4、模型预测(MPC)PETS复现demo
在复现完 DDPG 和 SAC 后,我们通过 BC 和 GAIL 掌握了模仿学习的范式,而 PETS (Probabilistic Ensembles with Trajectory Sampling) 代表了最终的升华:智能体不再盲目尝试,而是通过构建一个“不确定性感知”的动力学模型,在脑内沙盘中推演方案。轨迹采样 (Trajectory Sampling, TS)在规划时采用 TS1策略:每一
- “在复现完 DDPG、SAC 以及模仿学习后,你会发现它们都把环境当成了不可预测的‘黑盒’。而 PETS 则另辟蹊径,它不满足于仅仅模仿动作或盲目试错,而是尝试构建一个‘概率世界模型’,通过‘脑内演练’(Planning)实现了采样效率的量级提升。”
1. 学习心得:从 Model-Free 到 Model-Based
在复现完 DDPG 和 SAC 后,我们通过 BC 和 GAIL 掌握了模仿学习的范式,而 PETS (Probabilistic Ensembles with Trajectory Sampling) 代表了最终的升华:智能体不再盲目尝试,而是通过构建一个“不确定性感知”的动力学模型,在脑内沙盘中推演方案。
2. PETS 核心原理:预测世界与对抗偏差
PETS 的核心是解决基于模型强化学习(MBRL)中常见的“模型偏见”问题:
-
概率模型集成 (Probabilistic Ensembles)学一个概率分布而不是确定的值,捕捉环境随机性
(AleatoricUncertainty)。 s t + 1 ∼ N ( μ θ ( s t , a t ) , Σ θ ( s t , a t ) ) s_{t+1} \sim \mathcal{N}(\mu_\theta(s_t, a_t), \Sigma_\theta(s_t, a_t)) st+1∼N(μθ(st,at),Σθ(st,at))同时使用 B B B 个模型组成集成(Ensemble),用以应对数据不足带来的知识不确定性(Epistemic Uncertainty)。 -
轨迹采样 (Trajectory Sampling, TS)在规划时采用 TS1策略:每一条虚拟轨迹的每个步长都随机切换集成中的模型,确保不确定性随时间正确传播,防止规划陷入模型漏洞。
-
基于 CEM 的 MPC 规划不使用 Policy 网络,直接在学到的模型上通过 交叉熵方法 (CEM) 搜索最优动作:
1.采样 K K K 个动作序列。
2.利用模型集成评估这些序列的预估奖励。
3.挑选 Elite Set(精英样本)并更新采样分布。
4.仅执行第一个动作,然后进入下一个循环。
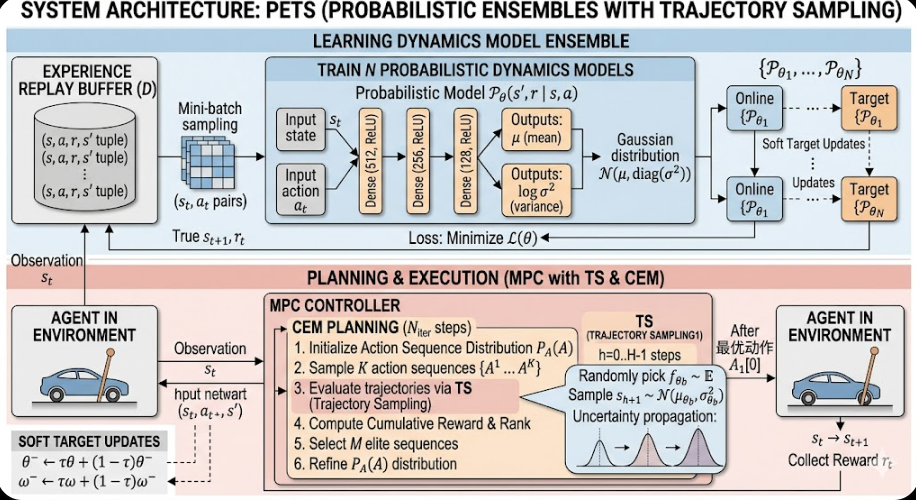
3. PETS的伪代码和网络框架图
伪代码:
PEST的网络框架图:
这个是gemini nano banana 画的。如果大家要发期刊或者论文,也可以用这个工具画噢!
- 复现demo
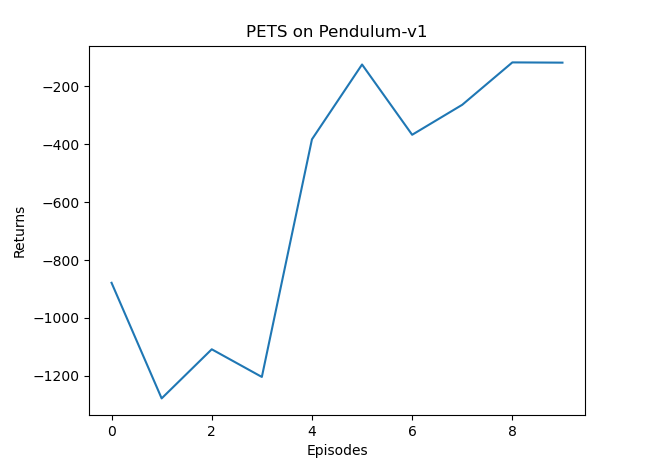
- 可以看出, PETS 算法的效果非常好, 但是由于每次选取动作都需要在环境模型上进行大量 的模拟, 因此运行速度非常慢。
- 与 SAC 算法的结果进行对比可以看出, PETS 算法大大提高了样本效率, 在比 SAC
算法的环境交互次数少得多的情况下就取得了差不多的效果。 - 它不需要构建和训练策略, 可以更好地利用环境, 可以进行更长步数的规划。
- 还有一个更为严重的问题, 即每次计算动作的复杂度太大, 这使其在一些策略及时性要求较高的系统中应用就变得不太现实。
我的个人github项目链接:PETS_demo

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)