【个人CNN学习记录之神经网络基础补充】
在日常工作中,我专注于并行计算领域,主要依托GPGPU、NPU等高算力芯片进行开发。当前,高算力与AI已深度融合,计算与人工智能二者相辅相成:底层计算为实现通用算法与算子提供基础,而AI模型则能反哺并优化传统算法的决策效率与性能。为系统构建这方面的知识体系,我在公司导师的推荐下,跟随up主“霹雳吧啦Wz”的CNN系列视频进行学习,并通过博客记录学习过程,融入自己的理解与总结。以上就是今天要讲的内容
个人CNN学习记录之神经网络基础补充
主要根据视频补充神经网络基础知识中的权重计算/反向传播/权重更新知识
前言
在日常工作中,我专注于并行计算领域,主要依托GPGPU、NPU等高算力芯片进行开发。当前,高算力与AI已深度融合,计算与人工智能二者相辅相成:底层计算为实现通用算法与算子提供基础,而AI模型则能反哺并优化传统算法的决策效率与性能。为系统构建这方面的知识体系,我在公司导师的推荐下,跟随up主“霹雳吧啦Wz”的CNN系列视频进行学习,并通过博客记录学习过程,融入自己的理解与总结。
一、误差的计算
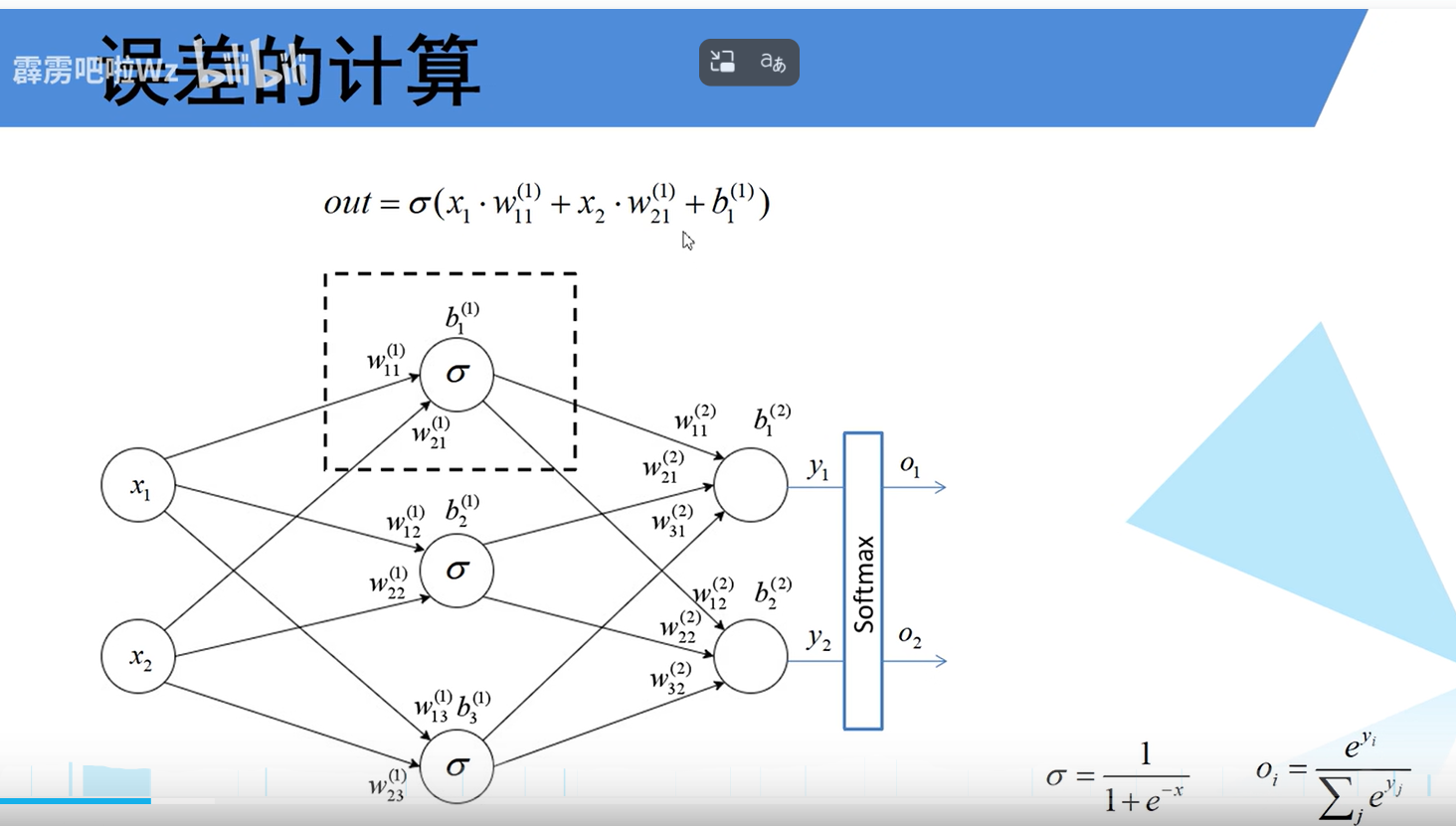
图中展示了一个三层神经网络,包含:输入层、隐藏层、输出层。
输入层:2个节点 (x₁, x₂)。
隐藏层:3个节点,每个节点均使用 σ函数(Sigmoid)作为激活函数。
输出层:2个节点 (y₁, y₂),其后连接一个 Softmax 模块,用于将输出转化为概率分布。
公式形式展示了信号从输入层到隐藏层单个神经元的计算过程:
out = σ(x₁·w₁₁⁽¹⁾ + x₂·w₂₁⁽¹⁾ + b₁⁽¹⁾)
该公式体现了神经网络的基本计算单元:加权求和(权重 w与输入 x相乘) + 偏置 (b) → 激活函数非线性变换 (σ)。
Sigmoid激活函数 (σ):公式为 σ(x) = 1 / (1 + e^{-x})。作用是将线性加权和映射到(0,1)区间,引入非线性。
Softmax函数:公式为 o_i = e^{y_i} / Σ_j e^{y_j}。作用是将输出层的多个节点的值(Logits)转化为一个概率分布(所有输出之和为1),常用于多分类任务的输出层。
这三层展示的是一个标准的、经典的全连接神经网络,可以类比CNN网络中的全连接层去看。
该图讲解了神经网络中用于衡量预测误差的交叉熵损失函数。核心知识点总结如下:
1、交叉熵损失的直观理解
交叉熵损失用于衡量模型预测的概率分布与真实的概率分布之间的差异。差异越小,损失值越低,模型预测越准确。它是分类任务中最常用的损失函数。
2、两种主要形式及其应用场景
图中根据不同的分类任务,给出了交叉熵损失的两种具体形式:
- 多分类交叉熵损失
应用场景:典型的多分类问题,例如识别图片中的手写数字(0-9)。
网络输出层:使用 Softmax 函数,将输出转化为概率,所有类别概率之和为1。
计算要点:对所有类别计算真实标签与预测概率对数值的乘积之和。通常真实标签
是独热编码形式(只有正确类别为1,其余为0),因此公式实际只计算真实类别对应的预测概率的负对数。
- 二分类交叉熵损失
应用场景:二分类问题,例如判断邮件是否为垃圾邮件。
网络输出层:使用 Sigmoid 函数,为每个样本输出一个介于0到1之间的独立概率(例如,属于正类的概率)。
计算要点:对每个样本,分别计算其正类(公式前项)和负类(公式后项)的损失。
真实标签 通常为0或1。当其为1时,后项为零;当其为0时,前项为零。因此,公式实际上只针对样本的真实类别计算损失。最后对所有 N个样本的损失求平均。
3、重要符号说明
Oi*:真实标签值(Ground Truth),代表样本的真实类别。
Oi:模型预测值,是模型认为样本属于某个类别的概率。
log:图中默认为以 e为底的自然对数(即 $\ln`)。
二、误差的反向传播
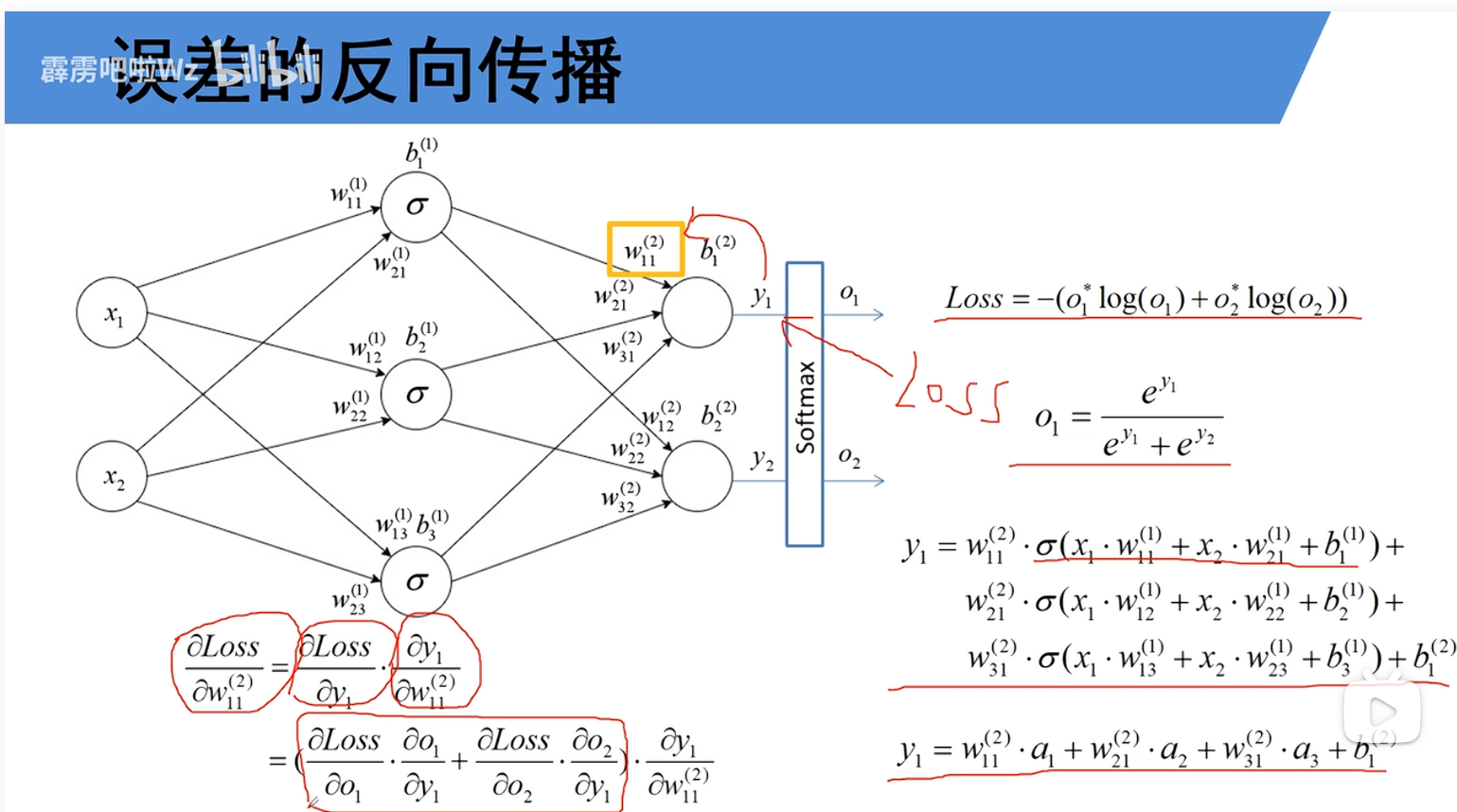
反向传播的核心:梯度计算(图中公式推导部分)
图片右侧及下方的公式推导是知识的核心,展示了如何利用链式法则进行反向传播。其思想是从最终损失开始,层层反向分解,计算损失对每一层参数的梯度。
推导过程通常遵循以下路径(与图中编号w{11}^{(2)}对应):
参数梯度传播:梯度被反向传播到隐藏层的参数。
计算损失对权重的梯度:例如,计算 ∂L/∂w_{11}^{(1)}。
根据链式法则,这等于:(∂L/∂y_1^{(l)}) * (∂y_1/∂w_{11}^{(1)}),后面的公式推导不做展开,在学习的过程中公式这一块确实没深入研究,主要在于理解其中的意义与作用。一个权重的梯度,等于其下一层神经元的误差信号(∂Loss/∂y₁)乘以其上一层的激活值(a₁)。这构成了反向传播高效计算的基石。
最终得到的梯度值参数更新的直接依据。这里只探讨了权重的梯度,偏置的梯度同样需要计算。
三、权重的更新
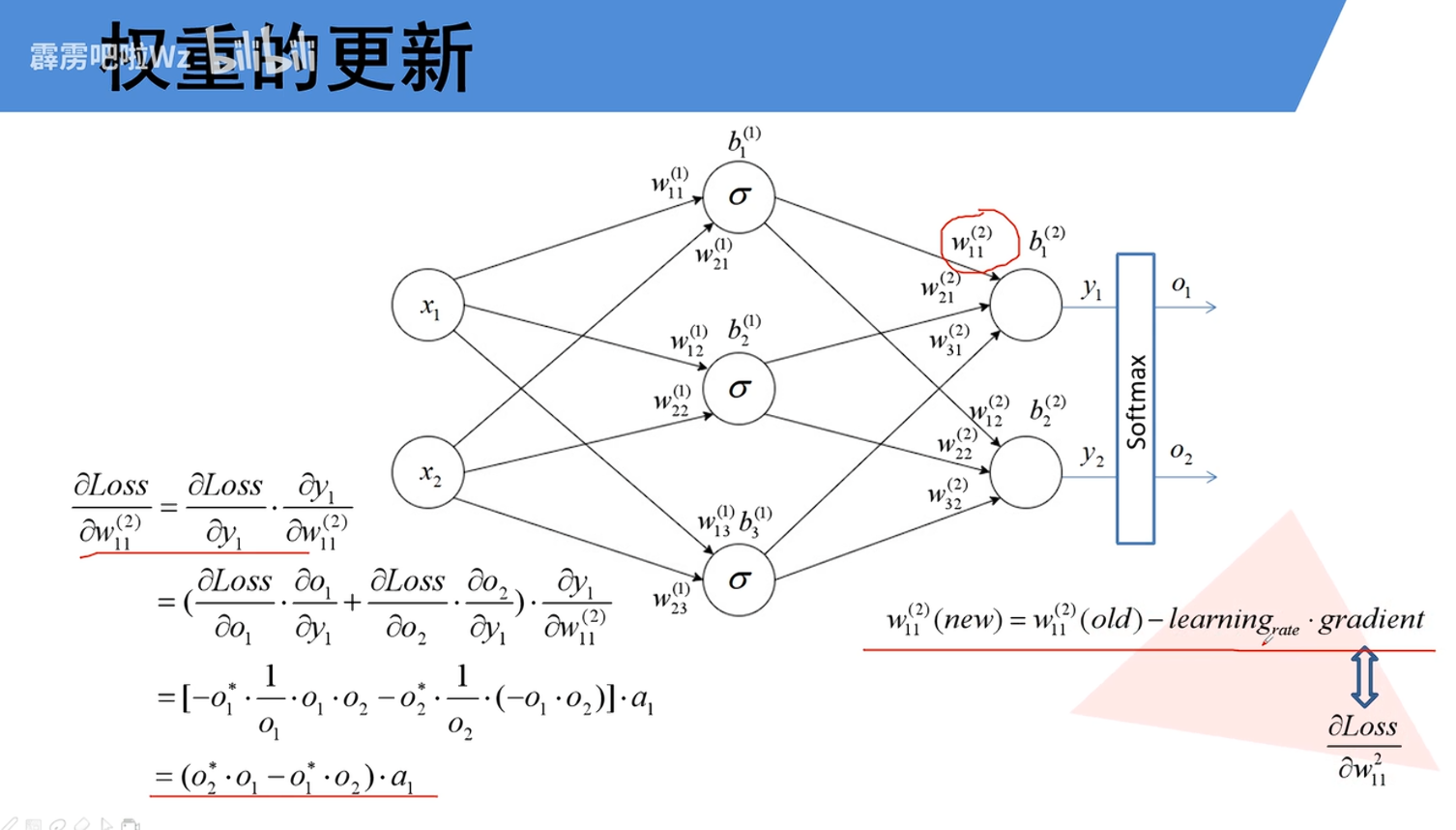
权重更新的核心公式,即梯度下降的参数更新规则,是神经网络学习的引擎。其标准形式如下:
w_new = w_old - η * (∂L/∂w)
w_old:当前迭代开始时的权重值。
∂L/∂w:损失函数 L关于权重 w的梯度(偏导数)
η:学习率,一个大于0的超参数。用于控制每次更新的步长。如果学习率太大,更新可能会“跨过”最低点,导致震荡甚至发散;如果太小,收敛速度会非常缓慢
核心思想:既然梯度 (∂L/∂w)指向损失上升最快的方向,那么取其反方向 (- ∂L/∂w)就是损失下降最快的方向。我们沿着这个方向,迈出大小为 η的一步,从而得到一个新的、期望能使损失降低的权重值 w_new
w_new:更新后得到的新权重值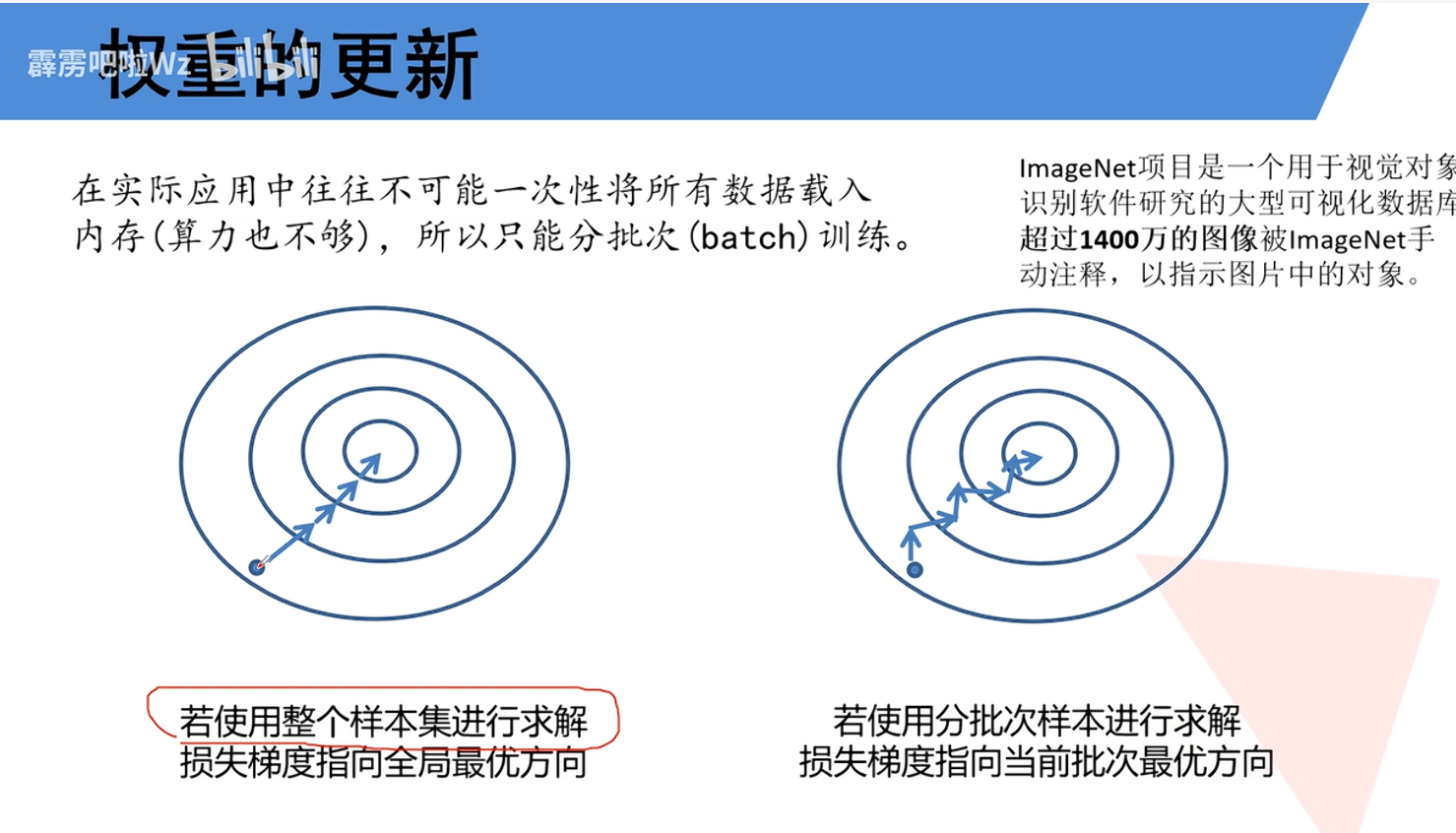
在神经网络的实际训练中,由于计算资源和数据的限制,我们无法一次性使用整个数据集来计算梯度和更新权重,而是必须将数据分成多个小批次进行处理。图中直观地展示了这两种不同方式对权重优化路径的影响。视频中提及ImageNet,它拥有超过1400万张标注图像,正是一个“不可能一次性载入内存”的大规模数据集的典型代表。这有力地解释了为什么我们必须使用分批次训练策略——这是处理大规模数据时的唯一可行方法。

优化器就是利用历史梯度信息,对当前有噪声的小批量梯度进行“智能修正”,从而得到更稳定、更有利于快速收敛的更新方向。图片中列出了一些常见的优化器。
| 优化器名称 | PyTorch 类 | 核心思想 | 常用初始化代码示例 | 关键参数解释 |
|---|---|---|---|---|
| SGD | torch.optim.SGD |
基础随机梯度下降,直接使用当前批次梯度更新,容易震荡 | optim.SGD(model.parameters(), lr=0.01) |
lr:学习率 (η)momentum=0 时是基础SGD |
| SGD+Momentum | torch.optim.SGD |
引入“惯性”,加速收敛、减少震荡 | optim.SGD(model.parameters(), lr=0.01, momentum=0.9) |
lr:学习率momentum:动量系数 (通常0.9),累积历史梯度方向 |
| Adagrad | torch.optim.Adagrad |
自适应学习率,为不频繁更新的参数增大步长 | optim.Adagrad(model.parameters(), lr=0.01) |
lr:学习率lr_decay:学习率衰减因子 |
| RMSProp | torch.optim.RMSprop |
改进的自适应学习率,解决Adagrad学习率过快衰减问题 | optim.RMSprop(model.parameters(), lr=0.001) |
lr:学习率 (通常设得较小,如1e-3)alpha:梯度平方的平滑常数 (通常0.99) |
| Adam | torch.optim.Adam |
动量 + 自适应学习率的集大成者,默认表现好 | optim.Adam(model.parameters(), lr=0.001) |
lr:学习率betas=(0.9, 0.999):动量项和梯度平方的指数衰减率eps=1e-8:数值稳定项 |
总结
以上就是今天要讲的内容。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)