Meta & 华盛顿大学新发现MAI:大模型配短输出,综合推理效率最高可提升 8 倍
让大模型不再“废话”,小模型不再“平庸”

在追求大模型(LLM)和视觉语言模型(VLM)落地的过程中,我们似乎达成了一个共识:模型越小,推理越快。为了让 AI 跑在手机或端侧设备上,开发者们拼命地压缩参数,从 8B 卷到 2B 甚至更小。但你有没有想过,这个“常识”可能并不完全正确?
最近,来自 Meta 现实实验室、华盛顿大学以及独立研究员的一项研究《Rethinking Model Efficiency: Multi-Agent Inference with Large Models》提出了一个非常有启发性的观点:在实际应用中,大模型配上短输出,往往比小模型配上长推理链更高效。
作者们提出了一个名为 MAI(Multi-Agent Inference,多智能体推理)的框架。这个名字非常直观,它不再让单一模型“孤军奋战”,而是通过大小模型的协作,让小模型负责“碎碎念”式的思考,大模型负责“一针见血”的决策。这种“推理转移”的策略,不仅保住了大模型的精度,还让推理速度飞升。

-
论文地址: https://arxiv.org/abs/2604.04929
为什么小模型反而“慢”了?
在视觉语言模型中,推理延迟主要由四个部分组成:预处理、视觉编码、预填充(Prefilling)和解码(Decoding)。研究人员通过对 Qwen3-VL 系列模型的深度剖析发现了一个扎实的数据:
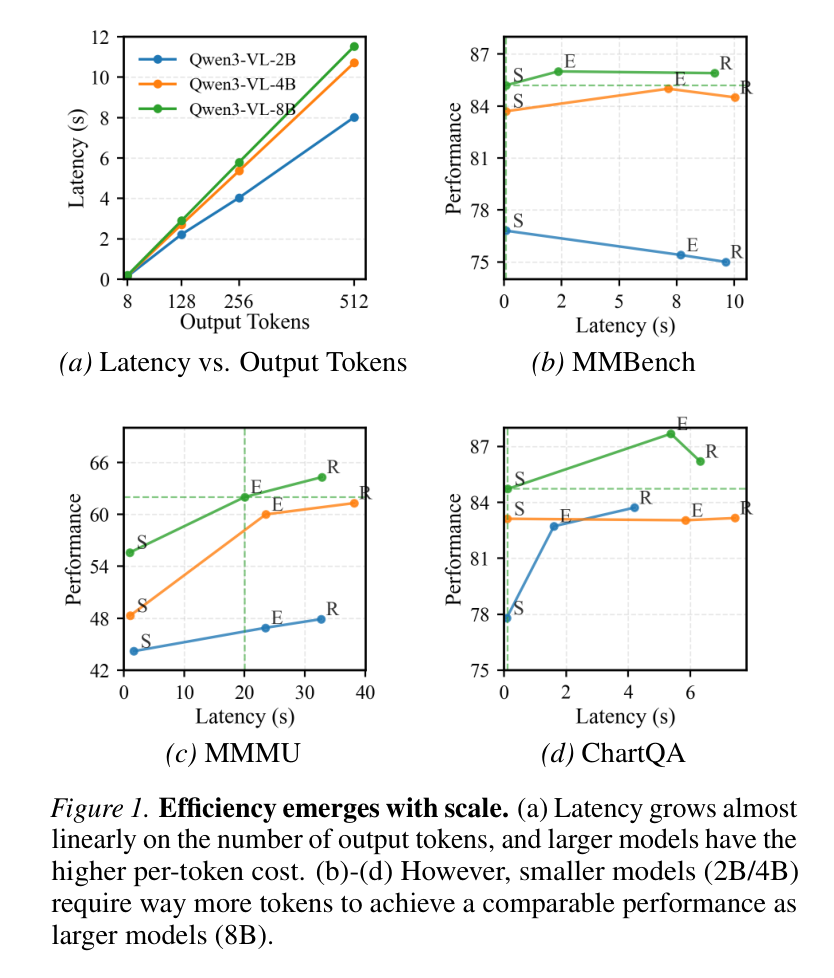
效率随规模增长的示意图
如上图 (a) 所示,推理延迟几乎随输出 Token 数量线性增长。虽然 8B 模型的单 Token 生成成本确实比 2B 模型高,但差距并没有想象中那么大(Qwen3-VL-2B 是 61.8 Tok/s,而 8B 也有 47.3 Tok/s)。
关键问题在于:小模型为了达到和大模型相当的准确率,往往需要生成更长的推理链(Chain-of-Thought, CoT)。在图 (b)-(d) 中可以看到,2B 模型在 MMBench 等测试集上,需要几百个 Token 的“思考”才能勉强追上 8B 模型只用几个 Token 给出的直接答案。
这就导致了一个尴尬的局面:你为了省资源选了小模型,结果它因为“废话多”反而跑得更费时间、更费电。
MAI 框架:让大模型“借用”小模型的思考
既然大模型“直觉”准但生成贵,小模型“思考”慢但生成便宜,那能不能结合一下?作者提出的 MAI 框架由两个核心模块组成:
1. 相互验证 (Mutual Verification, MV)
这是第一道防线。系统同时让大模型和小模型给出“短答案”(Simple Prompt)。
-
Input:原始查询
+ 图像
+ 简单提示词(如“直接回答,不需思考”)。
-
Output:大模型短答案
与小模型短答案
。
-
如果两者的答案语义一致,说明这个问题很简单,直接输出,省去了所有的推理开销。如果不同,则触发后续的推理逻辑。
2. 推理转移 (Reasoning Transfer, RT)
这是该研究最精妙的地方。当需要深度思考时,系统先让小模型生成一段详细的推理过程 。
以往的做法可能是让大模型也自己想一遍,但那太贵了。MAI 的做法是:把小模型想出来的这段话,直接塞给大模型当上下文!
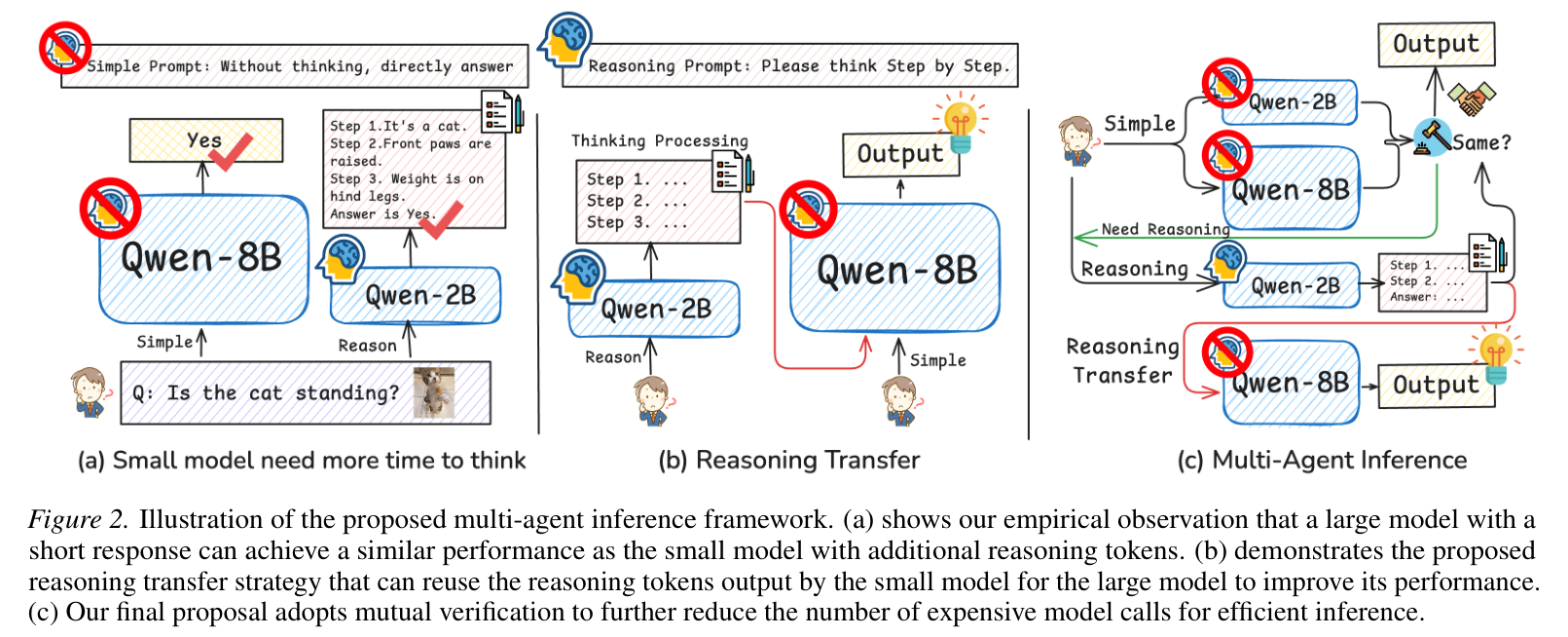
MAI 框架流程图
这里的技术逻辑在于:对大模型来说,“读”一段话(Prefilling)比“写”一段话(Decoding)要便宜得多。通过这种方式,大模型不需要自己去逐字生成昂贵的推理 Token,只需要在预填充阶段快速扫一遍小模型的思路,然后给出一个精准的短答案。
3. 解决小模型的“健忘症”:2阶段策略 (S2)
研究中发现,小模型在进行长推理后,往往会忘记按照要求的格式输出最终答案(指令遵循失败)。为此,作者引入了 2阶段策略(2-stage Strategy, S2):
-
Stage 1:小模型生成完整的推理链。
-
Stage 2:将推理链作为上下文,再次提示小模型提取最终答案。 这种方式虽然多了一次调用,但通过 KV 缓存复用,开销极小,却能显著提升小模型的评估准确率。
理论支柱:大模型能自动“去伪存真”吗?
你可能会担心:如果小模型想歪了,大模型被带坑里怎么办?
作者在文中给出了一个很有力的数学证明(Corollary 1)。基于 Transformer 的自注意力机制具有天然的“稀疏性”。简单来说,大模型在处理小模型传过来的推理 Token 时,会自动把注意力集中在那些关键的语义信号上,而忽略掉那些错误的、冗余的噪声。
公式表达为:
这个公式告诉我们,只要小模型的推理中包含了关键信息,大模型通过注意力机制过滤后的表示偏差就会被限制在一个很小的范围内。
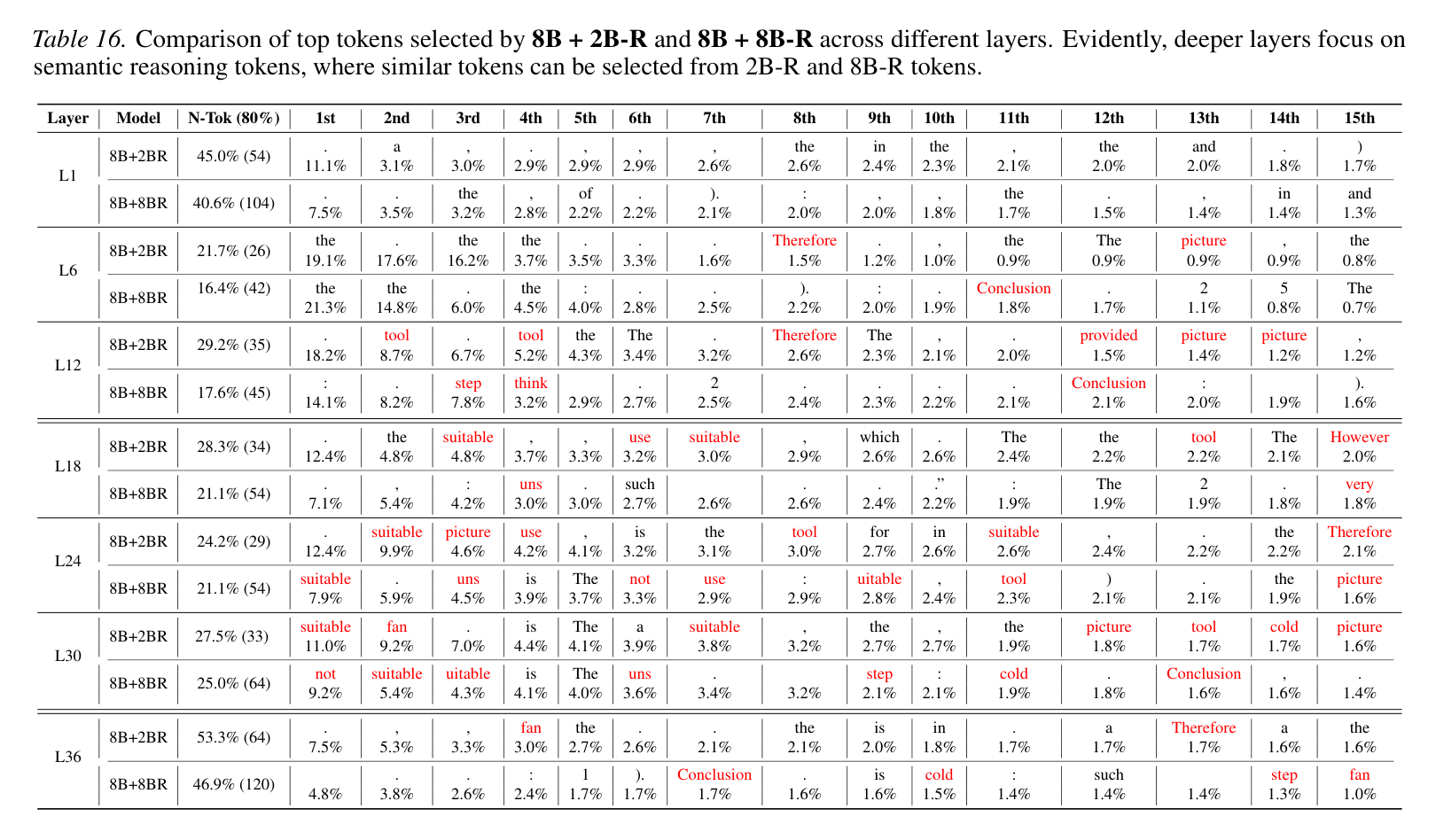
稀疏推理转移的 Token 选择
实验也证实了这一点(如上表所示):即便只从小模型的推理中挑选出权重最高的 20% 的 Token 传给大模型,效果依然稳健。大模型在深层网络中会自动锁定如“picture”、“tool”等核心语义词汇。
性能表现:不仅快,而且更准
研究人员在 Qwen3-VL 和 InternVL3.5 两个主流模型家族上进行了广泛测试,涵盖了 POPE(幻觉评估)、MMMU(综合理解)、ChartQA(图表分析)等 6 个基准测试。
在硬件配置上,实验主要在单张 H100 (96G) 上完成。以下是几个令人振奋的数据点:
-
加速效果显著:在 POPE 数据集上,MAI 框架相比于全量推理的大模型实现了 8.05倍 的加速!在 MMBench 上也有 4.69倍 的提升。
-
精度不降反升:通过 Reasoning Transfer,大模型在“读”了小模型的思考后,性能往往能超过其直接回答的表现。例如在 MMMU 任务中,8B 模型配合 2B 的推理,准确率从 55.6% 提升到了 62.9%。
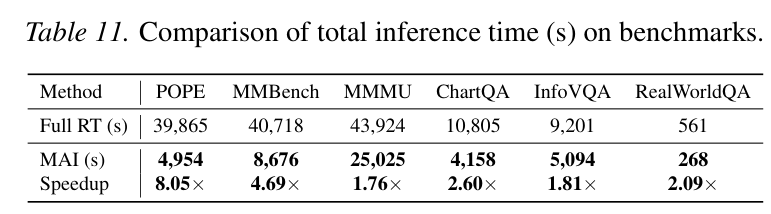
推理延迟对比表
此外,作者还对比了传统的投机采样(Speculative Decoding)。实验发现,在 VLM 这种多模态场景下,投机采样因为频繁的上下文切换和高拒绝率,在 vLLM 等优化后端上的加速效果远不如 MAI 这种“响应级”的协作方案。MAI 在 ChartQA 上实现了 2.40倍 的端到端加速。
写在最后
这项研究最核心的价值在于它打破了我们对“模型效率”的单一认知。它告诉我们,效率不仅仅是参数量的问题,更是 Token 长度管理的问题。
这种“小模型思考,大模型决策”的模式,非常像人类大脑的“系统 1”与“系统 2”的协作,或者是公司里“秘书初稿,领导定稿”的工作流。在未来,我们可能不再需要一个全能的巨型模型,而是一群各司其职的智能体,通过这种高效的“推理转移”实现真正的实时 AI 交互。
目前该方法是 Training-free 的,这意味着你可以直接在现有的开源模型上套用这套逻辑。如果你正在为 VLM 的推理延迟发愁,MAI 框架或许提供了一个“降维打击”的新思路。

入群加好友(v:xiao-ma-baoli),请备注你感兴趣的技术方向

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)