究团队由FaceMind Corporation的Hongyuan Adam Lu(第一作者)带领,联合香港中文大学信息工程系的Bowen Cao和Wai Lam完成。Wai Lam在自然语言处理领域深耕多年;Bowen Cao本人就曾深入研究过提示措辞对LLM性能的影响——这个选题,对这支团队来说是一次有机的延伸,而不是偶然的跨界。
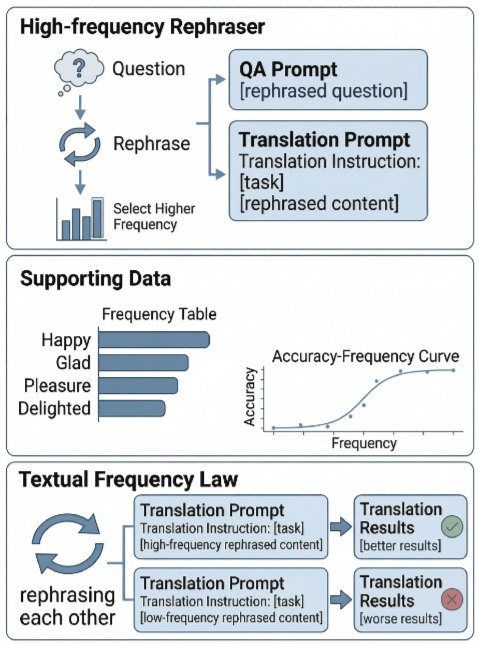
全局框架示意图
2. 频率怎么定义?——从词到句的估计框架
先把最基础的问题回答清楚:句子频率是什么,怎么算?
直觉上,你能感受到"The cat sat on the mat"和"The feline reposed upon the textile floor covering"之间的差距——前者用的全是高频常见词,后者像在写学术论文。
这篇研究把这种直觉形式化:句子频率 = 句子中每个词频率的几何平均。
公式写出来是:
其中 wfreq 是词级频率,K 是句子的词数,D 是参考语料。
这个公式的关键设计是"几何平均"而不是"算术平均"——因为几何平均对极低频词更敏感:一个超生僻词,会把整个句子的频率拉低一大截。就像一根木桶的短板,决定了整桶水的高度。
更重要的是:这个计算不需要目标LLM的训练数据。用开源词频资源(这篇研究用的是基于Zipf分布的wordfreq工具,背后有ParaCrawl等大规模语料支撑)就能完成估计。
这解决了一个实践中的巨大障碍——GPT-4o-mini、DeepSeek-V3的训练数据是闭源的,你根本不知道它们"见过什么"。但词级频率的估计不依赖这些,一样可以用。
当然,这只是估计,不是精确测量。公开词频资源和目标模型的真实训练分布之间,存在偏差。
于是有了第二个组件——TFD。
3. 文本频率蒸馏:让模型告诉你它更熟悉什么
TFD(Textual Frequency Distillation,文本频率蒸馏)的思路,非常直接:
既然我们不知道目标LLM的训练数据,那就让目标LLM用自己的语言风格生成数据,把生成的文本作为新的参考语料来校准频率估计。
这就像你想搞清楚一个人平时爱说什么话——与其翻遍他的所有聊天记录,不如直接让他自由发言录一段音,分析他开口说的词就行了。
具体操作:给模型一段数据集中的文本,让它做"故事补全"(story completion)——生成一段延续。这些模型自发产生的续写,天然反映了模型更习惯使用的词汇分布。
把补全生成的文本组成新语料D',重新计算频率:
最终频率是原始估计和蒸馏估计的加权组合:
这里的ζ是一个"强化系数"——当某个词在原始估计里频率接近零时,说明它几乎没出现过,这时候就把蒸馏估计的权重额外放大,弥补原始估计的失灵区域。
TFD的效果,随数据量单调递增。
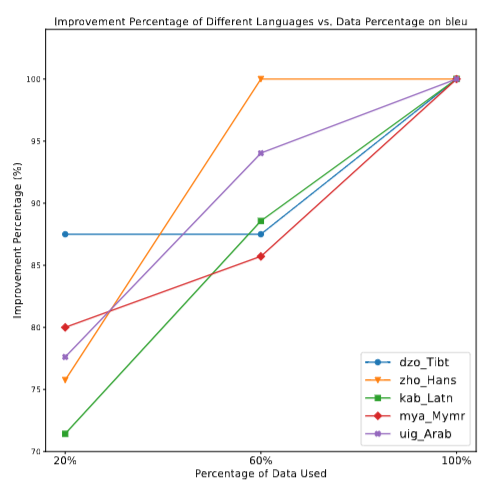
图1
图1展示了这一规律:在5种低资源语言上,用20%的数据做TFD时提升最弱,用100%时提升最强。没有出现边际递减的迹象——在这篇研究测试的范围内,数据越多,TFD就越准。
消融实验给出了更直接的数字。在DeepSeek-V3上,使用TFD vs 不使用TFD:
-
BLEU胜率:96.7% vs 3.3%
-
chrF胜率:100.0% vs 0.0%
-
COMET胜率:100.0% vs 0.0%
TFD不是可选项,是框架效果的关键来源。
4. 课程式文本频率训练:排序也是一门学问
解决了"选哪个",接下来的问题是:微调时,数据按什么顺序喂给模型?
CTFT(Curriculum Textual Frequency Training,课程式文本频率训练)给出的答案,反直觉——从低频到高频。
等等,不应该是"从简单到难"吗?
这里有一个微妙的区别。
传统课程学习(Easy-to-Hard)里的"简单",指的是任务复杂度——比如句子句法结构的复杂程度。CTFT里的"低频",指的是词汇使用的罕见程度。低频词汇更多样、更不确定——对模型来说,它们确实是"难"的;高频词汇是模型最熟悉的领域,在这里表现最稳定。
先让模型见识多样性,再强化熟悉地带。
这个思路,在机器翻译的微调实验上,给出了惊人的结果。
图2展示了在四个低资源语言上的翻译实验(kea_Latn卡布维尔迪语、kik_Latn基库尤语、pag_Latn邦板牙语、lvs_Latn拉脱维亚语):
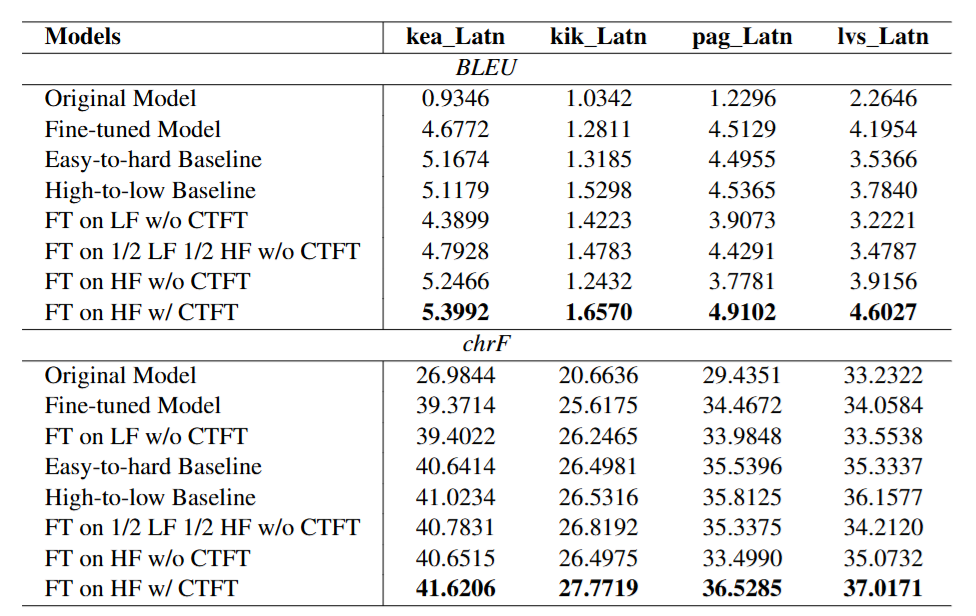
图2
| 方案 | pag_Latn BLEU |
|---|---|
| 原始模型 | 1.23 |
| 普通微调(原始数据) | 4.51 |
| 高频微调(无CTFT) | 3.78 |
| 高频微调(有CTFT) | 4.91 |
高频数据配合CTFT,从3.78到4.91——提升**29.96%**。
对比之下,反向排序(高频→低频)的基线,比CTFT差,但也比随机顺序稍好。这说明排序方向是有意义的——不是随意选的,而是有规律可循的。
8项实验指标(4个语言 × 2个评测)中,CTFT拿下全部8项最优。这不是运气,这是一致的规律。
5. TFPD:一个从零开始构建的配对数据集
做这些实验,首先面临一个问题:根本没有现成的数据集——每道题同时有高频版本和低频版本,且语义严格一致的那种。
研究团队从三个主流数据集出发:
-
GSM8K:数学推理(1319个测试样本)
-
FLORES-200:机器翻译(1012个dev-test样本)
-
CommonsenseQA:常识推理
用GPT-4o-mini,给每个样本生成20个改写版本——10个"更常见的表达",10个"更生僻的表达"。从中选出最高频和最低频各一个,送给三位有英语语言学背景的专业标注员做人工审核:只保留三人都认定语义相同的样本对。
最终得到738对数学推理样本、526对翻译样本、575对常识推理样本、114对工具调用样本,统称TFPD(Textual Frequency Paired Dataset)。
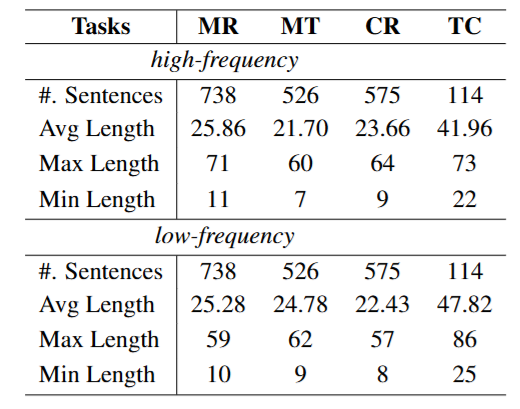
图3
图3的统计数据显示,高频和低频版本的平均句子长度差异很小(数学推理:25.86词 vs 25.28词;翻译:21.70词 vs 24.78词)——排除了"句子长度"这个混淆变量。
这个数据集本身,就是这篇研究对社区的贡献之一。
6. 实验结果:跨任务、跨模型、跨语言的全面验证
一句话概括:在所有任务、所有模型、所有语言上,高频文本输入都更好。
数学推理
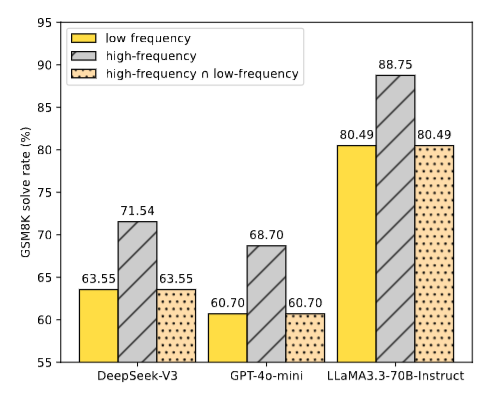
图4
图4是最直观的一张图。三个主流模型,高频vs低频分区的准确率对比:
-
DeepSeek-V3:63.55% → **71.54%**(+7.99pp)
-
GPT-4o-mini:60.70% → **68.70%**(+8.00pp)
-
LlaMA3.3-70B-Instruct:80.49% → **88.75%**(+8.26pp)
还有一个细节更值得注意:研究者计算了"两个版本都答对"的交集。发现当低频版本答对时,高频版本必然也答对。换句话说,高频输入只挽救了原本答错的样本,没有损坏任何原本正确的答案。
这是净收益,不是此消彼长的零和游戏。
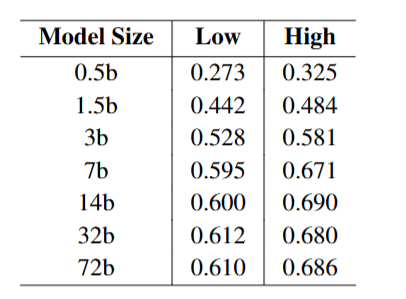
图5
图5验证了规律的鲁棒性:从0.5b到72b规模的全系列qwen2.5模型,高频分区一致优于低频分区。规律不随模型大小失效。
机器翻译(100个语言对)
这是这篇研究规模最大的实验——在100个语言对上,用两个翻译模型(DeepSeek-V3和GPT-4o-mini)、三个评测指标(BLEU、chrF、COMET)做全面测试。
DeepSeek-V3在BLEU分(机器翻译的词匹配精度评分)上:99/100个语言对得到改善,改善超过3分的有31个,超过5分的有12个。唯一下降的那一个,下降幅度不到1分。
chrF分(基于字符n-gram的评分,比BLEU对词形变化更鲁棒)的结果更强:DeepSeek-V3 100/100语言对全部改善。
COMET(基于神经网络的评测模型,更贴近人工判断,支持37种语言):DeepSeek-V3全胜,GPT-4o-mini 36/37改善。
GPT-4o-mini的BLEU结果略弱但方向一致:95/100改善,5个下降均不超过1分。
100个语言里超过一半是"低资源语言"(class 0或class 1)。TFL在资源匮乏语言上同样有效——这是这条定律跨越语言壁垒的重要信号。
常识推理和工具调用

图6
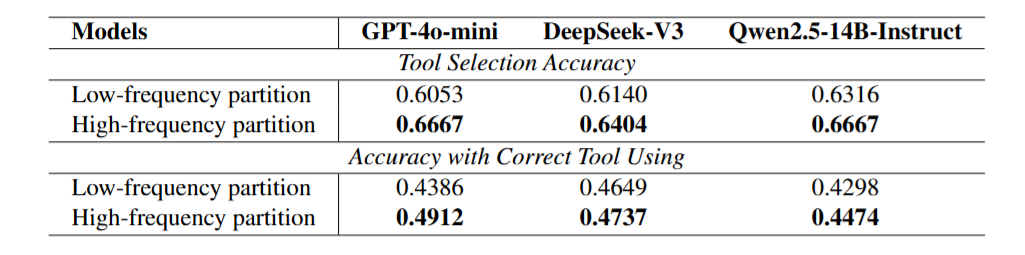
图7
图6(常识推理)和图7(工具调用)同样支持TFL:
-
常识推理:GPT-4o-mini 67.47% → 69.74%;LlaMA3.3-70B 75.30% → 77.04%
-
工具调用:工具选择准确率,GPT-4o-mini 60.53% → 66.67%;DeepSeek-V3 61.40% → 64.04%
规律覆盖数学推理、翻译、常识问答、工具调用——四类任务无一例外。
7. 这不是"简单文本更好"的老结论
一个合理的质疑:TFL的效果,是不是本质上等于"简单文本效果更好"?高频词汇,通常就是更简单的词,这有什么新鲜的?
表5给出了明确回答:不是。
研究者计算了三个文本复杂度指标(最大依存树深度、平均依存距离、Flesch-Kincaid可读性等级),然后测量了它们与翻译最终性能的相关性。
结果:Pearson相关系数最高才0.27,多数情况下低于0.1。
而文本频率与最终性能的相关性,在部分语言上高达1.0。
频率的预测力,远超文本复杂度。两者不是同一个维度。
表6的控制实验进一步确认了这一点:把高频和低频样本按句法树深度差异分组,控制复杂度变量之后,在绝大多数分组里,高频Prompt依然更好。
只有一个例外区间[50%-55%],低频稍好——但这个区间只有21个样本,而且仅在BLEU和chrF上,COMET不支持这一结论。统计噪声的嫌疑大于规律性的反例。
频率,是独立于复杂度之外的第四个数据维度。
8. 数学证明:定律背后的理论基础
这篇研究没有满足于"实验说明一切"。附录里,作者给出了一个形式化的数学证明,把TFL从经验观察提升为有理论根基的定律。
证明分两层:
Token级别(定理1):先从一个基础事实出发——自然语言里词的出现频率,遵循Zipf定律(一种幂律分布:排名第1的词,频率是排名第2的词的2倍,是第3的词的3倍……以此类推),高频词极少,低频词极多。
基于这个分布,每个token的NLL损失——负对数似然(Negative Log-Likelihood),也就是模型预测某个词时的"不确定性",用负的对数概率来衡量——与其频率排名之间,存在半对数线性关系。公式写出来:
, 其中
其中s是Zipf指数,r是词的频率排名,C是常数,ε(r)是模型的逼近误差。排名越高(r越大,频率越低),损失越大——这是单调递增的关系。高频词(r小)的误差项ε(r)也更小,因为训练时见过的样例更多,梯度信号更充分,模型预测得更稳。
句子级别(定理3、4):对句子的平均条件NLL损失做分解,可以证明:
,其中误差总量
当高频句和低频句的频率比足够大(超过两者误差项之和)时,高频句的损失严格更低——这就是文本频率定律的充分条件。
这个证明最有意思的地方在于:误差项在句子的K个token平均后,会以√K的速度缩小。实际需要的频率差距,远小于理论上的充分条件——定律在实践中比理论更容易满足。
有了理论支撑,TFL就不只是"我们发现了一个有趣现象"——它是Zipf定律在语言模型训练中的自然推论。
9. 项目总结
过去我们理解AI训练数据,看的是三件事:准不准、够不够多、噪声多不多。
文本频率定律打开了第四扇门:表达多常见。
这意味着什么?意味着同样的训练预算,选高频表达的数据,能免费获得额外提升。意味着Prompt工程不只是"把指令写清楚",还包括"把措辞写常见"。意味着从数学推理到机器翻译,从英语到百余种语言,都有一个此前被遗忘的性能空间等待挖掘。
未来值得关注的方向有三个:
第一,实时高频改写系统——把用户输入自动转换为高频表达,无感嵌入现有应用,提升所有下游任务的准确率。
第二,极低资源语言的深度探索——100个语言的实验已经验证了TFL的跨语言稳定性,但对于class 0类语言(几乎没有数字化资源),频率估计的准确性本身就是挑战。
第三,TFL与对齐方法的结合——RLHF、DPO等对齐训练阶段,高频数据选择能否同样发挥作用?这是一个尚未触碰的开放问题。
如果说过去我们对AI训练数据的理解,是"好数据就是对的数据",那么这篇研究展示的,是"好数据还要是熟悉的数据"——第一块揭开数据频率维度的基石。
论文标题: Adam's Law: Textual Frequency Law on Large Language Models
论文地址: https://arxiv.org/pdf/2604.02176
作者简介: 本文由FaceMind Corporation与香港中文大学(The Chinese University of Hong Kong)联合完成。第一作者为FaceMind Corporation的Hongyuan Adam Lu,与Z.L.同列等贡献(Equal Contribution);共同作者还包括FaceMind Corporation的Victor Wei、Zefan Zhang、Zhao Hong、Qiqi Xiang,以及来自香港中文大学的Bowen Cao和Wai Lam。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)