AICC 电话智能体之意向分类
重点:2种方式有什么区别,方式1用多轮对话提交给大模型,大模型有时候直接根据历史对话回答问题,不能理解需要总结的意图,所以添加了方式2支持,把历史对话内容直接放到用户提示词,让大模型更好的理解是需要对对话内容进行总结和分类,不是继续回答问题。\nuser:用户回答二。注意:大模型提示词里面的意向分类名字不要和系统预设的A-G冲突, 如果你的分类方法和系统预设的不一致,可以通过添加自定义分类标签,来
意向分类
呼叫失败的时候,系统会根据呼叫失败原因会自动以下几个分类标签
- D 用户忙: (收到回铃(180或者183)信令并且呼叫持续时间大于10秒)或者(空号识别反馈结果为下列值)
- 关机 power off 关机
- 正在通话中 hold on 正在通话中
- 用户拒接 not convenient 用户拒接
- 无法接通 is not reachable 无法接通
- 用户正忙 busy now 用户正忙
- 来电提醒 call reminder 各类秘书服务
- 无人接听 not answer 无人接听
- 无法接听 cannot be connected 无法接听
- 稍后再拨 redial later 各种稍后再拨提示
- E 拨打失败:(没收到回铃(180或者183)信令或者呼叫持续时间小于10秒)或者(空号识别反馈结果为下列值)
- 拨号方式不正确 not a local number 拨号方式不正确
- 呼入限制 barring of incoming 呼入限制
- 线路故障 line fault 线路不能呼出,比如SIM卡欠费
- 网络忙 line is busy 网络忙
- F 无效客户: (空号识别反馈结果为下列值)
- 改号 number change 改号
- 空号 does not exist 空号
- 停机 out of service 停机
- 欠费 defaulting 欠费
- 暂停服务 not in service 暂停服务
- 呼叫转移失败 forwarded 呼叫转移失败
- G 手机助手 :话术配置里面,通过多轮对话把各类语音助手,强制挂机,并且设置为G类
节点强制设置意向标签,优先级最高。只要执行到这个节点就设置。

根据通话时间,回答次数等信息设置意向标签。根据配置顺序执行,找到一个符合,后续的不再执行。

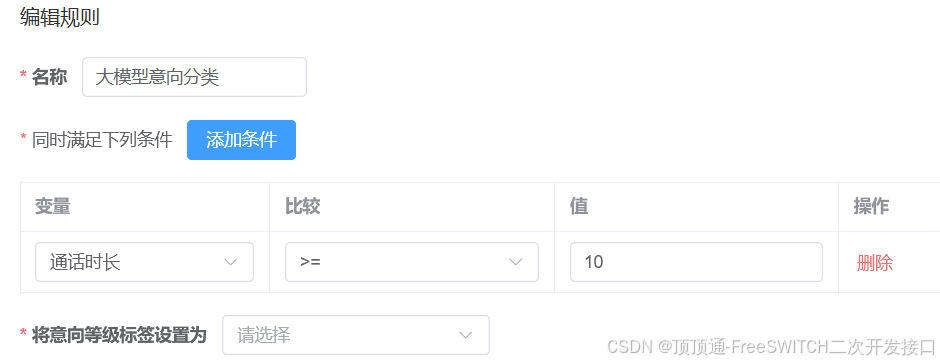
- 通话时长 :AI和通话通话的总时长单位秒
- 回答次数:用户回答次数,一轮对话只计算一次
- 积极回答:通过关键词或者正则命中意向为积极的回答分支次数(大模型命中的不算)
- 消极回答:通过关键词或者正则命中意向为消极的回答分支次数(大模型命中的不算)
- 有意向节点:执行到意向分类为有意向次数
- 无意向节点:执行到意向分类为无意向次数
- 触发知识库:触发知识库次数
- 触发多轮对话:触发多轮对话次数
- AI主动挂断:机器人主动挂断设置为1,否则设置为0
需要先设置符合什么条件才进入大模型分析。
|
注意:大模型提示词里面的意向分类名字不要和系统预设的A-G冲突, 如果你的分类方法和系统预设的不一致,可以通过添加自定义分类标签,来添加你需要的,然后意向提示词里面的分类名字需要和自定义分类名字一致。 |
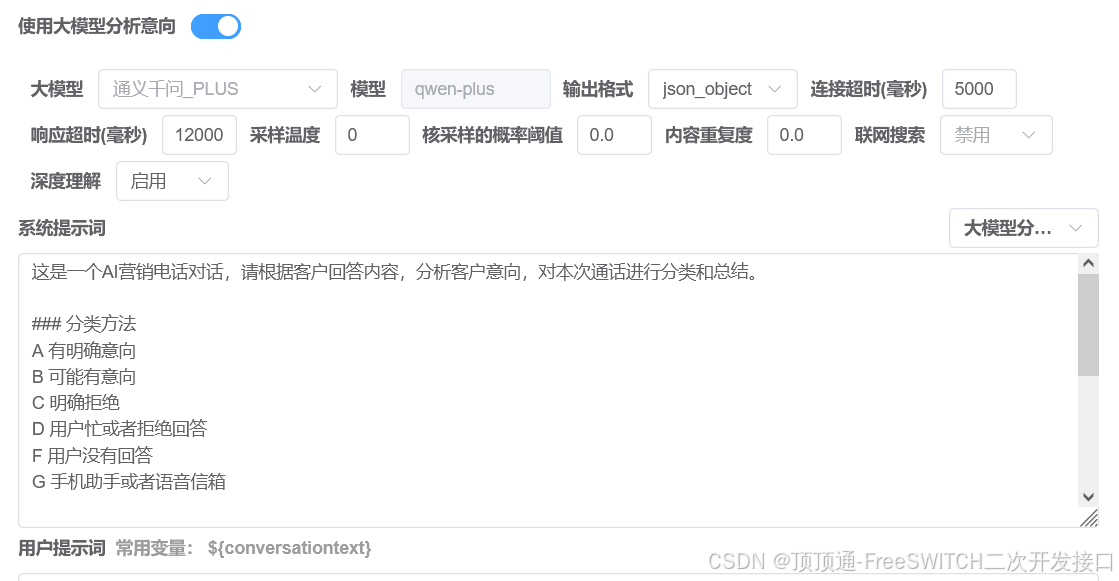
- 推荐选择支持JSON输出格式的大模型 比如 阿里云的,(这样可以用JSON输出格式的系统提示词模板,优点1:支持提取变量,优点2:如果文本输出格式的数据的分类ID经常不按提示词要求输出,可以试试JSON输出格式的模板。)
- 如果大模型支持深度理解,可以试试打开深度理解。注意:打开深度理解会消耗很多token和返回速度很慢,如果不打开能准确分类,千万不要打开,如果怎么修改提示词都达不到要求,才建议打开试试。
- 响应超时建议设置1分钟以上,也就是60000以上。开了深度理解会响应很慢,建议设置成2分钟。也就是120000。
- text格式示例
大模型返回的内容必须是 id:分类,content:总结内容 这样的格式,才可以解析出分类。
|
Markdown |
- json格式示例
大模型返回的内容必须是JSON格式 {"id":"A","content":"总结内容"}
|
Markdown |
- 收集变量实例
大模型返回的内容必须是输出例子一样的JSON格式,变量名字可以自己随便写,支持多个变量,变量必须放在variables属性下面。
|
Markdown |
下面讲解中提交大模型的数据以这个对话内容为例
- 用户提示词不包含${conversationtext}变量的情况下,会采用多轮对话的方式,把历史对话提交给大模型。用户提示词会设置到最后一个用户输入,提交到大模型的数据如下
|
JSON |
- 用户提示词包含 ${conversationtext} 变量的情况,会把变量 ${conversationtext}替换为历史对话内容。把历史对话包含在用户提示词里面的方式提交给大模型。
例子用户提示词为
|
JSON |
提交到大模型的数据如下
|
JSON |
|
重点:2种方式有什么区别,方式1用多轮对话提交给大模型,大模型有时候直接根据历史对话回答问题,不能理解需要总结的意图,所以添加了方式2支持,把历史对话内容直接放到用户提示词,让大模型更好的理解是需要对对话内容进行总结和分类,不是继续回答问题。 |
把通话时间、回答次数、是否AI挂机信息提交给大模型一起分析
用户提示词语支持这几个变量
${talk_time} 通话时间(单位秒)
${respond_count} 用户回答次数
${proactively_hangup} AI主动挂机(yes|no)
${conversationtext} 对话内容
系统提示词语例子
|
Markdown |
用户提示词语例子
|
Plain Text |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)