MLflow模型版本超简单
MLflow的“超简单”并非功能简陋,而是设计哲学的胜利——它将模型版本管理从“技术任务”转化为“开发习惯”。当团队不再为“如何记录”而纠结,就能聚焦于“如何创新”。在MLOps演进中,MLflow的易用性使其成为最广泛采用的工具(GitHub Stars超25k),但真正的价值在于:它让每个开发者都能轻松构建可重现的AI系统。行动建议:立即在下一个项目中集成MLflow,从记录第一个参数开始。记
💓 博客主页:瑕疵的CSDN主页
📝 Gitee主页:瑕疵的gitee主页
⏩ 文章专栏:《热点资讯》
目录
在机器学习项目开发中,模型版本管理常被视为“隐形的绊脚石”。团队反复遭遇“为什么上次实验效果好,这次却失败?”或“如何复现上周的模型结果?”等困境。根据Gartner 2025年MLOps调研报告,78%的AI项目因版本管理混乱导致迭代效率下降40%以上。传统方案依赖手动记录或分散存储,不仅增加协作成本,更埋下实验不可重现的隐患。而MLflow作为开源MLOps框架,通过其设计哲学——“让版本管理像写代码一样自然”,将这一痛点转化为可操作的实践。本文将深入探讨如何利用MLflow实现“超简单”的模型版本管理,从基础实践到未来演进,提供可立即落地的解决方案。
模型版本管理的本质是实验可重现性的保障。当团队在多个数据集、参数组合、代码版本中迭代时,缺乏系统化记录将导致:
- 数据漂移不可追踪:训练数据与推理数据版本不一致
- 参数黑箱化:无法回溯关键超参数(如学习率、树深度)
- 协作灾难:不同成员的实验结果无法对比验证
行业洞察:在医疗AI项目中,某团队因未记录数据清洗脚本版本,导致模型在新数据集上准确率骤降15%,追溯耗时2周。MLflow通过自动绑定代码、数据、参数,将此类问题从“耗时排查”变为“一键溯源”。
MLflow的版本管理能力并非堆砌功能,而是精准映射开发者需求:
| 传统方案痛点 | MLflow能力映射 | 用户价值 |
|---|---|---|
| 手动记录参数(Excel) | mlflow.log_param() API |
自动化、免人工输入 |
| 代码散落于不同仓库 | 代码版本绑定(Git集成) | 实验全链路追溯 |
| 模型文件无结构存储 | Model Registry(统一仓库) | 版本化部署与回滚 |
| 实验结果无法对比 | 实验比较视图(UI/CLI) | 快速决策迭代方向 |
MLflow的核心优势在于降低认知门槛。无需复杂配置,仅需5行关键代码即可启动版本管理。以下为生产级实践流程:
# 安装MLflow (仅需1行)
!pip install mlflow
# 设置跟踪服务器(本地开发)
import mlflow
mlflow.set_tracking_uri("file:///path/to/mlflow-logs") # 本地存储
mlflow.set_experiment("Customer_Churn_Model") # 创建实验
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 启动新实验运行
with mlflow.start_run():
# 记录关键参数(自动存储)
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 10)
# 训练模型
model = RandomForestClassifier(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)
# 记录指标(自动关联实验)
accuracy = accuracy_score(y_test, model.predict(X_test))
mlflow.log_metric("accuracy", accuracy)
# 保存模型到Registry(核心!)
mlflow.sklearn.log_model(model, "churn_model")
# 查看所有模型版本
mlflow models list --model-uri models:/churn_model/Production
# 从Registry部署到API
mlflow models serve -m models:/churn_model/1 -p 5000
关键洞察:MLflow将模型版本管理“嵌入”开发流程,开发者无需额外操作——记录参数、指标、模型均在
start_run()上下文中自动完成。这避免了“为版本管理而版本管理”的反模式。
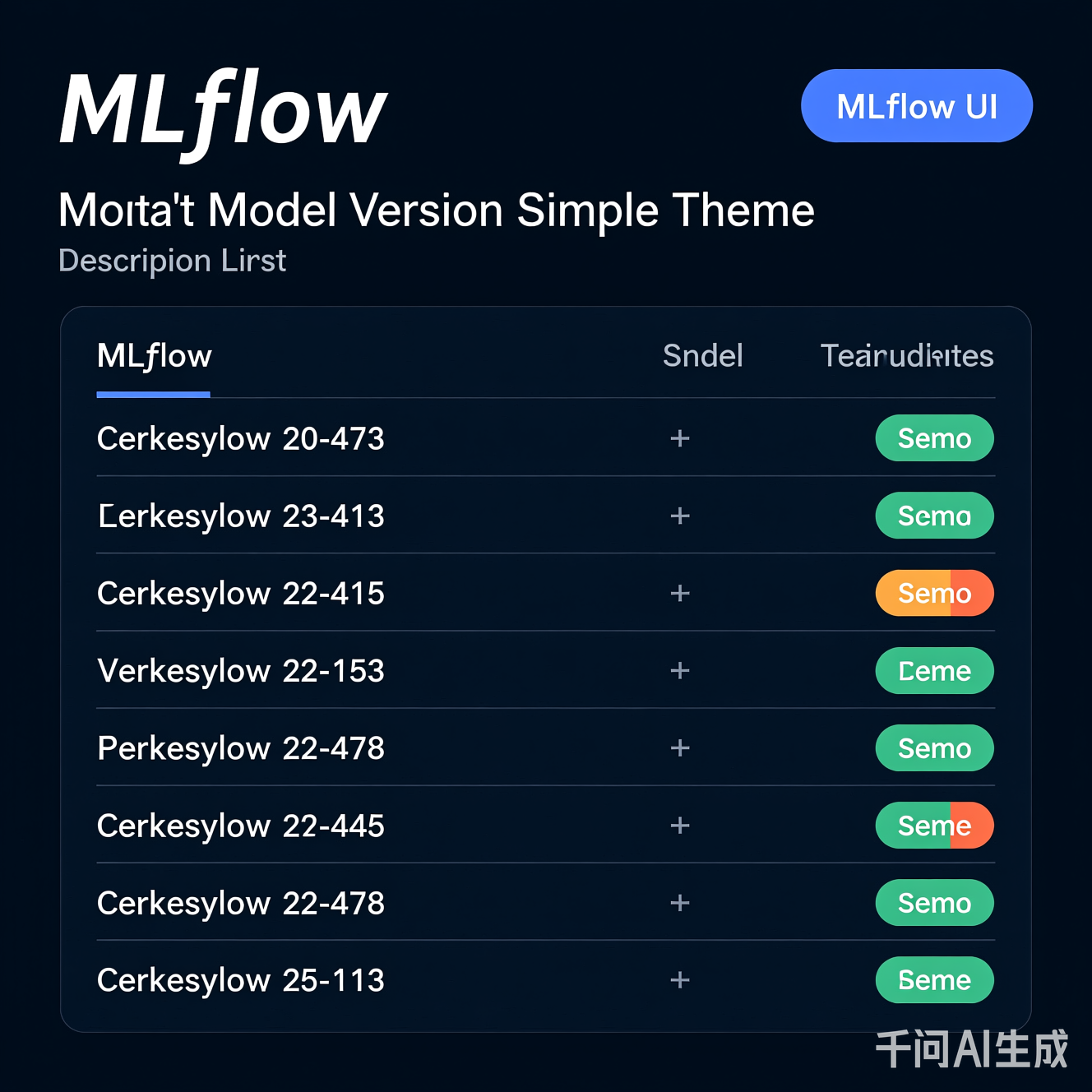
图:MLflow Model Registry界面,清晰展示版本迭代、指标对比与模型状态(如Production/Staging)。无需编码即可完成版本对比与部署。
MLflow的UI设计遵循最小化认知负荷原则:
- 版本列表:按时间/指标排序,一目了然
- 差异对比:点击两个版本自动展示指标、参数差异
- 状态标签:
Staging(测试中)→Production(已上线)的可视化流转
对比传统方案:若用Git管理模型文件,需手动解析
model.pkl内容;MLflow直接提供可点击的版本对比视图,将“版本分析”时间从小时级压缩到秒级。
问题:模型版本记录了参数,但数据版本(如CSV文件)仍需手动管理。
MLflow解决方案:
- 通过
mlflow.log_artifact()关联数据集版本 - 未来方向:与数据版本控制工具(如DVC)深度集成,实现“代码+数据+模型”三位一体版本化
问题:模型在训练环境运行良好,但部署时因依赖冲突失败。
MLflow解决方案:
- 使用
mlflow.pyfunc打包环境(自动记录requirements.txt) - 实现
mlflow.build_docker_image()生成可移植容器
行业争议:部分团队过度依赖MLflow自动记录,导致实验数据冗余。
深度分析:
- 正确姿势:仅记录关键参数(如
n_estimators),而非所有中间变量- 错误实践:记录每轮迭代的完整数据集(浪费存储且无价值)
建议:通过mlflow.start_run()的run_id实现“按需记录”,避免版本爆炸。
| 时期 | 现在时(成熟应用) | 将来时(5-10年愿景) |
|---|---|---|
| 核心能力 | 手动记录参数/模型版本 | AI自动推荐最佳版本(基于业务指标) |
| 协作模式 | 团队成员通过UI对比实验 | 智能协作:自动触发版本评审流程 |
| 技术栈 | MLflow + Git + Docker | MLflow + 云原生MLOps平台 + AIOps |
图:未来模型版本管理流程——从数据输入到生产部署,MLflow作为中枢实现自动化版本流转。
- AI驱动的版本决策:MLflow将集成业务指标(如“用户留存率”)自动选择最优模型版本,而非仅依赖准确率。
- 跨平台统一:在边缘计算场景,MLflow支持设备端模型版本轻量化管理(如手机APP内自动更新模型)。
- 合规性增强:满足GDPR/医疗数据法规,自动记录模型决策的版本证据链。
MLflow的“超简单”并非功能简陋,而是设计哲学的胜利——它将模型版本管理从“技术任务”转化为“开发习惯”。当团队不再为“如何记录”而纠结,就能聚焦于“如何创新”。在MLOps演进中,MLflow的易用性使其成为最广泛采用的工具(GitHub Stars超25k),但真正的价值在于:它让每个开发者都能轻松构建可重现的AI系统。
行动建议:立即在下一个项目中集成MLflow,从记录第一个参数开始。记住:版本管理不是负担,而是信任的基石。当你的模型版本在UI中清晰可见,团队协作的效率将如模型性能般飞速提升。
参考资料
- MLflow官方文档(2025.03更新版)
- Gartner: MLOps Maturity Model 2025
- DVC与MLflow集成最佳实践白皮书(开源社区2025)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)