Agent 四大组件(感知-记忆-决策-行动)详解
了解Agent 四大组件(感知-记忆-决策-行动)的关系
目录
四大组件详解及架构图
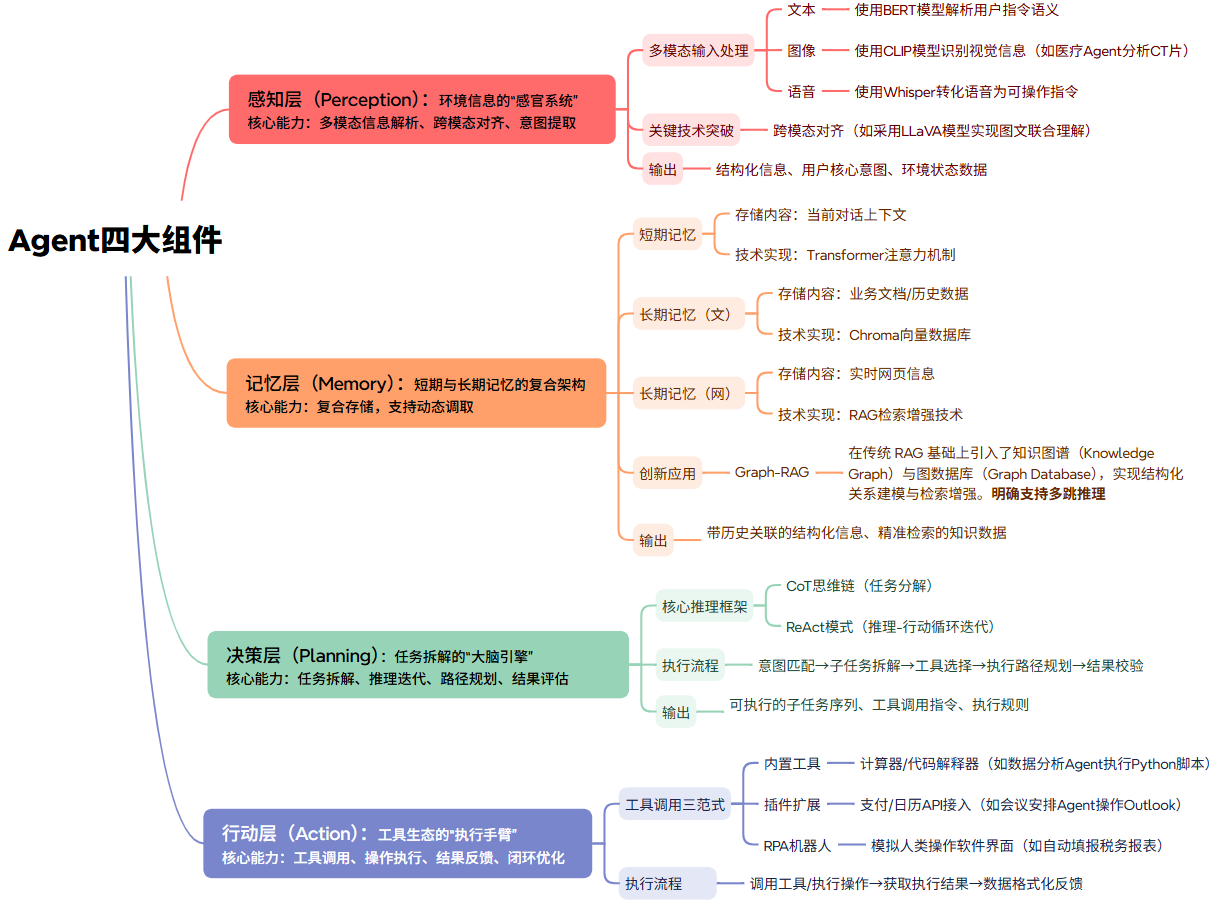
架构图:
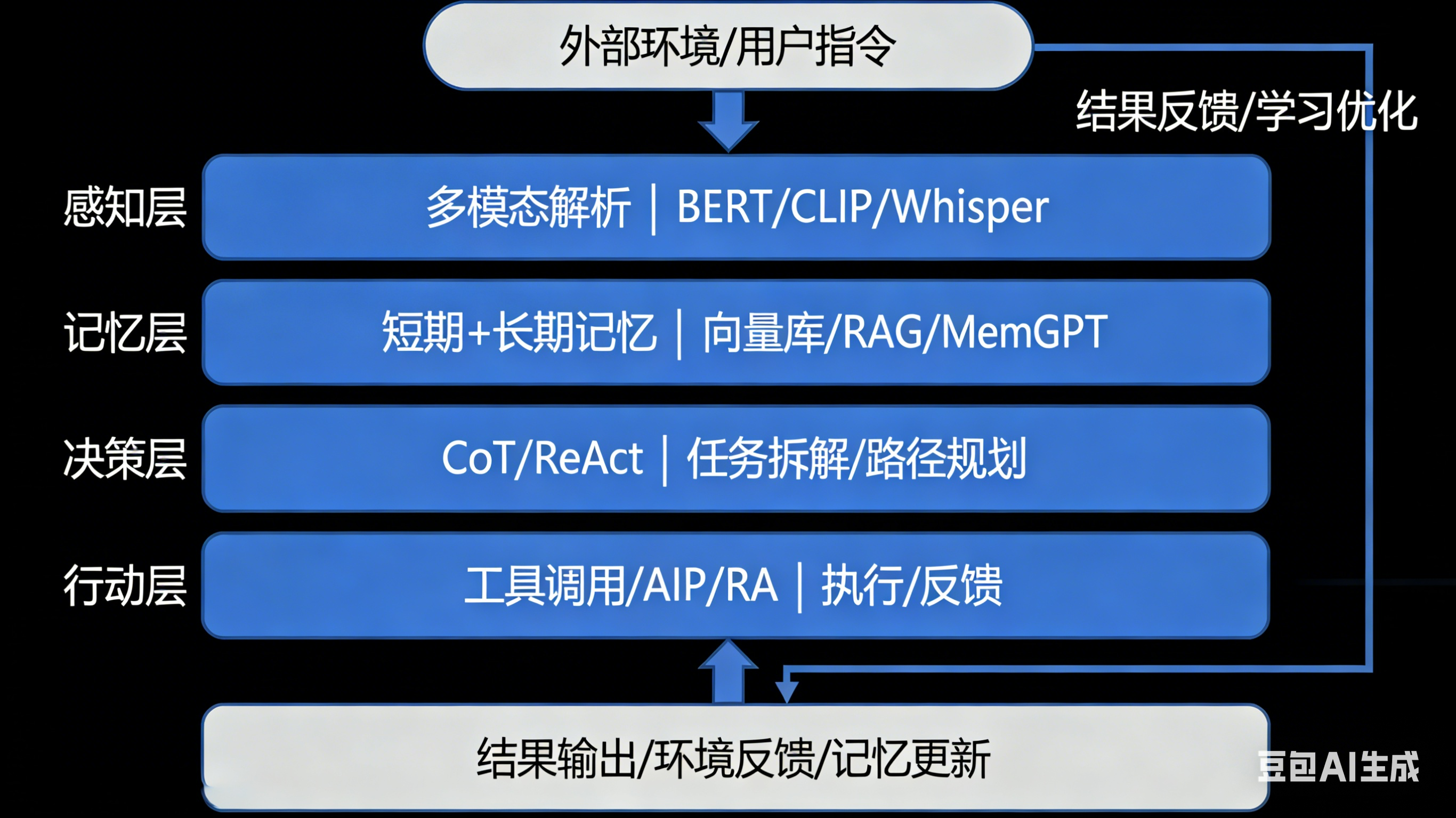
相关理论知识
一、 跨模态和多模态和联合模态的区别
1. 多模态学习(Multimodal Learning)
定义:同时利用多种模态的数据(如文本+图像+音频)进行建模,以提升整体性能。
目标:通过融合不同模态的信息,获得比单一模态更全面、准确的理解。
关键特点:强调信息互补与协同表示。不一定要求模态之间能相互转换。
典型应用:情感分析(结合语音语调、面部表情和文字内容)、自动驾驶(融合摄像头、雷 达、激光雷达数据)。
2. 跨模态学习(Cross-modal Learning)
定义:关注不同模态之间的映射、转换或检索,例如用文本生成图像,或根据图像搜索相关文本。
目标:建立模态间的语义对齐与转换关系。
关键特点:核心是模态间转换,通常依赖共同嵌入空间或对齐机制(如CLIP、DALL-E)。
典型任务:图像描述生成、文本到图像生成、跨模态检索(用语音找对应视频)。
3. 联合模态(Joint Representation / Joint Multimodal Learning)
定义:将多个模态的数据映射到统一的向量空间中,形成一个共享的联合表示,以便直接比较或融合。
目标:使不同模态在同一语义空间中具有可比性(如“猫”的图像和“cat”文本向量靠近)。
关键特点:是多模态学习的一种实现方式(属于融合策略)。强调统一表征,而非模态转换。
典型方法:多模态自编码器、联合嵌入模型(如ViLBERT、UNITER)
三者关系总结
| 维度 | 多模态学习 | 跨模态学习 | 联合模态 |
|---|---|---|---|
| 核心目标 | 融合多模态提升性能 | 实现模态间转换/检索 | 构建统一语义空间 |
| 是否需要转换 | 否 | 是 | 否(但隐含对齐) |
| 典型技术 | 特征拼接、注意力融合 | 对比学习、生成模型(GAN/VAE) | 联合嵌入、共享编码器 |
| 依赖关系 | 包含联合模态作为子方法 | 依赖联合表示或对齐 | 是实现多模态/跨模态的手段之一 |
简言之:
多模态是“一起用多种感官看世界”;
跨模态是“用一种感官理解另一种”;
联合模态是“让所有感官说同一种语言”。
二、CoT和ReAct的区别
CoT(Chain of Thought,思维链)与 ReAct(Reasoning + Acting,推理 + 行动)是大模型推理的两种核心范式,二者在设计思路、交互能力和适用场景上有显著差异。
核心区别
-
CoT(思维链)
- 本质:线性分步推理,模拟“一步步演算”的过程。
- 特点:
- 仅依赖内部推理,不与外部环境或工具交互。
- 推理步骤固定,无回溯、无纠错机制。
- 实现简单,只需在提示词中加入“请逐步推理”即可激活。
- 典型示例:数学计算、逻辑推理、常识判断等纯认知任务。
- 优势:轻量、高效、可解释性强。
- 局限:无法处理需查资料、调 API 或动态获取信息的任务。
-
ReAct(推理 + 行动)
- 本质:推理 + 外部行动 + 观察反馈 的闭环交互。
- 特点:
- 支持调用工具(如搜索、代码执行、数据库查询等)。
- 执行“思考 → 行动 → 观察 → 再思考”的循环,可动态调整策略。
- 能验证假设、修正错误,容错性更强。
- 典型示例:智能助手、自动化工作流、实时数据分析、多步骤业务处理。
- 优势:适用于复杂、开放、需外部信息的任务;工业界落地最广。
- 局限:实现复杂度高,依赖工具封装与环境交互能力。
简言之:CoT 是“纸上谈兵”,ReAct 是“实战演练”23。
目前主流框架
-
主流框架以 ReAct 为核心,因其支持工具调用与闭环交互,更契合 AI Agent 的实际需求。
-
主流开发框架:
- LangChain:广泛用于构建基于 ReAct 的 Agent,内置 Tool 封装与推理循环。
- LlamaIndex:侧重于检索增强与 ReAct 集成,适用于知识密集型任务。
- PocketFlow:轻量级 ReAct 框架,适合快速原型开发23。
-
工业界常见实践:采用 ReAct + CoT 融合范式(即在 ReAct 的每一步推理中使用 CoT 技术),兼顾逻辑清晰性与交互能力,覆盖约 90% 的企业级 AI Agent 场景5。
选型建议
-
纯推理、无工具交互 → 优先选 CoT
(如数学题、简单问答、逻辑判断) -
需调用工具、多步骤、自动化 → 优先选 ReAct
(如智能客服、数据分析、代码生成) -
高难度、多解法探索(如科研、竞赛)→ 可考虑 ToT(思维树)
(但成本高,目前工业落地较少)
三、当短期记忆出现截断时怎么处理
背景:
在 AI Agent 系统中,短期记忆出现截断通常是因为对话历史或任务状态信息超出了模型的上下文窗口限制,容量受限于 LLM 上下文窗口(如 4K~128K tokens),导致早期关键信息被丢弃,从而影响任务连贯性与推理准确性。
解决方案(https://docs.langchain.com/oss/python/langchain/short-term-memory):
- 修剪消息 (Trim messages) :在调用 LLM 之前,移除最初或最后的 N 条消息
- 删除消息 (Delete messages) :从状态中 永久删除 消息
- 总结消息 (Summarize messages):总结历史记录中较早的消息,并用摘要替换它们。(推荐)
- 自定义策略 (Custom strategies):自定义策略(例如:消息过滤等)。
四、长期记忆和短期记忆的区别
| 特征维度 | 短期记忆 | 长期记忆 |
|---|---|---|
| 本质 | 工作内存 / 意识现场 | 知识库 / 经验档案 |
| 技术载体 | 模型的上下文窗口 | 外部数据库(尤其是向量数据库) |
| 容量 | 有限且固定(由上下文长度决定) | 理论上可无限扩展(取决于存储硬件) |
| 持久性 | 临时易失(会话/任务结束时重置) | 永久持久(除非主动删除) |
| 访问方式 | 全局、直接(所有信息均在当前上下文中) | 选择性、按需检索(基于相似性搜索) |
| 主要内容 | 原始对话历史、工具原始输出、即时推理链 | 用户画像、会话摘要、关键事实、学习成果 |
| 核心目标 | 完成当前任务,保证响应连贯 | 实现个性化,支持持续学习 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)