英伟达×李飞飞等四大顶尖团队联合打造:代码驱动机器人操控的统一框架!
缺乏系统的评估基准,无法量化抽象层级、交互模式等因素对性能的影响;中,CaP-Agent0在4个任务上达到或超过人类专家水平,且在LIBERO-PRO和BEHAVIOR的长程任务中,表现出优于主流VLA模型的泛化能力——尤其在指令扰动场景下,CaP-Agent0的平均成功率(0.14-0.18)远高于VLA模型(0.00-0.01)。例如,低层级多轮评估(M4)的性能不仅超过高层级单轮评估(S2)

首次系统量化了大语言模型在机器人操纵场景中的能力边界
——代码即策略
目录
机器人操纵领域的两大范式矛盾:
传统编程控制依赖人工设计抽象接口,虽具备强可解释性却难以泛化;
VLA模型依托大规模数据学习,擅长复杂交互却缺乏灵活性与可解释性。
而新兴的“代码即策略”(Code-as-Policy)思路虽有望融合两者优势,但其在真实机器人操纵场景中的有效性、泛化能力及优化路径尚未得到系统探索。
由英伟达Jim Fan团队×伯克利×斯坦福李飞飞团队×CMU联合提出的CaP-X框架,填补了这一研究空白——通过统一的交互环境、标准化基准、无训练优化方案及强化学习扩展,第一次系统性、分层级、可复现地测评:
大模型写代码控制机器人,到底有多强?去掉人类脚手架后还能不能打?怎么让它更强?
01 核心定位:弥合范式鸿沟的统一平台
Code-as-Policy范式试图用通用代码生成替代人工编程,让模型自主合成可执行程序来协调感知与控制原语。但此前研究存在明显局限:大多依赖高-level抽象接口(如stack_objs_in_order()),性能提升究竟源于模型能力还是人工脚手架存疑;缺乏系统的评估基准,无法量化抽象层级、交互模式等因素对性能的影响;针对低层级原语的优化策略尚未形成体系。
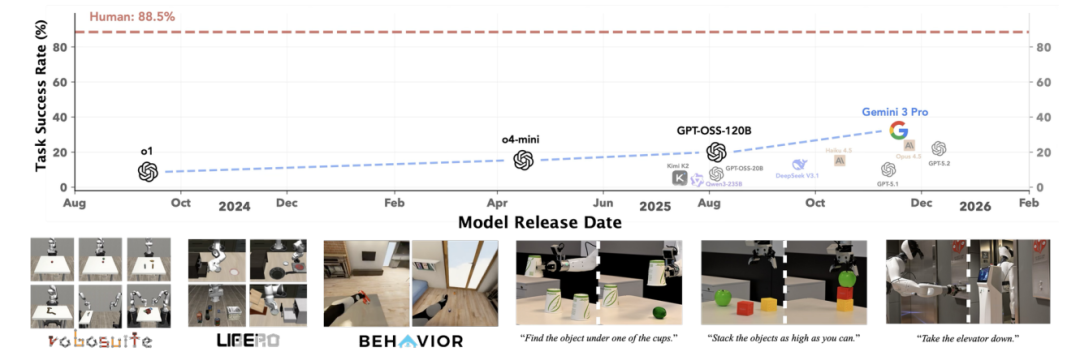
▲CaP-Bench 任务成功率与模型发布日期关系及 CaP-Gym 环境整合示意图
CaP-X的核心创新的在于构建了“环境-基准-优化”三位一体的统一框架:
-
CaP-Gym:整合187个来自RoboSuite、LIBERO-PRO等主流模拟器的任务,提供统一的感知与控制原语接口,兼容仿真与真实机器人系统;
-
CaP-Bench:从抽象层级、时间交互、感知接地三个维度设计评估体系,覆盖12个前沿语言/视觉-语言模型;
-
性能优化方案:提出无训练的CaP-Agent0和强化学习驱动的CaP-RL,分别针对快速部署和性能提升场景,实现从仿真到真实世界的高效迁移。

02 关键组件:拆解CaP-X的技术架构
CaP-Gym:兼容仿真与真实的交互环境
CaP-Gym基于Gymnasium接口构建,采用“低层级环境循环+有状态代码执行循环”的分层设计,既保留了底层模拟器的原生动力学特性,又通过REPL(Read-Eval-Print Loop)范式适配代码生成类智能体的交互需求。
其核心优势在于统一的原语设计:
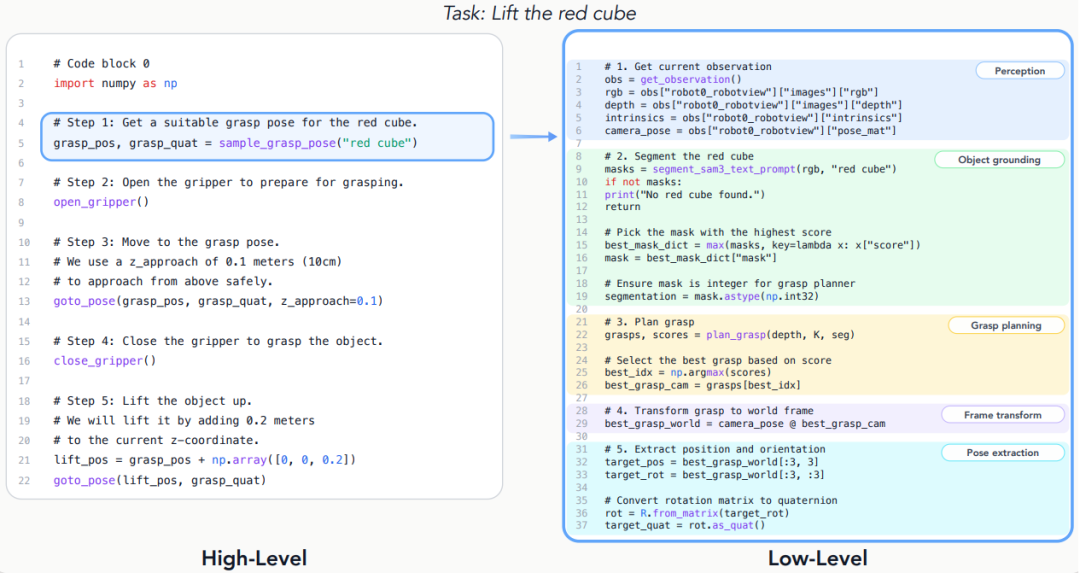
▲高低层级原语代码示例
-
感知原语:
将原始传感器数据抽象为结构化语义信息,集成SAM3(语言条件分割)、Molmo 2(开放词汇指向)等先进模型,搭配OpenCV、Open3D等基础视觉库,支持多模态感知输入;
-
控制原语:
不直接输出关节空间指令,而是调用运动规划器(如PyRoki)和逆运动学求解器,处理碰撞检测、可达性约束等底层问题,让智能体聚焦任务导向的笛卡尔空间推理。

这种设计让CaP-Gym能够无缝对接真实机器人的感知与控制接口,为sim-to-real迁移奠定基础。
CaP-Bench:三维度评估基准
CaP-Bench通过8个评估层级(4个单轮+4个多轮),系统探究模型在不同条件下的操控能力,核心评估维度包括:
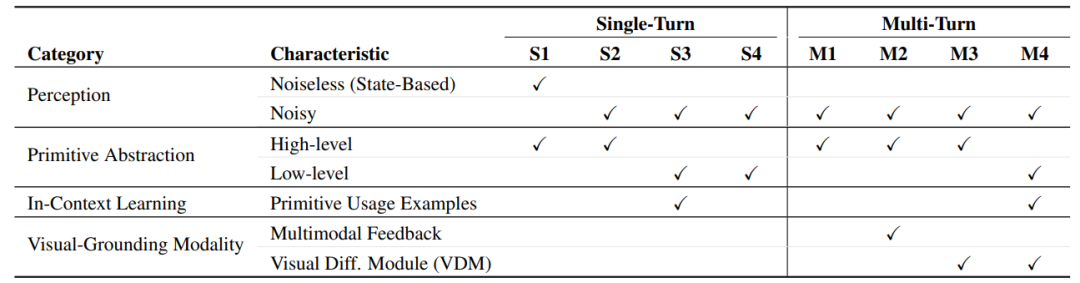
▲CaP-Bench 评估层级对比表
-
抽象层级(Abstraction Level)
从人类设计的高层宏指令(如sample_grasp_pose())到原子级底层原语(如solve_ik()、segment_sam3_text_prompt()),覆盖从“任务 sequencing”到“低层级代码合成”的全范围能力评估。
S1-S2为高层级评估(S1使用真实仿真状态,S2使用RGB-D感知输入);
S3-S4为低层级评估(S3提供API使用示例,S4仅提供函数签名和文档字符串)。
-
时间交互(Temporal Interaction)
对比零样本单轮程序生成与多轮交互的性能差异,量化模型的故障恢复和迭代推理能力。
多轮评估中,智能体可根据执行反馈(stdout/stderr、视觉观测)动态调整代码,无需重置环境。
-
感知接地(Perceptual Grounding)
评估不同视觉反馈模态对代码生成的影响,包括文本-only反馈(M1)、原始RGB图像反馈(M2)、视觉差异文本描述(M3)等。

特别提出的视觉差异模块(VDM),能将视觉观测转化为结构化自然语言,有效解决跨模态对齐问题。
性能优化双路径:CaP-Agent0与CaP-RL
基于CaP-Bench的评估洞察,研究团队提出两种互补的性能优化方案,分别适用于不同应用场景:
(1)CaP-Agent0:无训练的智能体框架
针对无需额外训练、快速部署的需求,CaP-Agent0通过三大核心设计提升低层级原语的操控性能:
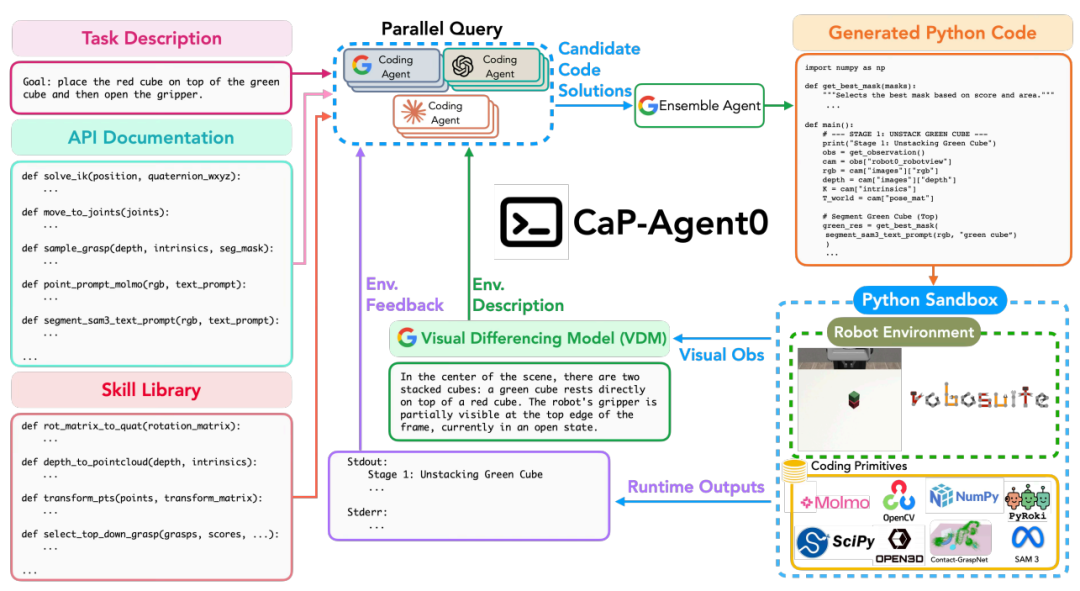
▲CaP-Agent0 架构示意图
-
多轮视觉差异(VDM):将视觉观测转化为结构化文本,避免原始RGB图像导致的跨模态对齐失效;
-
自动合成技能库:从成功执行轨迹中提取高频复用的任务无关逻辑(如旋转矩阵转四元数、点云变换等9个核心函数),减轻模型低层级代码合成负担;
-
并行推理:通过多模型/多温度采样生成候选代码,由集成智能体合成最优解,提升代码鲁棒性。
在CaP-Bench的7个核心任务中,CaP-Agent0在4个任务上达到或超过人类专家水平,且在LIBERO-PRO和BEHAVIOR的长程任务中,表现出优于主流VLA模型的泛化能力——尤其在指令扰动场景下,CaP-Agent0的平均成功率(0.14-0.18)远高于VLA模型(0.00-0.01)。
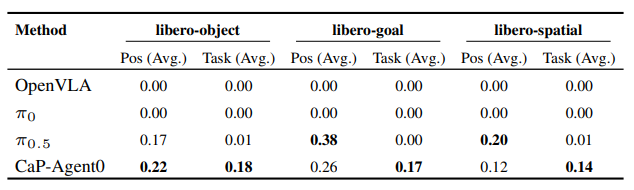
▲LIBERO-PRO 基准性能对比表
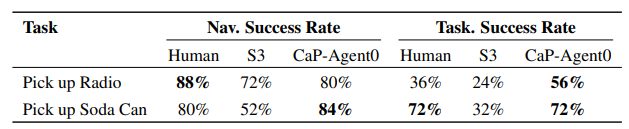
▲BEHAVIOR 任务性能对比表
(2)CaP-RL:强化学习驱动的性能提升
针对需要进一步提升成功率的场景,CaP-RL直接对编码智能体进行强化学习微调。采用Group Relative Policy Optimization(GRPO)算法,在S1层级(特权状态API)进行训练,避免感知噪声导致的奖励信号模糊。

▲CaP-RL 训练后真实世界任务执行示意图
实验结果显示,经过50轮迭代训练后,Qwen2.5-Coder-7B-Instruct模型在立方体抓取、堆叠、液体擦拭等任务上的成功率大幅提升,仿真环境中立方体堆叠任务成功率从4%提升至44%,真实Franka机器人上从12%提升至76%,实现了极小的sim-to-real差距。
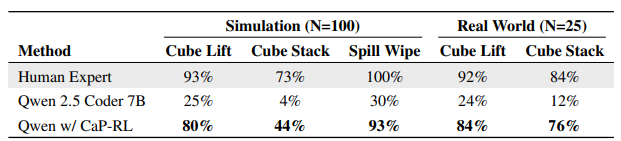
▲CaP-RL 仿真与真实世界性能对比表
这一提升源于强化学习带来的两大改进:
因果序列推理(掌握“识别-抓取-运输-释放”的完整操纵链)和动态几何推理(基于物体尺寸动态计算堆叠高度,而非依赖固定偏移量)。
03 关键发现:揭示代码驱动操控的核心规律
CaP-Bench的大规模评估(12个模型×7个任务×100次试验)揭示了代码驱动机器人操控的三大核心规律,为后续研究提供了重要指导:
前沿模型与人类专家仍存显著差距
单轮低层级评估(S4)中,即使是最先进的闭源模型(如GPT-5.2、Claude Opus 4.5),其任务成功率也未达到人类专家水平(人类专家平均成功率88.5%)。

闭源模型整体表现虽优于开源模型,但所有模型均存在代码合成错误、几何推理失效等问题,反映出当前大语言模型在机器人操控特定场景下的能力局限。
高层抽象提升性能但限制泛化
评估结果显示,随着抽象层级的提高(从S4到S1),所有模型的任务成功率呈单调上升趋势,这与此前Code-as-Policy研究的结论一致。
但高层抽象通过压缩感知、几何推理和控制逻辑,会限制智能体的表达能力,无法实现低层级原语支持的灵活行为(如层级感知故障 fallback)。
研究提出,通用机器人编码智能体应主要在低层级原语上进行评估,确保性能源于模型推理能力而非人工设计的API偏见。
测试时计算缩放有效弥补抽象不足
多轮交互、结构化反馈、并行推理等测试时计算策略,能有效弥补低层级原语带来的性能损失。
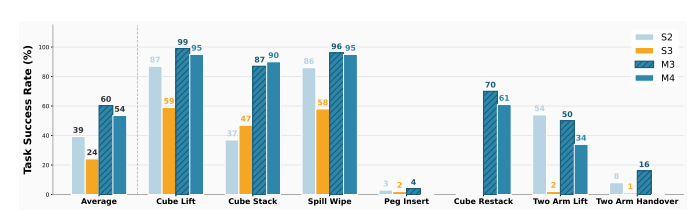
▲M4 层级与其他层级性能对比图
例如,低层级多轮评估(M4)的性能不仅超过高层级单轮评估(S2),甚至能与高层级多轮评估(M3)持平,验证了“通过推理能力提升弥补抽象不足”的核心假设。
值得一提的是,视觉差异文本描述(M3)的性能显著优于原始RGB图像反馈(M2),证明结构化文本是更有效的跨模态接地方式。
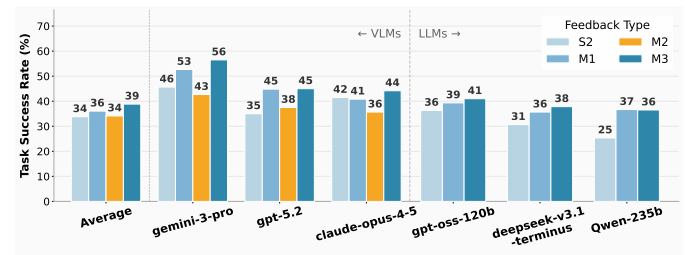
▲单轮与多轮评估对比图
04 局限与未来方向
尽管CaP-X框架在代码驱动机器人操控领域取得了突破性进展,但仍存在明显局限:
-
代码驱动范式在接触密集型任务(如精密插入、倾倒)中仍显脆弱,需依赖VLA模型的低层级执行能力;
-
低层级原语的代码合成仍存在几何推理错误,尤其在复杂姿态变换和碰撞避免场景中;
-
真实世界部署中,感知噪声和硬件误差对代码执行的影响尚未得到充分评估。

▲CaP-RL 任务变体泛化示意图
未来研究可从三个方向进一步拓展:
一是探索CaP与VLA的混合策略,由CaP负责高层级任务逻辑和故障恢复,VLA负责低层级精确执行;
二是增强模型的具身感知与推理能力,提升低层级代码合成的准确性;
三是扩展CaP-Gym的任务覆盖范围,纳入主动感知、多机器人协作等更复杂的机器人操纵场景。
05 总结
CaP-X框架的核心价值,在于构建了代码驱动机器人操控的标准化研究体系——通过统一的环境、基准和优化方案,首次系统量化了大语言模型在机器人操纵场景中的能力边界与提升路径。
其提出的“测试时计算缩放”和“强化学习微调”双路径,为不同应用场景提供了灵活的解决方案。
更重要的是,CaP-X将机器人操控重新定义为“机器智能问题”,实现了感知、控制、推理的协同优化,为通用具身智能的发展提供了新的研究范式。
Ref:
论文题目:CaP-X: A Framework for Benchmarking and Improving Coding Agents for Robot Manipulation
论文地址:https://arxiv.org/pdf/2603.22435v1.pdf
项目地址:https://capgym.github.io

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)