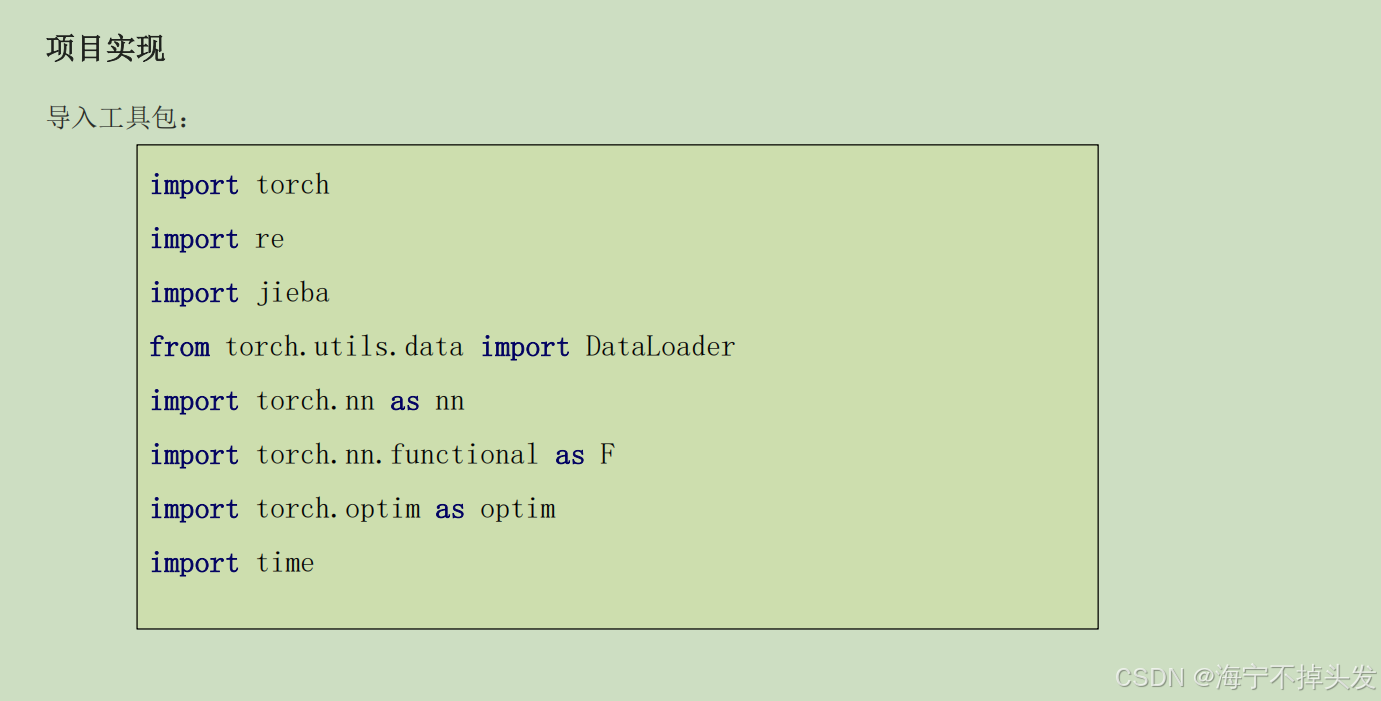
【11月16日-大模型前置知识【深度学习】+大模型开发入门】-基础篇笔记
本文介绍了机器学习基础内容,重点讲解了HuggingFace国内镜像站的使用方法,以及LLM大模型语言的基础知识。文章对比了N-gram和神经网络语言模型的原理差异,详细解析了BERT、GPT、T5等主流模型架构特点。同时介绍了卷积神经网络CNN的基本原理和应用场景。通过图表直观展示了各种模型的核心结构和训练流程,帮助读者快速理解机器学习的基础概念和主流模型的工作原理。
文章目录
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、huggingface国内
官网链接:https://huggingface.co/
国内镜像站:https://hf-mirror.com/# 二、使用步骤
1.引入库

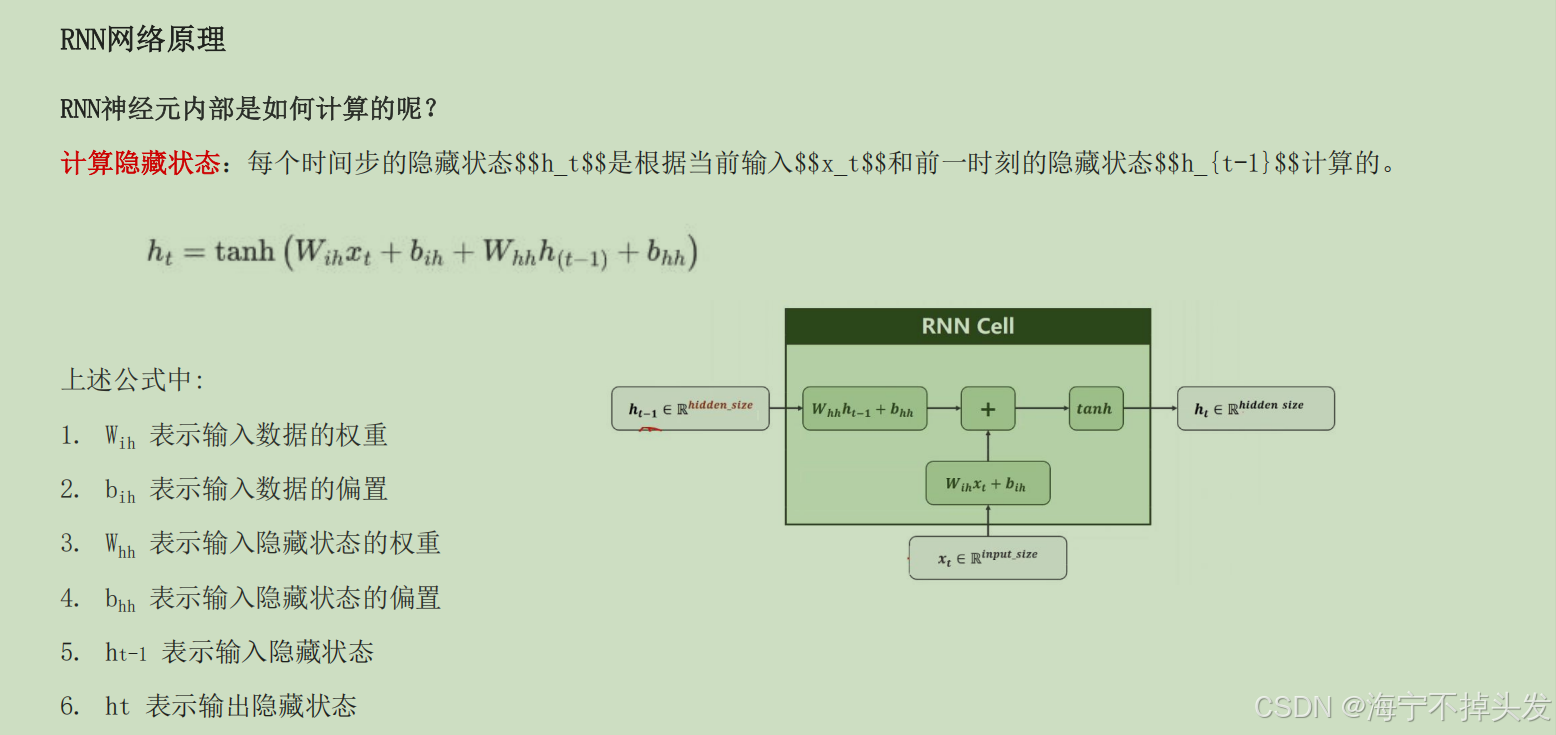
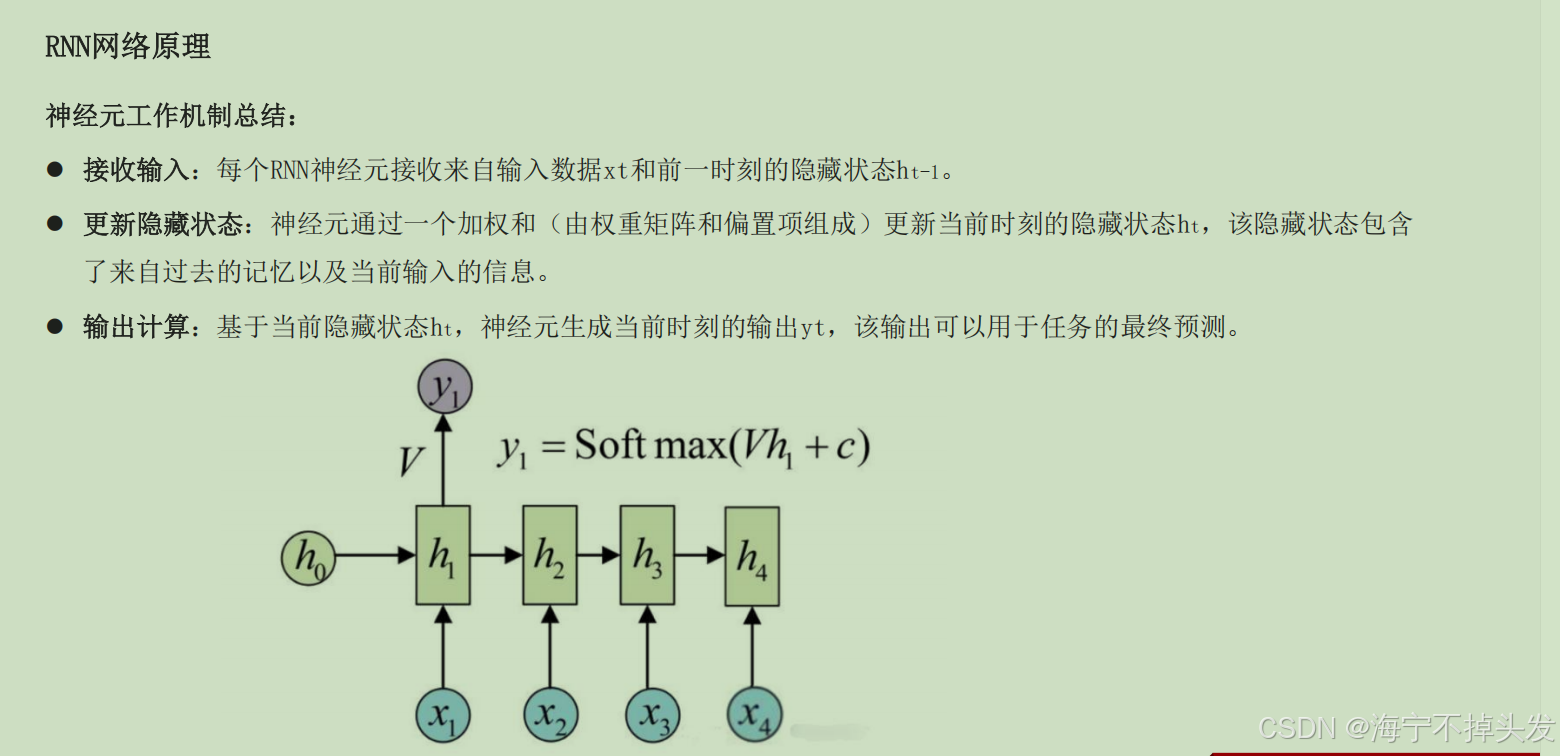
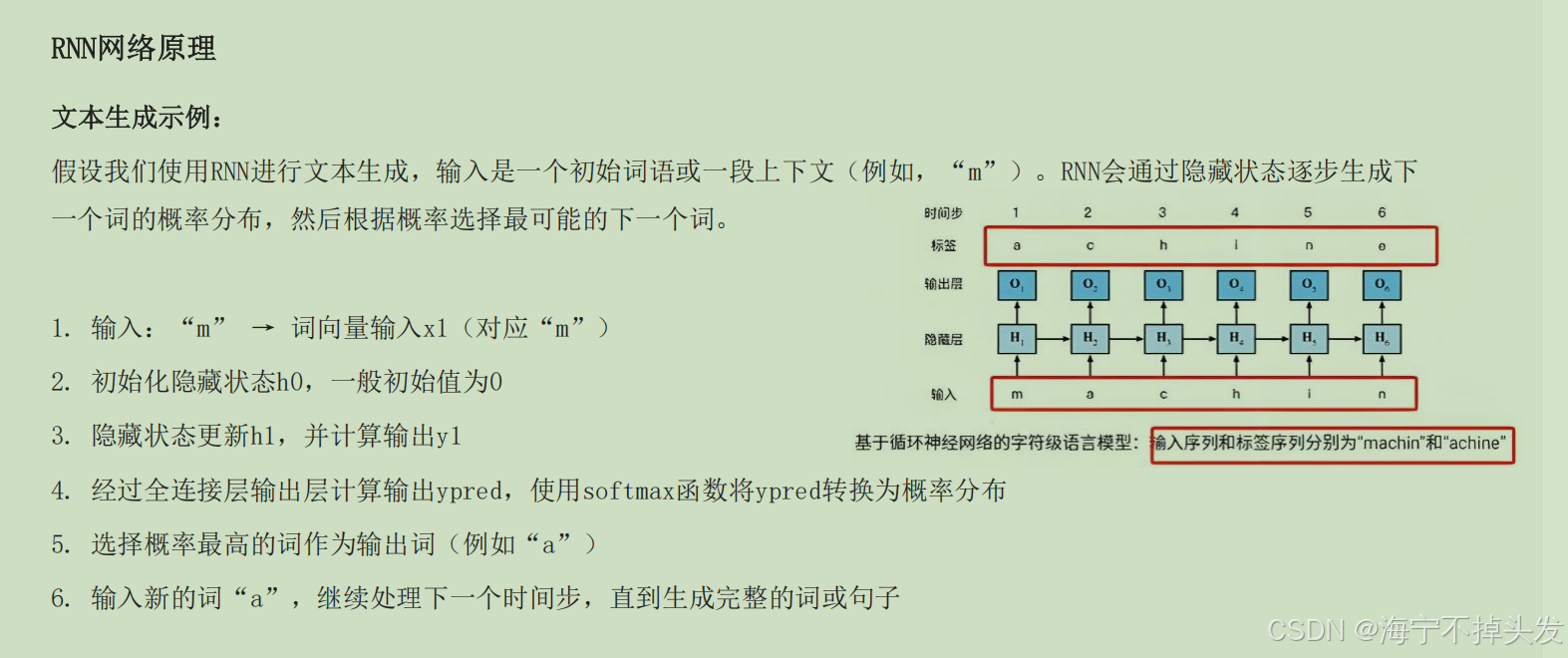
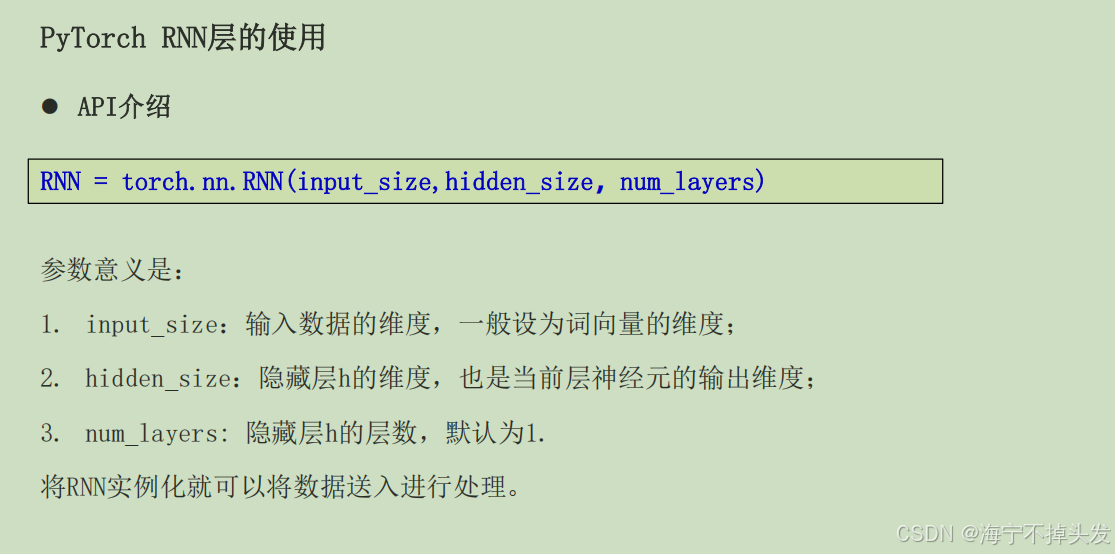
循环神经网络: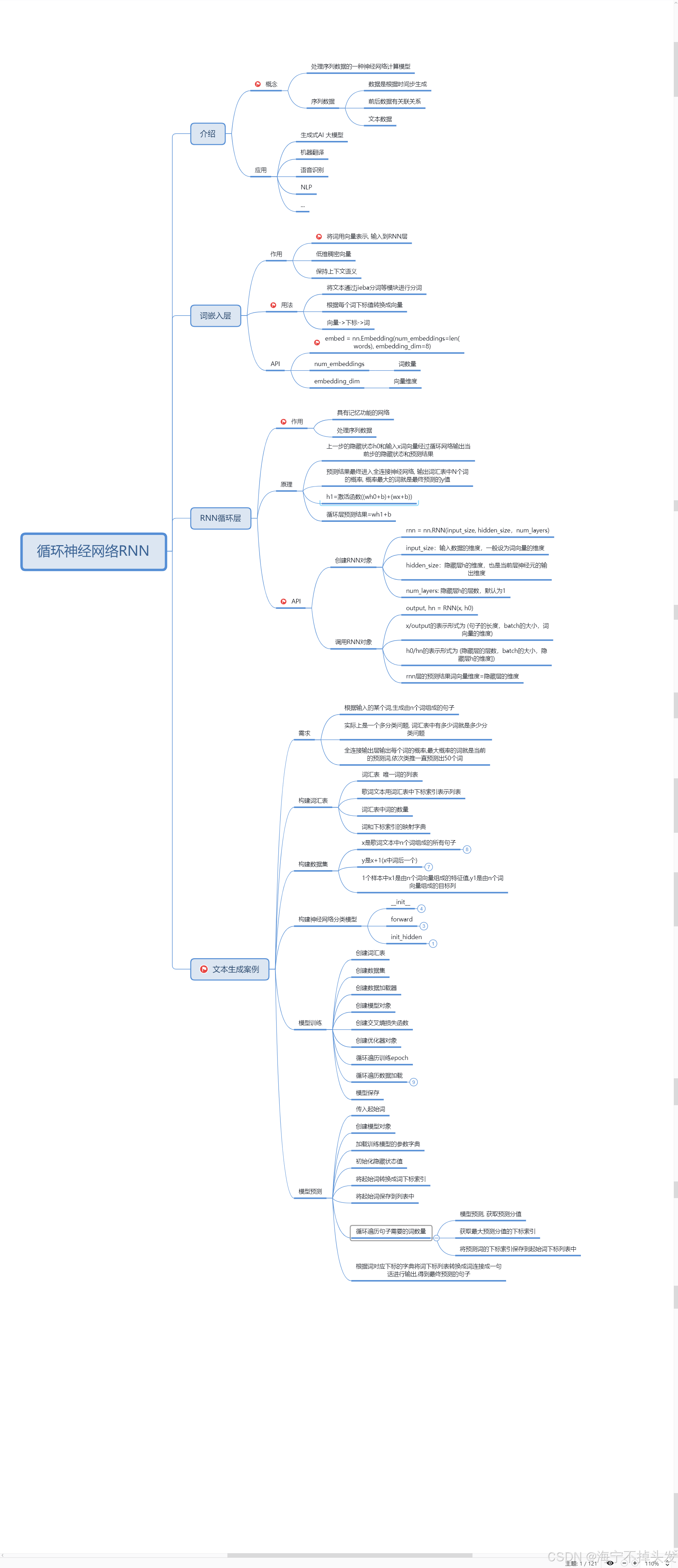
2.LLM 大模型语言的基础知识:
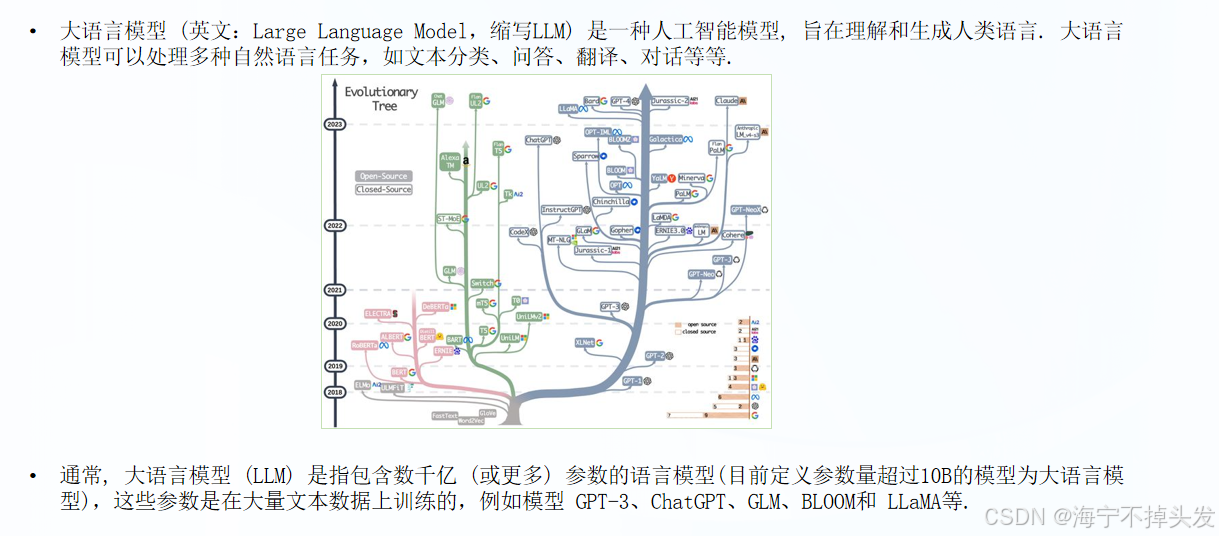



通俗的讲是:
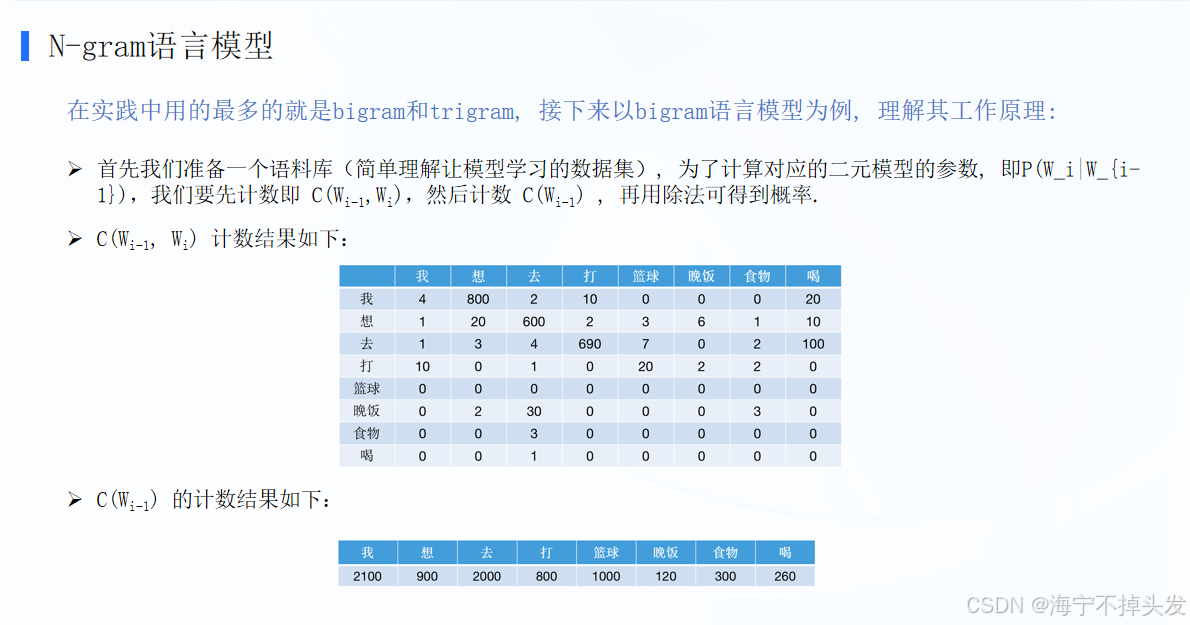
N-gram 核心就是用统计预测下一个词,最常用的是二元(Bigram)和三元(Trigram)模型。
核心原理(极简版)
核心假设:下一个词只跟前面有限个词有关(Bigram 只看前 1 个词)。
计算逻辑:
统计语料库中词对出现次数(比如 “我” 后面跟 “想” 的次数)。
用 “词对次数 / 前词总次数” 算出概率。
比如表格中 P (想 | 我)=800/2100≈0.38,P (去 | 想)=3/900=0.003。
关键表格含义
左表:C (Wi-1, Wi)—— 连续两个词同时出现的次数。
右表:C (Wi-1)—— 前一个词单独出现的总次数。
概率公式:P(Wi∣Wi−1)=C(Wi−1)C(Wi−1,Wi)
通俗类比
就像输入法联想,输入 “我”,推荐 “想” 的概率远高于 “篮球”,因为统计数据里 “我 + 想” 出现得最多。
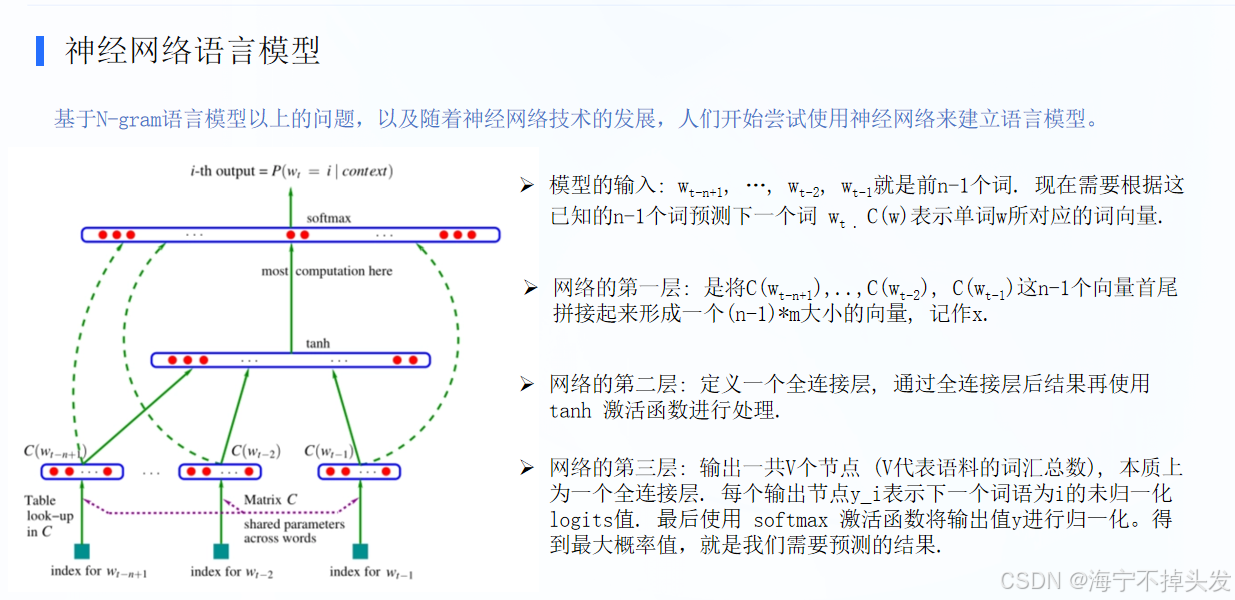
神经网络语言模型(NNLM),它是 N-gram 的 “进化版”,核心用神经网络替代纯统计,能捕捉词之间更复杂的关联,而非简单算词频。
核心目标(一句话概括)
给你前 n-1 个词(比如 “我想喝”),通过神经网络预测下一个最可能的词(比如 “水”)。
逐步骤通俗拆解
- 输入层:把词变成向量(查表)
不能直接读 “词”,得转成数字向量(词向量)。
图中Table look-up in C就是 “查词表”:把w_{t-n+1}…w_{t-1}这些词,转成对应的向量C(w)。
比如 “我”→向量 A,“想”→向量 B,把这些向量拼起来形成一个长向量 x,作为网络输入。 - 隐藏层:提取特征(全连接 + 激活)
把长向量 x 喂进全连接层,做线性计算后,再用tanh激活函数处理。
这一步是核心 “计算”,作用是把前 n-1 个词的向量融合,提取出能表示上下文的特征(比如捕捉 “我想喝” 里的 “口渴” 语义)。 - 输出层:预测下一个词(归一化概率)
最后接一个全连接层,输出 V 个节点(V 是词汇总数),每个节点对应一个词的 “未归一化分数”(logits)。
用softmax把这些分数转成概率(总和为 1),概率最高的那个词,就是模型预测的下一个词。
和 N-gram 的核心区别
表格
对比维度 N-gram 神经网络语言模型
核心逻辑 纯统计词频 神经网络学习语义
词的表示 独热编码(稀疏) 词向量(稠密、有语义)
关联捕捉 固定窗口内的简单关联 复杂语义关联(如长距离依赖)
通俗类比
N-gram 像记 “口头禅频率”:“我” 后面说 “想” 的次数多,就猜下一个是 “想”;神经网络语言模型像理解 “语境”:结合 “我、想、喝” 的语义,精准猜下一个是 “水 / 奶茶”,而非盲目按频率选。


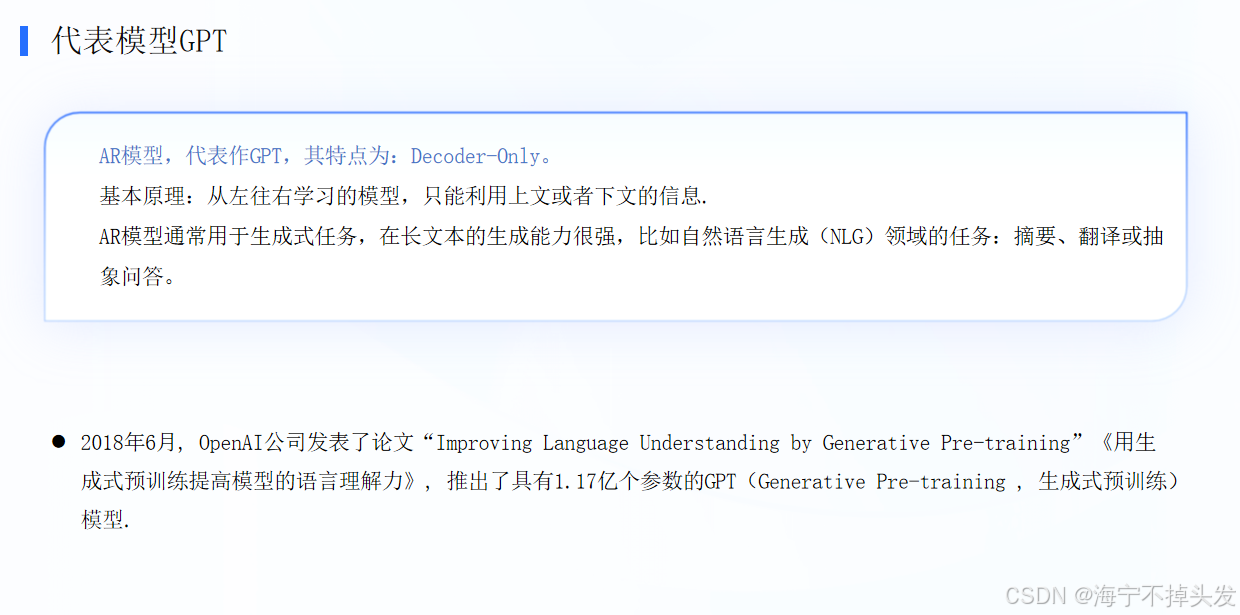
2.LLM主要类别架构介绍
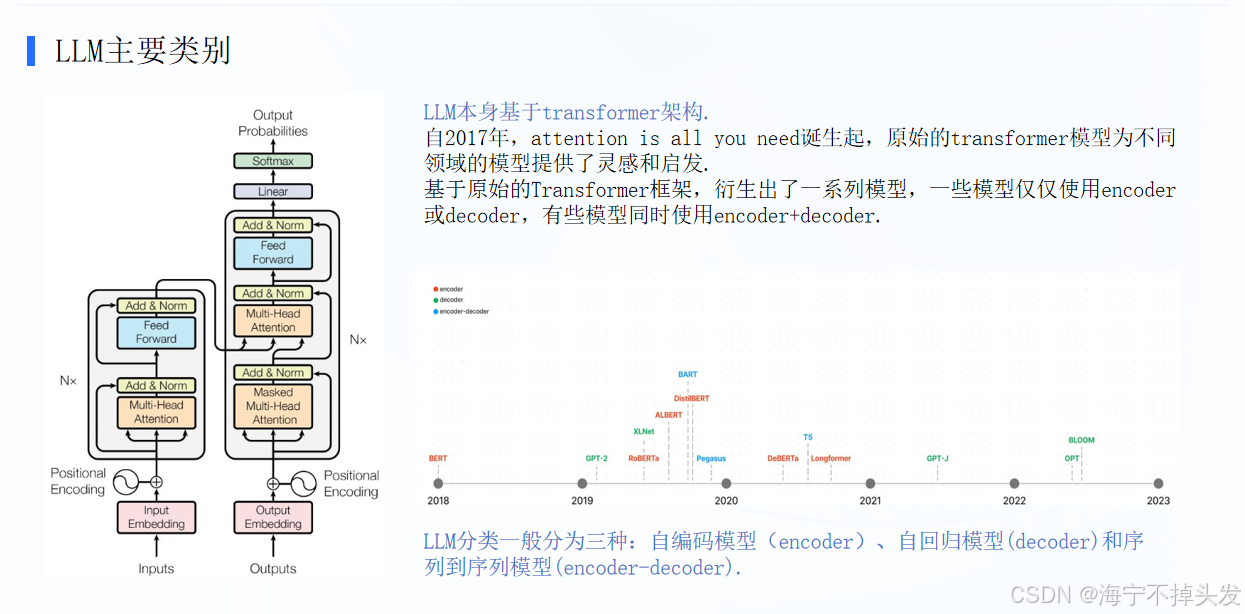

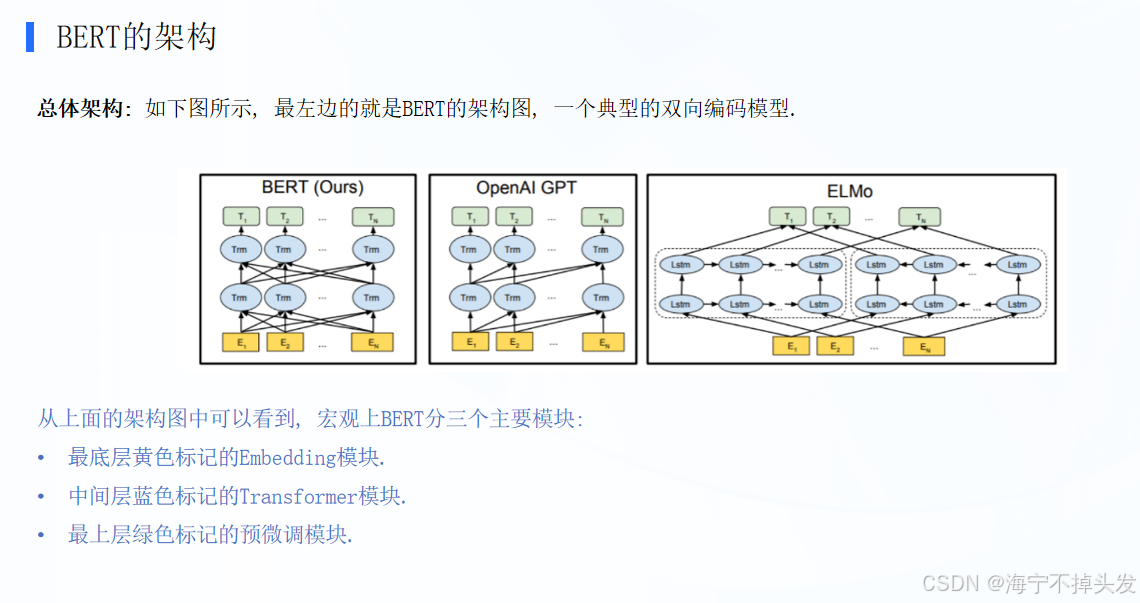
BERT的核心架构,并将其与GPT、ELMo做了横向对比。BERT 本质是一个基于 Transformer 的双向语言模型,它是当前 NLP(自然语言处理)的基石。
以下是结合图表的极简通俗解释:
- 核心定位:BERT 是什么?
正如图中文字所说,BERT 是一个典型的双向编码模型。
通俗理解:它像一个 “阅读理解大师”,能同时看左下文和右下文来理解词义(比如判断 “ bank ” 在 “河岸” 和 “银行” 里的意思)。
对比看架构:
BERT:左边直接堆叠多层 Transformer(Trm),信息双向流动,看的最全。
GPT:用的是单向 Decoder 结构,只能往左看,有局限性。
ELMo:简单拼接左向和右向 LSTM,不如 BERT 融合得好。
- BERT 的三大核心模块
宏观上,BERT 由下往上分为三层,功能各不相同:
① 底层:Embedding(词嵌入模块)
作用:把输入的字 / 词变成计算机能看懂的向量。
构成:不仅包含词向量,还加上了位置向量(知道词的顺序)和句子向量(区分是哪句话)。
② 中间层:Transformer(核心编码模块)
作用:BERT 的 “大脑”。由多层(图中画了两层,实际通常 12 层 / 24 层)Transformer 编码器堆叠而成。
关键机制:利用Attention(注意力机制),让每个词都能同时关注到句子里的其他所有词(双向),从而深度理解语义关联。
③ 顶层:Pre-training(预训练模块)
作用:模型训练好后的 “应用层”。
流程:接收 Transformer 提取的深层特征,经过简单的全连接层,输出最终的预测结果(比如做分类、提取特征等)。
- 一句话总结流程
输入词 → Embedding 转向量 → Transformer 双向理解语义 → 输出任务结果

初代 GPT 训练用的数据集:BooksCorpus,以及 OpenAI 选它的两个核心理由。
数据集基本信息
规模:约 5GB 文本,包含 7400 万 + 句子,来自 7000 本不同风格、不同类型的书籍。
本质:一个专门用于预训练大语言模型的书籍语料库。
选择这个数据集的两个核心原因(通俗版)
01 练 “长文理解” 能力
书籍里有大量高质量长句子、连贯的长段落,能让 GPT 学会长距离的上下文依赖。比如小说里 “他十年前埋下的盒子,今天终于挖了出来”,模型要能把 “十年前” 和 “今天” 关联起来,而不是只看前后几个词。这比用零散的网页、短文本训练,更能练出模型的 “全局理解能力”。
02 测 “泛化能力”
这些书籍没有开源、没有公开,下游任务(比如问答、分类)用的数据集里,几乎不会出现这些内容。用它预训练,相当于让模型在 “全新的、没见过的文本” 上学通用语言规律,而不是死记硬背常见数据。这样训练出来的模型,在各种下游任务上的表现会更好,真正验证了模型的泛化能力。
补充小知识(帮你串起之前的内容)
初代 GPT 是单向自回归模型(只能从左到右预测下一个词),BooksCorpus 的长文本,刚好完美适配它的训练目标:让模型在连贯的书籍内容里,学习 “根据上文预测下文” 的能力,为后续的微调打下基础

T5 是个全能型大模型,在 Transformer 基础上做了 2 个小优化,核心是把所有 NLP 任务都统一成「文本输入→文本输出」的格式。
- 架构小改动(人话版)
层归一化:简化了计算,去掉偏置,把归一化放到残差连接外面,训练更稳。
位置编码:不用固定位置的向量,改用「相对距离标量」,不同注意力头学自己的位置信息,更灵活。 - 训练流程(人话版)
预训练:用类似 BERT(填空)+GPT(续写)的方式,学通用语言规律。
微调:把翻译、问答、摘要等所有任务,都改成 “输入文本、输出文本”,一个模型搞定所有任务,泛化能力超强。
一句话总结
T5 = 优化版 Transformer + 统一文本到文本格式 + 双目标预训练,是能理解也能生成的全能 NLP 模型。
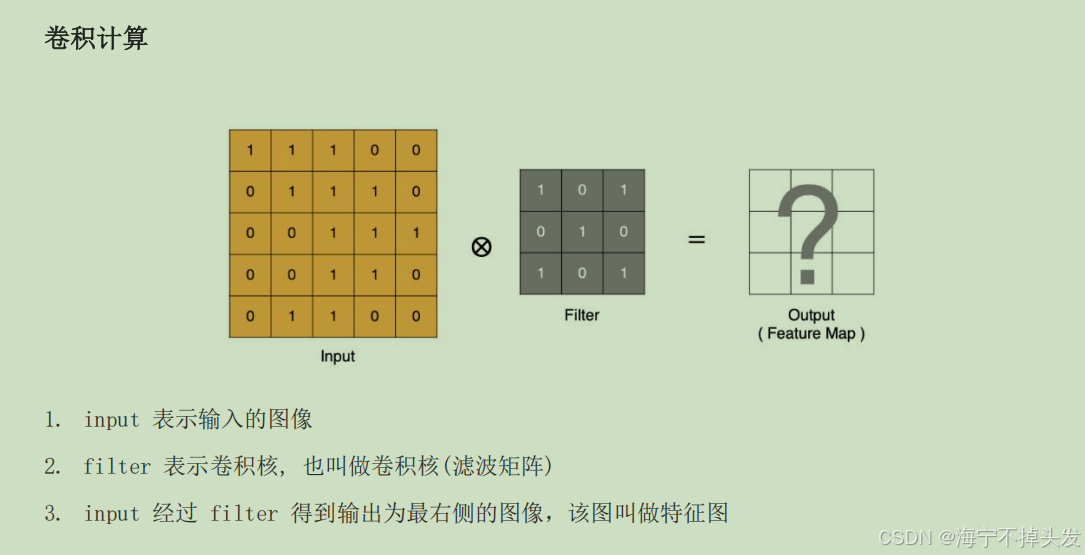
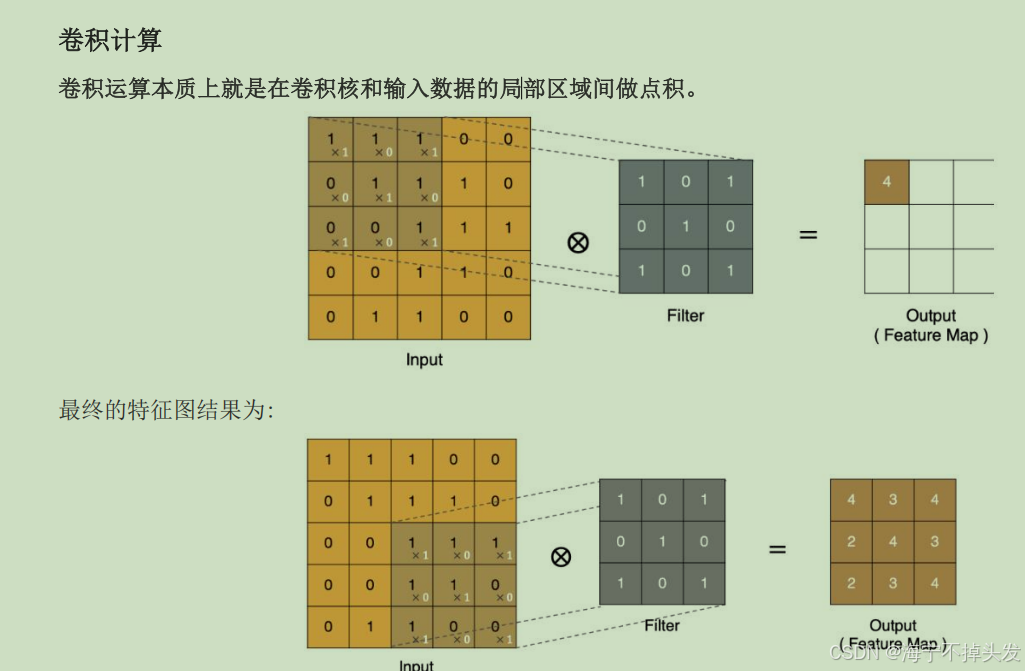
3.卷积神经网络CNN






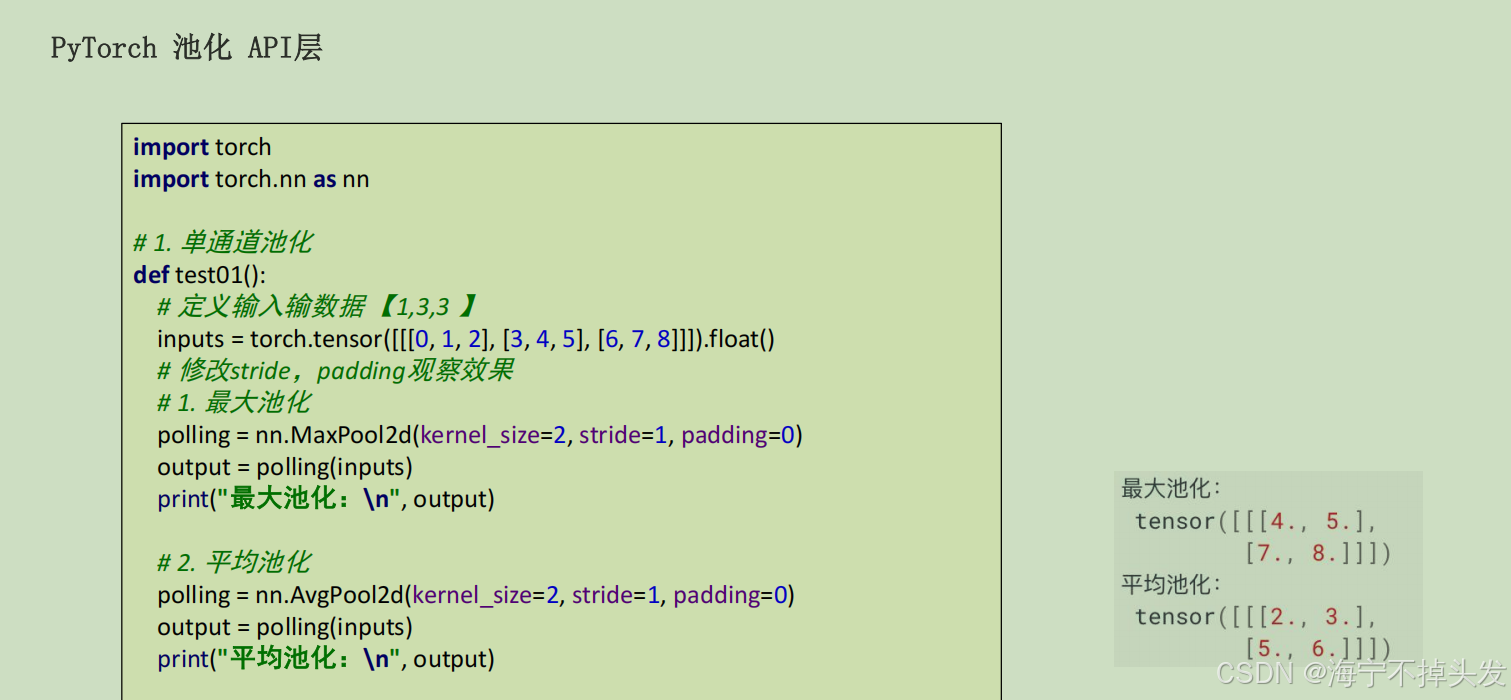

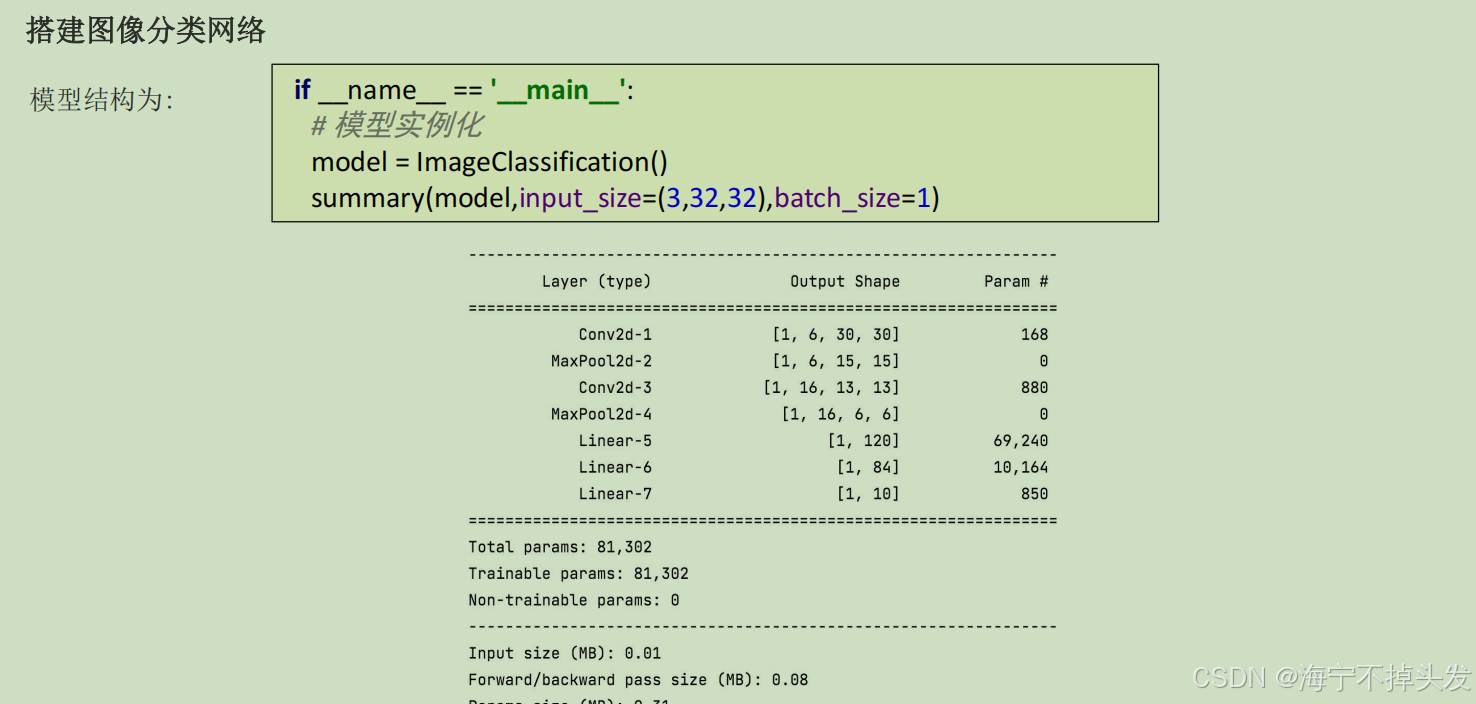
def train(model,train_dataset):
criterion = nn.CrossEntropyLoss() # 构建损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 构建优化方法
epoch = 100 # 训练轮数
for epoch_idx in range(epoch):
# 构建数据加载器
dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
sam_num = 0 # 样本数量
total_loss = 0.0 # 损失总和
start = time.time() # 开始时间
# 遍历数据进行网络训练
for x, y in dataloader:
output = model(x)
loss = criterion(output, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 计算每次训练模型的总损失值 loss是每批样本平均损失值
total_loss += loss.item()*len(y) # 统计损失和
sam_num += len(y)
print('epoch:%2s loss:%.5f time:%.2fs' %(epoch_idx + 1,total_loss / sam_num,time.time() - start))
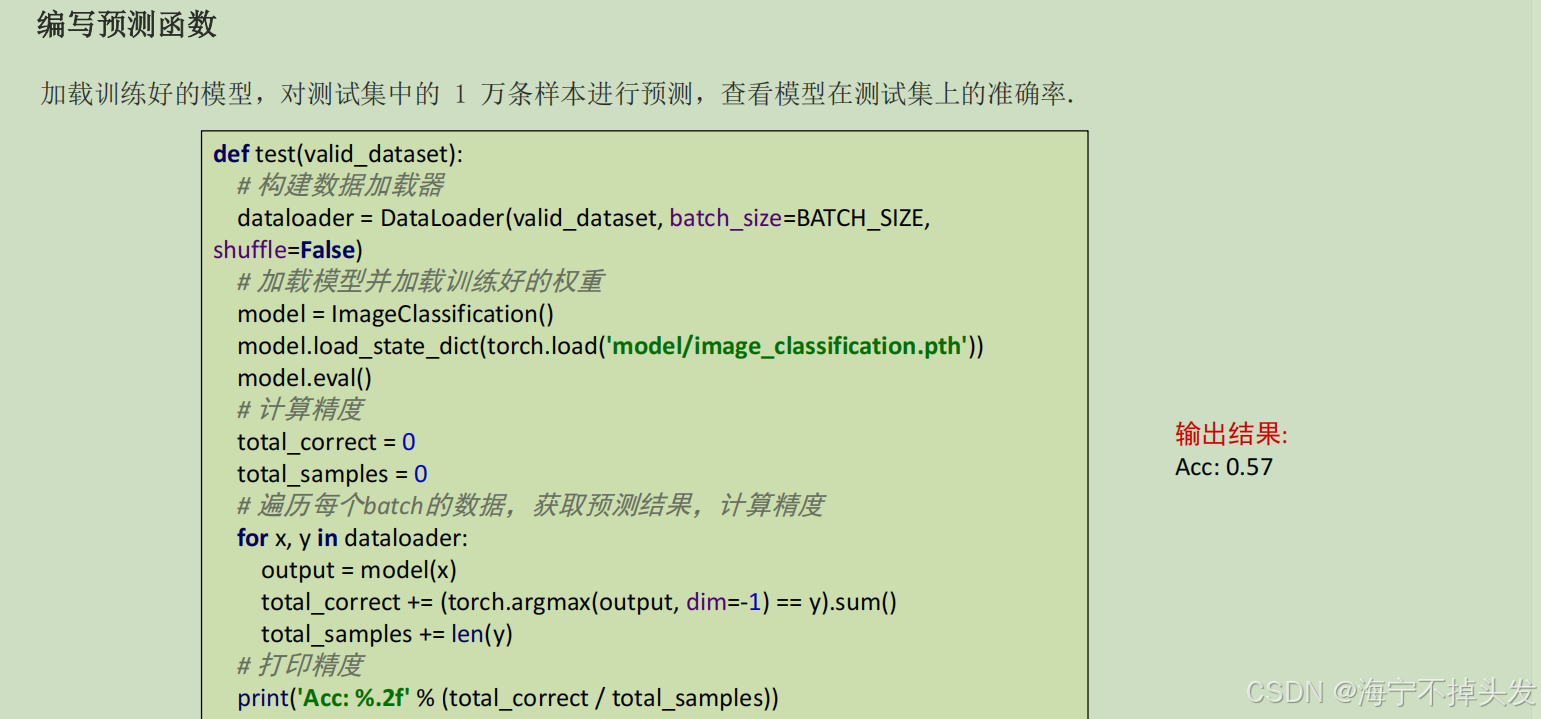
# 模型保存
torch.save(model.state_dict(), 'model/image_classification.pth')
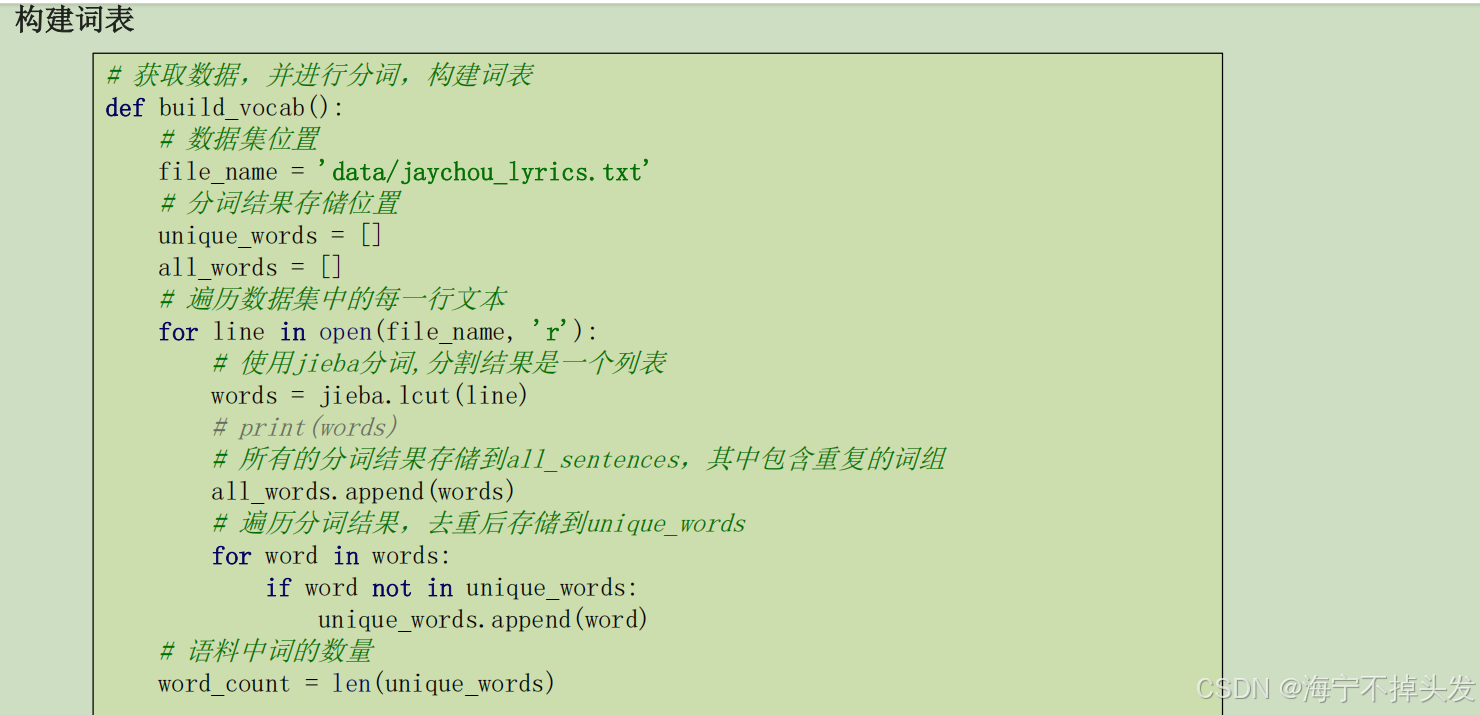
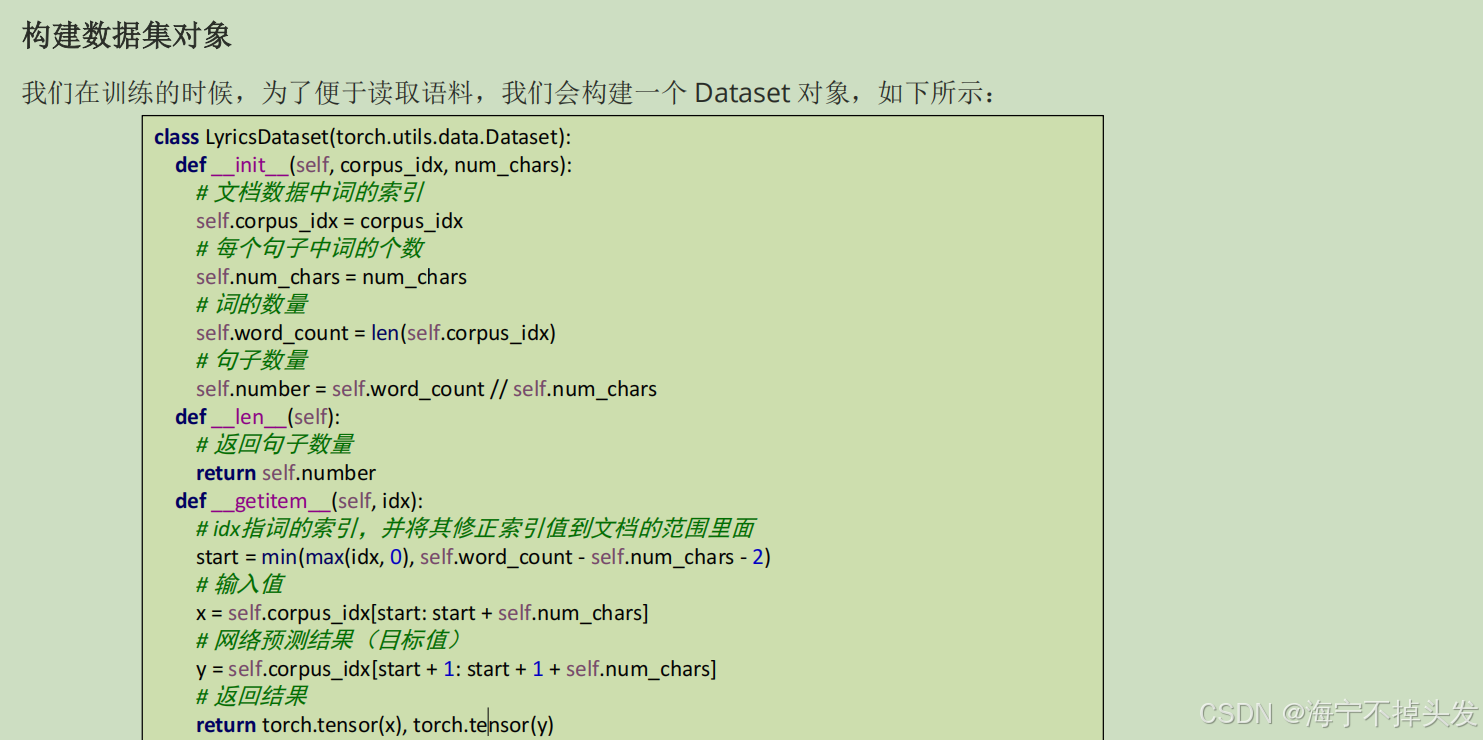
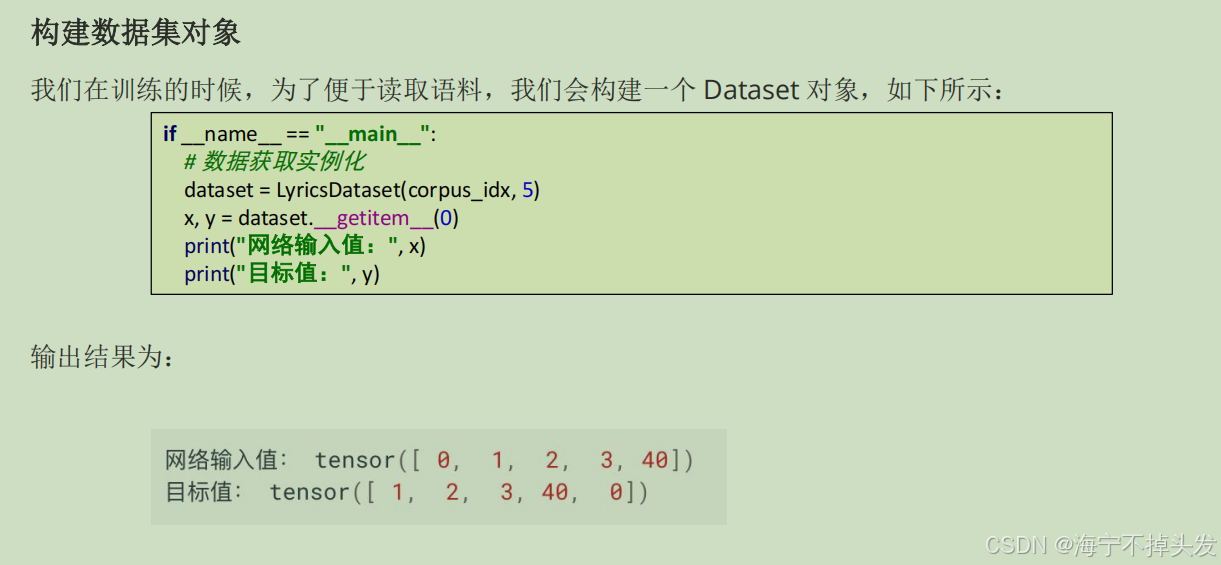
4.循环神经网络
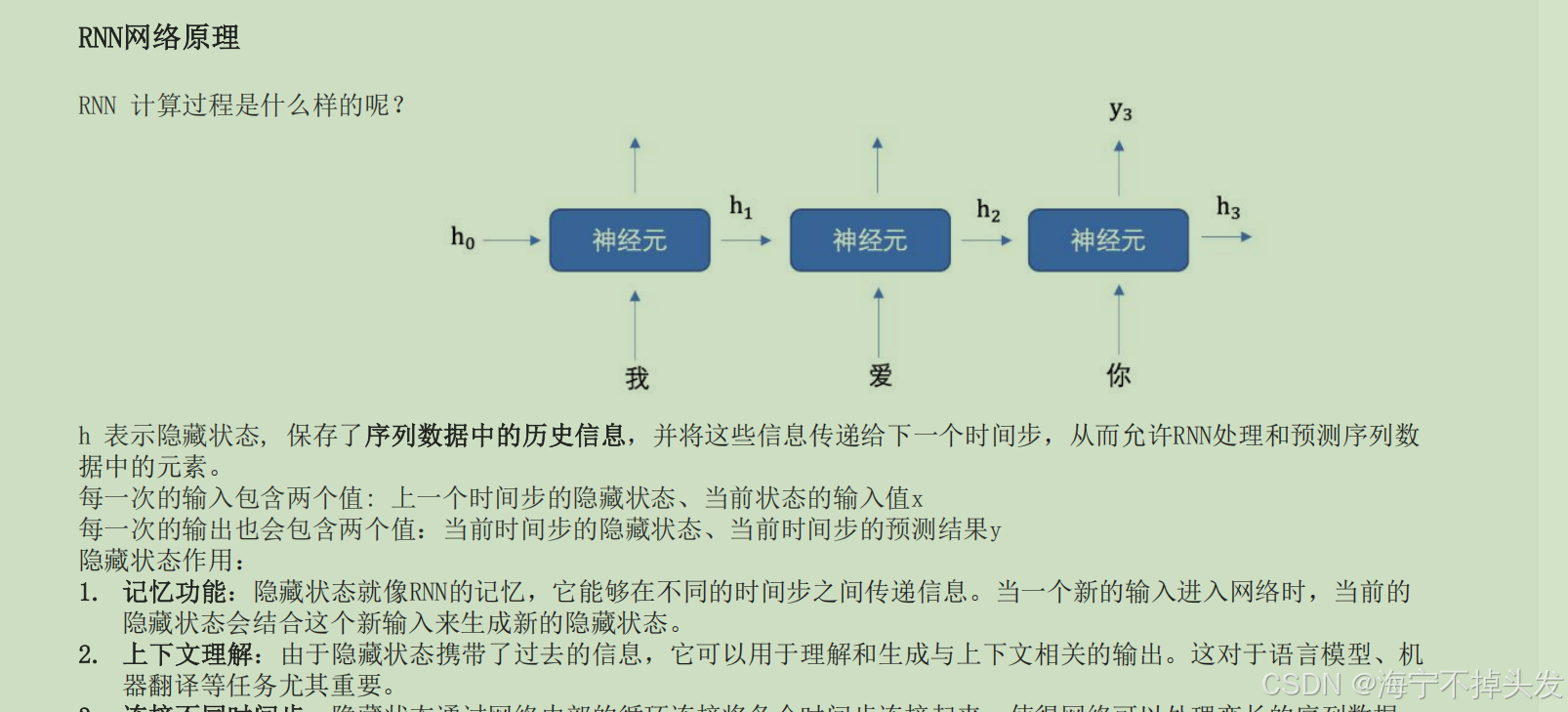
RNN介绍循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同
,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。
我们要明确什么是序列数据,时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随
时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一
个特点——后面的数据跟前面的数据有关系。
RNN的应用: l 自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等。 l
时间序列预测:股市预测、气象预测、传感器数据分析等。 l 语音识别:将语音信号转换为文字。 l
音乐生成:通过学习音乐的时序模式来生成新乐曲。







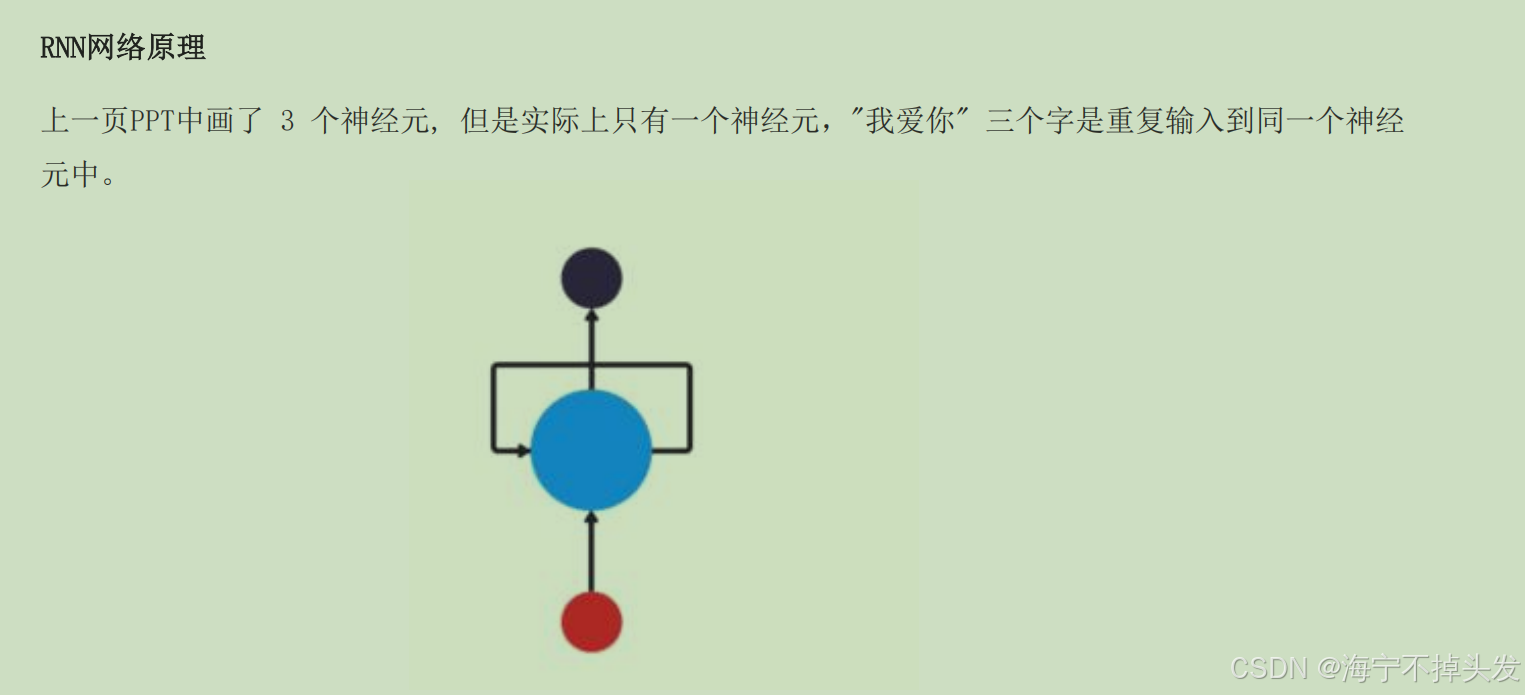
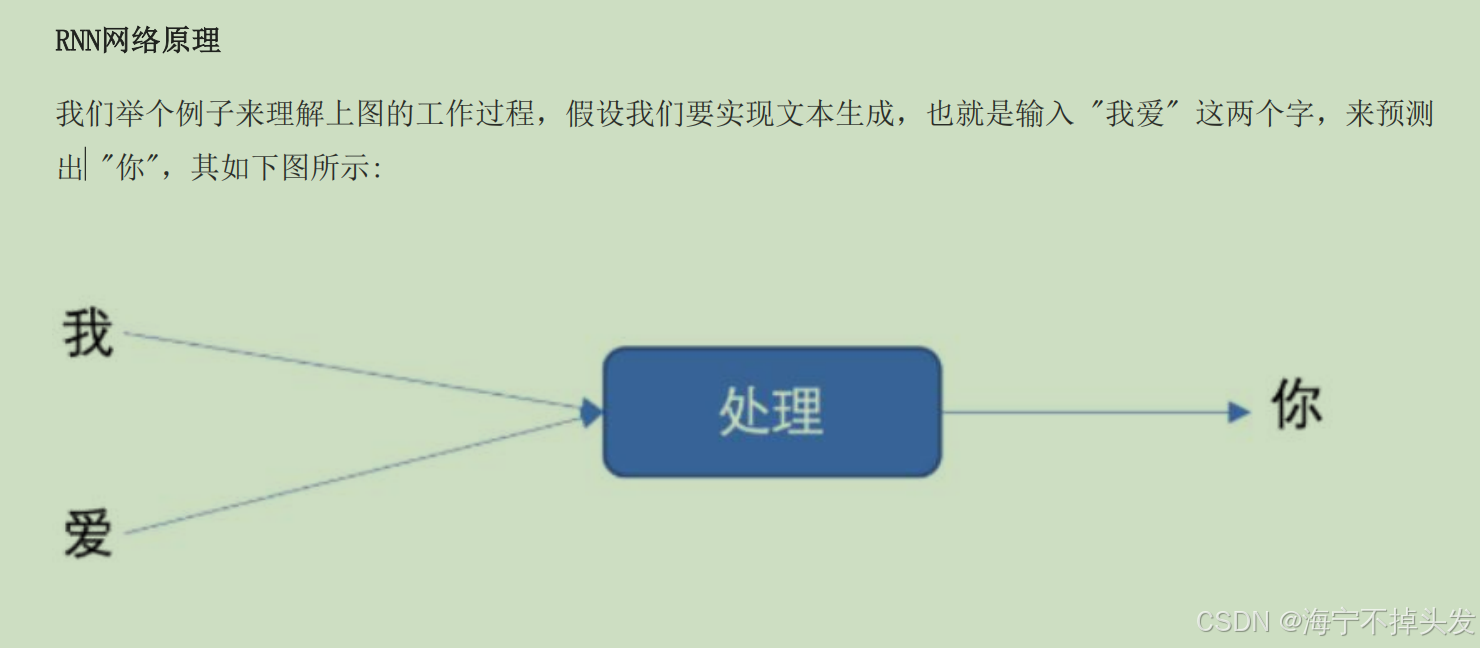
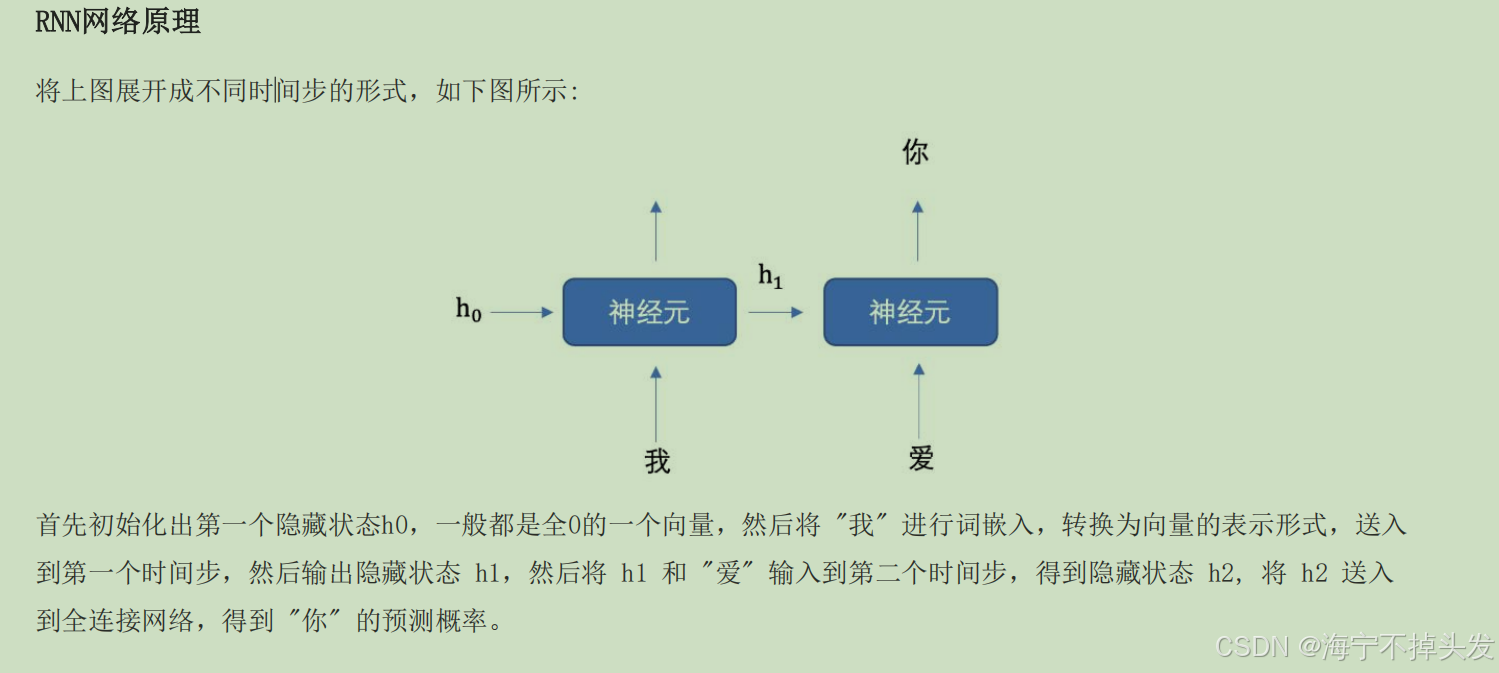






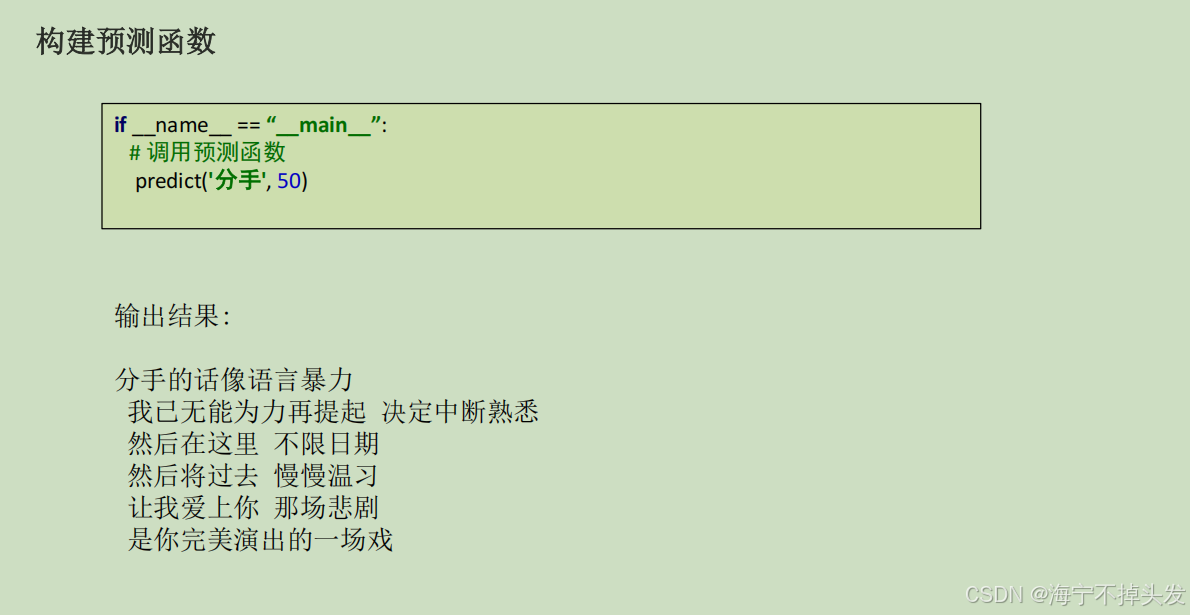
总结
全文通俗总结
这篇文章是大语言模型(LLM)+ 深度学习基础的新手入门指南,从工具、底层原理、主流模型,到神经网络基础和实战代码,手把手带你搞懂AI大模型到底是怎么回事,核心内容可以拆成5个部分:
一、入门工具:Hugging Face
它就是AI圈的“GitHub”,是全球最大的大模型、数据集开源仓库,官方地址和国内镜像站都给好了,解决国内访问慢的问题,新手不用从零造轮子,直接就能用现成的模型和数据。
二、LLM底层核心:语言模型的进化
这部分讲清了“AI是怎么学会说话、猜下一个词的”,核心是两代模型的升级:
- 初代N-gram:靠“死记词频”干活。比如统计“我”后面跟“想”的次数最多,输入“我”就优先猜“想”,本质是输入法联想的逻辑,只会背规律,不会理解语义。
- 进化版神经网络语言模型(NNLM):不用死记硬背了。先把词转成带语义的向量,再用神经网络学习上下文的意思,比如看到“我想喝”,能理解是要找饮品,而不是光看词出现的次数,真正学会了“理解语境”。
三、主流LLM架构大盘点
讲了现在最核心的3类大模型底子,一句话说清各自的定位:
- BERT:「阅读理解大师」。双向Transformer结构,能同时看一句话的前后文,精准理解词义,最适合做语义理解、文本分类、智能问答这种“读懂文本”的任务。
- GPT:「续写作家」。单向Transformer结构,只能从左到右看上文、猜下文,天生适合文本生成,ChatGPT就是在这个架构上发展来的;用大量书籍文本训练,练会了长文理解和通用能力。
- T5:「全能翻译官」。把翻译、问答、摘要、分类等所有NLP任务,全统一成“输入一段文本、输出一段文本”的格式,一个模型就能搞定所有文本任务,泛化能力拉满。
四、深度学习基础:两大核心神经网络
补充了大模型的“前辈”——CNN和RNN,也是AI最核心的基础组件:
- CNN(卷积神经网络):「特征提取专家」。最擅长抓局部关键特征,原本是做图像识别的,也能处理文本;文章里不仅讲清了它的结构,还附了完整的训练代码,新手能直接跑通。
- RNN(循环神经网络):「序列处理专家」。专门处理有顺序的数据(比如文本、天气预报时序数据),自带“记忆功能”,能把前面的内容存下来,给后面的预测用,天生适合文本生成、机器翻译;文章里还做了周杰伦歌词生成的实战项目,输入开头词就能自动生成歌词,把原理落地成了可运行的项目。
五、最终总结
整篇文章从“AI怎么学会说话”的底层逻辑,到主流大模型的区别,再到神经网络基础和实战代码,完整覆盖了LLM入门的核心内容。核心就是让你搞懂:AI大模型的本质,是从海量文本里学习语言规律,从最开始的死记词频,到现在用神经网络深度理解语义,一步步变得更智能,最终能完成各类文本理解、生成任务。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)