智谱AI GLM-5.1登场即巅峰,对标Claude Opus 4.6,刷新全球最佳纪录
智谱AI发布全新旗舰模型GLM-5.1,综合能力对标ClaudeOpus4.6,在代码能力评测中刷新全球纪录。该模型具备200K上下文窗口和128K输出能力,支持8小时持续工作,可完成从规划到交付的完整闭环。在SWE-BenchPro测试中以58.4分超越GPT-5.4等国际主流模型,并在12项基准评测中表现优异。典型案例显示其能构建完整Linux系统、优化数据库性能等。GLM-5.1提供完善AP
导读: 当全球AI大模型竞争进入白热化阶段,国产大模型再次传来重磅消息。
智谱AI正式发布全新旗舰模型GLM-5.1,不仅在综合能力上对标Claude Opus 4.6,
更在代码能力评测中刷新全球最佳纪录。
这款被称为“中国版GPT”的最强基座模型,究竟有哪些过人之处?
一、GLM-5.1震撼发布:国产大模型的里程碑时刻
在AI大模型领域,有一个残酷的现实:长期以来,全球顶尖模型的头把交椅一直被OpenAI的GPT系列和Anthropic的Claude系列牢牢占据。然而,这一格局正在被悄然改写。

智谱AI正式发布其全新旗舰模型——GLM-5.1。这是一款真正意义上的“工程级”AI助手,它不仅仅是一个会聊天的语言模型,更是一个能够像人类工程师一样,持续、自主地工作长达8小时的智能代理。
智谱AI官方毫不讳言:GLM-5.1的整体表现已经与Claude Opus 4.6对齐,在综合能力与代码能力上达到全球第一梯队。这意味着,中国的大模型终于站在了世界舞台的中央。
二、硬核参数:重新定义旗舰标准

让我们先来看一组令人印象深刻的技术参数:
核心指标 参数详情
模型定位 旗舰基座模型
输入模态 文本
输出模态 文本
上下文窗口 200K tokens
最大输出 128K tokens200K的上下文窗口意味着什么?这相当于可以一次性处理约15万字的文本内容,足以容纳一部完整的中篇小说。而128K的最大输出,则保证了模型在处理复杂任务时不会因输出长度限制而中断。
三、核心能力:不止于“会说”,更在于“会做”

3.1 长程任务能力:8小时级持续工作
传统的大语言模型在处理长程任务时往往会遇到“虎头蛇尾”的困境:任务开始时表现尚可,但随着对话轮次的增加,模型容易出现目标漂移、错误累积等问题,最终交付的成果往往与初衷相去甚远。
GLM-5.1彻底解决了这一痛点。它能够在单次任务中持续、自主地工作长达8小时,完成从规划、执行、测试到修复和交付的完整闭环。这是中国模型中率先达到8小时级持续工作水平的代表。
3.2 工程交付能力:从代码生成到全自治智能体
如果说ChatGPT是“会说的话”,那么GLM-5.1就是“会做事的人”。
在长程任务中,GLM-5.1能够形成“实验—分析—优化”的自主闭环。它不仅能够生成代码,更能够主动运行benchmark(基准测试)、识别性能瓶颈、调整优化策略,在多轮迭代中持续提升结果质量。
这已经从单纯的“代码生成”进化为真正的“全自治智能体”。

3.3 全面的能力支持
GLM-5.1提供了丰富的技术能力支持:
- 思考模式
:提供多种思考模式,覆盖不同任务需求,让模型在面对复杂问题时能够像人类一样“深思熟虑”。
- 流式输出
:支持实时流式响应,大幅提升用户交互体验,告别“等待焦虑”。
- Function Call
:强大的工具调用能力,支持多种外部工具集成,让AI真正成为你的智能助手。
- 上下文缓存
:智能缓存机制,优化长对话性能,降低使用成本。
- 结构化输出
:支持JSON等结构化格式输出,便于系统集成和二次开发。
- MCP支持
:可灵活调用外部MCP工具与数据源,扩展无限应用场景。
四、性能评测:一项纪录震惊全球
在AI领域,基准测试(Benchmark)是衡量模型能力的黄金标准。GLM-5.1在多项权威评测中的表现,足以让整个行业为之侧目。
SWE-Bench Pro:刷新全球最佳纪录
SWE-Bench是目前最具权威性的软件工程能力评测基准,涵盖真实开源项目中的数万条issue解决任务。在最新的SWE-Bench Pro测试中:
GLM-5.1以58.4分的成绩,超越GPT-5.4、Claude Opus 4.6和Gemini 3.1 Pro,刷新全球最佳表现!
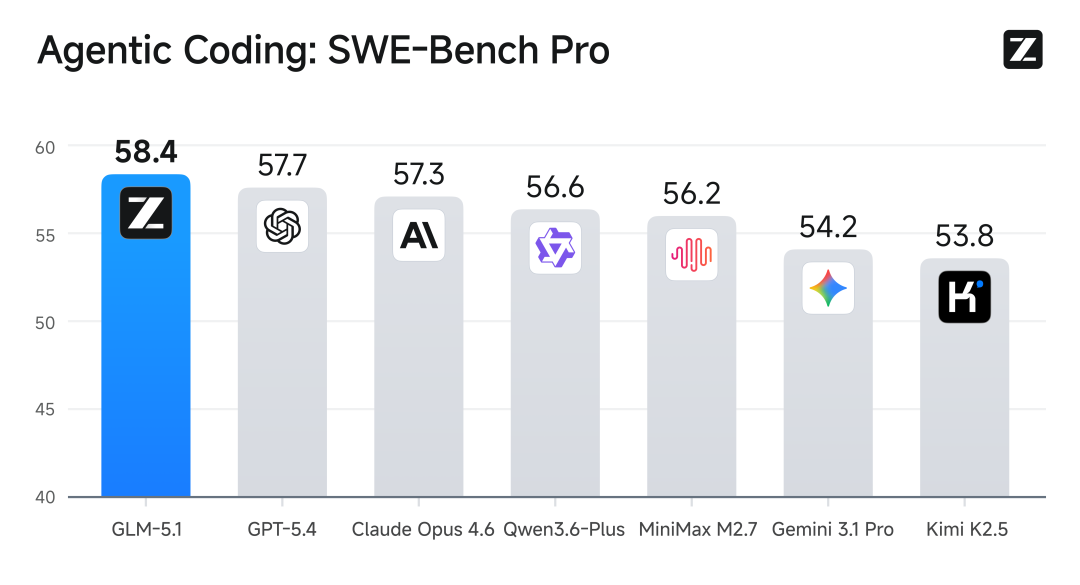
这一成绩的意义非凡。要知道,SWE-Bench测试的是模型解决真实软件工程问题的能力,而非简单的代码补全或生成。它要求模型能够理解issue描述、定位代码问题、编写修复方案、验证测试通过——这是一个完整的软件工程闭环。
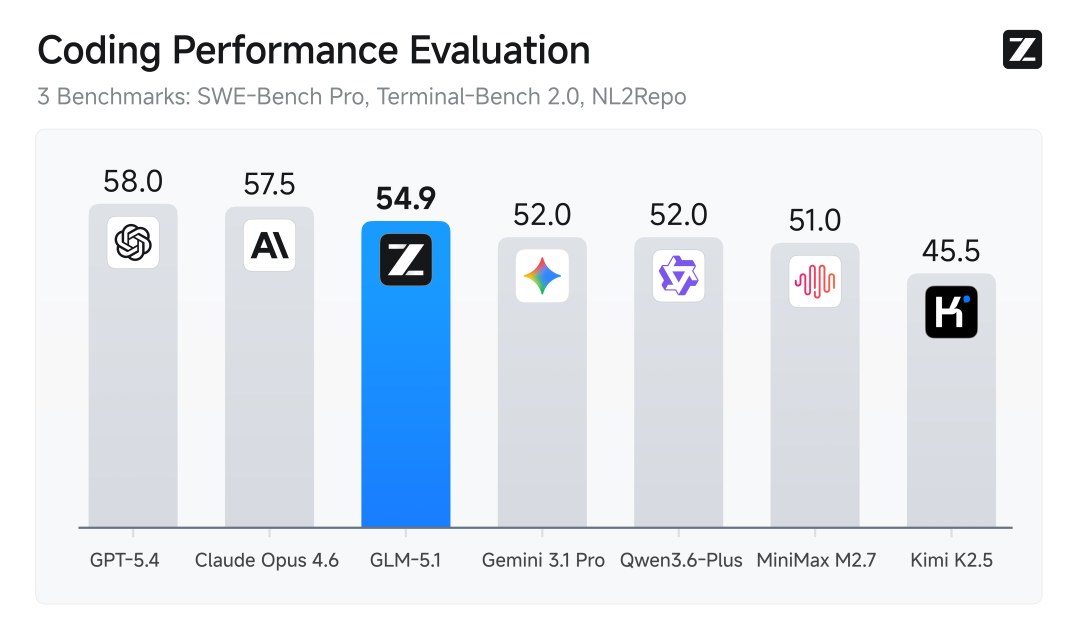
覆盖12项代表性基准
GLM-5.1的能力不局限于代码领域。在覆盖推理、编程、Agent、工具调用与浏览等12项代表性基准的综合评测中,GLM-5.1均展现出第一梯队的领先水平。
五、典型案例:真实场景中的惊艳表现
纸上得来终觉浅,让我们通过几个真实案例来看看GLM-5.1究竟有多强。
案例一:从零构建完整Linux桌面系统
在8小时内,GLM-5.1从零开始构建了一个完整的Linux桌面系统。这不是简单的“hello world”,而是涉及内核配置、图形界面、驱动程序、系统服务等在内的完整工程。

案例二:向量数据库优化
在向量数据库的性能优化任务中,GLM-5.1历经655轮迭代,最终将查询吞吐量提升到初始版本的6.9倍。这种持续优化、自主迭代的能力,是传统代码生成工具无法企及的。
案例三:KernelBench Level 3
在KernelBench Level 3评测中,GLM-5.1通过千轮工具调用,成功优化了真实机器学习模型负载,实现了3.6倍的几何平均加速比。
作为对比,PyTorch官方大名鼎鼎的torch.compile max-autotune功能,仅能达到1.49倍的加速。GLM-5.1的性能提升是其2.4倍以上。
六、应用场景:赋能千行百业
基于上述强大的能力,GLM-5.1在以下场景中具有无可比拟的优势:

6.1 Agentic Coding(智能体编程)
这是GLM-5.1的核心战场。针对Claude Code、OpenClaw等典型Agentic Coding场景,GLM-5.1进行了深度优化,具备更强的长程规划、分步执行、过程调整与结果交付能力。
无论是个人开发者还是企业团队,都可以借助GLM-5.1构建属于自己的AI编程助手。
6.2 通用对话
在开放式问答、复杂指令理解与多轮交流场景中,GLM-5.1同样表现出色。它能够准确理解用户的真实意图,提供专业、详尽、有深度的回答。
6.3 创意写作
从小说片段到故事设定,从品牌文案到营销内容,GLM-5.1能够激发创意灵感,协助创作者高效完成各类写作任务。
6.4 Artifacts/前端开发
网页、交互页面与前端原型生成——GLM-5.1可以将你的想法快速转化为可视化的成果,让“所见即所得”成为现实。

6.5 Office生产力
PPT、Word、PDF、Excel——GLM-5.1能够协助完成各类文档生产任务,让繁琐的办公室工作变得轻松高效。
七、API调用:轻松集成
GLM-5.1提供了完善的API支持,开发者可以轻松将其集成到自己的应用中。
端点地址
POST https://open.bigmodel.cn/api/paas/v4/chat/completions
核心参数
参数 类型 说明
model string 模型名称:"glm-5.1"
messages array 消息列表
thinking object 思考模式配置:{"type": "enabled"}
max_tokens int 最大输出tokens:65536
temperature float 控制输出随机性:1.0
stream boolean 是否启用流式输出
SDK支持
智谱AI提供了多语言的SDK支持:
Python
:pip install zai-sdk 或 pip install zhipuai==2.1.5.20250726
Java
:通过Maven/Gradle添加依赖 ai.z.openapi:zai-sdk:0.3.3
cURL
:直接调用REST API
- 八、属于中国AI的时代正在到来
回顾过去几年中国AI产业的发展历程,从追赶,到并跑,再到如今的局部领跑,每一步都走得艰辛而坚定。
GLM-5.1的发布,不仅仅是一款新模型的问世,更是中国AI产业从“能用”到“好用”再到“领先”的标志性事件。当国产模型能够在全球最权威的评测中登顶,当中国AI能够在8小时内完成以往需要团队协作的复杂工程,我们有理由相信:
属于中国AI的时代,正在到来。
如果你对GLM-5.1感兴趣,可以前往智谱AI的体验中心进行试用,或者查阅官方API文档进行开发集成。让我们一起见证国产大模型的崛起!
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)