Python科学计算基础包numpy
目录
2.zeros()、ones()、empty()与zeros_like()、ones_like()、empty_like()
4.广播的手动控制:np.newaxis 与 reshape
一.什么是numpy
numpy是Python中科学计算的基础包。它是一个Python库,提供多维数组对象、各种派生对象(例如掩码数组和矩阵)以及用于对数组进行快速操作的各种方法,包括数学、逻辑、形状操作、排序、选择、I/O 、离散傅里叶变换、基本线性代数、基本统计运算、随机模拟等等。
numpy的部分功能如下:
- ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
- 用于对整组数据进行快速运算的标准数学函数(无需编写循环)。
- 用于读写磁盘数据的工具以及用于操作内存映射文件的工具。
- 线性代数、随机数生成以及傅里叶变换功能。
- 用于集成由C、C++、Fortran等语言编写的代码的API(所以这个库计算效率很高)。
二.numpy的安装
我的环境是Windows下的一般Python环境,不自带常用库,所以我就直接命令行安装。
pip install numpy如网络不稳定,可能会安装不成功,这时候多试几次或者科学上网吧。
三.ndarray的限制
大多数numpy数组都有一些限制:
- 数组的所有元素必须具有相同的数据类型。
- 一旦创建,数组的总大小就不能改变。
- 形状必须是“矩形”,而不是“锯齿状”。也就是二维数组的每一行必须具有相同的列数。
四.ndarray的属性
ndarray,一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。它有一些属性,下面先用代码进行展示:
import numpy as np
a = np.array([[1,2,3], [4,5,6]]) # 创建一个2行3列的二维数组
print(a)
print(f'{a.ndim}维') # 维度(ndim == ndarray dimension)
print(f'表示几行几列:{a.shape}') # 形状
print(f'{a.size}个') # 元素个数
print(f'默认64位8字节的int:{a.dtype}') # 数据类型(dtype == data type)
print(f'每个元素字节数大小:{a.itemsize}') # 每个元素字节数大小控制台输出如下:

五.ndarray的创建方式
1.array()与asarray()
array():将输入数据转换为ndarray,会进行copy。
asarray():将输入数据转换为ndarray,如果输入本身是ndarray则不会进行copy。
第一段代码如下:
import numpy as np
# array()
data = [1, 2, 3] # 创建一个列表(也就是C中的数组)
print(f'data的地址为:{id(data)}') # id(一个对象)可以获取这个对象的地址
arr1 = np.array(data)
print(f'arr1的地址为:{id(arr1)}')
arr2 = np.asarray(data)
print(f'arr2的地址为:{id(arr2)}')运行结果:

可见3个对象的地址都不一样,也就是说,无论用array()还是asarray()将一个列表转换为ndarray时都发生了copy,更准确地说是深拷贝。很容易理解,一个数据结构(列表)构造另一个数据结构(ndarray)肯定是要发生深拷贝的。
第二段代码如下:
import numpy as np
# asarray()
data = np.ndarray([1, 2, 3]) # 创建一个ndarray
print(f'data的地址为:{id(data)}') # id(一个对象)可以获取这个对象的地址
arr1 = np.array(data)
print(f'arr1的地址为:{id(arr1)}')
arr2 = np.asarray(arr1)
print(f'arr2的地址为:{id(arr2)}')运行结果:

data与arr的地址不同,array()在将一个ndarray转换为另一个ndarray时任然默认发生深拷贝。arr1和arr2的地址相同,这里asarray()在将一个ndarray转换为另一个ndarray时仅仅发生了浅拷贝,或者说arr2引用arr1,或者说arr1和arr2共享内存。
第三段代码如下:(仅比第二段多了个“copy=False”)
import numpy as np
# asarray()
data = np.ndarray([1, 2, 3]) # 创建一个ndarray
print(f'data的地址为:{id(data)}') # id(一个对象)可以获取这个对象的地址
arr1 = np.array(data, copy=False)
print(f'arr1的地址为:{id(arr1)}')
arr2 = np.asarray(arr1)
print(f'arr2的地址为:{id(arr2)}')运行结果:

此时,三个对象的地址都相同,也就是说我们可以设置“copy=False”令array()在将一个ndarray转换为另一个ndarray时具有和asarray()一样的效果。但如果是array()将一个列表转换为一个ndarray时设置“copy=False”,将会报错,因为这时候不深拷贝不合理。
2.zeros()、ones()、empty()与zeros_like()、ones_like()、empty_like()
zeros():返回给定形状和类型的新数组(ndarray),用0填充。
ones():返回给定形状和类型的新数组(ndarray),用1填充。
empty():返回给定形状和类型的未初始化的新数组(ndarray)。
需要注意的是,np.empty 并不保证数组元素被初始化为 0,它只是分配内存空间,数组(ndarray)中的元素值是未初始化的,可能是内存中的任意值。
上述3个方法创建的数组元素类型默认都是float64。
zeros_like():返回与给定数组具有相同形状和类型的0新数组(ndarray)。
ones_like():返回与给定数组具有相同形状和类型的1新数组(ndarray)。
empty_like():返回与给定数组具有相同形状和类型的未初始化的新数组(ndarray)。
代码如下:
import numpy as np
a = np.zeros((2, 3)) # 创建2行3列的全0 ndarray
print(a)
b = np.ones_like(a) # 创建与a形状相同的全1 ndarray
print(b)
c = np.empty((3, 4)) # 创建3行4列的未初始化的 ndarray
print(c)
d = np.empty_like(c) # 创建与c的形状相同的未初始化的 ndarray
print(d)输出结果:
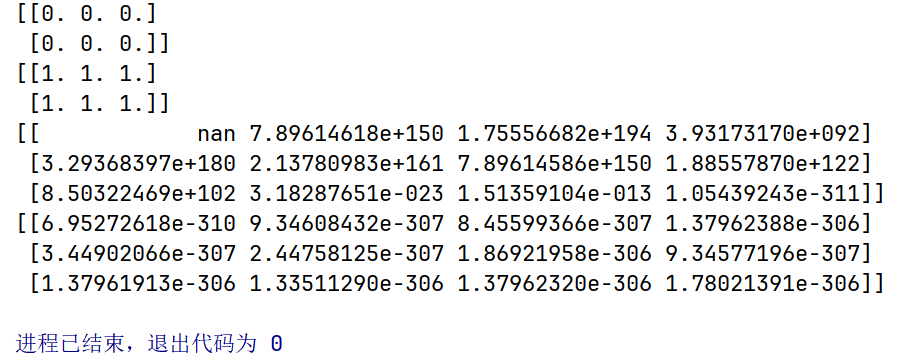
注意:这里元素间的分隔符是空格,而不是小数点 。
我们也可以设置数据类型为int或者其它类型:
import numpy as np
a = np.zeros((2, 3), dtype='i') # 创建2行3列的全0 ndarray
print(a)输出结果如下:

数据类型会在本文后面具体讲解。
3.full()与full_like()
full():返回给定形状和类型的新数组(ndarray),用指定的值填充。
full_like():返回与给定数组具有相同形状和类型的用指定值填充的新数组(ndarray)。
import numpy as np
a = np.full((2, 3), dtype='i', fill_value=5)
# 或者不加数据类型直接写成 a = np.full((2, 3), 5)
print(a)
b = np.full_like(a, 7)
print(b)运行结果:

4.arange()
arange():返回在给定范围内用均匀间隔的值填充的一维数组(ndarray)。
a = np.arange(0, 10, 2)
print(a)运行结果:

5.linspace()与logspace()
linspace():返回指定范围和元素个数的等差数列。数组(ndarray)元素类型为浮点型。
logspace():返回指定指数范围、元素个数、底数的等比数列。
import numpy as np
# 0到10范围内均分为5个数的ndarray
arr1 = np.linspace(0, 10, 5)
print(arr1)
# 设置endpoint=False,表示不包括stop
arr2 = np.linspace(0, 10, 5, endpoint=False)
print(arr2)
# 2到5之间均分为5个数作为指数:2 2.75 3.5 4.25 5
arr3 = np.logspace(2, 5, 5, base=2)
print(arr3)输出结果:

默认endpoint=True时
如果把0到10看作一条线段,相当于用5个点将这条线段分成了4段,要计算每段的长度(即相邻元素的间隔),用总长度 (stop - start) 除以段数 (num - 1) ,得到间隔为 10-0 / 4 = 2.5。这样从起始点 0 开始,每次加上间隔 2.5 就能依次得到序列中的元素:0、2.5、5、7.5、10 。
若 endpoint=False 的情况
当 endpoint=False 时,意味着 stop 这个值不包含在生成的序列中,此时 [start, stop) 区间相当于一条右端点空心(不包含 stop 这个点)的线段。我们在这条线段上放置 num 个点进行划分,每一个点都会划分出一个新的区间段。比如,放 1 个点会把线段分成 1 段,放 2 个点会分成 2 段,放 num 个点就会分成 num 段,段数就等于点数 num,计算间隔的公式就变为 (stop - start) / num 。
这里详细说一下arr3的输出结果,如注释:2到5之间均分为5个数作为指数:2 2.75 3.5 4.25 5。2的2.75次方 == 6.72717132,2的3.5次方 == 11.3137085,2的4.25次方 == 19.02731384。这样就非常清楚了嘿嘿。
6.创建随机数数组
random.rand():返回给定形状的数组(ndarray),用 [0, 1) 上均匀分布的随机样本填充。
random.randint():返回给定形状的数组(ndarray),用从低位(包含)到高位(不包含)上均匀分布的随机整数填充。
random.uniform():返回给定形状的数组(ndarray),用从低位(包含)到高位(不包含)上均匀分布的随机浮点数填充。
random.randn():返回给定形状的数组(ndarray),用标准正态分布(均值为0,标准差为1)的随机样本填充。
代码如下:
import numpy as np
a = np.random.rand(2, 3)
print(a)
b = np.random.randint(2, 8, (3, 4))
print(b)
c = np.random.uniform(3, 7, (3, 4))
print(c)
d = np.random.randn(2, 3)
print(d)运行结果:

均匀分布是最简单的连续概率分布:在一个指定区间 [a, b] 内,所有取值的概率密度完全相等,就像 “抽签” 一样,区间内每个位置被抽到的机会均等。
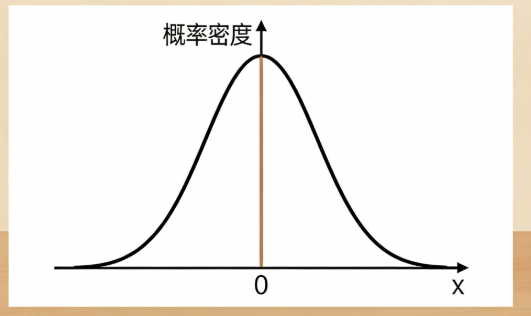
正态分布(高斯分布)是自然界最常见的连续概率分布,标准正态分布是正态分布的特例:均值 μ=0,标准差 σ=1。
标准正态分布N(0,1)概率密度曲线:
7.matrix()
matrix为ndarray的子类,只能生成二维的矩阵。
代码如下:
import numpy as np
a = np.matrix("1 2; 3 4")
print(a)
b = np.matrix([[5, 6], [7, 8]])
print(b)运行结果:

六.ndarray的数据类型
|
数据类型 |
类型代码 |
说明 |
|
bool |
? |
布尔类型 |
|
int8、uint8 int16、uint16 int32、uint32 int64、uint64 |
i1,u1 i2,u2 i4,u4 i8,u8 |
有符号、无符号的8位(1字节)整型 有符号、无符号的16位(2字节)整型 有符号、无符号的32位(4字节)整型 有符号、无符号的64位(8字节)整型 |
|
float16 float32 float64 |
f2 f4或f f8或d |
半精度浮点型 单精度浮点型 双精度浮点型 |
|
complex64 complex128 |
c8 c16 |
用两个32位浮点数表示的复数 用两个64位浮点数表示的复数 |
创建数组时可以使用dtype参数指定元素类型:
import numpy as np
arr1 = np.array([1, 2, 3], dtype=np.float64)
print(arr1)
arr2 = np.array([0.2, 2.5, 4.8], dtype="i8")
print(arr2)运行结果:
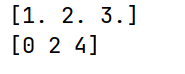
也可以使用ndarray.astype()方法转换数组的元素类型:
import numpy as np
arr1 = np.array([1, 2, 3])
print(arr1)
arr2 = arr1.astype(np.int64)
print(arr2)运行结果:
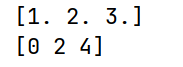
需要注意,ndarray默认为浮点型。
七.ndarray切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
可以通过内置的slice函数,或者冒号设置start, stop及step参数进行切片,从原数组中切割出一个新数组。
代码如下:
import numpy as np
arr = np.arange(10)
print(arr)
# 获取索引为2的数据
print(arr[2])
# 从索引 2开始到索引9(不包含)停止,间隔为2
print(arr[slice(2, 9, 2)])
# 从索引2开始到索引9(不包含)停止,间隔为2
print(arr[2:9:2])
# 从索引2开始到最后(不包含),默认间隔为1,这里的最后指的是索引10,所以输出里会包含9
print(arr[2:])
# 从索引2开始到索引9(不包含)结束,默认间隔为1
print(arr[2:9])运行结果:

八.numpy常用函数
1.基本函数
|
函数 |
说明 |
|
np.abs() |
元素的绝对值,参数是 number 或 array |
|
np.ceil() |
向上取整,参数是 number 或 array |
|
np.floor() |
向下取整,参数是 number 或 array |
|
np.rint() |
银行家四舍六入五成双算法: 四舍六入:当需要舍入的数字小于 5 时,直接舍去;当需要舍入的数字大于 5 时,进位。 五成双:当需要舍入的数字恰好是 5 时,会看 5 前面的数字,如果是偶数则直接舍去 5,如果是奇数则进位。 普通四舍五入会让0.5 的情况全部进位,长期统计下会产生系统性的正偏差(结果整体偏大)。 银行家舍入法让 0.5 的情况一半进位、一半舍去,长期统计下偏差会相互抵消,更适合科学计算、金融统计等场景,这也是 NumPy 默认用它的原因。 |
|
np.isnan() |
判断元素是否为NaN(Not a Number) ,参数是 number 或 array |
|
np.multiply() |
元素相乘,参数是 number 或 array。如果第二个参数传递的是number,原数组中所有元素乘以这个数字,返回新的数组;如果第二个参数也是一个数组,是将两个数组中对应位置的元素相乘,返回一个新的数组,其形状与输入数组相同。(不是线性代数中的乘法) |
|
np.divide() |
元素相除,参数是 number 或 array(不是线性代数中的除法) |
|
np.where(condition, x, y) |
三元运算符,x if condition else y |
代码如下:
import numpy as np
arr = np.random.randn(2, 3)
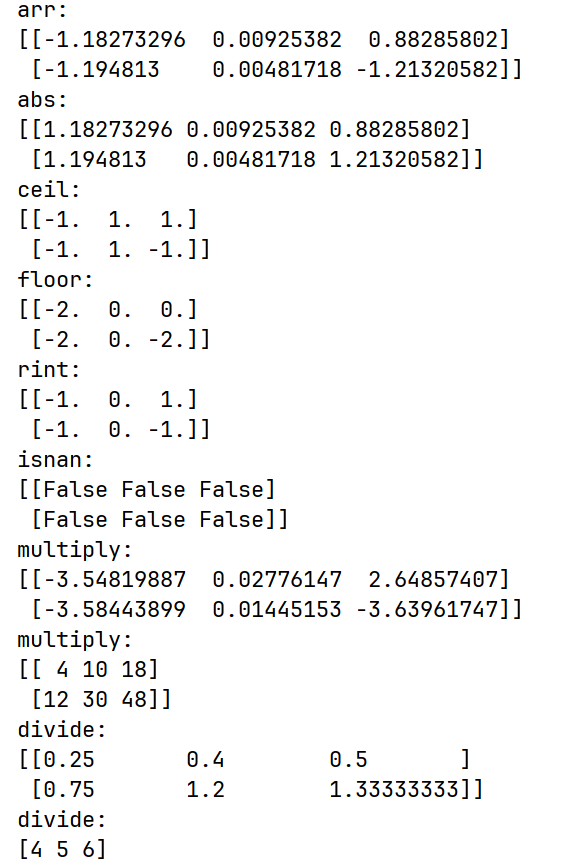
print(f"arr:\n{arr}")
print(f"abs:\n{np.abs(arr)}")
print(f"ceil:\n{np.ceil(arr)}")
print(f"floor:\n{np.floor(arr)}")
print(f"rint:\n{np.rint(arr)}")
print(f"isnan:\n{np.isnan(arr)}")
print(f"multiply:\n{np.multiply(arr, 3)}")
print(f"multiply:\n{np.multiply(np.array([[1, 2, 3], [3, 6, 8]]), np.array([4, 5, 6]))}")
print(f"divide:\n{np.divide(np.array([[1, 2, 3], [3, 6, 8]]), np.array([4, 5, 6]))}")
print(f"where:\n{np.where(True, np.array([4, 5, 6]), np.array([1, 2, 3]))}")运行结果:
2.统计函数
|
函数 |
说明 |
|
np.mean() |
所有元素的平均值 |
|
np.sum() |
所有元素的和 |
|
np.max() |
所有元素的最大值 |
|
np.min() |
所有元素的最小值 |
|
np.std() |
所有元素的标准差 |
|
np.var() |
所有元素的方差 |
|
np.argmax() |
最大值的下标索引值 |
|
np.argmin() |
最小值的下标索引值 |
|
np.cumsum() |
返回一个一维数组,每个元素都是之前所有元素的累加和 |
|
np.cumprod() |
返回一个一维数组,每个元素都是之前所有元素的累乘积 |
多维数组在计算时默认计算全部维度,可以使用axis参数指定按某一维度为轴心统计,axis=0按列统计、axis=1按行统计。
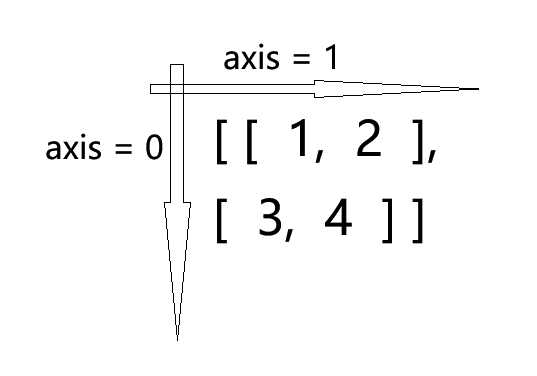
三维的数组就还有axis = 3这个轴。
下面演示表格中的函数:
import numpy as np
arr1 = np.random.randint(1, 5, (2, 3))
print(arr1)
print(f"平均值:{np.mean(arr1)}")
print(f"元素和:{np.sum(arr1)}")
print(f"最大值:{np.max(arr1)}")
print(f"最小值:{np.min(arr1)}")
print(f"标准差:{np.std(arr1)}")
print(f"方差:{np.var(arr1)}")
print(f"最大值索引:{np.argmax(arr1)}")
print(f"最小值索引:{np.argmin(arr1)}")
print(f"累加和:{np.cumsum(arr1)}")
print(f"累乘积:{np.cumprod(arr1)}")
print(f"累乘积\n:{np.cumprod(arr1, axis=1)}")运行结果:

最后一行 "print(f"累乘积\n:{np.cumprod(arr1, axis=1)}")" 指定axis=1,所以按行统计,不同行之间没有什么联系。
3.比较函数
|
函数 |
说明 |
|
np.any() |
至少有一个元素满足指定条件,就返回True |
|
np.all() |
所有的元素都满足指定条件,才返回True |
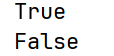
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
print(np.any(arr1 > 3))
print(np.all(arr1 > 3))运行输出:
4.排序函数
ndarray.sort():就地排序(直接修改原数组)。
import numpy as np
arr1 = np.random.randint(0, 10, (3, 3))
print(arr1)
arr1.sort()
print(arr1)
arr1.sort(axis=0)
print(arr1)运行结果:

axis:指定排序的轴。默认值为 -1,表示沿着最后一个轴进行排序。在二维数组中,axis = 0 表示按列排序,axis = 1 表示按行排序。
在 NumPy 中,轴是对数组维度的一种抽象描述。对于多维数组,每个维度都对应一个轴,轴的编号从 0 开始。对于二维数组,它有两个轴:
轴 0:代表垂直方向,也就是行的方向。可以把二维数组想象成一个表格,轴 0 就像是表格中从上到下的行索引方向对列数据排序,所以axis=0表示按列排序。
轴 1:代表水平方向,也就是列的方向。就像是表格中从左到右的列索引方向对行数据进行排序,所以axis=1表示按行排序。
np.sort():返回排序后的副本(创建新的数组)。
import numpy as np
arr1 = np.random.randint(0, 10, (3, 3))
print(arr1)
print(np.sort(arr1))
print(arr1)运行结果:

5.去重函数
np.unique():计算唯一值并返回有序结果。
import numpy as np
arr1 = np.random.randint(0, 5, (3, 3))
print(arr1)
print(np.unique(arr1))运行结果:

这里[0, 1, 3]就是去重之后的数组。
九.基本运算
numpy中的数组不用编写循环即可执行批量运算,称之为矢量化运算。
大小相等的数组之间的任何算术运算都会将运算应用到元素级。
import numpy as np
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[7, 8, 9], [10, 11, 12]])
print(arr1 + arr2)
print(arr1 - arr2)
print(arr1 * arr2)
print(arr1 / arr2)运行结果:

1.什么是广播?
广播(Broadcasting) 是 NumPy 中最核心、最高效的特性之一,它允许不同形状的数组进行算术运算,而无需手动复制数据、循环遍历。
简单来说:当两个数组形状不匹配时,NumPy 会自动扩展维度更小的数组,让两个数组的形状在逻辑上对齐,再执行逐元素运算。
- 核心优势:代码极简、零内存复制、性能拉满,彻底告别 Python 原生循环的低效。
- 本质:用逻辑扩展替代物理复制,在不增加内存开销的前提下,实现批量运算。
2.广播的核心规则(必须刻进 DNA)
两个数组进行运算时,从右往左(从最后一个维度) 依次对比每个维度的大小,满足以下任一条件,即可广播:
- 对应维度大小相等;
- 其中一个维度大小为 1;
- 维度数量不足时,自动在左侧补 1 维(相当于
np.newaxis)。
如果两个维度既不相等,也不为 1,则直接抛出 ValueError: operands could not be broadcast together 错误。
广播永远从最右侧维度开始匹配,左侧维度不足自动补 1,再依次向左对比。(从右往左是关键!)
举个直观的对比逻辑:
| 数组 A 形状 | 数组 B 形状 | 广播后形状 | 说明 |
|---|---|---|---|
(3,) |
(3,1) |
(3,3) |
右维:3 vs 1(可广播);左维:补 1 后 1 vs 3(可广播) |
(2,3) |
(3,) |
(2,3) |
右维:3 vs 3(相等);左维:补 1 后 1 vs 2(可广播) |
(2,1,4) |
(3,4) |
(2,3,4) |
右维:4 vs 4(相等);中间维:1 vs 3(可广播);左维:2 vs 补 1(可广播) |
(2,3) |
(2,4) |
❌ 报错 | 右维:3 vs 4(既不相等也不为 1) |
3.5个经典案例
案例 1:标量与数组广播(最常用)
标量(0 维数组)可以和任意形状的数组广播,是日常开发中最频繁的场景。
import numpy as np
# 一维数组
arr = np.array([1, 2, 3])
# 标量 2 自动广播为 [2, 2, 2],再逐元素相加
print(arr + 2)
# 输出: [3 4 5]
# 二维数组
arr_2d = np.array([[1, 2, 3], [4, 5, 6]])
# 标量 10 广播为 2x3 的全10矩阵
print(arr_2d * 10)
# 输出:
# [[10 20 30]
# [40 50 60]]原理:标量会被逻辑扩展为与原数组完全相同的形状,再执行运算,全程无内存复制。
案例 2:一维数组与二维数组广播(高频场景)
这是数据预处理、矩阵运算中最常用的广播形式,比如给矩阵的每一行 / 列加上偏移量。
# 二维数组 (2,3)
arr_2d = np.array([[1, 2, 3],
[4, 5, 6]])
# 一维数组 (3,)
row_offset = np.array([10, 20, 30])
# 广播:row_offset 自动扩展为 (2,3),每行都是 [10,20,30]
print(arr_2d + row_offset)
# 输出:
# [[11 22 33]
# [14 24 36]]
# 给每列加偏移量:手动将一维数组转为 (2,1) 形状
col_offset = np.array([[100], [200]]) # 形状 (2,1)
print(arr_2d + col_offset)
# 输出:
# [[101 102 103]
# [204 205 206]]原理:
- 行偏移:
(2,3)+(3,)→ 右维 3=3,左维补 1 后 1=2,广播为(2,3) - 列偏移:
(2,3)+(2,1)→ 右维 3 和 1(可广播),左维 2=2,广播为(2,3)
案例 3:(3,) 与 (3,1) 广播
# 一维数组 (3,)
arr1 = np.array([1, 2, 3])
# 二维数组 (3,1)
arr2 = np.array([[4], [5], [6]])
# 执行加法
print(arr1 + arr2)
# 输出:
# [[ 5 6 7]
# [ 6 7 8]
# [ 7 8 9]]广播过程拆解(一步到位):
-
形状对比(从右往左):
arr1形状(3,)→ 补左维后为(1, 3)arr2形状(3, 1)- 右维:
3vs1(满足「一个为 1」,可广播) - 左维:
1vs3(满足「一个为 1」,可广播) - 最终广播形状:
(3, 3)
-
逻辑扩展过程(无实际内存复制):
arr1从(1,3)沿第 0 维(行)复制 3 次 →[[1,2,3],[1,2,3],[1,2,3]]arr2从(3,1)沿第 1 维(列)复制 3 次 →[[4,4,4],[5,5,5],[6,6,6]]- 两个
(3,3)数组逐元素相加,得到最终结果。
案例 4:高维数组广播(进阶)
广播规则对任意维度的数组都生效,核心永远是「从右往左对比」。
# 3维数组 (2, 1, 4)
arr_3d = np.ones((2, 1, 4))
# 2维数组 (3, 4)
arr_2d = np.arange(12).reshape(3, 4)
print("arr_3d 形状:", arr_3d.shape) # (2, 1, 4)
print("arr_2d 形状:", arr_2d.shape) # (3, 4)
print("广播后形状:", np.broadcast_shapes(arr_3d.shape, arr_2d.shape)) # (2, 3, 4)
# 执行运算
result = arr_3d + arr_2d
print("结果形状:", result.shape) # (2, 3, 4)
print(result)原理:
- 右维:
4vs4(相等,可广播) - 中间维:
1vs3(一个为 1,可广播) - 左维:
2vs 补 1(一个为 1,可广播) - 最终广播为
(2,3,4)的 3 维数组。
案例 5:广播的反例:为什么会报错?
理解报错原因,才能彻底避开广播的坑。
# 形状 (2,3)
a = np.ones((2, 3))
# 形状 (2,4)
b = np.ones((2, 4))
# 尝试相加 → 报错
print(a + b)
# ValueError: operands could not be broadcast together with shapes (2,3) (2,4) 报错原因:从右往左对比,第一个维度3 vs 4,既不相等,也不为 1,完全不满足广播规则,直接报错。
4.广播的手动控制:np.newaxis 与 reshape
当数组形状不满足广播规则时,我们可以手动插入维度,让形状兼容,这是广播的「进阶玩法」。
1. np.newaxis:插入维度(推荐)
np.newaxis 本质是None,用于在指定位置插入一个大小为 1 的维度,是最直观的手动广播方式。
# 原始一维数组 (3,)
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 直接相加:(3,) + (3,) → 逐元素相加,结果 (3,)
print(a + b) # [5 7 9]
# 手动插入维度,实现外积
a_row = a[np.newaxis, :] # 形状 (1,3)
b_col = b[:, np.newaxis] # 形状 (3,1)
# 广播:(1,3) + (3,1) → (3,3)
print(a_row + b_col)
# 输出:
# [[ 5 6 7]
# [ 6 7 8]
# [ 7 8 9]]2. reshape:重塑形状(等价方式)
用reshape也能实现相同效果,适合需要批量重塑的场景。
a_row = a.reshape(1, 3) # (1,3)
b_col = b.reshape(3, 1) # (3,1)
print(a_row + b_col) # 结果完全一致5.广播的底层原理:为什么这么快?
很多人误以为广播会复制数组,这是最大的误区!
- 物理层面:广播不会真的创建一个大数组,原数组的内存完全不变。
- 逻辑层面:NumPy 会在运算时,通过索引偏移的方式,模拟数组扩展的效果,直接在原数组上取值计算。
- 性能对比:广播的速度比 Python 原生循环快 100~1000 倍,甚至比手动复制数组再运算快数倍,是 NumPy 高性能的核心保障,因为底层是C语言。
6.总结
广播是 NumPy 的「灵魂特性」,它用极简的规则,实现了极致的性能,是从「会用 NumPy」到「精通 NumPy」的必经之路。
- 核心规则:从右往左,相等或为 1,不足补 1
- 核心优势:零内存复制,性能拉满,代码极简
- 核心应用:数据预处理、矩阵运算、网格生成、批量计算
掌握广播,你就能用一行代码实现原本需要循环几十行的功能,彻底告别低效的 Python 原生循环,写出真正优雅、高效的 NumPy 代码。
十.矩阵乘法
通过*运算符和np.multiply()对两个数组相乘进行的是对位乘法而非矩阵乘法运算。
import numpy as np
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[6, 5, 4], [3, 2, 1]])
print(arr1 * arr2)
print(np.multiply(arr1, arr2))运行结果:

使用np.dot()、ndarray.dot()、@可以进行矩阵乘法运算。
import numpy as np
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
arr2 = np.array([[6, 5], [4, 3], [2, 1]])
#对于矩阵乘法来说,要求第一个矩阵的列数等于第二个矩阵的行数
print(arr1)
print(arr2)
print(arr1.shape, arr2.shape)
print(np.dot(arr1, arr2))
print(arr1.dot(arr2))
print(arr1 @ arr2)
# 一个二维数组跟一个大小合适的一维数组的矩阵点积运算之后将会得到一个一维数组
arr3 = np.array([6, 5, 4])
print(arr1 @ arr3)运行结果:
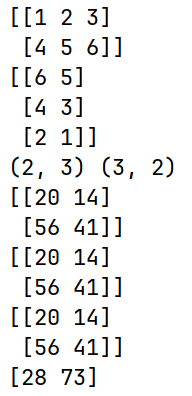
矩阵乘法的规则是:结果矩阵中第 i 行第 j 列的元素等于第一个矩阵的第 i 行与第二个矩阵的第 j 列对应元素乘积之和。
- 结果矩阵第一行第一列的元素:
计算 arr1 的第一行 [1, 2, 3] 与 arr2 的第一列 [6, 4, 2] 对应元素乘积之和,即 1*6 + 2*4 + 3*2 = 6 + 8 + 6 = 20。
- 结果矩阵第一行第二列的元素:
计算 arr1 的第一行 [1, 2, 3] 与 arr2 的第二列 [5, 3, 1] 对应元素乘积之和,即 1*5 + 2*3 + 3*1 = 5 + 6 + 3 = 14。
- 结果矩阵第二行第一列的元素:
计算 arr1 的第二行 [4, 5, 6] 与 arr2 的第一列 [6, 4, 2] 对应元素乘积之和,即 4*6 + 5*4 + 6*2 = 24 + 20 + 12 = 56。
- 结果矩阵第二行第二列的元素:
计算 arr1 的第二行 [4, 5, 6] 与 arr2 的第二列 [5, 3, 1] 对应元素乘积之和,即 4*5 + 5*3 + 6*1 = 20 + 15 + 6 = 41。
所以,手动计算得到的结果矩阵是 [[20, 14], [56, 41]]。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)